



python定义
--解释型语言(一行一行翻译执行)
编程方式
cmd编程:

IDE编程:(本人使用VS code编程学习)
Debug:
断点、控制台操作
注释:ctrl+/ 多行:‘’‘ ’‘’ “”“ ”“”
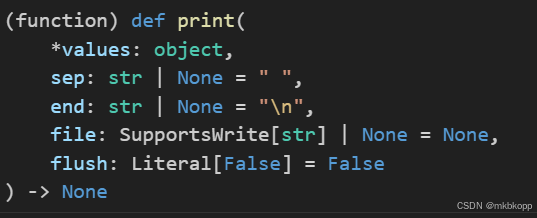
print函数
变量及命名
变量名=值 (右到左)
不能是关键字、大小写区分、大小驼峰命名、_命名
数值类型
type():获取数据类型
整型int:任意大小整数 浮点型float:有小数部分 布尔型bool:true and false(隐值:1和0)
复数型complex: a = 3 - 4j
字符串str:
使用单引号、双引号、三引号(多行)
格式化输出
1.format( )

2.f-string (f or F)
可嵌入表达式和函数
![]()
设置位数
 往前补0
往前补0
设置精度(四舍五入,不足补0)

运算符
算数运算符:
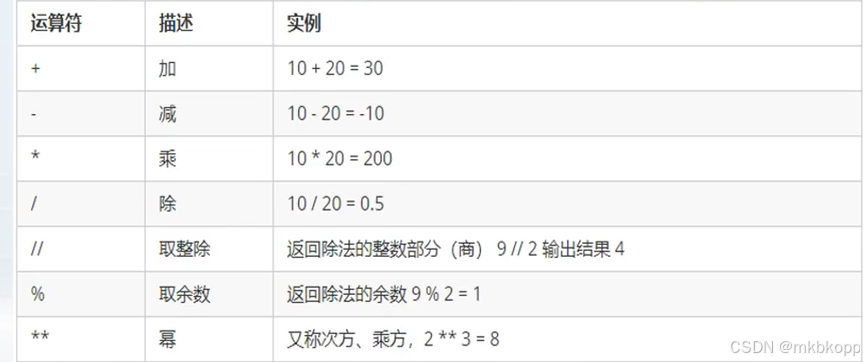
注意浮点数
赋值运算符:
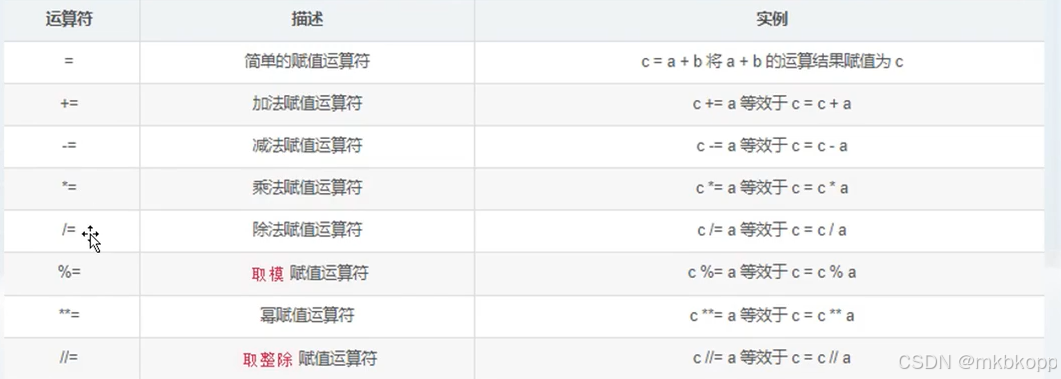
输入函数
input(notice=none<提示信息>)
输入的信息,都会被视为字符串
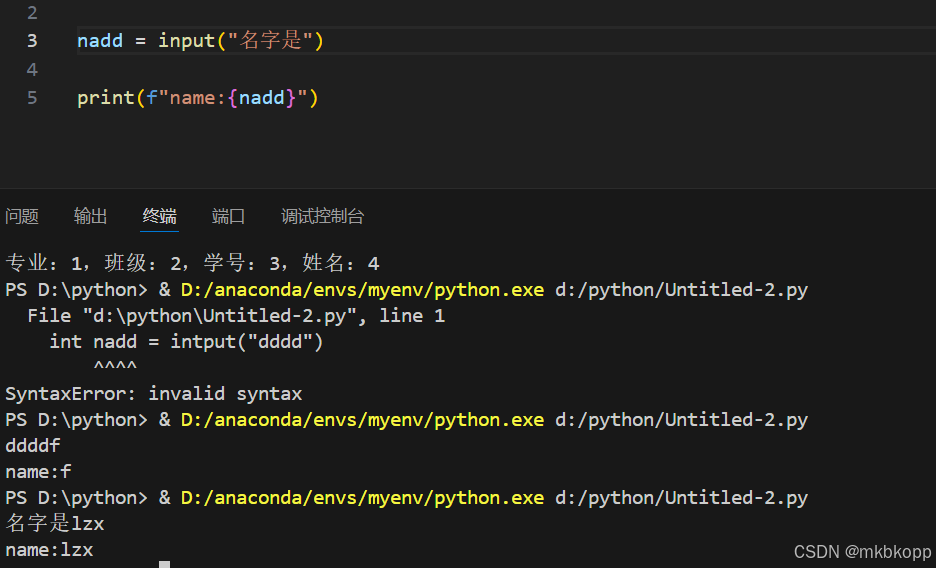
转义字符
: \ 转义
r" "原生字符串:取消" "内所有转义
if语句
条件判断->true->执行 ->false->跳过->else or ..
运算符:

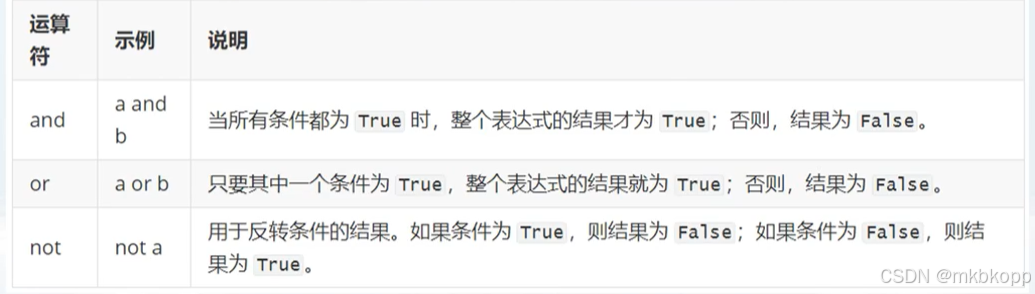

非0非空 是true
短路行为:
and(有一个0则0,否则为最后的一个非0数字) or(类似)
if-else: 语句
三元表达式:(简易的)
真结果 if 条件 else 假结果

if-elif语句:
if-else是二选一 if-elif是多选一
不会在判断以下的语句
if-elif-else: 若if与elif中的条件都不满足,则执行else
if嵌套
循环
while(条件循环)
while 条件:
循环体(代码块)
while嵌套:处理较复杂问题
#生成一个3排6列的队伍
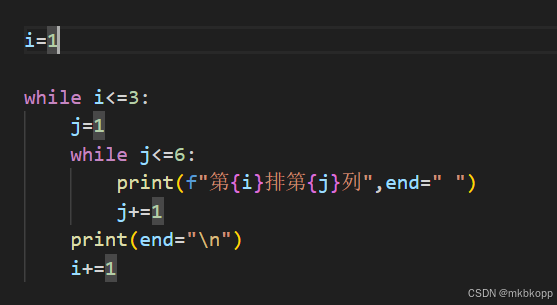

for循环(计次循环)
for 变量 in 可迭代对象
range函数,range(star,stop,step)起始值,结束值(不包括),步长
break continue
要在循环中使用
break:终止循环
continue:跳过此次循环
循环与else语句:
while-else for-else
循环正常结束:->执行else语句
作用:搜索、遍历、处理数据
字符串
字符串编码转换
->翻译二进制数据
编码:
如:ASCII、GB2312、GBK、Unicode、UTF-8(1,2,3)
编码转换
encode()函数 字符串-->字节串
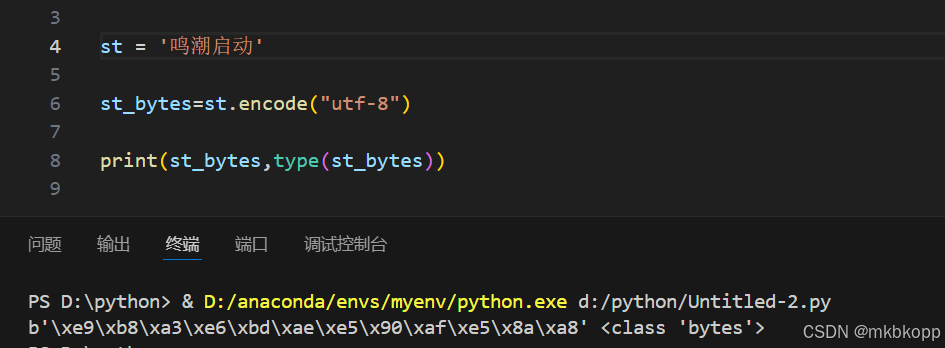
decode()函数 字节串-->字符串
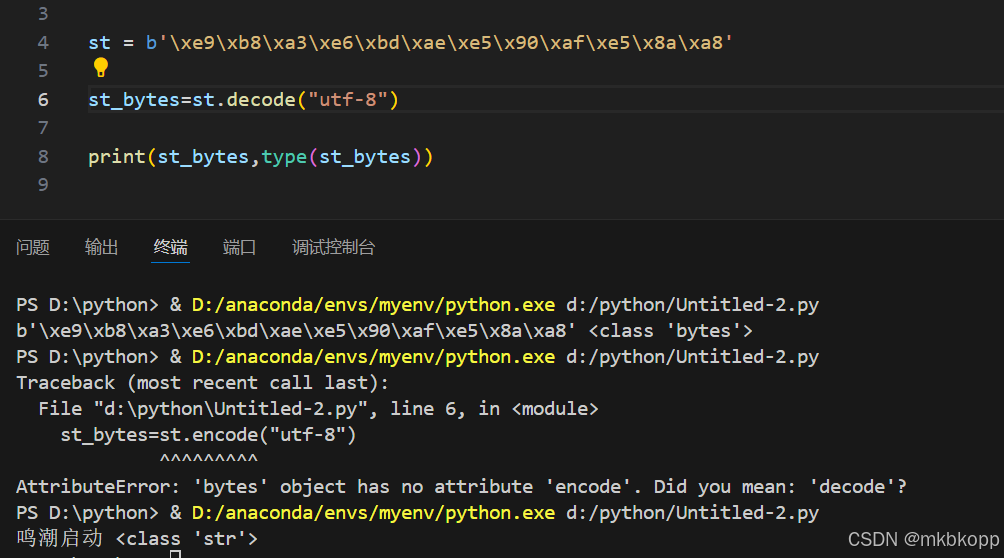
注意使用确定编码方式
字符串运算符

[] 从左到右,下标从0开始 从右到左,下标从-1开始
切片:[star:stop:step] 方向要一致
查找元素
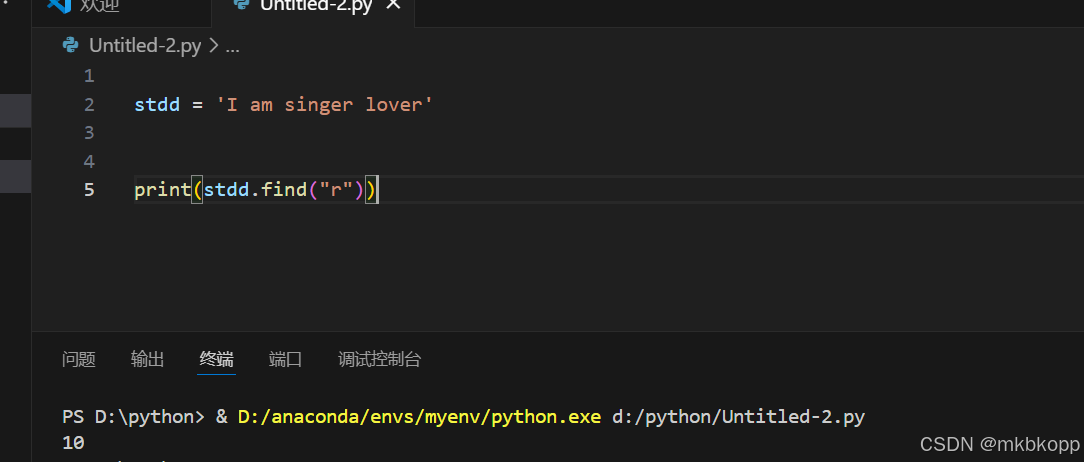
.find(sub,star,end) 返回找到的子字符串的首次出现的位置。 <包前不包后>
.index()和find一样 但返回一个报错。
.count(sub,star,end) 统计子字符串出现次数
修改元素
.replace(old,new,count) count:指定替换次数
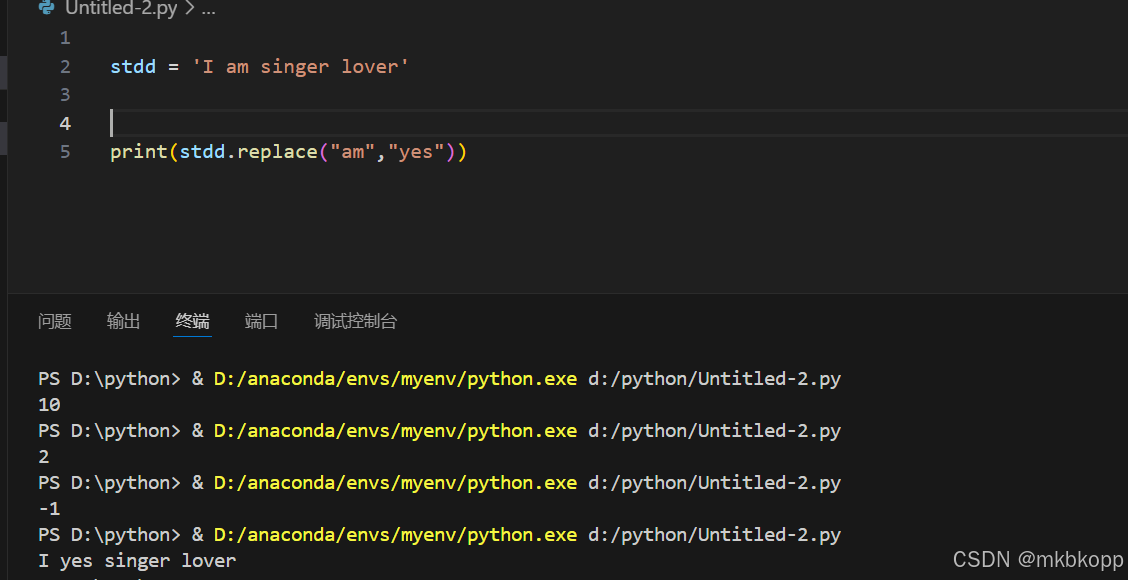
.split(sep,maxsplit) 切割 sep:分隔符
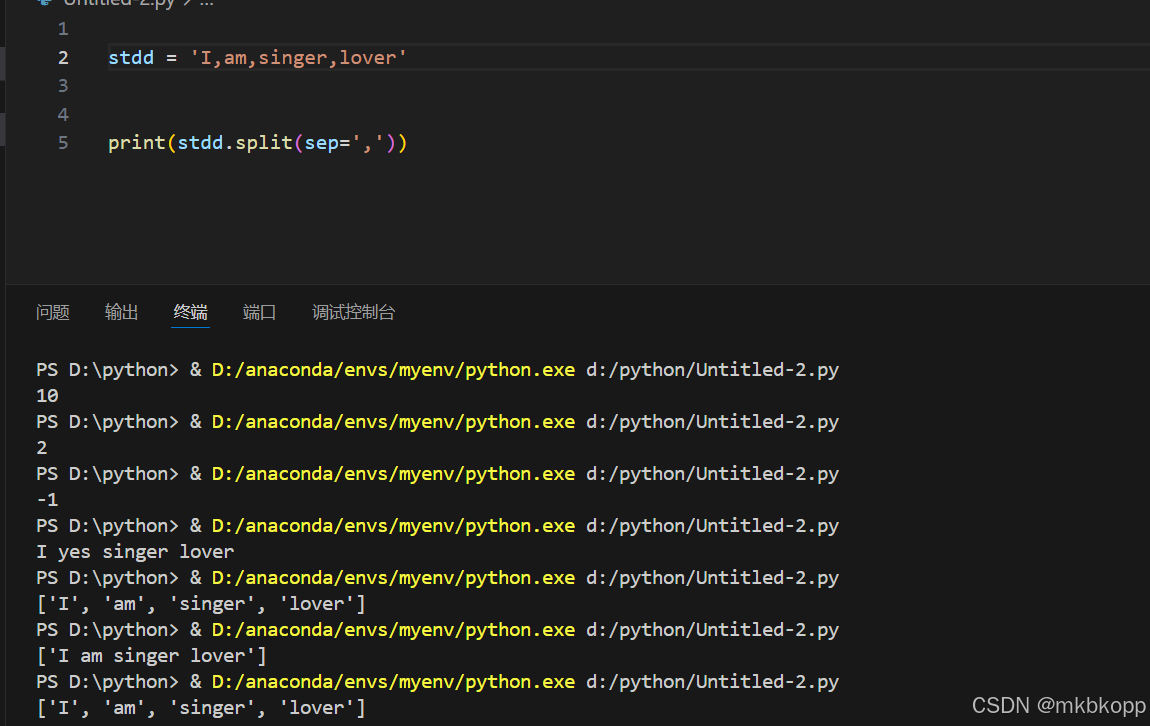
.strip() 去头尾字符(空白)
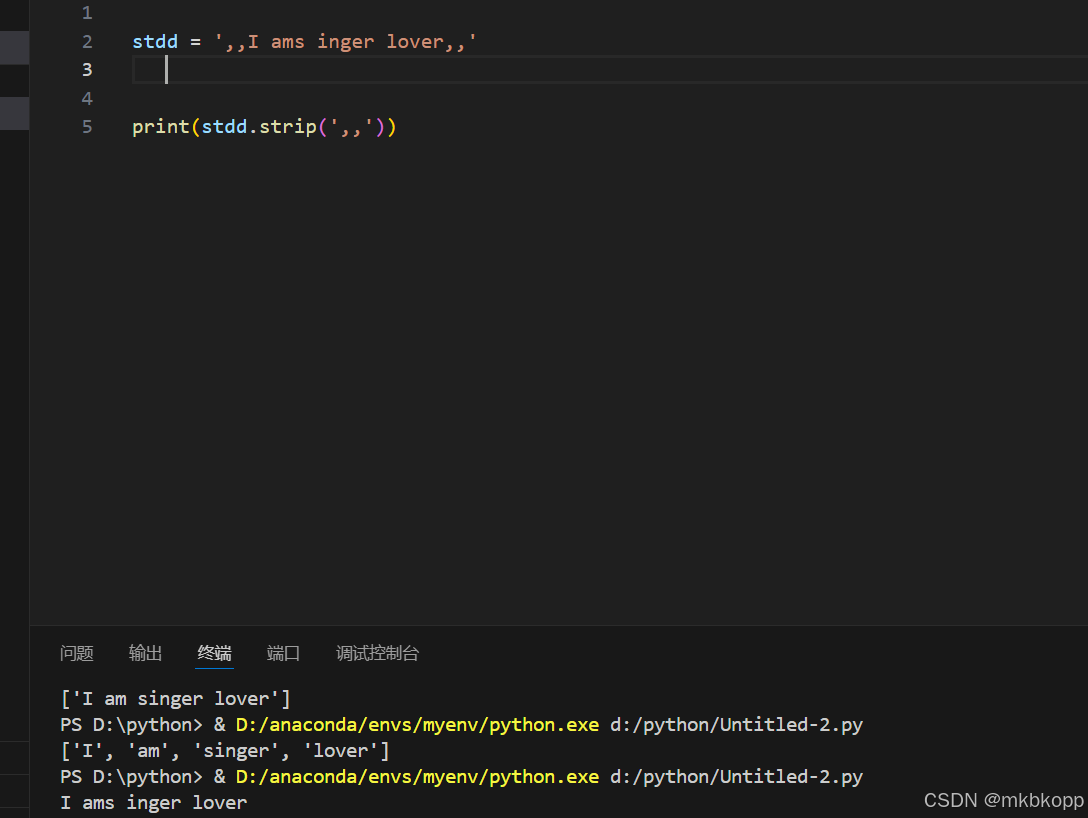
lower upper 大小写转换(字母字符串)
.startswith(prefix,start,end) 检查前缀
.endswith() 检查后缀
.isupper() 检查大写
.islower
列表&元组
定义列表
li = [1,2,2,3,4] 元素不限
访问 列表 li[0] 从左往右,下标从0开始 从右往左,下标从-1开始
切片:[ : : ]
遍历:for循环 for i in li
添加
.append()
.extend()<可迭代对象>(逐个添加)
插入
.insert(index:,object:) 索引插入(无索引加到末尾)
修改
li[index] = value 直接赋值
查找
元素 (not)in list (整体判断)返回bool
.index(value,start,stop) 返回索引
.count() 统计
删除
del list[index]
remove(value) 移除第一匹配成功的元素
排序
.sort(key,reverse(T=升序,F=降序))
.reverse()反转列表
列表推导式
li = [i(表达数据可运算) for i(取出元素) range(1,10)(可) if condition]
嵌套列表
li = [1,2,[3,4,5]]
元组
(小括号)
class,tuple 数值类型不限
元组只有一个元素时,要加逗号
访问(索引)
tup[0]
切片
tup[ : : ]
遍历
for i in tup:
只能查询
元素 in tup (返回bool)
.index(index) 索引查找
.count(元素) 计数
.len(object) 获取长度 <公共函数> 容器类型对象
字典&集合
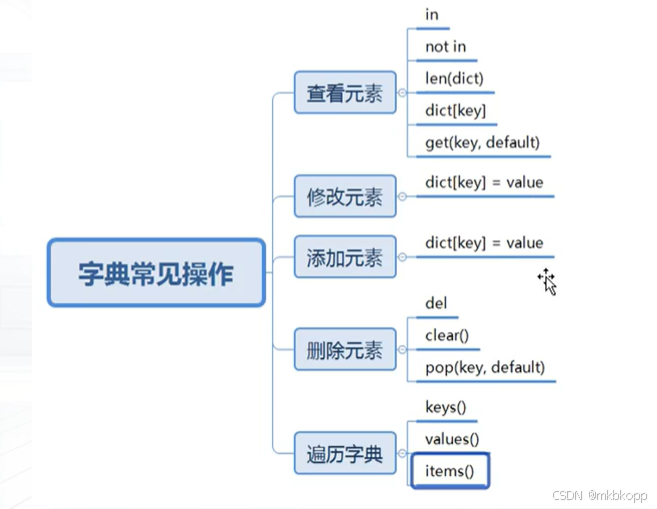
字典
(存储键值对){} 键唯一(重复的话,会被后面的键值对覆盖),值可重复
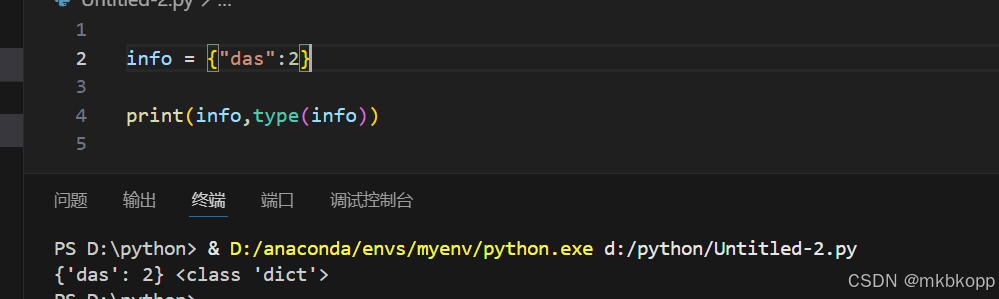
查询:in (键)
获取数量:.len()
获取值:dict[key]、get[key,default(不存在键而设置的返回值)]
修改和添加(根据存在与否)
删除:del dict[key]、.clear()<清空所有的键值对>、
.pop(key,default(不存在键而设置的返回值))<删除键值对并返回值>
遍历:.keys() --> 包含所有键的视图对象 .values() --> 包含所有值的视图对象
.item() --> 包含所有键值对的视图对象 保存在元组中


集合
(无序,不重复,集合中的元素必须为可哈希)
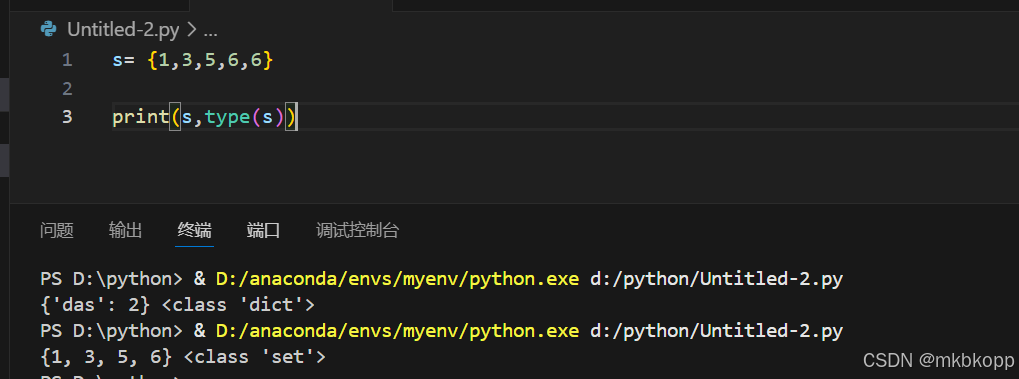
定义空集合:
空的花括号为dict类型 应该用set()创建空集合

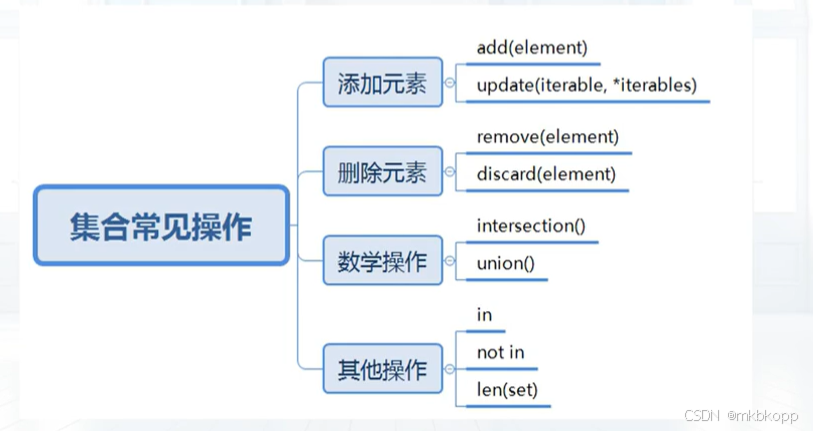
添加:.add()<添加已存在元素对原来集合无影响>、
.update(iterable<可迭代对象>,*iterable)<添加一个或多个>
删除:.remove(element)<删除不存在的元素会报错>、discard(element)
数学操作:
交集:&、.intersection(s1,s2...)
并集:|、.union()

类型转换
int():转换为整型 要求:浮点型(去小数部分)、布尔型(1,0)、字符串(可以有负号数字字符)、
float():转换为浮点型
bool():转换为布尔型 要求:False、none、。。。、非0非空为true
str():转换为字符串 要求:几乎都可以
eval():执行表达式(字符串中的python代码并返回结果)
list():转换为列表 要求:可迭代对象 注意:字典要用对应的方法取键值
tuple():转换为元组 要求:和list()差不多
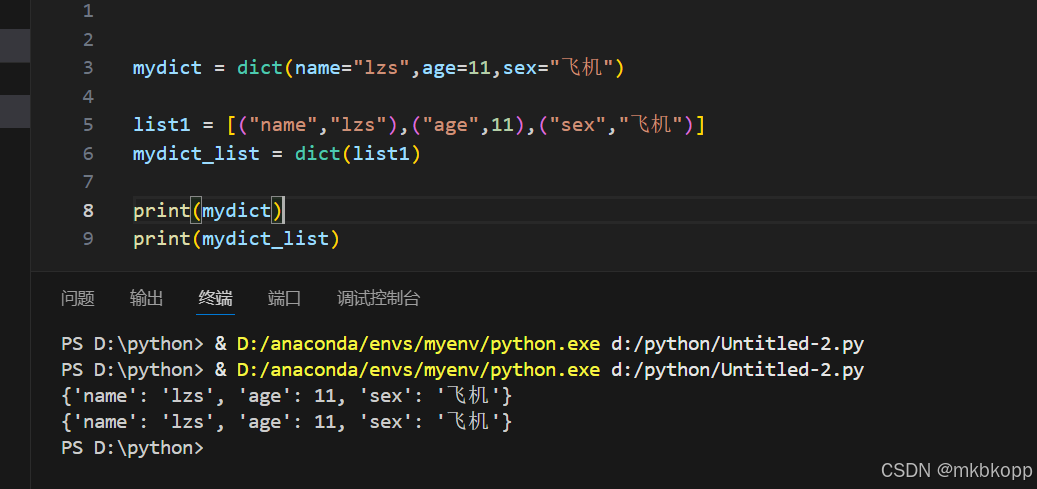
dict(): 要求:关键字参数、。。内部尽量用元组
set():转换为集合 要求:可迭代对象
深浅拷贝
id():内存地址

浅拷贝:嵌套层(内层对象)的内存地址相同,不可变类型(原对象)的地址相同。

深拷贝:与原对象完全独立,创建新的对象,递归的复制原对象。不可变类型(原对象)的地址相同
![]()
可变类型
内容变化,地址不变
列表、字典、集合都是可变类型。
不可变类型
存储空间保存的数据不允许修改(重新定义变量,开辟新的内存空间)
int、float、str、bool、元组(直接赋值)
函数基础
函数
封装的代码块,允许在任何时候调用,可重复使用
提高编程效率和代码复用,减少冗余
定义函数:
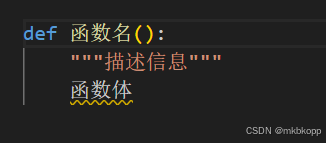
调用:
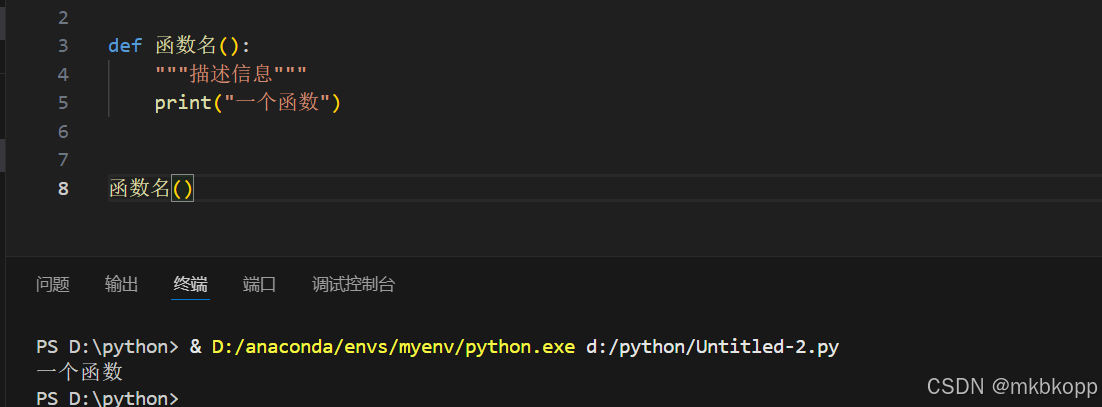
先定义后调用:python代码从上往下执行
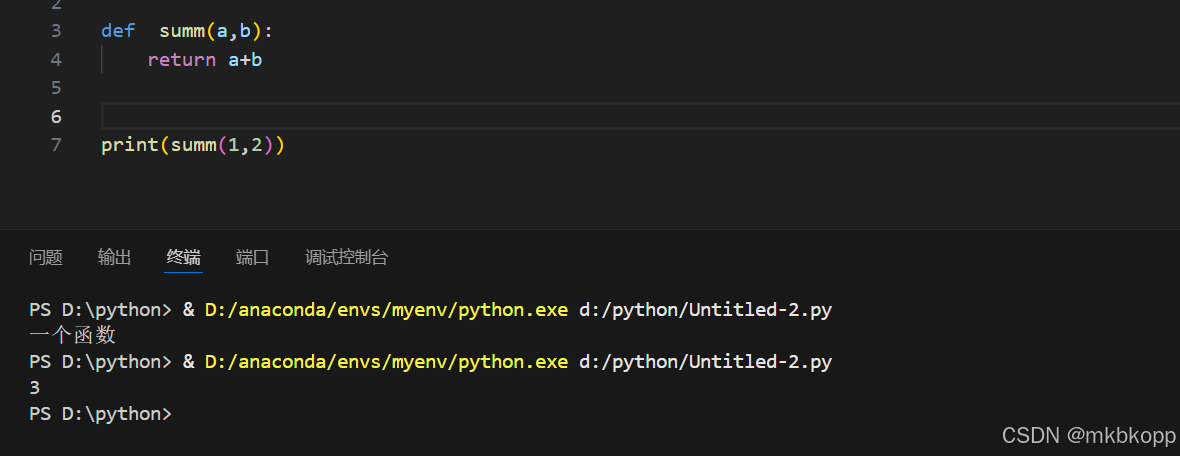
返回值
函数执行完成后,向调用者提供最终数据(无返回值,则隐式返回None)
多个返回值允许用元组的形式
参数
形参(参数名称)和实参(实际参数值)
位置参数:调用函数时传入实际参数的数量和位置都必须和定义函数时保持一致。
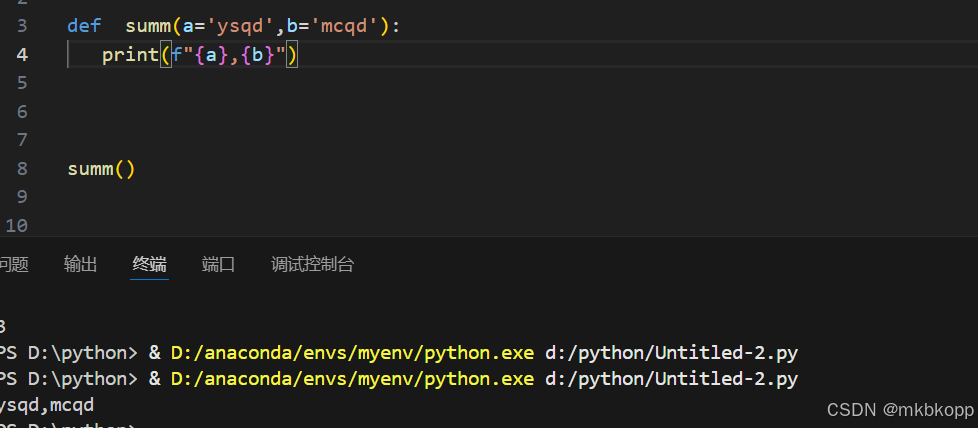
缺省(默认)参数:定义函数时,为形参提供默认值,默认参数必须在最右端。 调用函数的时候如果没有传入实参,则取默认参数。如果传入实参,则取实参。
可变参数
- *args参数:可接受任意个位置参数,当函数调用时,所有未使用(未匹配)的位置参数会在函数内自动组装进一个tuple对象中,此tuple对象会赋值给变量名args。
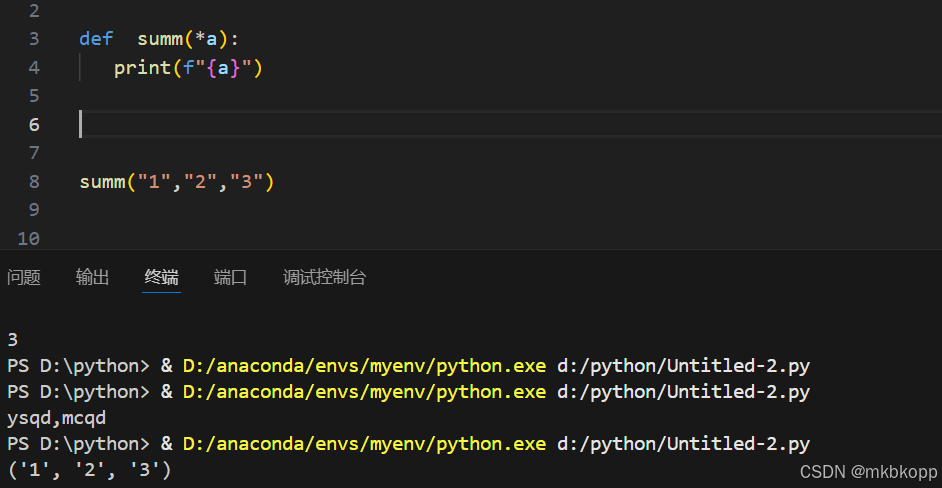
关键字参数
- **kwargs参数:可接受任意个关键字参数,当函数调用时,所有未使用(未匹配)的关键字参数会在函数内组装进一个dict对象中,此dict对象会赋值给变量名kwargs。
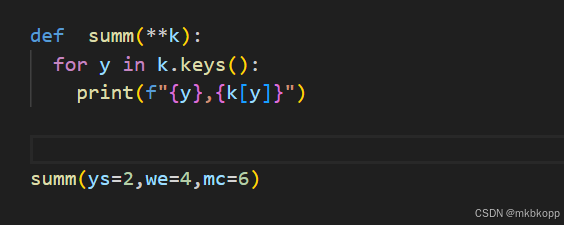
变量作用域
局部变量(在局部作用域中定义)
全局变量(在全局作用域中定义)
注意:如果局部变量和全局变量命名相同,局部变量会覆盖掉全局变量,但在外部不变。
global关键字(声明):在局部修改全局变量、在局部声明全局变量
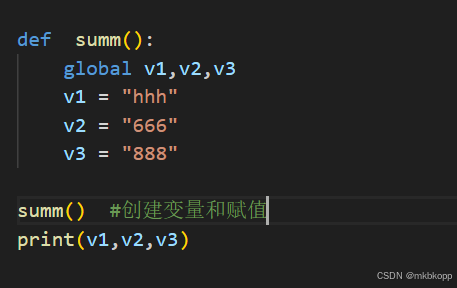
nolocal关键字: 内层函数修改外层函数(上一层)的值。
异常
在程序运行过程中,当Python检测到一个错误时,解释器将无法继续执行后续代码,并显示相应的错误提示信息,这种情况被称为异常。
Taceback
异常处理(捕获异常)
try-except(类型)
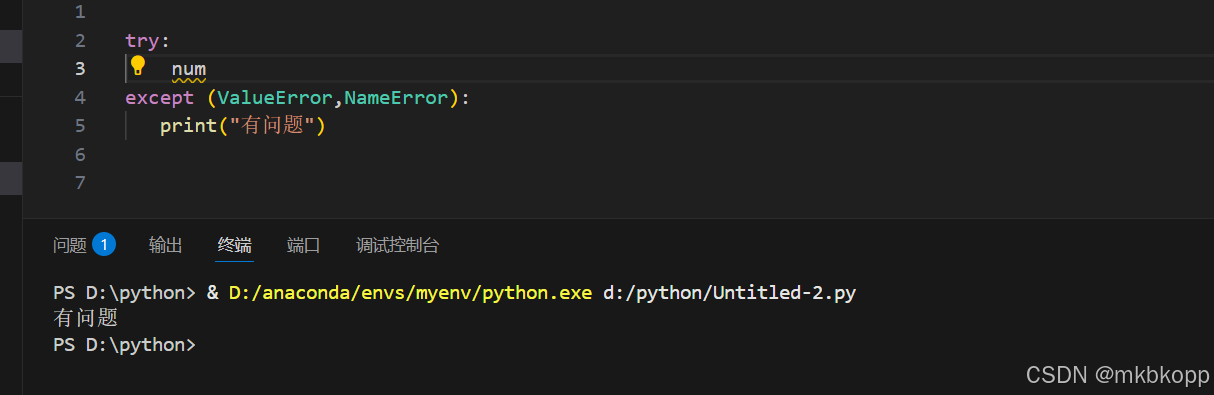
Exception as e :捕获程序中发生的任意非语法错误的类型并保存在变量e中。
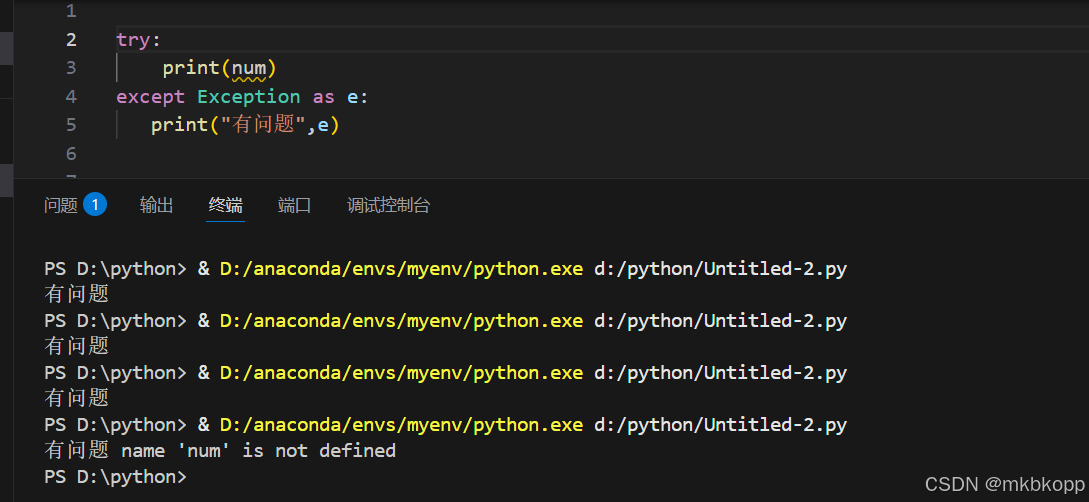
try-except-else-finally:
(无异常后执行)else:
(无论是否有异常都会执行)finally:
try-finally:(也有这样的结构)
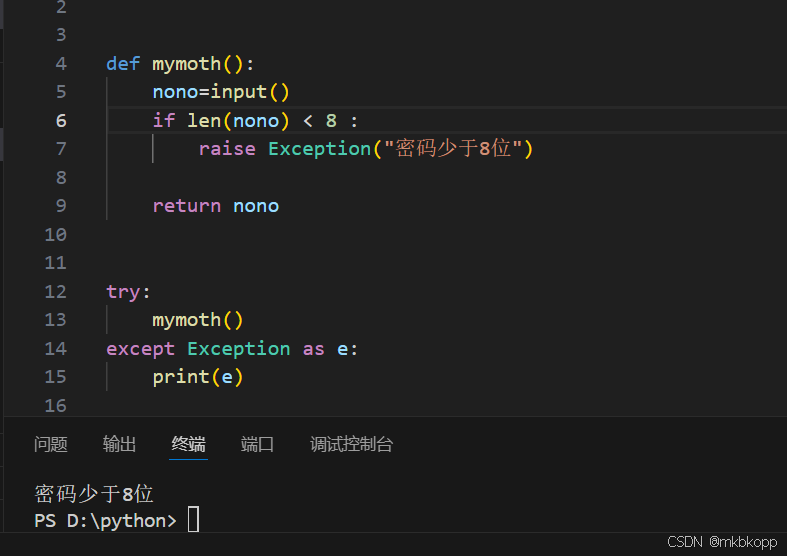
自定义异常:
raise 异常类型(信息)
模块
(可维护,可重用)
导入模块 import (模块)<as 别名>
使用时要加前缀:模块名.功能名()
from 模块名 import 功能名(*):不用前缀了,确保不重名
内置模块()
第三方模块
pip install 模块名 (cmd)
自定义模块(命名规范)
以主程序方式执行
_name_ = "_main_"
_name_ :
它可以标识模块的名字,可以显示一个模块的某功能是被自己执行还是被别的文件调用执行,假设模块A、B,模块A自己定义了功能C,模块B调用模块A,现在功能C被执行了:
如果C被A自己执行,也就是说模块执行了自己定义的功能,那么 __name__=='__main__'
如果C被B调用执行,也就是说当前模块调用执行了别的模块的功能,那么__name__=='A'(被调用模块的名字)
包
它的目的是为了组织和封装多个模块,以便更方便地进行模块化管理和使用。
导包:
import 包名(.模块名)(.功能名)
_init_.py:创建包后会出现的文件。
_all_ =[模块名,模块名,] :允许使用from 包名 import * 在_init_.py中编写

















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









