






 聚焦人工智能,它正引领时代前行。在人工智能领域,大模型训练服务器以卓越实力,担当着推动人工智能持续创新的关键角色。深入探寻人工智能奥秘,我们不难发现,智能应用背后离不开庞大复杂的模型训练。大模型训练服务器就如同幕后功臣,为人工智能发展注入动力。
聚焦人工智能,它正引领时代前行。在人工智能领域,大模型训练服务器以卓越实力,担当着推动人工智能持续创新的关键角色。深入探寻人工智能奥秘,我们不难发现,智能应用背后离不开庞大复杂的模型训练。大模型训练服务器就如同幕后功臣,为人工智能发展注入动力。
那么,具备哪些条件的服务器才能被称为大模型服务器呢?众多大模型训练服务器中,我们又该如何做出明智之选呢?
计算能力上,需更强的处理器性能。如英特尔至强、AMD EPYC 等服务器级处理器,凭借其多核心优势,能够并行处理复杂的计算任务与大规模数据。与此同时,GPU 的作用至关重要,像 NVIDIA 的 A100、H100 等高端产品,能够极大地加速模型训练和推理进程。
存储性能上,由于大模型参数众多且训练数据极为庞大,所以需要配备大容量的存储设备,例如硬盘或固态硬盘。在一些大规模图像识别模型中,训练数据甚至可达数百 TB 乃至 PB 级别。并且,存储设备的读写速度必须要高,高速的 SSD 或 NVMe 固态硬盘能够有效减少延迟,从而加快模型的训练和推理速度。
网络性能上,大模型训练往往涉及多服务器的数据传输和分布式计算,因此需要高速的网络连接。高带宽的网络接口能够满足大规模数据并行处理的需求。对于那些对实时性要求较高的应用来说,低延迟的网络至关重要。
能源效率上,源效率而言,随着大模型服务器规模的不断扩大,能耗问题日益凸显。提高能源效率、降低功耗,不仅可以降低成本,还能减少对环境的影响。可采用先进的芯片制造工艺以及优化电源管理策略。由于高功耗会产生大量热量,所以液冷等先进散热方式能够保证服务器稳定运行。
综上所述这里也做了2套大模型训练服务器配置,如下:
4卡 GPU大模型服务器,配置细节方面堪称卓越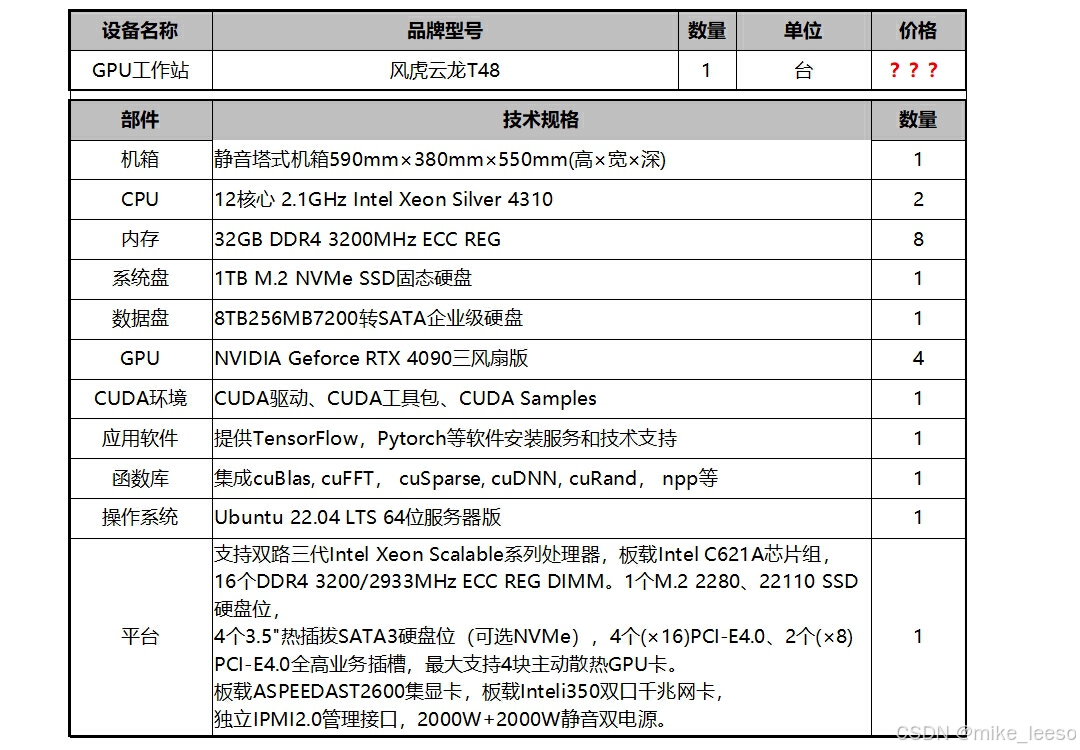
静音塔式机箱设计,尺寸达 590mmx380mmx550mm,运行时可营造安静的环境,适合对噪音较为敏感的使用场景。
搭载了 2 个 12 核心 2.1GHz 的 Intel Xeon Silver4310 CPU,能够为大模型训练赋予强大的算力支撑。
8 个 32GB DDR4 3200MHz ECC REG 内存,有力地确保了数据处理的高效和稳定。
1 个 1TB 的 M.2 NVMe SSD 固态硬盘用作系统盘,1 个 8TB 256MB 7200 转 SATA 企业级硬盘充当数据盘,为大模型训练供应了充裕的存储空间。尤为引人注目的是,它装配了 4 个 NVIDIA Geforce RTX 4090 三风扇版 GPU,极大地增强了图形处理和计算的速度,使其在诸如人工智能图像识别、自然语言处理模型训练等领域能够大显身手。

拥有完备的 CUDA 环境、丰富多样的应用软件,如 TensorFlow、Pytorch 等,能够满足不同类型的模型训练需求,还有强大实用的函数库以及稳定可靠的 Ubuntu 22.04 LTS 64 位服务器版操作系统。其平台支持双路三代 Intel Xeon Scalable 系列处理器等,为大模型训练的高效顺畅运行筑牢了坚实基础。
8卡 GPU大模型服务器配置更是非同凡响。
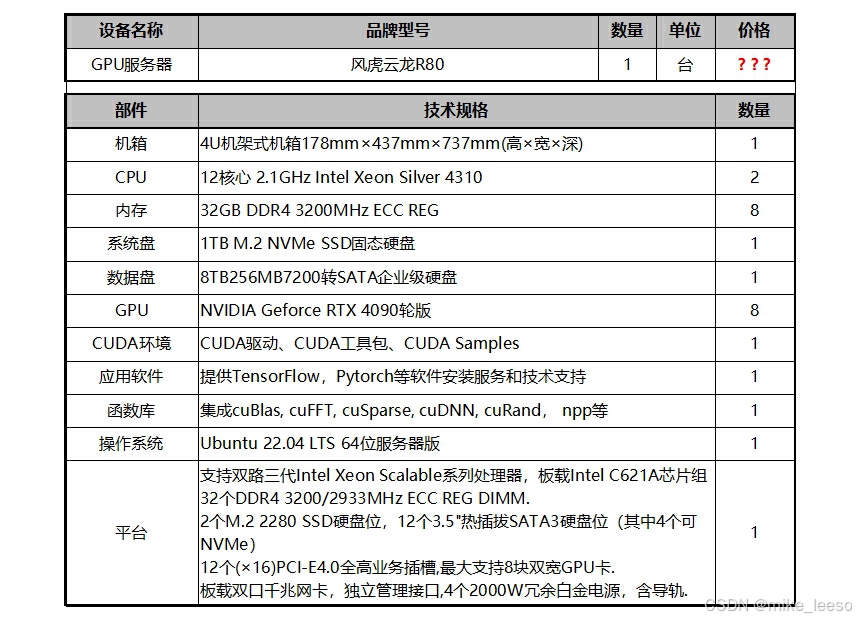
机箱为 4U 机架式,尺寸为 178mmx437mmx737mm,这种紧凑的设计便于在机房中进行集中部署。
同样搭载了 2 个 12 核心 2.1GHz 的 Intel Xeon Silver 4310 CPU。
内存配置上,同样是 8 个 32GB DDR4 3200MHz ECC REG 。系统盘和数据盘的配置与 四卡机型一致。
其显著的特色在于拥有 8 个 NVIDIA Geforce RTX 4090 涡轮版 GPU,图形处理能力更显强劲,能够轻松应对大规模数据的深度学习训练任务,适用于复杂的金融风险预测模型训练或者大型的智能推荐系统开发。
其他方面,如 CUDA 环境、应用软件,像 TensorFlow、Pytorch 等,函数库、操作系统等均配备齐全,平台支持双路三代 Intel Xeon Scalable 系列处理器等,并且还配备了 4 个 2000W 冗余白金电源以及导轨,有力地保障了服务器稳定持久地运行。

不论是 4 卡机型(风虎云龙 T48)还是 8 卡机型(风虎云龙 R80),都已经能够充分满足大家在大模型训练中的多样化需求。不管是科研机构致力于探索未知的前沿研究,还是企业谋求创新突破的智能化业务拓展,它们都能带来高效便捷的体验。
在科研领域,其强大的计算能力和充足的存储能够处理海量的数据,助力科学家们在基因分析、气候模拟等复杂课题中取得突破性的进展。对于企业而言,无论是优化生产流程的预测模型训练,还是提升客户体验的个性化推荐系统开发,这两款机型都能凭借出色的性能和稳定的运行,为企业节省时间和成本,提高市场竞争力。
它们所具备的完善的软件和硬件配置,就像是为您精心打造的一把利剑,助您在大模型训练的道路上披荆斩棘,勇往直前!

















 653
653

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









