




一、概述
2024 年对 YOLO 而言是具有里程碑意义的一年。这一年,YOLO 系列在 9 月的最后一天推出了其年度第三部重磅之作。2024 年 2 月 21 日,距离 2023 年 1 月 YOLOv8 正式发布已过去一年有余,YOLOv9 终于问世。YOLOv9 创新性地提出了可编程梯度信息(Programmable Gradient Information,PGI)的概念。借助 PGI,模型能够获取完整信息,使得从头开始训练的模型,性能超越了基于大型数据集预训练的 SOTA 模型。同时,通过引入多级辅助网络分支和通用高效层聚合网络(Generalized Efficient Layer Aggregation Network,GELAN),YOLOv9 显著提升了 YOLO 检测器的信息提取能力。
随后,在 2024 年 5 月 25 日,清华大学研究团队发布了 YOLO 系列的最新版本 ——YOLOV10。该版本通过紧凑的倒置瓶颈层(Compact Inverted Bottleneck,CIB)和有效的部分自注意力(Partial Self-attention,PSA)模块增强了模型能力,实现了更高效率与精度的实时目标检测。此外,用于无 NMS 训练的一致双重分配策略,大幅降低了计算开销。最终,在 2024 年 9 月 30 日,YOLO11 震撼登场,再次吸引了学界和业界的广泛关注。
二、 YOLO11
YOLO11 是 Ultralytics 推出的 YOLO 系列的最新版本。YOLO11 拥有超轻量级的模型,比之前的 YOLO 模型更快、更高效。YOLO11 能够处理更广泛的计算机视觉任务。Ultralytics 根据模型大小发布了五款 YOLO11 模型,涵盖所有任务的模型共有 25 款:
- YOLO11n:纳米级,适用于小型和轻量级任务。
- YOLO11s:在纳米级基础上进行了小幅升级,提高了一定的准确性。
- YOLO11m:中等规模,适用于通用用途。
- YOLO11l:大型,在更高的计算量下实现更高的准确性。
- YOLO11x:超大型,实现最高的准确性和性能。
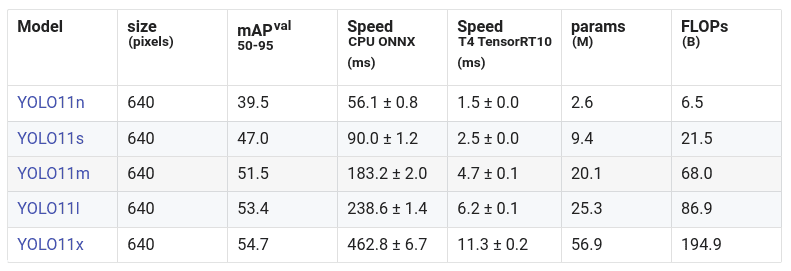
YOLO11 基于 Ultralytics YOLOv8 的代码库构建,并进行了一些架构修改。它还集成了之前 YOLO 版本(如 YOLOv9 和 YOLOv10)的新特性(并对这些特性进行了优化),以提升性能。
三、 YOLO11 的应用
YOLO 主要以其目标检测模型而闻名。然而,和 YOLOv8 一样,YOLO11 可以执行多种计算机视觉任务,包括:
- 目标检测
- 实例分割
- 图像分类
- 姿态估计
- 旋转目标检测(OBB)
3.1 目标检测
YOLO11 通过将输入图像传入卷积神经网络(CNN)来提取特征,从而进行目标检测。然后,网络预测网格内目标的边界框和类别概率。为了处理多尺度检测,模型使用不同的层来确保能够检测到各种大小的目标。这些预测结果随后通过非极大值抑制(NMS)进行优化,以过滤掉重复或低置信度的边界框,从而实现更准确的目标检测。YOLO11 在目标检测任务上使用 MS - COCO 数据集进行训练,该数据集包含 80 个预训练类别。

3.2 实例分割
除了目标检测,YOLO11 还通过添加掩码预测分支扩展到了实例分割任务。这些模型同样在 MS - COCO 数据集上进行训练,包含 80 个预训练类别。该分支为每个检测到的目标生成逐像素的分割掩码,使模型能够区分重叠的目标,并精确描绘出它们的形状轮廓。头部的掩码分支处理特征图并输出目标掩码,从而在图像中实现像素级的目标识别和区分。

3.3 姿态估计
YOLO11 通过检测和预测目标上的关键点(如人体关节)来进行姿态估计。这些关键点连接起来形成骨骼结构,代表目标的姿态。这些模型在 COCO 数据集上进行训练,该数据集包含一个预训练类别“人”。在头部添加了姿态估计层,网络经过训练来预测关键点的坐标。后续的后处理步骤将这些点连接起来形成骨骼结构,实现实时姿态识别。

1.鼻子
2.左眼
3.右眼
4.左耳
5.右耳
6.左肩
7.右肩
8.左肘
9.右肘
10.左腕
11.右手腕
12.左髋关节
13.右髋关节
14.左膝
15.右膝盖
16.左脚踝
17.右脚踝
3.5 图像分类
对于图像分类任务,YOLO11 使用其深度神经网络从输入图像中提取高级特征,并将其分配到几个预定义的类别之一。这些模型在 ImageNet 数据集上进行训练,该数据集包含 1000 个预训练类别。网络通过多层卷积和池化处理图像,在降低空间维度的同时增强重要特征。网络顶部的分类头输出预测类别,使其适用于需要识别图像整体类别的任务。

3.6 旋转目标检测(OBB)
YOLO11 通过引入旋转目标检测(OBB)扩展了常规的目标检测功能,使模型能够检测和分类旋转或不规则方向的目标。这在航空图像分析等应用中特别有用。这些模型在 DOTAv1 数据集上进行训练,该数据集包含 15 个预训练类别。
OBB 模型不仅输出边界框的坐标,还输出旋转角度(θ)或四个角点。这些坐标用于创建与目标方向对齐的边界框,提高旋转目标的检测准确性。

四、YOLO11 架构及新特性
YOLO11 架构是在 YOLOv8 架构基础上的升级,进行了一些新的集成和参数调整。YOLO11 的配置文件:
# 参数
nc: 80 # 类别数量
scales: # 模型复合缩放常数,即 'model=yolo11n.yaml' 将调用 yolo11.yaml 并使用缩放 'n'
# [深度, 宽度, 最大通道数]
n: [0.50, 0.25, 1024] # 总结: 319 层, 2624080 个参数, 2624064 个梯度, 6.6 GFLOPs
s: [0.50, 0.50, 1024] # 总结: 319 层, 9458752 个参数, 9458736 个梯度, 21.7 GFLOPs
m: [0.50, 1.00, 512] # 总结: 409 层, 20114688 个参数, 20114672 个梯度, 68.5 GFLOPs
l: [1.00, 1.00, 512] # 总结: 631 层, 25372160 个参数, 25372144 个梯度, 87.6 GFLOPs
x: [1.00, 1.50, 512] # 总结: 631 层, 56966176 个参数, 56966160 个梯度, 196.0 GFLOPs
# YOLO11n 主干网络
backbone:
# [来源, 重复次数, 模块, 参数]
- [-1, 1, Conv, [64, 3, 2]] # 0 - P1/2
- [-1, 1, Conv, [128, 3, 2]] # 1 - P2/4
- [-1, 2, C3k2, [256, False, 0.25]]
- [-1, 1, Conv, [256, 3, 2]] # 3 - P3/8
- [-1, 2, C3k2, [512, False, 0.25]]
- [-1, 1, Conv, [512, 3, 2]] # 5 - P4/16
- [-1, 2, C3k2, [512, True]]
- [-1, 1, Conv, [1024, 3, 2]] # 7 - P5/32
- [-1, 2, C3k2, [1024, True]]
- [-1, 1, SPPF, [1024, 5]] # 9
- [-1, 2, C2PSA, [1024]] # 10
# YOLO11n 头部网络
head:
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [[-1, 6], 1, Concat, [1]] # 拼接主干网络的 P4
- [-1, 2, C3k2, [512, False]] # 13
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [[-1, 4], 1, Concat, [1]] # 拼接主干网络的 P3
- [-1, 2, C3k2, [256, False]] # 16 (P3/8 - 小尺度)
- [-1, 1, Conv, [256, 3, 2]]
- [[-1, 13], 1, Concat, [1]] # 拼接头部的 P4
- [-1, 2, C3k2, [512, False]] # 19 (P4/16 - 中尺度)
- [-1, 1, Conv, [512, 3, 2]]
- [[-1, 10], 1, Concat, [1]] # 拼接头部的 P5
- [-1, 2, C3k2, [1024, True]] # 22 (P5/32 - 大尺度)
- [[16, 19, 22], 1, Detect, [nc]] # 检测层 (P3, P4, P5)
4.1 主干网络(Backbone)
主干网络是模型从输入图像中多尺度提取特征的部分。它通常通过堆叠卷积层和模块来创建不同分辨率的特征图。
- 卷积层(Conv Layers):YOLO11 具有类似的初始卷积层结构,用于对图像进行下采样:
- [-1, 1, Conv, [64, 3, 2]] # 0 - P1/2
- [-1, 1, Conv, [128, 3, 2]] # 1 - P2/4
- **C3k2 模块**:与 YOLOv8 中的 C2f 模块不同,YOLO11 引入了 C3k2 模块,它在计算效率上更高。该模块是 CSP 瓶颈的自定义实现,使用两个卷积层代替一个大的卷积层(如 YOLOv8 中那样)。
- **CSP(跨阶段部分连接)**:CSP 网络将特征图分割,一部分通过瓶颈层处理,另一部分与瓶颈层的输出合并。这减少了计算量并提高了特征表示能力。
- [-1, 2, C3k2, [256, False, 0.25]]
- C3k2 模块还使用了较小的核大小(由 k2 表示),在保持性能的同时提高了速度。
- **SPPF 和 C2PSA**:YOLO11 保留了 SPPF 模块,并在 SPPF 之后添加了新的 C2PSA 模块:
- [-1, 1, SPPF, [1024, 5]]
- [-1, 2, C2PSA, [1024]]
- C2PSA(带空间注意力的跨阶段部分连接)模块增强了特征图中的空间注意力,使模型能够更有效地关注图像中的重要部分。通过对特征进行空间池化,该模块让模型能够更有针对性地聚焦于感兴趣的特定区域。
4.2 颈部网络(Neck)
颈部网络负责聚合不同分辨率的特征,并将其传递给头部进行预测。它通常涉及对不同层次的特征图进行上采样和拼接操作。
- C3k2 模块:YOLO11 用 C3k2 模块取代了颈部网络中的 C2f 模块。如前所述,C3k2 是一个更快、更高效的模块。例如,在进行上采样和拼接操作后,YOLO11 中的颈部网络结构如下:
- [-1, 2, C3k2, [512, False]] # P4/16 - 中尺度
- 这一改变提高了特征聚合过程的速度和性能。
- **注意力机制**:YOLO11 通过 C2PSA 模块更加注重空间注意力,这有助于模型聚焦于图像中的关键区域,从而实现更准确的检测。而 YOLOv8 中缺少这一机制,这使得 YOLO11 在检测较小或被遮挡的目标时可能更加准确。
4.3 头部网络(Head)
头部网络是模型负责生成最终预测结果的部分。在目标检测任务中,这通常意味着生成边界框并对框内的目标进行分类。
- C3k2 模块:与颈部网络类似,YOLO11 用 C3k2 模块取代了头部网络中的 C2f 模块。
- [-1, 2, C3k2, [512, False]] # P4/16 - 中尺度
- **检测层(Detect Layer)**:最终的检测层与 YOLOv8 中的相同:
- [[16, 19, 22], 1, Detect, [nc]] # 检测层 (P3, P4, P5)
- 使用 C3k2 模块使模型在推理速度上更快,并且在参数使用上更加高效。
看看这些新模块(层)在代码中的实现:
C3k2 模块(来自 blocks.py):C3k2 是 CSP 瓶颈的一个更快、更高效的变体。它使用两个卷积层代替一个大的卷积层,从而加快了特征提取的速度。
class C3k2(C2f):
def __init__(self, c1, c2, n=1, c3k=False, e=0.5, g=1, shortcut=True):
super().__init__(c1, c2, n, shortcut, g, e)
self.m = nn.ModuleList(
C3k(self.c, self.c, 2, shortcut, g) if c3k else Bottleneck(self.c, self.c, shortcut, g) for _ in range(n)
)
C3k 模块(来自 blocks.py):C3k 是一个更灵活的瓶颈模块,允许自定义核大小。这对于提取图像中更详细的特征非常有用。
class C3k(C3):
def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5, k=3):
super().__init__(c1, c2, n, shortcut, g, e)
c_ = int(c```python
# 计算隐藏通道数
c_ = int(c2 * e)
# 构建包含一系列瓶颈层的序列
self.m = nn.Sequential(*(Bottleneck(c_, c_, shortcut, g, k=(k, k), e=1.0) for _ in range(n)))
C2PSA 模块(来自 blocks.py):C2PSA(具有空间注意力的跨阶段部分模块)增强了模型的空间注意力能力。该模块为特征图添加注意力机制,帮助模型聚焦于图像的重要区域。
class C2PSA(nn.Module):
def __init__(self, c1, c2, e=0.5):
super().__init__()
# 计算隐藏通道数
c_ = int(c2 * e)
# 定义 1x1 卷积层 cv1
self.cv1 = Conv(c1, c_, 1, 1)
# 定义 1x1 卷积层 cv2
self.cv2 = Conv(c1, c_, 1, 1)
# 定义 1x1 卷积层 cv3,用于调整通道数
self.cv3 = Conv(2 * c_, c2, 1)
def forward(self, x):
# 对输入特征图 x 进行处理,先通过 cv1 和 cv2 卷积,然后在通道维度上拼接,最后通过 cv3 卷积
return self.cv3(torch.cat((self.cv1(x), self.cv2(x)), 1))
五、 YOLO11 代码流程
在 ultralytics GitHub 仓库中,主要关注以下内容:
nn/modules/中的模块block.pyconv.pyhead.pytransformer.pyutils.py
nn/tasks.py文件
5.1 代码库概述
代码库由多个模块组成,这些模块定义了 YOLO11 模型中使用的各种神经网络组件。这些组件被组织在 nn/modules/ 目录下的不同文件中:
block.py:定义了模型中使用的各种构建模块(如瓶颈层、CSP 模块和注意力机制等)。conv.py:包含卷积模块,包括标准卷积、深度可分离卷积和其他变体。head.py:实现了模型的头部,负责生成最终的预测结果(如边界框、类别概率等)。transformer.py:包含基于变压器的模块,用于注意力机制和高级特征提取。utils.py:提供了在各个模块中使用的实用函数和辅助类。
nn/tasks.py 文件定义了不同的特定任务模型(如检测、分割、分类等),这些模型将上述模块组合在一起形成完整的架构。
5.2 nn/modules/ 中的模块
如前所述,YOLO11 基于 YOLOv8 代码库构建。因此,主要关注此处更新的脚本:block.py、conv.py 和 head.py。
block.py
此文件定义了 YOLO11 模型中使用的各种构建模块。这些模块是构成神经网络层的基本组件。
关键组件:瓶颈层模块(Bottleneck Modules)
- Bottleneck:一种标准的瓶颈模块,带有可选的快捷连接。
- Res:一个残差块,使用一系列卷积和恒等快捷连接。
class Bottleneck(nn.Module):
def __init__(self, c1, c2, shortcut=True, g=1, e=0.5):
super().__init__()
# 计算隐藏通道数
c_ = int(c2 * e)
# 定义 1x1 卷积层 cv1
self.cv1 = Conv(c1, c_, 1, 1)
# 定义 3x3 卷积层 cv2,用于调整通道数并增加特征维度
self.cv2 = Conv(c_, c2, 3, 1, g=g)
# 判断是否添加快捷连接
self.add = shortcut and c1 == c2
def forward(self, x):
# ### (续)
如果 `self.add` 为 `True`,则将原始输入 `x` 与经过 `cv1` 和 `cv2` 处理后的输出相加(残差连接);否则,仅返回经过 `cv1` 和 `cv2` 处理后的输出
```python
return x + self.cv2(self.cv1(x)) if self.add else self.cv2(self.cv1(x))
Bottleneck类实现了一个瓶颈模块,它先减少通道数(降维),然后再增加通道数。- 组件:
self.cv1:一个 1×1 卷积层,用于减少通道数。self.cv2:一个 3×3 卷积层,用于将通道数恢复到原始数量。self.add:一个布尔值,指示是否添加快捷连接。
- 前向传播:输入
x依次通过cv1和cv2。如果self.add为True,则将原始输入x与输出相加(残差连接)。
CSP(跨阶段部分)模块:
BottleneckCSP:瓶颈模块的 CSP 版本。CSPBlock:一个更复杂的 CSP 模块,包含多个瓶颈层。
class BottleneckCSP(nn.Module):
def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5):
super().__init__()
# 计算隐藏通道数
c_ = int(c2 * e)
# 定义 1x1 卷积层 cv1
self.cv1 = Conv(c1, c_, 1, 1)
# 定义包含多个瓶颈层的序列 cv2
self.cv2 = nn.Sequential(
*[Bottleneck(c_, c_, shortcut, g, e=1.0) for _ in range(n)]
)
# 定义 1x1 卷积层 cv3,用于调整通道数
self.cv3 = Conv(2 * c_, c2, 1)
# 判断是否添加快捷连接
self.add = c1 == c2
def forward(self, x):
# 对输入特征图 x 进行处理,先通过 cv1 卷积,再通过 cv2 中的一系列瓶颈层
y1 = self.cv2(self.cv1(x))
# 如果 self.add 为 True,则将原始输入 x 赋值给 y2,否则 y2 为 None
y2 = x if self.add else None
# 如果 y2 不为 None,则将 y1 和 y2 在通道维度上拼接,然后通过 cv3 卷积;否则,直接将 y1 通过 cv3 卷积
return self.cv3(torch.cat((y1, y2), 1)) if y2 is not None else self.cv3(y1)
CSPBottleneck模块将特征图分为两部分。一部分通过一系列瓶颈层,另一部分直接连接到输出,从而降低计算成本并增强梯度流。- 组件:
self.cv1:减少通道数。self.cv2:一系列瓶颈层。self.cv3:合并特征并调整通道数。self.add:确定是否添加快捷连接。
其他模块:
SPPF:快速空间金字塔池化模块,可在多个尺度上进行池化操作。Concat:沿指定维度连接多个张量。
class SPPF(nn.Module):
def __init__(self, c1, c2, k=5):
super().__init__()
# 计算中间通道数
c_ = c1 // 2
# 定义 1x1 卷积层 cv1
self.cv1 = Conv(c1, c_, 1, 1)
# 定义 1x1 卷积层 cv2,用于调整通道数
self.cv2 = Conv(c_ * 4, c2, 1, 1)
# 定义最大池化层 m
self.m = nn.MaxPool2d(kernel_size=k, stride=1, padding=k // 2)
def forward(self, x):
# 对输入特征图 x 进行处理,先通过 cv1 卷积
x = self.cv1(x)
# 对 x 进行最大池化操作得到 y1
y1 = self.m(x)
# 对 y1 进行最大池化操作得到 y2
y2 = self.m(y1)
# 对 y2 进行最大池化操作得到 y3
y3 = self.m(y2)
# 将 x、y1、y2 和 y3 在通道维度上拼接,然后通过 cv2 卷积
return self.cv2(torch.cat([x, y1, y2, y3], 1))
SPPF模块在不同尺度上执行最大池化,并将结果连接起来,以捕获多个空间尺度的特征。- 组件:
self.cv1:减少通道数。self.cv2:在连接后调整通道数。self.m:最大池化层。
- 前向传播:输入
x先通过cv1,然后经过三个连续的最大池化层(y1、y2、y3)。结果被连接起来并通过cv2。
conv.py
此文件包含各种卷积模块,包括标准卷积和特殊卷积。
关键组件:标准卷积模块(Conv)
class Conv(nn.Module):
# 默认激活函数为 SiLU
default_act = nn.SiLU()
def __init__(self, c1, c2, k=1, s=1, p=None, g=1, d=1, act=True):
super().__init__()
# 定义卷积层 conv
self.conv = nn.Conv2d(c1, c2, k, s, autopad(k, p, d), groups=g, dilation=d, bias=False)
# 定义批量归一化层 bn
self.bn = nn.BatchNorm2d(c2)
# 根据 act 参数确定激活函数
self.act = self.default_act if act is True else act if isinstance(act, nn.Module) else nn.Identity()
def forward(self, x):
# 对输入特征图 x 进行处理,先通过 conv 卷积,再通过 bn 批量归一化,最后通过 act 激活函数
return self.act(self.bn(self.conv(x)))
- 实现一个带有批量归一化和激活函数的标准卷积层。
- 组件:
self.conv:卷积层。self.bn:批量归一化层。self.act:激活函数(默认是nn.SiLU())。
- 前向传播:依次进行卷积、批量归一化和激活操作。
深度可分离卷积(DWConv)
class DWConv(Conv):
def __init__(self, c1, c2, k=1, s=1, d=1, act=True):
super().__init__(c1, c2, k, s, g=math.gcd(c1, c2), d=d, act=act)
- 执行深度可分离卷积,其中每个输入通道单独进行卷积。
- 组件:
- 继承自
Conv。 - 将
groups参数设置为c1和c2的最大公约数,从而实现按通道分组卷积。
- 继承自
其他卷积模块:
Conv2:RepConv的简化版本,用于模型压缩和加速。GhostConv:实现 GhostNet 的幽灵模块,减少特征图中的冗余。RepConv:可重新参数化的卷积层,可从训练模式转换为推理模式。
head.py
此文件实现了负责生成模型最终预测结果的头部模块。
关键组件:检测头部(Detect)
class Detect(nn.Module):
def __init__(self, nc=80, ch=()):
super().__init__()
# 类别数量
self.nc = nc
# 检测层的数量
self.nl = len(ch)
# DFL 通道数
self.reg_max = 16
# 每个锚点的输出数量
self.no = nc + self.reg_max * 4
# 步长,在构建过程中计算
self.stride = torch.zeros(self.nl)
# 定义层
self.cv2 = nn.ModuleList(
nn.Sequential(Conv(x, c2, 3), Conv(c2, c2, 3), nn.Conv2d(c2, 4 * self.reg_max, 1)) for x in ch
)
self.cv3 = nn.ModuleList(
nn.Sequential(
nn.Sequential(DWConv(x, x, 3), Conv(x, c3, 1)),
nn.Sequential(DWConv(c3, c3, 3), Conv(c3, c3, 1)),
nn.Conv2d(c3, self.nc, 1),
)
for x in ch
)
# 如果 reg_max 大于 1,则使用 DFL 模块进行边界框细化;否则,使用恒等映射
self.dfl = DFL(self.reg_max) if self.reg_max > 1 else nn.Identity()
Detect类定义了输出边界框坐标和类别概率的检测头部。- 组件:
self.cv2:用于边界框回归的卷积层。self.cv3:用于分类的卷积层。self.dfl:用于边界框细化的分布焦点损失模块。
- 前向传播:处理输入特征图并输出边界框和类别的预测结果。
分割头部(Segment)
class Segment(Detect):
def __init__(self, nc=80, nm=32, npr=256, ch=()):
super().__init__(nc, ch)
# 掩码数量
self.nm = nm
# 原型数量
self.npr = npr
# 生成掩码原型的模块
self.proto = Proto(ch[0], self.npr, self.nm)
# 计算通道数 c4
c4 = max(ch[0] // 4, self.nm)
self.cv4 = nn.ModuleList(nn.Sequential(Conv(x, c4, 3), Conv(c4, c4, 3), nn.Conv2d(c4, self.nm, 1)) for x in ch)
- 继承自
Detect类,增加了分割功能。 - 组件:
self.proto:生成掩码原型。self.cv4:用于掩码系数的卷积层。
- 前向传播:输出边界框、类别概率和掩码系数。
姿态估计头部(Pose)
class Pose(Detect):
def __init__(self, nc=80, kpt_shape=(17, 3), ch=()):
super().__init__(nc, ch)
# 关键点形状(关键点数量,每个关键点的维度)
self.kpt_shape = kpt_shape
# 关键点输出的总数
self.nk = kpt_shape[0] * kpt_shape[1]
# 计算通道数 c4
c4 = max(ch[0] // 4, self.nk)
self.cv4 = nn.ModuleList(nn.Sequential(Conv(x, c4, 3), Conv(c4, c4, 3), nn.Conv2d(c4, self.nk, 1)) for x in ch)
- 继承自
Detect类,用于人体姿态估计任务。 - 组件:
self.kpt_shape:关键点的形状(关键点数量,每个关键点的维度)。self.cv4:用于关键点回归的卷积层。
- 前向传播:输出边界框、类别概率和关键点坐标。
5. 3. nn/tasks.py
nn/tasks.py 是执行所有 YOLO11 模型以完成计算机视觉任务的主代码,包括检测、分割、姿态估计和分类模型。
# 这是原始脚本的简化版本
class BaseModel(nn.Module):
# YOLOv8 模型的基础模型类
def forward(self, x, *args, **kwargs):
# 前向传播:处理训练(损失)和推理(预测)
if isinstance(x, dict):
return self.loss(x, *args, **kwargs) # 训练:计算损失
return self.predict(x, *args, **kwargs) # 推理:进行预测
class DetectionModel(BaseModel):
# YOLOv8 检测模型类
def __init__(self, cfg="yolov8n.yaml", ch=3, nc=None, verbose=True):
super().__init__()
# 模型设置(配置解析、层设置等)
self.yaml = cfg if isinstance(cfg, dict) else yaml_model_load(cfg)
self.model, self.save = parse_model(deepcopy(self.yaml), ch=ch, verbose=verbose)
# 步长和偏置初始化(为简洁起见省略细节)
m = self.model[-1]
if isinstance(m, Detect):
s = 256
m.stride = torch.tensor([s / x.shape[-2] for x in self._predict_once(torch.zeros(1, ch, s, s))])
self.stride = m.stride
m.bias_init()
class SegmentationModel(DetectionModel):
# YOLOv8 分割模型类
def __init__(self, cfg="yolov8n - seg.yaml", ch=3, nc=None, verbose=True):
super().__init__(cfg=cfg, ch=ch, nc=nc, verbose=verbose)
def init_criterion(self):
# 返回特定于分割的损失函数
return v8SegmentationLoss(self)
class PoseModel(DetectionModel):
# YOLOv8 姿态估计模型类
def __init__(self, cfg="yolov8n - pose.yaml", ch=3, nc=None, data_kpt_shape=(None, None), verbose=True):
if not isinstance(cfg, dict):
cfg = yaml_model_load(cfg)
if list(data_kpt_shape) != list(cfg["kpt_shape"]):
cfg["kpt_shape"] = data_kpt_shape
super().__init__(cfg=cfg, ch=ch, nc=nc, verbose=verbose)
def init_criterion(self):
# 返回特定于姿态估计的损失函数
return v8PoseLoss(self)
class ClassificationModel(BaseModel):
# YOLOv8 分类模型类
def __init__(self, cfg="yolov8n - cls.yaml", ch=3, nc=None, verbose=True):
super().__init__()
self._from_yaml(cfg, ch, nc, verbose)
def _from_yaml(self, cfg, ch, nc, verbose):
# 解析配置并设置模型层
self.yaml = cfg if isinstance(cfg, dict) else yaml_model_load(cfg)
self.model, self.save = parse_model(deepcopy(self.yaml), ch=ch, verbose=verbose)
self.names = {i: f"{i}" for i in range(self.yaml["nc"])}
class Ensemble(nn.ModuleList):
# 集成类,用于合并多个模型的输出
def __init__(self):
super().__init__()
def forward(self, x, augment=False, profile=False, visualize=False):
# 集成的前向传播,合并所有模型的输出
y = [module(x, augment, profile, visualize)[0] for module in self]
return torch.cat(y, 2), None
代码首先定义了 BaseModel 类,它作为所有模型的基础,其 forward 方法可处理训练(通过损失函数)和推理(通过预测函数)。DetectionModel 类继承自 BaseModel,专门用于目标检测,通过 fuse 方法实现步长初始化和层融合以提高效率。SegmentationModel 和 PoseModel 进一步继承自 DetectionModel,分别添加了分割和姿态估计任务的特定功能,并且各自初始化了像 v8SegmentationLoss 和 v8PoseLoss 这样的损失函数。ClassificationModel 处理分类任务,并根据类别数量(nc)重塑输出层。此外,还包含了 Ensemble 类,用于合并多个模型的输出。辅助函数如 parse_model、yaml_model_load 和 fuse_conv_and_bn 用于模型解析、配置加载和推理层优化。
六、YOLO11 推理
使用来自 Ultralytics GitHub 的 YOLO11 预训练权重进行推理实验。要进行推理,需要使用以下命令克隆 Ultralytics 仓库:
git clone https://github.com/ultralytics/ultralytics.git
cd ultralytics
然后,使用以下命令设置环境:
conda create -n yolo11 python=3.11
conda activate yolo11
pip install ultralytics
6.1 目标检测
目标检测:
yolo detect predict model=yolo11x.pt source='./path/to/your/video.mp4' save=True classes=[0]
6.2 实例分割
对于实例分割,运行以下命令:
yolo segment predict model=yolo11x.pt source='./path/to/your/video.mp4' save=True classes=[0]
6.3 姿态估计
对于姿态估计,运行:
yolo pose predict model=yolo11x-pose.pt source='./path/to/your/video.mp4' save=True classes=[0]
6.4 旋转目标检测(OBB)
运行以下命令:
yolo obb predict model=yolo11x-obb.pt source='./path/to/your/video.mp4' save=True
七、 YOLO11 与 YOLOv10 对比
从图表上看,似乎 YOLO11l 和 YOLO11x 比 YOLOv10 慢,而 YOLO11n 和 YOLOv10n 速度相同。那么,为什么不通过实际对比这两个模型来消除争议呢?
所以,将比较 YOLO11 和最新发布的 YOLOv10,并查看两者的性能基准。在 Nvidia Geforce RTX 4060 笔记本 GPU 上运行了所有推理。
首先,将比较 YOLOv10n(2.3M 参数)和 YOLO11n(2.6M 参数)模型在同一个视频上进行推理,并比较了延迟和帧率。以下是为你提供的基准测试结果:
- YOLOv11n
- 速度:预处理 1.4ms,推理 3.9ms,后处理 1.2ms(每张图像,形状为 (1, 3, 384, 640))
- FPS(推理):256
- YOLOv10n
- 速度:预处理 1.4ms,推理 4.5ms,后处理 0.4ms(每张图像,形状为 (1, 3, 384, 640))
- FPS(推理):222
现在,将比较 YOLOv10x(29.5M 参数)和 YOLO11x(56.9M 参数)。在同一个视频上进行推理,并比较了延迟和帧率。得到的基准测试结果如下:
- YOLOv11x
- 速度:预处理 1.4ms,推理 18.5ms,后处理 1.6ms(每张图像,形状为 (1, 3, 384, 640))
- FPS(推理):54
- YOLOv10x
- 速度:预处理 1.4ms,推理 16.8ms,后处理 0.6ms(每张图像,形状为 (1, 3,384, 640))
- FPS(推理):59
对于n模型,YOLO11 即使参数更多但表现更好。此外,和 YOLOv10 一样,Ultralytics 团队计划很快推出端到端模型。

八、总结
- 轻量高效:YOLO11 是 YOLO 家族中最轻量且最快的模型。它具有五种不同尺寸(微小、小型、中型、大型和超大型),适用于从轻量级任务到高性能应用的各种用例。
- 新架构:YOLO11 引入了如 C3k2 模块、SPPF 和 C2PSA 等新的架构改进,使模型在提取和处理特征方面更高效,并增强了对图像关键区域的关注。
- 多任务能力:除了目标检测,YOLO11 还能处理实例分割、图像分类、姿态估计和旋转目标检测(OBB),使其在计算机视觉任务中具有高度通用性。
- 增强的注意力机制:架构中像 C2PSA 这样的空间注意力机制的集成,帮助 YOLO11 更有效地聚焦于图像中的关键区域,提高了其检测准确性,特别是对于复杂或遮挡的物体。
- 基准优势:与 YOLOv10 直接比较,YOLO11 表现出更优越的性能,特别是在n模型系列中。尽管参数更多,但 YOLO11n 在推理速度和 FPS 方面优于 YOLOv10n,使其成为实时应用中高效的模型,且不牺牲准确性或计算效率。



















 4万+
4万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











