







作者:Ultralytics公司
代码:https://github.com/ultralytics/ultralytics
YOLO系列算法解读:
YOLOv1通俗易懂版解读、SSD算法解读、YOLOv2算法解读、YOLOv3算法解读、YOLOv4算法解读、YOLOv5算法解读、YOLOR算法解读、YOLOX算法解读、YOLOv6算法解读、YOLOv7算法解读、YOLOv8算法解读、YOLOv9算法解读、YOLOv10算法解读、YOLO11算法解读
PP-YOLO系列算法解读:
PP-YOLO算法解读、PP-YOLOv2算法解读、PP-PicoDet算法解读、PP-YOLOE算法解读、PP-YOLOE-R算法解读
R-CNN系列算法解读:
R-CNN算法解读、SPPNet算法解读、Fast R-CNN算法解读、Faster R-CNN算法解读、Mask R-CNN算法解读、Cascade R-CNN算法解读、Libra R-CNN算法解读
1、算法概述
最近Ultralytics项目又更新,推出了YOLOv11,基于上一个版本YOLOv8变化不是很大。还是和YOLOv8一样,可参考工程readme里面参考文档(https://docs.ultralytics.com/models/yolo11/),该文档非常丰富,包含如何快速运行、训练、验证、预测及导出其他格式模型,还包含除检测任务的其他任务的扩展如:分割、分类和姿态估计,同时也包含YOLO系列其他模型的汇总介绍。相比YOLO之前其他版本,YOLO11推理速度更快,精度更高。如下图:

按照官方文档的介绍,YOLO11主要改进有如下几点:
- 增强特征提取能力,YOLO11采用改进的backbone和neck结构,增强了特征提取能力,以实现更高精确和更复杂的目标检测任务。
相对于YOLOv8的更新,具体有如下几点:
(1)、backbone部分,将YOLOv8的C2f模块替换成了YOLO11的C3k2模块;
(2)、在YOLOv8的SPPF模块后新增了C2PSA模块,这是一个由两个卷积层和一个多头自注意力模块组成的,用于增强特征提取能力;
(3)、在检测头的分类分支中替换了两个常规卷积层为depthwise卷积;
(4)、整个n/s/m/l/x系列模型的depth、width、max_channels的比例参数相对于YOLOv8进行了调整。 - 更高效且速度更快,因为整个结构的调整和训练流程的优化,使得模型推理速度更快。
- 更高的精度,但是参数量更少
- 和YOLOv8一样,YOLO11依然可以无缝衔接到实例分割、图像分类以及姿态估计任务,并且支持导出多种格式的模型,并且可以在CPU/GPU上运行。
2、YOLO11细节
YOLO11n网络结构如下所示,自己用PPT画的,有错误的地方,还请大家提示一下。
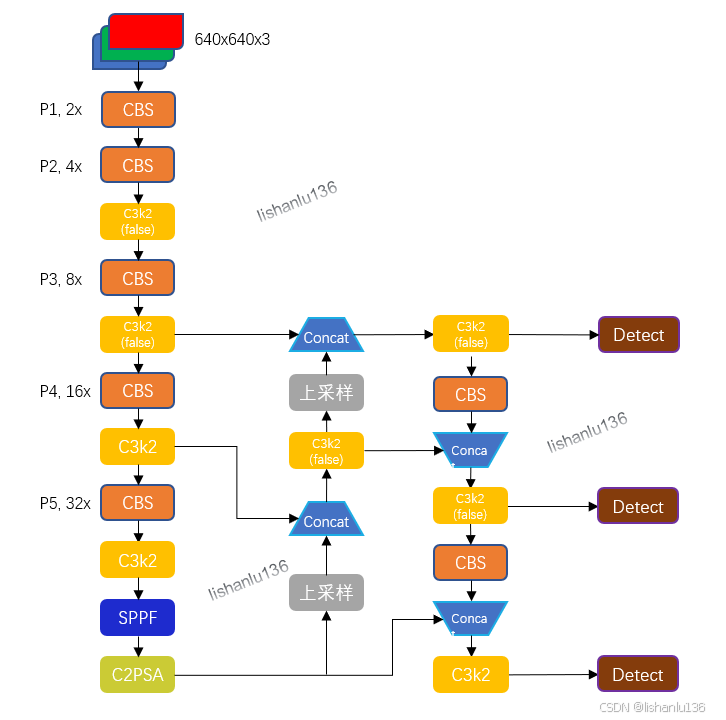
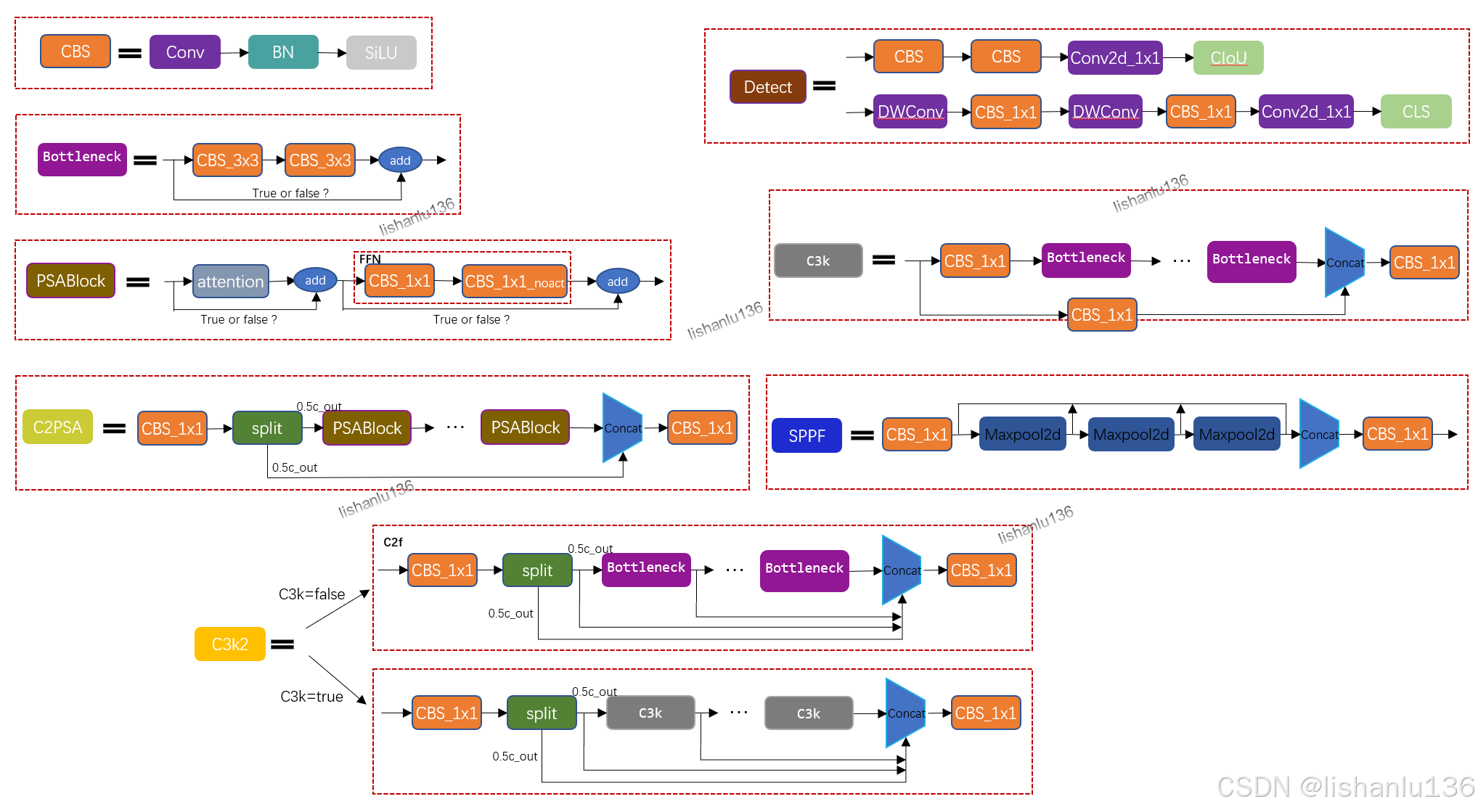
对应的每个子模块如下图所示:
对比YOLO11和YOLOv8的yaml格式网络结构配置

可以看到网络规模n/s/m/l/x的深度、宽度和输出通道数配置比例有改变,层数增多了,但是参数量和flops却减少了。
2.1 YOLO11的C3k2结构
YOLO11中的C3k2结构如下图:
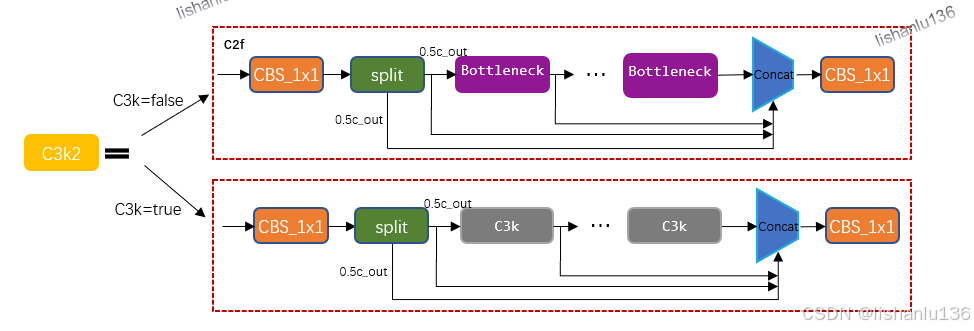
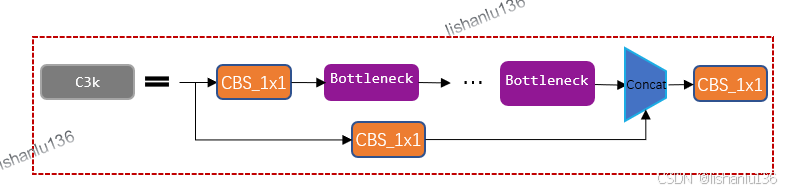
它由子模块ConvModule和多个Bottleneck所组成,而Bottleneck又因是否用C3k模块而变化,当不用C3k模块时,Bottleneck和YOLOv8一样即C3k2变成了和YOLOv8中的C2f一样,而用C3k模块时,就是YOLO11改进的地方。C3K模块细节如下,又是由3个卷积层和多个Bottleneck模块组成。
2.2 新增的C2PSA结构
另一个大的改进是在SPPF后面新增了C2PSA模块,其结构如下:
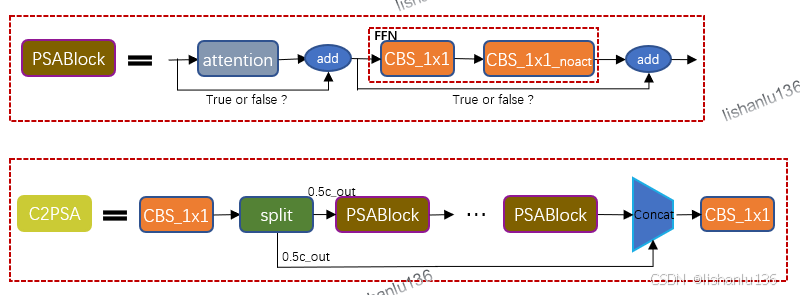
其中C2PSA模块的核心是PSABlock,这是一个带自注意力机制的模块,也就是transformer结构。新增这个模块可以增强backbone提取特征的能力。

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









