




概述
在前面的博客中,介绍了基于python私有化部署了DeepSeek-R1-Distill-Qwen的命令行对话与服务器客服端访问的方式,这两种方法都要基于torch算法框架,安装时还要对应torch的版本,假设安装的torch的版本小2.2,那么可以加载模型时可能获取到"triu_tril_cuda_template" not implemented for 'BFloat16’这个错误。还有一个问题是,GPU显存分配问题,DeepSeek官方给的文档,7B的模型要16G以上的显存,假设我现在用的显存只有8G,要部署7B的模型,那么可能获取一个显存不够的错误。如果使用Ollama框架的话,就不用面对这些问题了。
一.Ollama
Ollama 是一个开源的大型语言模型(LLM)平台,旨在让用户能够轻松地在本地运行、管理和与大型语言模型进行交互。Ollama 提供了一个简单的方式来加载和使用各种预训练的语言模型,支持文本生成、翻译、代码编写、问答等多种自然语言处理任务。Ollama 的特点在于它不仅仅提供了现成的模型和工具集,还提供了方便的界面和 API,使得从文本生成、对话系统到语义分析等任务都能快速实现。与其他 NLP 框架不同,Ollama 旨在简化用户的工作流程,使得机器学习不再是只有深度技术背景的开发者才能触及的领域。Ollama 支持多种硬件加速选项,包括纯 CPU 推理和各类底层计算架构(如 Apple Silicon),能够更好地利用不同类型的硬件资源。

1.1 核心功能与特点
-
多种预训练语言模型支持
Ollama 提供了多种开箱即用的预训练模型,包括常见的 GPT、BERT 等大型语言模型。用户可以轻松加载并使用这些模型进行文本生成、情感分析、问答等任务。 -
易于集成和使用
Ollama 提供了命令行工具(CLI)和 Python SDK,简化了与其他项目和服务的集成。开发者无需担心复杂的依赖或配置,可以快速将 Ollama 集成到现有的应用中。 -
本地部署与离线使用
不同于一些基于云的 NLP 服务,Ollama 允许开发者在本地计算环境中运行模型。这意味着可以脱离对外部服务器的依赖,保证数据隐私,并且对于高并发的请求,离线部署能提供更低的延迟和更高的可控性。 -
支持模型微调与自定义
用户不仅可以使用 Ollama 提供的预训练模型,还可以在此基础上进行模型微调。根据自己的特定需求,开发者可以使用自己收集的数据对模型进行再训练,从而优化模型的性能和准确度。 -
性能优化
Ollama 关注性能,提供了高效的推理机制,支持批量处理,能够有效管理内存和计算资源。这让它在处理大规模数据时依然保持高效。 -
跨平台支持
Ollama 支持在多个操作系统上运行,包括 Windows、macOS 和 Linux。这样无论是开发者在本地环境调试,还是企业在生产环境部署,都能得到一致的体验。 -
开放源码与社区支持
Ollama 是一个开源项目,这意味着开发者可以查看源代码,进行修改和优化,也可以参与到项目的贡献中。此外,Ollama 有一个活跃的社区,开发者可以从中获取帮助并与其他人交流经验。
1.2 应用场景
-
内容创作:
帮助作家、记者、营销人员快速生成高质量的内容,例如博客文章、广告文案等。 -
编程辅助::
帮助开发者生成代码、调试程序或优化代码结构。 -
教育和研究:
辅助学生和研究人员进行学习、写作和研究,例如生成论文摘要或解答问题。 -
跨语言交流:
提供高质量的翻译功能,帮助用户打破语言障碍。 -
个人助手:
作为一个智能助手,帮助用户完成日常任务,例如撰写邮件、生成待办事项等。
1.3 安装
Ollama 支持多种操作系统,包括 macOS、Windows、Linux 以及通过 Docker 容器运行。Ollama 对硬件要求不高,旨在让用户能够轻松地在本地运行、管理和与大型语言模型进行交互。
- CPU:多核处理器(推荐 4 核或以上)。
- GPU:如果你计划运行大型模型或进行微调,推荐使用具有较高计算能力的 GPU(如 NVIDIA 的 CUDA 支持)。
- 内存:至少 8GB RAM,运行较大模型时推荐 16GB 或更高。
- 存储:需要足够的硬盘空间来存储预训练模型,通常需要 10GB 至数百 GB 的空间,具体取决于模型的大小。
- **软件要求:**确保系统上安装了最新版本的 Python(如果打算使用 Python SDK)。
Ollama 官方下载地址:https://ollama.com/download。
打开浏览器,访问 Ollama 官方网站:https://ollama.com/download,下载适用于 Windows 的安装程序。
下载地址为:https://ollama.com/download/OllamaSetup.exe。
下载完成后,双击安装程序并按照提示完成安装。
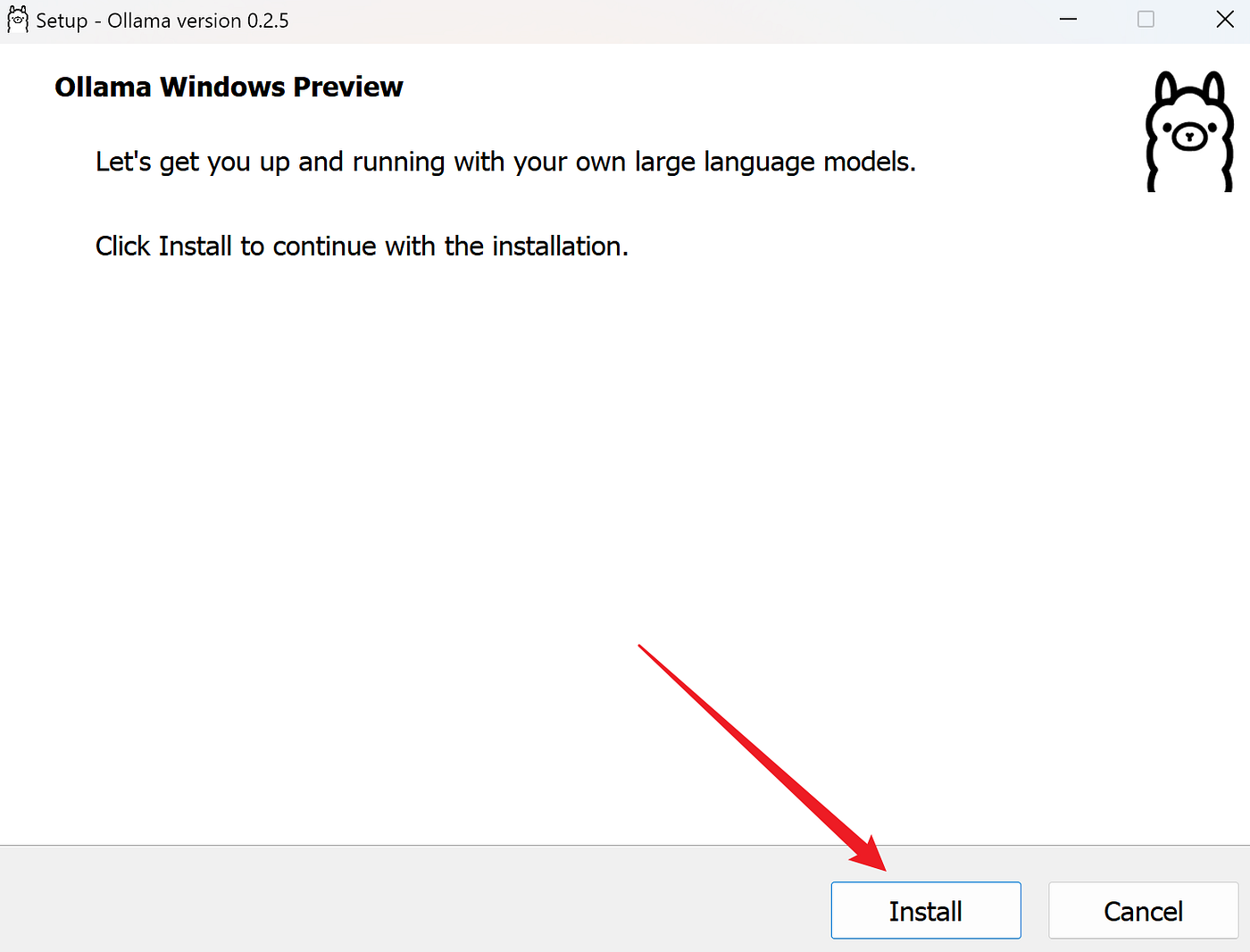
验证安装
打开命令提示符或 PowerShell,输入以下命令验证安装是否成功:
ollama --version
如果显示版本号,则说明安装成功。
更改安装路径(可选)
如果需要将 Ollama 安装到非默认路径,可以在安装时通过命令行指定路径,例如:
OllamaSetup.exe /DIR="d:somelocation"
1.4 下载模型与运行
打开https://ollama.com/download,选择Models,第一个就是DeepSeek:

选择要下载的模型:

打开cmd,输入:
ollama run deepseek-r1:14b
之后会进入漫长的下载等待,下载完成之后,就可以在当前命令行窗口进行对话:

二.命令行部署
为了方便开发与项目嵌入,可以使用代码进行部署,这里默认已经安装了Conda:
conda create -n deepseek python==3.10
conda activate deepseek
pip install ollama
然后创建一个ollama_server.py文件,代码如下:
from ollama import chat
# 初始化消息列表,用于存储对话历史
messages = []
while True:
# 获取用户输入
user_input = input("请输入你的问题(输入 '退出' 结束对话):")
# 如果用户输入 '退出',则结束对话
if user_input.lower() == '退出':
break
# 将用户输入添加到消息列表中
messages.append({'role': 'user', 'content': user_input})
# 调用 chat 函数进行问答
stream = chat(
model='deepseek-r1:7b',
messages=messages,
stream=True,
)
# 用于存储当前轮次的回答内容
response_content = ""
# 处理流式响应
for chunk in stream:
# 获取当前 chunk 的内容
chunk_content = chunk['message']['content']
# 打印内容,设置 end='' 防止换行,flush=True 确保内容立即输出
print(chunk_content, end='', flush=True)
# 将当前 chunk 的内容添加到响应内容中
response_content += chunk_content
# 将模型的回答添加到消息列表中,角色为 'assistant'
messages.append({'role': 'assistant', 'content': response_content})
# 打印换行符,使下一轮问答从新的一行开始
print()
运行效果:

三.FastApi部署
FastAPI是一个现代、快速(高性能)的Web框架,用于构建APIs与Web应用程序。由于其出色的性能,简洁的代码编写方式,以及自动化文档的支持,FastAPI迅速成为Python社区中受欢迎的Web框架之一。本文将深入探讨FastAPI的核心特性、使用方法及其如何帮助开发者有效地构建高性能的API服务。
pip install fastapi
3.1 服务端代码
from fastapi import FastAPI, HTTPException
from pydantic import BaseModel
from ollama import chat
import uvicorn
app = FastAPI()
# 用于存储对话历史
messages = []
# 定义请求体模型
class UserInput(BaseModel):
user_input: str
@app.post("/chat")
async def chat_with_model(user_input: UserInput):
global messages
# 如果用户输入 '退出',则结束对话
if user_input.user_input.lower() == '退出':
messages = [] # 清空对话历史
return {"response": "对话已结束"}
# 将用户输入添加到消息列表中
messages.append({'role': 'user', 'content': user_input.user_input})
# 调用 chat 函数进行问答
stream = chat(
model='deepseek-r1:7b',
messages=messages,
stream=True,
)
# 用于存储当前轮次的回答内容
response_content = ""
# 处理流式响应
for chunk in stream:
# 获取当前 chunk 的内容
chunk_content = chunk['message']['content']
# 将当前 chunk 的内容添加到响应内容中
response_content += chunk_content
# 将模型的回答添加到消息列表中,角色为 'assistant'
messages.append({'role': 'assistant', 'content': response_content})
# 返回模型的回答
return {"response": response_content}
if __name__ == "__main__":
uvicorn.run(app, host="0.0.0.0", port=8000)
3.2 客户端代码
import requests
# FastAPI 服务器的地址
API_URL = "http://127.0.0.1:8000/chat"
def chat_with_server():
print("欢迎使用聊天客户端!输入 '退出' 结束对话。")
while True:
# 获取用户输入
user_input = input("输入: ")
# 如果用户输入 '退出',则结束对话
if user_input.lower() == '退出':
print("对话已结束。")
break
# 构造请求体
payload = {"user_input": user_input}
# 发送 POST 请求到 FastAPI 服务器
try:
response = requests.post(API_URL, json=payload)
response.raise_for_status() # 检查请求是否成功
data = response.json()
# 打印模型的回答
print(f"AI: {data['response']}")
except requests.exceptions.RequestException as e:
print(f"请求失败: {e}")
break
if __name__ == "__main__":
chat_with_server()



















 3061
3061

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











