




一、概述
上个博客实现了在命令行终端下DeepSeek-R1-Distill-Qwen的模型部署与流式输出,但在日常的生产环境中,基本上是会把模型推理部署在一个服务器上,然后使用客户端调用api接口实现对话。
想试用满血版的DeepSeek与各种开源的大语言模型可以转到,实测比DeepSeek官网还牛逼:https://askmany.cn/login?i=d788ca33
API 是软件间相互传输数据的接口。它在生活中十分常见,比如博物馆订票系统中就使用了 API. 当你在手机应用上订票时,手机实际上发送了一个 HTTP 请求给远程服务器。远程服务器解析该请求。当确认所有字段信息均准确无误后,它才会把你的订票信息录入数据库,并回调成功标识。只有当上述操作全都被正确执行时,你的手机才会显示订票成功。
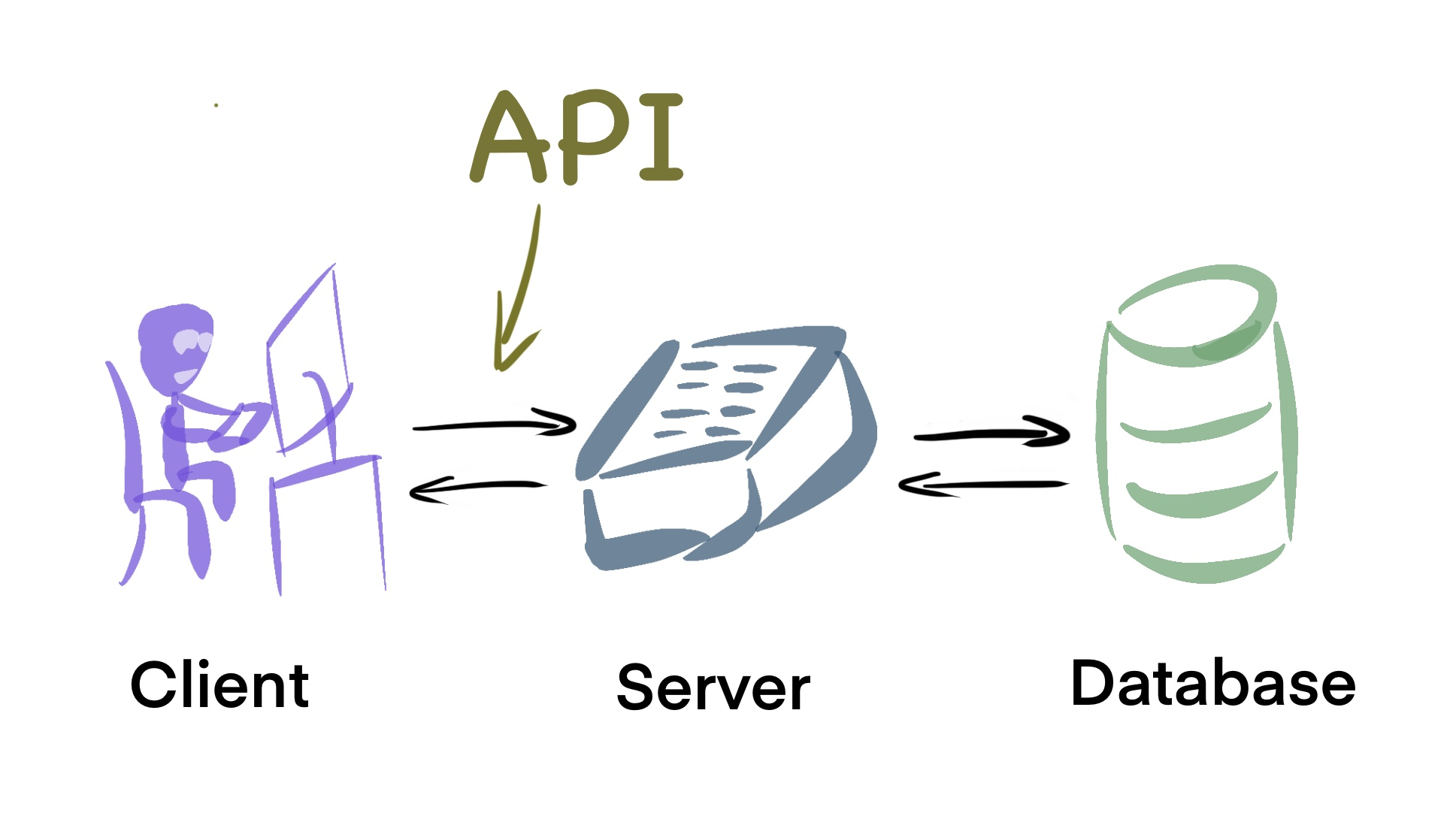
API 程序通常运行在服务端 (server) 上。客户端 (client) 通过向 API 提供的网络接口发送请求,以实现对服务端的通信。服务端收到请求后,对请求进行解析。如果请求是合法的,则执行该请求,并将请求结果回调给客户端。一次典型的 API 请求大体上是这么个过程。
二、FastApi
FastAPI基于Python的类型提示系统,利用类型提示来提高代码的可读性和可维护性,同时还能进行一些运行时的类型检查。它使用了Pydantic库来处理数据验证和序列化,确保接收到的数据符合预期的格式和类型。
2.1 主要特点
- 高性能:FastAPI基于
Starlette框架构建,使用异步编程和uvicorn等高性能的ASGI服务器,能处理大量并发请求,性能表现出色,可与Node.js、Go等语言的高性能框架相媲美。 - 简洁易用:采用简洁直观的函数式编程风格,通过装饰器来定义路由和处理请求,代码结构清晰,易于理解和编写。开发者可以快速上手,轻松构建各种复杂的API。
- 类型安全:充分利用Python的类型提示功能,在开发过程中提供强大的类型检查和自动补全支持。这有助于减少代码中的错误,提高代码的可维护性和可读性,尤其是在大型项目中。
- 功能丰富:支持自动生成API文档,可根据代码中的定义自动生成交互式的Swagger UI和ReDoc文档,方便开发者和用户查看和测试API。还支持请求验证、响应序列化、依赖注入、中间件等功能,满足各种Web开发需求。
2.2 应用场景
- Web API开发:是构建各种类型Web API的理想选择,包括RESTful API和GraphQL API等。可用于开发企业级应用、互联网应用、移动应用的后端API,为前端应用提供数据支持。
- 数据服务:适用于构建数据服务接口,为数据分析师、数据科学家或其他后端服务提供数据查询、处理和更新的API。可以方便地与数据库、数据仓库等进行集成,提供高效的数据访问接口。
- 微服务架构:非常适合用于构建微服务架构中的各个微服务。每个微服务可以使用FastAPI快速搭建,实现独立的业务功能,并通过API进行通信和协作。
以下是一个简单的FastAPI示例代码:
from fastapi import FastAPI
app = FastAPI()
# 定义一个GET请求的路由
@app.get("/")
async def read_root():
return {"Hello": "World"}
# 定义一个带有路径参数的GET请求的路由
@app.get("/items/{item_id}")
async def read_item(item_id: int):
return {"item_id": item_id}
代码定义了一个简单的FastAPI应用,包含两个路由:一个是根路径/的GET请求,返回{"Hello": "World"};另一个是带有路径参数item_id的/items/{item_id}的GET请求,返回包含item_id的JSON数据。
三、模型下载
使用 modelscope 中的 snapshot_download 函数下载模型,第一个参数为模型名称,参数 cache_dir 为模型的下载路径。
使用PyCharm中新建download_ model.py 文件,文件代码如下:
import os
from modelscope import snapshot_download
from modelscope.utils.constant import DownloadMode
def download_model(model_name,cache_path):
"""
此函数用于从 modelscope 下载指定模型到指定路径。
函数会尝试从 modelscope 下载 'deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B' 模型,
并将其保存到 './models' 目录下。如果下载过程中出现任何异常,
将会捕获并打印错误信息。
返回值:
- 如果下载成功,返回模型保存的目录路径。
- 如果下载失败,返回 None。
"""
try:
# 确保下载路径存在,如果不存在则创建
if not os.path.exists(cache_path):
os.makedirs(cache_path)
# 使用 snapshot_download 函数下载模型,设置下载模式为强制重新下载以获取最新版本
model_dir = snapshot_download(
model_name,
cache_dir=cache_path,
revision='master',
download_mode=DownloadMode.FORCE_REDOWNLOAD
)
print(f"模型已成功下载到: {model_dir}")
return model_dir
except Exception as e:
print(f"下载模型时出现错误: {e}")
return None
if __name__ == "__main__":
model_name = 'deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B'
cache_path = './models'
download_model(model_name,cache_path)
四、DeepSeek FastApi服务器与客服端实现
4.1 服务器代码
4.1. 1 导入模块
import os
import re
import json
import datetime
import torch
from fastapi import FastAPI, Request
from transformers import AutoTokenizer, AutoModelForCausalLM
import uvicorn
注释:
导入所需的库,包括操作系统工具、正则表达式、JSON处理、日期时间、PyTorch、FastAPI框架、transformers库以及uvicorn服务器。
4.1. 2 配置管理
# 配置管理
DEVICE = "cuda" if torch.cuda.is_available() else "cpu" # 检查是否有可用的GPU设备
DEVICE_ID = os.getenv("CUDA_DEVICE_ID", "0") # 从环境变量中获取CUDA设备ID,默认为"0"
CUDA_DEVICE = f"{DEVICE}:{DEVICE_ID}" if DEVICE == "cuda" else DEVICE # 构造设备字符串
MODEL_NAME_OR_PATH = './models/deepseek-ai/DeepSeek-R1-Distill-Qwen-1-5B' # 模型文件路径
MAX_NEW_TOKENS = 8192 # 模型生成的最大新token数量
PORT = 6006 # 服务运行的端口号
注释:
这部分代码定义了程序运行的基本配置,包括设备选择、模型路径、最大生成长度和端口号。
4.1. 3 FastAPI应用初始化
# 创建FastAPI应用
app = FastAPI()
注释:
初始化一个FastAPI应用实例,用于处理HTTP请求。
4.1. 4 加载预训练模型和分词器
# 加载预训练的分词器和模型
try:
tokenizer = AutoTokenizer.from_pretrained(MODEL_NAME_OR_PATH, use_fast=False) # 加载分词器
if tokenizer.pad_token_id is None: # 如果分词器没有定义pad_token_id,则使用eos_token_id
tokenizer.pad_token_id = tokenizer.eos_token_id
model = AutoModelForCausalLM.from_pretrained(MODEL_NAME_OR_PATH, device_map=CUDA_DEVICE, torch_dtype=torch.bfloat16) # 加载模型
except Exception as e:
print(f"模型加载失败: {e}") # 如果加载失败,打印错误信息
raise
注释:
这部分代码负责加载预训练的分词器和模型,并处理可能的加载错误。如果模型加载失败,程序会抛出异常。
4.1. 5 清理GPU内存的函数
# 清理GPU内存函数
def torch_gc():
if torch.cuda.is_available(): # 检查是否有可用的GPU
with torch.cuda.device(CUDA_DEVICE): # 在指定的GPU设备上执行
torch.cuda.empty_cache() # 清理未使用的缓存
torch.cuda.ipc_collect() # 收集并释放共享内存
注释:
定义了一个函数torch_gc,用于清理GPU内存。这在生成模型响应后调用,以释放未使用的内存。
4.1. 6. 文本分割函数
# 文本分割函数
def split_text(text):
pattern = re.compile(r'<think>(.*?)</think>(.*)', re.DOTALL) # 定义正则表达式模式
match = pattern.search(text) # 在文本中搜索匹配模式
if match:
think_content = match.group(1).strip() # 提取<think>标签内的内容
answer_content = match.group(2).strip() # 提取<think>标签之后的内容
else:
think_content = "" # 如果没有匹配到,think_content为空
answer_content = text.strip() # answer_content为原始文本
return think_content, answer_content # 返回分割后的两部分内容
注释:
定义了一个函数split_text,用于将生成的文本分割为think部分和answer部分。它使用正则表达式来实现分割。
4.1. 7 处理POST请求的端点
# 处理POST请求的端点
@app.post("/")
async def create_item(request: Request):
try:
json_post_raw = await request.json() # 获取请求中的JSON数据
prompt = json_post_raw.get('prompt') # 提取JSON中的"prompt"字段
if not prompt: # 如果没有提供prompt
return {
"response": "请求中缺少 'prompt' 字段",
"think": "",
"answer": "请求中缺少 'prompt' 字段",
"status": 400,
"time": datetime.datetime.now().strftime("%Y-%m-%d %H:%M:%S")
}
messages = [{"role": "user", "content": prompt}] # 构造输入消息
input_ids = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True) # 应用聊天模板
model_inputs = tokenizer([input_ids], return_tensors="pt").to(model.device) # 将输入转换为模型所需的张量
generated_ids = model.generate( # 生成响应
model_inputs.input_ids,
attention_mask=model_inputs.attention_mask,
max_new_tokens=MAX_NEW_TOKENS
)
generated_ids = [output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)] # 提取生成的新token
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0] # 将生成的token解码为文本
think_content, answer_content = split_text(response) # 分割生成的文本
now = datetime.datetime.now() # 获取当前时间
time = now.strftime("%Y-%m-%d %H:%M:%S") # 格式化时间
answer = { # 构造返回的JSON响应
"response": response,
"think": think_content,
"answer": answer_content,
"status": 200,
"time": time
}
log = f"[{time}], prompt:\"{prompt}\", response:\"{repr(response)}\", think:\"{think_content}\", answer:\"{answer_content}\"" # 构造日志信息
print(log) # 打印日志
torch_gc() # 清理GPU内存
return answer # 返回响应
except Exception as e: # 捕获异常
error_time = datetime.datetime.now().strftime("%Y-%m-%d %H:%M:%S") # 获取当前时间
error_log = f"[{error_time}] 请求处理出错: {e}" # 构造错误日志
print(error_log) # 打印错误日志
return { # 返回错误响应
"response": f"请求处理出错: {e}",
"think": "",
"answer": f"请求处理出错: {e}",
"status": 500,
"time": error_time
}
注释:
这部分代码定义了一个处理POST请求的端点/。它接收一个JSON请求,提取prompt字段,使用模型生成响应,并返回分割后的think和answer内容。如果发生错误,会返回错误信息。
4.1. 8 主函数入口
# 主函数入口
if __name__ == '__main__':
uvicorn.run(app, host='0.0.0.0', port=PORT, workers=1) # 启动FastAPI应用
注释:
程序的入口点。使用uvicorn运行FastAPI应用,监听0.0.0.0地址的指定端口。
4.2 客户端代码
import requests
import json
def get_completion(prompt):
headers = {'Content-Type': 'application/json'}
data = {"prompt": prompt}
response = requests.post(url='http://127.0.0.1:6006', headers=headers, data=json.dumps(data))
return response.json()['response']
if __name__ == '__main__':
print(get_completion('用python写一个svm分类器'))
显示结果:
实现视频效果:
基于FastApi的DeepSeek-R1模型部署
从输出的结果看,提出问题之后,要等待服务器回复完成之后,获取的结果一下全部抛出来,这对于正常的日常生产环境,并不是实用。
五、实现FastApi流式输出
5.1 流式输出服务端实现
def generate_streaming_text(prompt):
messages = [{"role": "user", "content": prompt}]
input_ids = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
model_inputs = tokenizer([input_ids], return_tensors="pt").to(model.device)
streamer = TextIteratorStreamer(tokenizer, skip_prompt=True, skip_special_tokens=True)
generation_kwargs = dict(model_inputs, streamer=streamer, max_new_tokens=MAX_NEW_TOKENS)
thread = Thread(target=model.generate, kwargs=generation_kwargs)
thread.start()
generated_text = ""
for new_text in streamer:
generated_text += new_text
think_content, answer_content = split_text(generated_text)
now = datetime.datetime.now()
time = now.strftime("%Y-%m-%d %H:%M:%S")
answer = {
"response": new_text, # 只发送新增的内容
"think": think_content,
"answer": answer_content,
"status": 200,
"time": time
}
yield json.dumps(answer).encode() + b'\n'
torch_gc()
5.2 流式输出客户务端实现
import requests
import json
import hashlib
# API 地址,根据实际情况修改
api_url = "http://localhost:6008"
# 构造请求数据
data = {
"prompt": "用python写个分类器"
}
# 发送 POST 请求并获取流式响应
response = requests.post(api_url, json=data, stream=True)
# 用于存储已解析数据的哈希值
parsed_hashes = set()
# 处理流式响应
if response.status_code == 200:
for line in response.iter_lines():
if line:
try:
line_hash = hashlib.sha256(line).hexdigest()
if line_hash in parsed_hashes:
continue
result = json.loads(line.decode('utf-8'))
# 实时输出新增的内容
print(result['response'], end="", flush=True)
parsed_hashes.add(line_hash)
except json.JSONDecodeError as e:
print(f"解析 JSON 出错: {e}")
else:
print(f"请求失败,状态码: {response.status_code}")
实现效果如下:
DeepSeek FastApi流式输出
备注:
代码下载地址:https://download.youkuaiyun.com/download/matt45m/90440695



















 5426
5426

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











