







一、YOLO11简介
ultralytics:是一个框架,通过它可以使用YOLO11模型,会自动下载模型到当前目录(自己手动在浏览器下载要快很多),支持YOLOv2到YOLO11。
YOLO11的模型都不大,yolo11n.pt 为5.4M,yolo11x.pt 为109M。
ultralytics文档:https://docs.ultralytics.com/
模型下载地址:https://github.com/ultralytics/assets/releases/download/v8.3.0/yolo11n.pt
ultralytics为YOLO11在不同功能上训练了一批模型,由于不同数据集的特点,所以针对不同的功能会选择在不同数据集上训练。
YOLO11 Detect, Segment and Pose models pretrained on the COCO dataset are available here, as well as YOLO11 Classify models pretrained on the ImageNet dataset. Track mode is available for all Detect, Segment and Pose models. All Models download automatically from the latest Ultralytics release on first use.
模型指标
size (pixels):图片像素 640 * 640
mAP:平均精度均值
Speed:推理时间,毫秒
params (M):参数量,百万级
FLOPs (G):每秒浮点运算次数。G表示10亿,可以用来衡量算法/模型复杂度,理论上该数值越高越好
模型规格
模型后缀n, s, m, l, x代表模型越来越大。
YOLO11m 在准确性、效率、模型大小之间取得了最佳平衡
模型功能
- Detect:物体检测
- Segment:图像分割
- Classify:分类
- Pose:人体姿态推断
- OBB:定向物体检测,检测框有一定的倾斜角度
- Track:物体追踪

模型列表
Detection (COCO)See Detection Docs for usage examples with these models trained on COCO, which include 80 pre-trained classes.
| Model | size (pixels) | mAPval 50-95 | Speed CPU ONNX (ms) | Speed T4 TensorRT10 (ms) | params (M) | FLOPs (B) |
|---|---|---|---|---|---|---|
| YOLO11n | 640 | 39.5 | 56.1 ± 0.8 | 1.5 ± 0.0 | 2.6 | 6.5 |
| YOLO11s | 640 | 47.0 | 90.0 ± 1.2 | 2.5 ± 0.0 | 9.4 | 21.5 |
| YOLO11m | 640 | 51.5 | 183.2 ± 2.0 | 4.7 ± 0.1 | 20.1 | 68.0 |
| YOLO11l | 640 | 53.4 | 238.6 ± 1.4 | 6.2 ± 0.1 | 25.3 | 86.9 |
| YOLO11x | 640 | 54.7 | 462.8 ± 6.7 | 11.3 ± 0.2 | 56.9 | 194.9 |
- mAPval values are for single-model single-scale on COCO val2017 dataset.
Reproduce byyolo val detect data=coco.yaml device=0 - Speed averaged over COCO val images using an Amazon EC2 P4d instance.
Reproduce byyolo val detect data=coco.yaml batch=1 device=0|cpu
See Segmentation Docs for usage examples with these models trained on COCO-Seg, which include 80 pre-trained classes.
| Model | size (pixels) | mAPbox 50-95 | mAPmask 50-95 | Speed CPU ONNX (ms) | Speed T4 TensorRT10 (ms) | params (M) | FLOPs (B) |
|---|---|---|---|---|---|---|---|
| YOLO11n-seg | 640 | 38.9 | 32.0 | 65.9 ± 1.1 | 1.8 ± 0.0 | 2.9 | 10.4 |
| YOLO11s-seg | 640 | 46.6 | 37.8 | 117.6 ± 4.9 | 2.9 ± 0.0 | 10.1 | 35.5 |
| YOLO11m-seg | 640 | 51.5 | 41.5 | 281.6 ± 1.2 | 6.3 ± 0.1 | 22.4 | 123.3 |
| YOLO11l-seg | 640 | 53.4 | 42.9 | 344.2 ± 3.2 | 7.8 ± 0.2 | 27.6 | 142.2 |
| YOLO11x-seg | 640 | 54.7 | 43.8 | 664.5 ± 3.2 | 15.8 ± 0.7 | 62.1 | 319.0 |
- mAPval values are for single-model single-scale on COCO val2017 dataset.
Reproduce byyolo val segment data=coco.yaml device=0 - Speed averaged over COCO val images using an Amazon EC2 P4d instance.
Reproduce byyolo val segment data=coco.yaml batch=1 device=0|cpu
See Classification Docs for usage examples with these models trained on ImageNet, which include 1000 pretrained classes.
| Model | size (pixels) | acc top1 | acc top5 | Speed CPU ONNX (ms) | Speed T4 TensorRT10 (ms) | params (M) | FLOPs (B) at 224 |
|---|---|---|---|---|---|---|---|
| YOLO11n-cls | 224 | 70.0 | 89.4 | 5.0 ± 0.3 | 1.1 ± 0.0 | 1.6 | 0.5 |
| YOLO11s-cls | 224 | 75.4 | 92.7 | 7.9 ± 0.2 | 1.3 ± 0.0 | 5.5 | 1.6 |
| YOLO11m-cls | 224 | 77.3 | 93.9 | 17.2 ± 0.4 | 2.0 ± 0.0 | 10.4 | 5.0 |
| YOLO11l-cls | 224 | 78.3 | 94.3 | 23.2 ± 0.3 | 2.8 ± 0.0 | 12.9 | 6.2 |
| YOLO11x-cls | 224 | 79.5 | 94.9 | 41.4 ± 0.9 | 3.8 ± 0.0 | 28.4 | 13.7 |
- acc values are model accuracies on the ImageNet dataset validation set.
Reproduce byyolo val classify data=path/to/ImageNet device=0 - Speed averaged over ImageNet val images using an Amazon EC2 P4d instance.
Reproduce byyolo val classify data=path/to/ImageNet batch=1 device=0|cpu
See Pose Docs for usage examples with these models trained on COCO-Pose, which include 1 pre-trained class, person.
| Model | size (pixels) | mAPpose 50-95 | mAPpose 50 | Speed CPU ONNX (ms) | Speed T4 TensorRT10 (ms) | params (M) | FLOPs (B) |
|---|---|---|---|---|---|---|---|
| YOLO11n-pose | 640 | 50.0 | 81.0 | 52.4 ± 0.5 | 1.7 ± 0.0 | 2.9 | 7.6 |
| YOLO11s-pose | 640 | 58.9 | 86.3 | 90.5 ± 0.6 | 2.6 ± 0.0 | 9.9 | 23.2 |
| YOLO11m-pose | 640 | 64.9 | 89.4 | 187.3 ± 0.8 | 4.9 ± 0.1 | 20.9 | 71.7 |
| YOLO11l-pose | 640 | 66.1 | 89.9 | 247.7 ± 1.1 | 6.4 ± 0.1 | 26.2 | 90.7 |
| YOLO11x-pose | 640 | 69.5 | 91.1 | 488.0 ± 13.9 | 12.1 ± 0.2 | 58.8 | 203.3 |
- mAPval values are for single-model single-scale on COCO Keypoints val2017 dataset.
Reproduce byyolo val pose data=coco-pose.yaml device=0 - Speed averaged over COCO val images using an Amazon EC2 P4d instance.
Reproduce byyolo val pose data=coco-pose.yaml batch=1 device=0|cpu
See OBB Docs for usage examples with these models trained on DOTAv1, which include 15 pre-trained classes.
| Model | size (pixels) | mAPtest 50 | Speed CPU ONNX (ms) | Speed T4 TensorRT10 (ms) | params (M) | FLOPs (B) |
|---|---|---|---|---|---|---|
| YOLO11n-obb | 1024 | 78.4 | 117.6 ± 0.8 | 4.4 ± 0.0 | 2.7 | 17.2 |
| YOLO11s-obb | 1024 | 79.5 | 219.4 ± 4.0 | 5.1 ± 0.0 | 9.7 | 57.5 |
| YOLO11m-obb | 1024 | 80.9 | 562.8 ± 2.9 | 10.1 ± 0.4 | 20.9 | 183.5 |
| YOLO11l-obb | 1024 | 81.0 | 712.5 ± 5.0 | 13.5 ± 0.6 | 26.2 | 232.0 |
| YOLO11x-obb | 1024 | 81.3 | 1408.6 ± 7.7 | 28.6 ± 1.0 | 58.8 | 520.2 |
- mAPtest values are for single-model multiscale on DOTAv1 dataset.
Reproduce byyolo val obb data=DOTAv1.yaml device=0 split=testand submit merged results to DOTA evaluation. - Speed averaged over DOTAv1 val images using an Amazon EC2 P4d instance.
Reproduce byyolo val obb data=DOTAv1.yaml batch=1 device=0|cpu
二、使用YOLO11模型
环境准备
python >= 3.8
pytorch >= 1.8
conda create -n yolo11 python=3.11.4
conda activate yolo11
pip install ultralytics
创建项目 learn-yolo
下载 ultralytics代码,因为有一些东西需要参考,主要是ultralytics目录。
1、Detect
参考:https://docs.ultralytics.com/tasks/detect/
从图像或视频流中,识别对象的位置和类别。
物体检测器的输出是一组包围图像中物体的边框,以及每个边框的类别标签和置信度分数。如果您需要识别场景中感兴趣的物体,但又不需要知道物体的具体位置或确切形状,那么物体检测就是一个不错的选择。
Predict:https://docs.ultralytics.com/modes/predict/
我们知道,Detect 功能是在 COCO 数据集上训练的,那这个 COCO 数据集可以识别哪些东西呢。我们打开ultralytics/cfg/datasets/coco.yaml文件,里面列出了 80 个物体名称。
from ultralytics import YOLO
import cv2
def detect():
model = YOLO("yolo11n.pt")
results = model(["imgs/20250210101802.png", "imgs/20240731142129234.jpg", "imgs/cat.jpg"])
for result in results:
# print(type(result)) # <class 'ultralytics.engine.results.Results'>
boxes = result.boxes # Boxes object for bounding box outputs
masks = result.masks # Masks object for segmentation masks outputs
keypoints = result.keypoints # Keypoints object for pose outputs
probs = result.probs # Probs object for classification outputs
obb = result.obb # Oriented boxes object for OBB outputs
result.show() # display to screen
# result.save(filename="result.jpg") # save to disk
results 是一个列表,result 类型为 <class 'ultralytics.engine.results.Results'>
Attributes:
orig_img (numpy.ndarray): The original image as a numpy array.
orig_shape (Tuple[int, int]): Original image shape in (height, width) format.
boxes (Boxes | None): Detected bounding boxes.
masks (Masks | None): Segmentation masks.
probs (Probs | None): Classification probabilities.
keypoints (Keypoints | None): Detected keypoints.
obb (OBB | None): Oriented bounding boxes.
speed (Dict): Dictionary containing inference speed information.
names (Dict): Dictionary mapping class indices to class names.
path (str): Path to the input image file.
save_dir (str | None): Directory to save results.
Methods:
update: Updates the Results object with new detection data.
cpu: Returns a copy of the Results object with all tensors moved to CPU memory.
numpy: Converts all tensors in the Results object to numpy arrays.
cuda: Moves all tensors in the Results object to GPU memory.
to: Moves all tensors to the specified device and dtype.
new: Creates a new Results object with the same image, path, names, and speed attributes.
plot: Plots detection results on an input RGB image.
show: Displays the image with annotated inference results.
save: Saves annotated inference results image to file.
verbose: Returns a log string for each task in the results.
save_txt: Saves detection results to a text file.
save_crop: Saves cropped detection images to specified directory.
summary: Converts inference results to a summarized dictionary.
to_df: Converts detection results to a Pandas Dataframe.
to_json: Converts detection results to JSON format.
to_csv: Converts detection results to a CSV format.
to_xml: Converts detection results to XML format.
to_html: Converts detection results to HTML format.
to_sql: Converts detection results to an SQL-compatible format.
show()是打开图片查看器展示图片。
plot()是返回结果图片的 numpy.ndarray数组,这样就可以使用cv2来处理图片了,其已经安装了opencv-python。对于视频流,那最好是用cv2.imshow,使用同一个窗口名称,就只有一个窗口。
def detect():
model = YOLO("yolo11n.pt")
results = model(["imgs/20250210101802.png", "imgs/20240731142129234.jpg", "imgs/cat.jpg"])
for k, result in enumerate(results):
im = result.plot() # numpy.ndarray
cv2.imshow("test"+str(k), im)
cv2.waitKey(0)
输出信息
0: 640x640 1 person, 1 sports ball, 1 tennis racket, 138.6ms
1: 640x640 3 persons, 3 cars, 138.6ms
2: 640x640 1 cat, 138.6ms
Speed: 6.8ms preprocess, 138.6ms inference, 1.5ms postprocess per image at shape (1, 3, 640, 640)



2、Segment
实例分割比对象检测更进一步,它涉及识别图像中的单个对象,并将它们从图像的其余部分中分割出来。
实例分割模型的输出是一组掩码或轮廓,这些掩码或轮廓勾勒出图像中的每个对象,并且每个对象都附有类别标签和置信度分数。当你不仅需要知道图像中对象的位置,还需要了解它们的确切形状时,实例分割就非常有用。
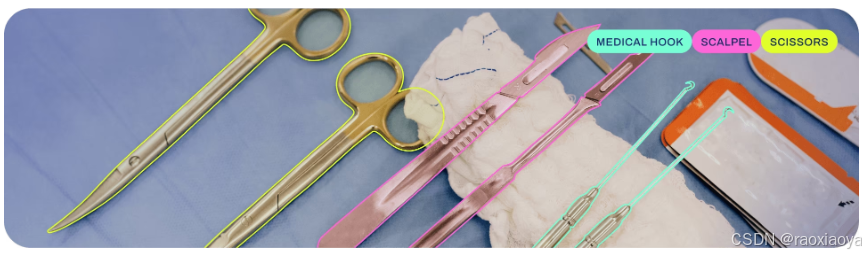
def segment():
model = YOLO("yolo11n-seg.pt")
results = model(["imgs/20250210101802.png"])
for k, result in enumerate(results):
filename = util.generate_random_string(15)
result.save(filename="imgs_result/"+filename+".jpg")

3、Pose
姿态估计是一项涉及识别图像中特定点的位置的任务,这些点通常被称为关键点。关键点可以代表对象的各种部分,如关节、标志点或其他显著特征。关键点的位置通常以一组2D [x, y]或3D [x, y, 可见性]坐标表示。
姿态估计模型的输出是一组代表图像中对象上的关键点的点,通常还附有每个点的置信度分数。当你需要识别场景中对象的具体部分及其相互之间的位置关系时,姿态估计是一个很好的选择。
使用的是 coco-pose数据集。
人的姿态被定义为17个点,并标记每个点在图像中的坐标
Nose
Left Eye
Right Eye
Left Ear
Right Ear
Left Shoulder
Right Shoulder
Left Elbow
Right Elbow
Left Wrist
Right Wrist
Left Hip
Right Hip
Left Knee
Right Knee
Left Ankle
Right Ankle
def pose():
model = YOLO("yolo11n-pose.pt") # load an official model
results = model("imgs/20250210101802.png")
for result in results:
print(result.keypoints)
result.show()

ultralytics.engine.results.Keypoints object with attributes:
conf: tensor([[0.9966, 0.9942, 0.9561, 0.9619, 0.3857, 0.9993, 0.9988, 0.9974, 0.9947, 0.9763, 0.9706, 0.9999, 0.9998, 0.9985, 0.9982, 0.9850, 0.9847]])
data: tensor([[[2.1565e+02, 3.4999e+01, 9.9656e-01],
[2.1984e+02, 2.7018e+01, 9.9415e-01],
[2.0907e+02, 3.1001e+01, 9.5614e-01],
[2.3481e+02, 2.5937e+01, 9.6186e-01],
[0.0000e+00, 0.0000e+00, 3.8572e-01],
[2.5573e+02, 4.5721e+01, 9.9928e-01],
[2.0819e+02, 6.0532e+01, 9.9878e-01],
[2.8809e+02, 6.5891e+01, 9.9740e-01],
[1.5987e+02, 8.1759e+01, 9.9467e-01],
[3.2300e+02, 1.0970e+02, 9.7626e-01],
[1.1831e+02, 8.0122e+01, 9.7056e-01],
[2.5918e+02, 1.3346e+02, 9.9990e-01],
[2.0929e+02, 1.4076e+02, 9.9985e-01],
[3.3731e+02, 1.8365e+02, 9.9854e-01],
[1.6218e+02, 1.9817e+02, 9.9822e-01],
[3.9673e+02, 2.3521e+02, 9.8505e-01],
[9.3972e+01, 2.5031e+02, 9.8471e-01]]])
has_visible: True
orig_shape: (299, 478)
shape: torch.Size([1, 17, 3])
xy: tensor([[[215.6517, 34.9987],
[219.8361, 27.0179],
[209.0718, 31.0013],
[234.8076, 25.9374],
[ 0.0000, 0.0000],
[255.7305, 45.7213],
[208.1883, 60.5316],
[288.0875, 65.8907],
[159.8745, 81.7594],
[323.0020, 109.6960],
[118.3133, 80.1224],
[259.1849, 133.4618],
[209.2867, 140.7613],
[337.3135, 183.6483],
[162.1798, 198.1695],
[396.7317, 235.2071],
[ 93.9718, 250.3072]]])
xyn: tensor([[[0.4512, 0.1171],
[0.4599, 0.0904],
[0.4374, 0.1037],
[0.4912, 0.0867],
[0.0000, 0.0000],
[0.5350, 0.1529],
[0.4355, 0.2024],
[0.6027, 0.2204],
[0.3345, 0.2734],
[0.6757, 0.3669],
[0.2475, 0.2680],
[0.5422, 0.4464],
[0.4378, 0.4708],
[0.7057, 0.6142],
[0.3393, 0.6628],
[0.8300, 0.7866],
[0.1966, 0.8371]]])
conf:每个点的置信度
xy:每一个点的x,y坐标
xyn:坐标标准化
data:x, y, visibility
4、Classify
图像分类是这三个任务中最简单的,它涉及将整张图像归类到一组预定义的类别中的一种。
图像分类器的输出是一个单一的类别标签和一个置信度分数。当你只需要知道图像属于哪个类别,而不需要知道该类别的对象在图像中的具体位置或它们的确切形状时,图像分类就非常有用。
使用的是imageNet数据集,里面有1000个类别。
def classify():
model = YOLO("yolo11m-cls.pt")
results = model(["imgs/20250210101802.png"])
for k, result in enumerate(results):
print(result.probs)
result.show()
imgs/20250210101802.png是上面的打羽毛球的图片。
输出结果
......
orig_shape: None
shape: torch.Size([1000])
top1: 752
top1conf: tensor(0.9599)
top5: [752, 852, 890, 722, 422]
top5conf: tensor([0.9599, 0.0154, 0.0079, 0.0037, 0.0026])
top1: 752代表分类ID,打开ultralytics\cfg\datasets\ImageNet.yaml文件,搜索到752: racket,就是球拍的意思。
top1conf: tensor(0.9599)代表 top1 的得分。
top5和top5conf代表 top5 的分类。
从得分来看,top1 远远超过了其他四个。

5、Track
https://docs.ultralytics.com/modes/track/

在视频分析领域中,对象跟踪是一项至关重要的任务,它不仅能够识别帧内对象的位置和类别,而且还能在视频进行过程中为每个检测到的对象维持一个唯一的ID。该技术的应用范围非常广泛,从 surveillance(监控)和安全到实时体育分析等领域都有涉及。
来自Ultralytics跟踪器的输出与标准对象检测一致,但增加了对象ID的价值。这使得在视频流中跟踪对象并执行后续分析变得容易。
Ultralytics YOLO 提供了两个跟踪算法,你需要在 YAML 配置文件中设置tracker=tracker_type.yaml,可选的值为botsort.yaml 和 bytetrack.yaml,默认值是botsort。
你可以使用训练好的Detect / Segment / Pose模型,在视频流上运行追踪器,比如YOLO11n, YOLO11n-seg, YOLO11n-pose。
def track():
model = YOLO("yolo11n.pt")
# Tracking with default tracker
results = model.track("https://youtu.be/LNwODJXcvt4", show=True)
# with ByteTrack
# results = model.track("https://youtu.be/LNwODJXcvt4", show=True, tracker="bytetrack.yaml")
for result in results:
print(result.boxes.id) # print track IDs
result.show()
def track2():
model = YOLO("yolo11n.pt")
video_path = "path/to/video.mp4"
cap = cv2.VideoCapture(video_path)
while cap.isOpened():
success, frame = cap.read()
if success:
# Run YOLO11 tracking on the frame, persisting tracks between frames
results = model.track(frame, persist=True)
annotated_frame = results[0].plot()
cv2.imshow("YOLO11 Tracking", annotated_frame)
if cv2.waitKey(1) & 0xFF == ord("q"):
break
else:
break
cap.release()
cv2.destroyAllWindows()
def track3():
model = YOLO("yolo11n.pt")
video_path = "path/to/video.mp4"
cap = cv2.VideoCapture(video_path)
# Store the track history
track_history = defaultdict(lambda: [])
# Loop through the video frames
while cap.isOpened():
# Read a frame from the video
success, frame = cap.read()
if success:
# Run YOLO11 tracking on the frame, persisting tracks between frames
results = model.track(frame, persist=True)
# Get the boxes and track IDs
boxes = results[0].boxes.xywh.cpu()
track_ids = results[0].boxes.id.int().cpu().tolist()
# Visualize the results on the frame
annotated_frame = results[0].plot()
# Plot the tracks
for box, track_id in zip(boxes, track_ids):
x, y, w, h = box
track = track_history[track_id]
track.append((float(x), float(y))) # x, y center point
if len(track) > 30: # retain 90 tracks for 90 frames
track.pop(0)
# Draw the tracking lines
points = np.hstack(track).astype(np.int32).reshape((-1, 1, 2))
cv2.polylines(annotated_frame, [points], isClosed=False, color=(230, 230, 230), thickness=10)
# Display the annotated frame
cv2.imshow("YOLO11 Tracking", annotated_frame)
# Break the loop if 'q' is pressed
if cv2.waitKey(1) & 0xFF == ord("q"):
break
else:
# Break the loop if the end of the video is reached
break
# Release the video capture object and close the display window
cap.release()
cv2.destroyAllWindows()
def track4():
# Define model names and video sources
MODEL_NAMES = ["yolo11n.pt", "yolo11n-seg.pt"]
SOURCES = ["path/to/video.mp4", "0"] # local video, 0 for webcam
def run_tracker_in_thread(model_name, filename):
"""
Run YOLO tracker in its own thread for concurrent processing.
Args:
model_name (str): The YOLO11 model object.
filename (str): The path to the video file or the identifier for the webcam/external camera source.
"""
model = YOLO(model_name)
results = model.track(filename, save=True, stream=True)
for r in results:
pass
# Create and start tracker threads using a for loop
tracker_threads = []
for video_file, model_name in zip(SOURCES, MODEL_NAMES):
thread = threading.Thread(target=run_tracker_in_thread, args=(model_name, video_file), daemon=True)
tracker_threads.append(thread)
thread.start()
# Wait for all tracker threads to finish
for thread in tracker_threads:
thread.join()
# Clean up and close windows
cv2.destroyAllWindows()
6、OBB
Oriented Bounding Boxes Object Detection,定向物体检测,画出来的边界框带有一个倾斜角度。
定向对象检测比传统对象检测更进一步,它引入了一个额外的角度来更精确地定位图像中的对象。
定向对象检测器的输出是一组旋转的边界框,这些框精确地包围了图像中的对象,并且每个框都附有类别标签和置信度分数。当你需要识别场景中的感兴趣对象,但不需要知道对象的确切位置或其确切形状时,对象检测是一个很好的选择。
使用的数据集是 DOTAv1
def obb():
model = YOLO("yolo11n-obb.pt")
results = model(["imgs/boats.jpg"])
for result in results:
# print(result.obb)
# xywhr = result.obb.xywhr # center-x, center-y, width, height, angle (radians)
# xyxyxyxy = result.obb.xyxyxyxy # polygon format with 4-points
# names = [result.names[cls.item()] for cls in result.obb.cls.int()] # class name of each box
# confs = result.obb.conf # confidence score of each box
filename = util.generate_random_string(15)
result.save(filename="imgs_result/"+filename+".jpg")

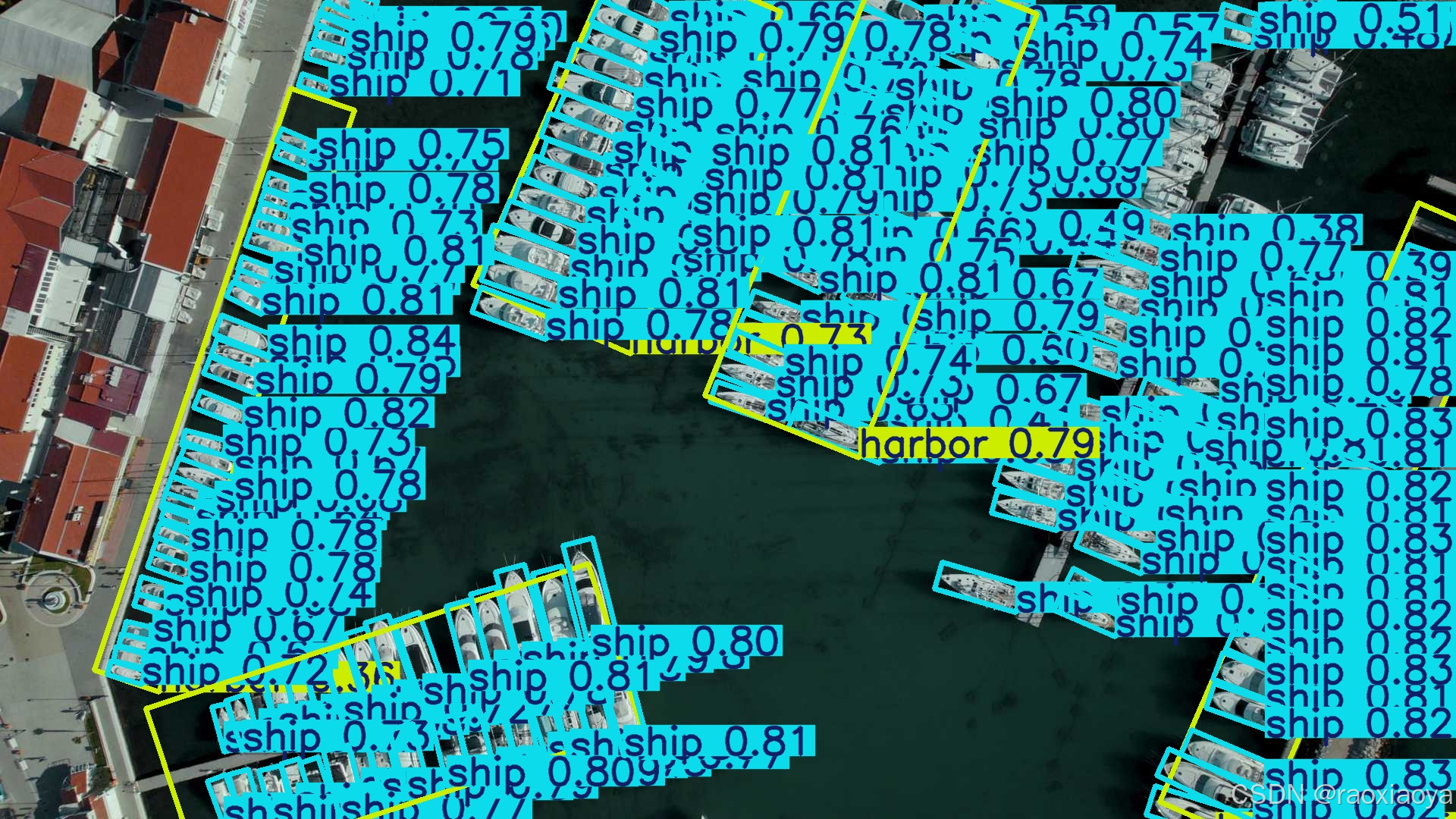
三、训练YOLO11模型的 Detection Task
如果你要检测的对象在YOLO11的训练集上没有,或者你的使用场景不同导致预训练模型的效果不佳,那就需要自己来准备数据集和训练了。
以 Detection Task 为例:https://docs.ultralytics.com/tasks/detect/#train
Train YOLO11n on the COCO8 dataset for 100 epochs at image size 640. For a full list of available arguments see the Configuration page.
从上面我们知道,Detect 是在 COCO 数据集上训练的,那此处为什么又说 COCO8,这两者有什么区别?
COCO 数据集
COCO说明:https://docs.ultralytics.com/datasets/detect/coco/
COCO(Common Objects in Context,常见物体上下文)数据集 是一个大规模的目标检测、分割和字幕生成数据集。它旨在鼓励对广泛物体类别进行研究,并常用于计算机视觉模型的性能基准测试。对于从事目标检测、分割和姿态估计任务的研究人员及开发者而言,COCO数据集是不可或缺的核心资源。
COCO 训练了 YOLO11n ~ YOLO11x模型
COCO 官网:https://cocodataset.org/#home
主要特点
- COCO数据集包含了33万张图像,其中20万张图像具有针对目标检测、分割和字幕生成任务的标注。
- 该数据集包含了80个物体类别,包括像汽车、自行车和动物这样的常见物体,以及更具体的类别,如雨伞、手提包和运动器材。
- 标注信息包括每个图像的对象边界框、分割掩膜和字幕。
- COCO提供了标准化的评估指标,如用于目标检测的平均精度均值(mAP)和用于分割任务的平均召回率均值(mAR),使其适合于比较模型性能。
打开ultralytics\cfg\datasets\coco.yaml文件
urls = [
"http://images.cocodataset.org/zips/train2017.zip", # 19G, 118k images
"http://images.cocodataset.org/zips/val2017.zip", # 1G, 5k images
"http://images.cocodataset.org/zips/test2017.zip", # 7G, 41k images (optional)
]
COCO8 数据集
这是一个小数据集,用于对象检测,它包含 COCO train2017 中的前8张图片,4个是用来训练,4个用来验证。COCO8 是tesing 和 debugging 对象检测模型的理想数据集,或者实验新的检测方法。其zip大小只有1M。
coco8的yaml定义跟coco几乎一样。虽然它只有8张图片,但是每张图片上可以有多个对象,因此,它依然有80个分类。
imageNet 数据集
在计算机视觉领域这是一个非常有名的数据集,它的特点是一张图片上只聚焦一个对象,也就说一个图片只会被识别成一个对象,所以被用来做classification。

官网 https://www.image-net.org/
准备数据集
我们先来参考一下 coco8 ,下载解压后
tree coco8
coco8
├── LICENSE
├── README.md
├── images
│ ├── train
│ │ ├── 000000000009.jpg
│ │ ├── 000000000025.jpg
│ │ ├── 000000000030.jpg
│ │ └── 000000000034.jpg
│ └── val
│ ├── 000000000036.jpg
│ ├── 000000000042.jpg
│ ├── 000000000049.jpg
│ └── 000000000061.jpg
└── labels
├── train
│ ├── 000000000009.txt
│ ├── 000000000025.txt
│ ├── 000000000030.txt
│ └── 000000000034.txt
└── val
├── 000000000036.txt
├── 000000000042.txt
├── 000000000049.txt
└── 000000000061.txt
images里面放的是原始图片,labels放的是标签信息。
000000000009.jpg

000000000009.txt
45 0.479492 0.688771 0.955609 0.5955
45 0.736516 0.247188 0.498875 0.476417
50 0.637063 0.732938 0.494125 0.510583
45 0.339438 0.418896 0.678875 0.7815
49 0.646836 0.132552 0.118047 0.0969375
49 0.773148 0.129802 0.0907344 0.0972292
49 0.668297 0.226906 0.131281 0.146896
49 0.642859 0.0792187 0.148063 0.148062
分别为:对象ID,标注框中心点X坐标(归一化值),标注框中心点Y坐标,标注框宽,标注框高
自己标注
我们可以使用 labelimg工具来自己标注。
参考:深度学习工具|LabelImg(标注工具)的安装与使用教程
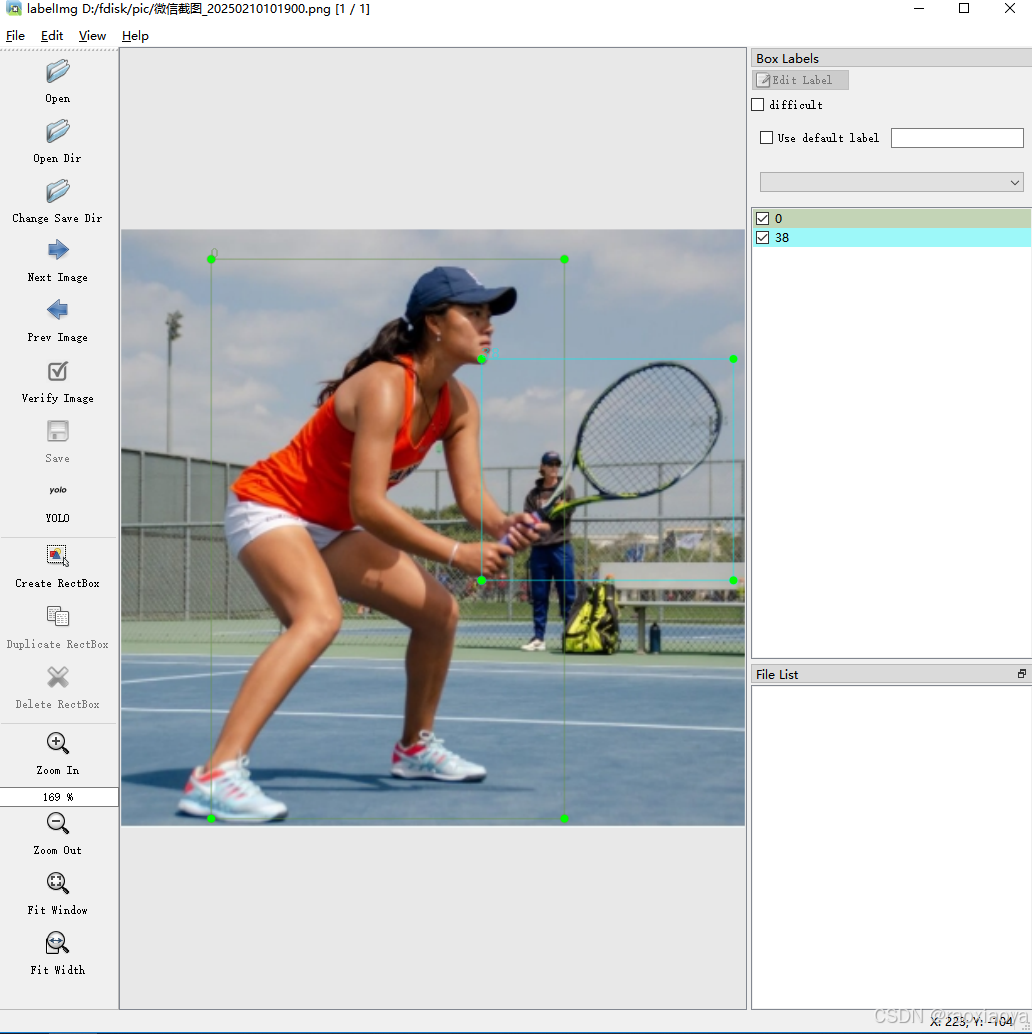
├── classes.txt
├── 微信截图_20250210101900.txt
└── 微信截图_20250210101922.txt
微信截图_20250210101922.txt
0 0.574367 0.505495 0.541139 0.824176
1 0.313291 0.195055 0.234177 0.351648
这里的0, 1是序号而不是对象ID
classes.txt
0
38
这才是对象ID
得到的结构与 coco8 还不一样,还需要将对象ID填充进去。
如果没有自己的数据集,本文提供一个小型数据集(摘自SIMD公共数据集)以供测试代码,包含24张训练集以及20张测试集,约17.7MB,百度云链接:https://pan.baidu.com/s/1sCivMDjfAmUZK1J2P2_Dtg?pwd=1234
我们使用自有数据集来训练模型,也需要按照 coco.yaml的格式来定义配置
train 训练集,val验证集,test测试集
在定义train/val/test的时候,可以是文件夹(比如 coco8.yaml),表示这个目录下的图片是做这个事的,当然你要将图片复制进去。也可以是xxx.txt文件(比如 coco.yaml),把图片文件名列进去。
path: ../datasets/coco # dataset root dir
train: train2017.txt # train images (relative to 'path') 118287 images
val: val2017.txt # val images (relative to 'path') 5000 images
test: test-dev2017.txt
path: ../datasets/coco8 # dataset root dir
train: images/train # train images (relative to 'path') 4 images
val: images/val # val images (relative to 'path') 4 images
test: # test images (optional)
将SIMD公共数据集解压到 datasets/simd 目录下
simd.yaml
# dataset path
path: D:\dev\php\magook\trunk\server\learn-yolo\datasets\simd
train: images/train
val: images/test
test: images/test
# Classes
names:
0: "car"
1: "Truck"
2: "Van"
3: "Long Vehicle"
4: "Bus"
5: "Airliner"
6: "Propeller Aircraft"
7: "Trainer Aircraft"
8: "Chartered Aircraft"
9: "Fighter Aircraft"
10: "Others"
11: "Stair Truck"
12: "Pushback Truck"
13: "Helicopter"
14: "Boat"
path 最好填绝对路径,否则它会使用DATASETS_DIR + path,而DATASETS_DIR的值在C:\Users\Administrator.DESKTOP-TPJL4TC\AppData\Roaming\Ultralytics\settings.json中。
训练模型
def train():
os.environ['KMP_DUPLICATE_LIB_OK'] = 'True'
model = YOLO('yolo11n.pt')
results = model.train(data='./simd.yaml', epochs=10, batch=1, imgsz=640, cache=False,
amp=True, mosaic=False, project='runs/train', name='exp')
- epochs 训练多少轮,通常要大于100
- cache 是否缓存数据集以加快后续训练速度
- batch 输入端每次输入几张图片,这个受限于内存大小
- workers 设置用于数据加载的线程数,更多线程可以加快数据加载速度
Train Settings:https://docs.ultralytics.com/usage/cfg/#train-settings
Ultralytics 8.3.89 🚀 Python-3.11.4 torch-2.6.0+cpu CPU (Intel Core(TM) i7-4790 3.60GHz)
engine\trainer: task=detect, mode=train, model=yolo11n.pt, data=./simd.yaml, epochs=10, time=None, patience=100, batch=1, imgsz=640, save=True, save_period=-1, cache=False,
device=None, workers=8, project=runs/train, name=exp4, exist_ok=False, pretrained=True, optimizer=auto, verbose=True, seed=0, deterministic=True, single_cls=False, rect=Fa
lse, cos_lr=False, close_mosaic=10, resume=False, amp=True, fraction=1.0, profile=False, freeze=None, multi_scale=False, overlap_mask=True, mask_ratio=4, dropout=0.0, val=T
rue, split=val, save_json=False, save_hybrid=False, conf=None, iou=0.7, max_det=300, half=False, dnn=False, plots=True, source=None, vid_stride=1, stream_buffer=False, visu
alize=False, augment=False, agnostic_nms=False, classes=None, retina_masks=False, embed=None, show=False, save_frames=False, save_txt=False, save_conf=False, save_crop=Fals
e, show_labels=True, show_conf=True, show_boxes=True, line_width=None, format=torchscript, keras=False, optimize=False, int8=False, dynamic=False, simplify=True, opset=None
, workspace=None, nms=False, lr0=0.01, lrf=0.01, momentum=0.937, weight_decay=0.0005, warmup_epochs=3.0, warmup_momentum=0.8, warmup_bias_lr=0.1, box=7.5, cls=0.5, dfl=1.5,
pose=12.0, kobj=1.0, nbs=64, hsv_h=0.015, hsv_s=0.7, hsv_v=0.4, degrees=0.0, translate=0.1, scale=0.5, shear=0.0, perspective=0.0, flipud=0.0, fliplr=0.5, bgr=0.0, mosaic=
False, mixup=0.0, copy_paste=0.0, copy_paste_mode=flip, auto_augment=randaugment, erasing=0.4, crop_fraction=1.0, cfg=None, tracker=botsort.yaml, save_dir=runs\train\exp4
Overriding model.yaml nc=80 with nc=15
from n params module arguments
0 -1 1 464 ultralytics.nn.modules.conv.Conv [3, 16, 3, 2]
1 -1 1 4672 ultralytics.nn.modules.conv.Conv [16, 32, 3, 2]
2 -1 1 6640 ultralytics.nn.modules.block.C3k2 [32, 64, 1, False, 0.25]
3 -1 1 36992 ultralytics.nn.modules.conv.Conv [64, 64, 3, 2]
4 -1 1 26080 ultralytics.nn.modules.block.C3k2 [64, 128, 1, False, 0.25]
5 -1 1 147712 ultralytics.nn.modules.conv.Conv [128, 128, 3, 2]
6 -1 1 87040 ultralytics.nn.modules.block.C3k2 [128, 128, 1, True]
7 -1 1 295424 ultralytics.nn.modules.conv.Conv [128, 256, 3, 2]
8 -1 1 346112 ultralytics.nn.modules.block.C3k2 [256, 256, 1, True]
9 -1 1 164608 ultralytics.nn.modules.block.SPPF [256, 256, 5]
10 -1 1 249728 ultralytics.nn.modules.block.C2PSA [256, 256, 1]
11 -1 1 0 torch.nn.modules.upsampling.Upsample [None, 2, 'nearest']
12 [-1, 6] 1 0 ultralytics.nn.modules.conv.Concat [1]
13 -1 1 111296 ultralytics.nn.modules.block.C3k2 [384, 128, 1, False]
14 -1 1 0 torch.nn.modules.upsampling.Upsample [None, 2, 'nearest']
15 [-1, 4] 1 0 ultralytics.nn.modules.conv.Concat [1]
16 -1 1 32096 ultralytics.nn.modules.block.C3k2 [256, 64, 1, False]
17 -1 1 36992 ultralytics.nn.modules.conv.Conv [64, 64, 3, 2]
18 [-1, 13] 1 0 ultralytics.nn.modules.conv.Concat [1]
19 -1 1 86720 ultralytics.nn.modules.block.C3k2 [192, 128, 1, False]
20 -1 1 147712 ultralytics.nn.modules.conv.Conv [128, 128, 3, 2]
21 [-1, 10] 1 0 ultralytics.nn.modules.conv.Concat [1]
22 -1 1 378880 ultralytics.nn.modules.block.C3k2 [384, 256, 1, True]
23 [16, 19, 22] 1 433597 ultralytics.nn.modules.head.Detect [15, [64, 128, 256]]
YOLO11n summary: 181 layers, 2,592,765 parameters, 2,592,749 gradients, 6.5 GFLOPs
Transferred 448/499 items from pretrained weights
Freezing layer 'model.23.dfl.conv.weight'
train: Scanning D:\dev\php\magook\trunk\server\learn-yolo\datasets\simd\labels\train... 24 images, 0 backgrounds, 0 corrupt: 100%|██████████| 24/24 [00:00<00:00, 88.58it/ss
train: New cache created: D:\dev\php\magook\trunk\server\learn-yolo\datasets\simd\labels\train.cache
val: Scanning D:\dev\php\magook\trunk\server\learn-yolo\datasets\simd\labels\test... 20 images, 0 backgrounds, 0 corrupt: 100%|██████████| 20/20 [00:00<00:00, 276.82it/s]
val: New cache created: D:\dev\php\magook\trunk\server\learn-yolo\datasets\simd\labels\test.cache
Plotting labels to runs\train\exp4\labels.jpg...
optimizer: 'optimizer=auto' found, ignoring 'lr0=0.01' and 'momentum=0.937' and determining best 'optimizer', 'lr0' and 'momentum' automatically...
optimizer: AdamW(lr=0.000526, momentum=0.9) with parameter groups 81 weight(decay=0.0), 88 weight(decay=0.0005), 87 bias(decay=0.0)
Image sizes 640 train, 640 val
Using 0 dataloader workers
Logging results to runs\train\exp4
Starting training for 10 epochs...
Closing dataloader mosaic
Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size
1/10 0G 2.332 5.702 1.51 2 640: 100%|██████████| 24/24 [00:20<00:00, 1.20it/s]]
Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 10/10 [00:06<00:00, 1.58it/s]
all 20 146 0 0 0 0
Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size
2/10 0G 2.327 6.118 1.462 5 640: 100%|██████████| 24/24 [00:15<00:00, 1.58it/s]]
Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 10/10 [00:03<00:00, 3.16it/s]
all 20 146 0 0 0 0
Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size
3/10 0G 2.239 5.617 1.536 4 640: 100%|██████████| 24/24 [00:14<00:00, 1.69it/s]]
Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 10/10 [00:03<00:00, 3.06it/s]
all 20 146 0.0224 0.102 0.0308 0.0152
Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size
4/10 0G 2.199 5.524 1.471 9 640: 100%|██████████| 24/24 [00:13<00:00, 1.78it/s]]
Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 10/10 [00:03<00:00, 2.84it/s]
all 20 146 0.0224 0.102 0.0308 0.0152
Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size
5/10 0G 2.15 5.443 1.409 1 640: 100%|██████████| 24/24 [00:13<00:00, 1.79it/s]]
Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 10/10 [00:03<00:00, 3.24it/s]
all 20 146 0.0224 0.102 0.0308 0.0152
Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size
6/10 0G 1.882 5.329 1.337 5 640: 100%|██████████| 24/24 [00:13<00:00, 1.72it/s]]
Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 10/10 [00:03<00:00, 3.07it/s]
all 20 146 0.00469 0.184 0.0375 0.0216
Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size
7/10 0G 2.071 5.78 1.363 22 640: 100%|██████████| 24/24 [00:13<00:00, 1.77it/s]]
Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 10/10 [00:03<00:00, 2.99it/s]
all 20 146 0.00469 0.184 0.0375 0.0216
Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size
8/10 0G 1.929 5.379 1.376 2 640: 100%|██████████| 24/24 [00:13<00:00, 1.76it/s]]
Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 10/10 [00:03<00:00, 2.97it/s]
all 20 146 0.823 0.00714 0.0493 0.0291
Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size
9/10 0G 1.745 5.327 1.143 2 640: 100%|██████████| 24/24 [00:13<00:00, 1.79it/s]]
Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 10/10 [00:03<00:00, 3.05it/s]
all 20 146 0.823 0.00714 0.0493 0.0291
Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size
10/10 0G 1.818 5.315 1.221 4 640: 100%|██████████| 24/24 [00:13<00:00, 1.78it/s]]
Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 10/10 [00:03<00:00, 2.90it/s]
all 20 146 0.823 0.00714 0.0493 0.0291
10 epochs completed in 0.052 hours.
Optimizer stripped from runs\train\exp4\weights\last.pt, 5.5MB
Optimizer stripped from runs\train\exp4\weights\best.pt, 5.5MB
Validating runs\train\exp4\weights\best.pt...
Ultralytics 8.3.89 🚀 Python-3.11.4 torch-2.6.0+cpu CPU (Intel Core(TM) i7-4790 3.60GHz)
YOLO11n summary (fused): 100 layers, 2,585,077 parameters, 0 gradients, 6.3 GFLOPs
Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 10/10 [00:03<00:00, 3.25it/s]
all 20 146 0.823 0.00714 0.0486 0.0289
car 7 50 1 0 0 0
Truck 5 16 1 0 0 0
Van 9 23 1 0 0 0
Long Vehicle 1 7 1 0 0.00252 0.000757
Bus 3 5 1 0 0.00539 0.000539
Airliner 14 14 0.231 0.0714 0.392 0.243
Trainer Aircraft 2 11 1 0 0.0862 0.0452
Others 5 10 1 0 0 0
Stair Truck 5 6 0 0 0 0
Pushback Truck 3 4 1 0 0 0
Speed: 3.8ms preprocess, 120.5ms inference, 0.0ms loss, 5.8ms postprocess per image
Results saved to runs\train\exp4
...
...
从输出信息可以看到训练后模型权重保存在runs\train\exp4\weights,当然这不是固定的,要以输出为准。
验证模型
Validation Settings:https://docs.ultralytics.com/usage/cfg/#validation-settings
def val():
os.environ['KMP_DUPLICATE_LIB_OK'] = 'True'
model = YOLO("runs/train/exp4/weights/best.pt")
results = model.val(data='./simd.yaml', split='val', batch=1, project='runs/val', name='exp', half=False)
Ultralytics 8.3.89 🚀 Python-3.11.4 torch-2.6.0+cpu CPU (Intel Core(TM) i7-4790 3.60GHz)
YOLO11n summary (fused): 100 layers, 2,585,077 parameters, 0 gradients, 6.3 GFLOPs
val: Scanning D:\dev\php\magook\trunk\server\learn-yolo\datasets\simd\labels\test.cache... 20 images, 0 backgrounds, 0 corrupt: 100%|██████████| 20/20 [00:00<?, ?it/s]
Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 20/20 [00:03<00:00, 5.73it/s]
all 20 146 0.823 0.00714 0.0486 0.0289
car 7 50 1 0 0 0
Truck 5 16 1 0 0 0
Van 9 23 1 0 0 0
Long Vehicle 1 7 1 0 0.00252 0.000757
Bus 3 5 1 0 0.00539 0.000539
Airliner 14 14 0.231 0.0714 0.392 0.243
Trainer Aircraft 2 11 1 0 0.0862 0.0452
Others 5 10 1 0 0 0
Stair Truck 5 6 0 0 0 0
Pushback Truck 3 4 1 0 0 0
Speed: 2.8ms preprocess, 144.3ms inference, 0.0ms loss, 5.9ms postprocess per image
Results saved to runs\val\exp
模型预测
def predict2():
model = YOLO("runs/train/exp4/weights/best.pt")
results = model(["datasets/simd/images/train/0011.jpg"])
for k, result in enumerate(results):
filename = util.generate_random_string(15)
result.save(filename="imgs_result/"+filename+".jpg")
0: 480x640 (no detections), 133.2ms
Speed: 6.1ms preprocess, 133.2ms inference, 1.1ms postprocess per image at shape (1, 3, 480, 640)
但是它并没有检测到对象。。。
于是将 train 的 epochs 改成 100,重新训练。这次它能识别到了。
0: 480x640 2 Airliners, 134.8ms
Speed: 5.4ms preprocess, 134.8ms inference, 2.0ms postprocess per image at shape (1, 3, 480, 640)
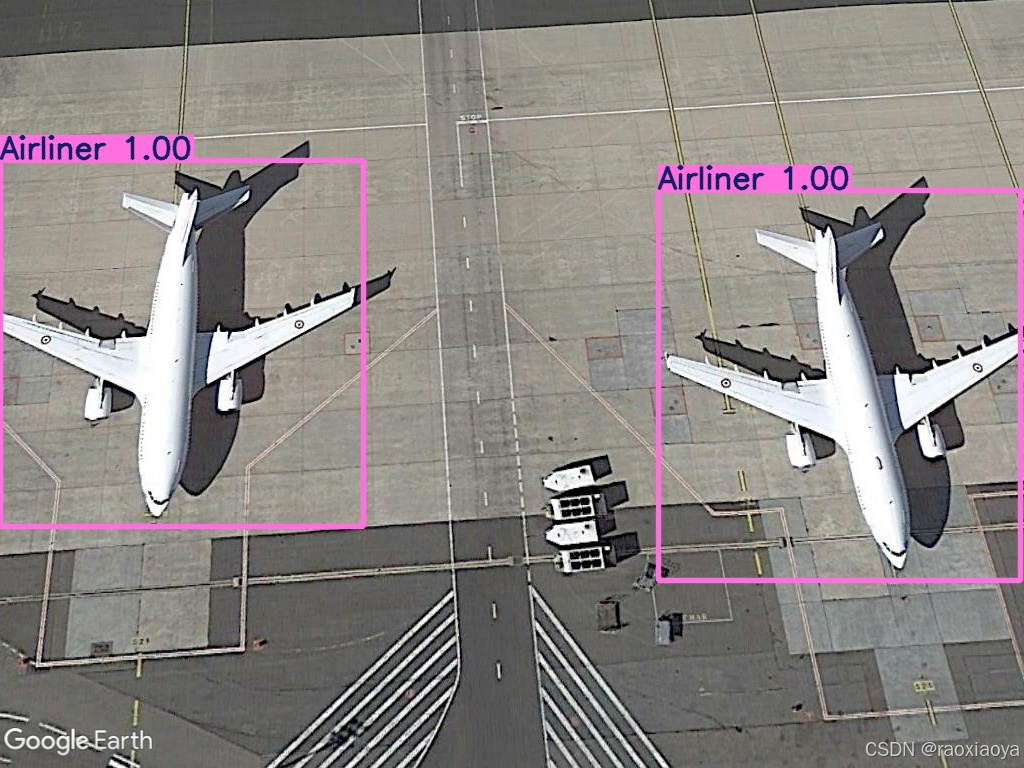
那为什么 epochs 参数能影响模型的效果呢,它代表训练多少轮,这就是一个“熟能生巧”的过程,跟人类的学习过程是一样的,一本书你看一百遍总比看十遍要理解的透彻一些。
以下是通义千问的回答:
epochs参数在训练模型时代表整个训练集将被遍历的次数。这意味着,如果你设置epochs=10,那么训练集中的每个样本都会被网络看过10次。这个参数对模型的效果有着直接的影响,主要原因如下:
- 学习机会增加:随着epoch数量的增加,模型有更多机会去学习数据集中的模式和特征。理论上,更多的epoch可以让模型更好地拟合训练数据。
- 误差减少:在一个epoch过程中,模型通过反向传播算法调整其权重以最小化损失函数(即预测值与实际值之间的差异)。因此,通常情况下,随着epoch数量的增加,模型的总体误差会逐渐减少。
- 过拟合风险:然而,这并不意味着epoch越多越好。如果epoch数量过多,模型可能会开始记住训练数据的具体细节,而不是学习通用的模式来做出预测。这种现象称为过拟合,它会导致模型在未见过的数据上表现不佳。
- 收敛性:对于某些模型而言,经过一定数量的epoch后,性能提升会变得微乎其微,因为模型已经接近最优解。在这种情况下,继续增加epoch数量可能不会带来显著的好处。
- 计算成本:更多的epoch也意味着更高的计算成本。因此,在实践中,需要找到一个平衡点,既能使模型达到满意的性能水平,又不会导致过高的计算开销。
模型导出
将 pt 模型导出为其他格式的。
支持的格式:https://docs.ultralytics.com/tasks/detect/#export
阅读


















 411
411

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









