



目录
目录
背景
行人检测 目标检测 行人追踪是当前的热点
应用图像处理技术,结合计算机视觉可以得到目标检测和追踪的效果,目前比较流行的是深度学习,transfmer,MLP等方法
深度学习有CNN,SSD,yolo算法等,yolov1-yolov5都可以进行很好的目标检测,行人检测,目标追踪等问题,可以给大家带来很好的效果,目前主流的开发语言是python,基于pytocrh或者ztensorflow框架进行编程处理
当然比较流行的方法有 hogsvm gaborsvm等,都在开始的时候广泛的应用到行人检测的方法中
但是最原始的基于图像处理技术还是很值得研究的,本文主要采取图像处理技术,进行行人检测的技术研究。
并且不断和持续的更新采取和探索的技术。
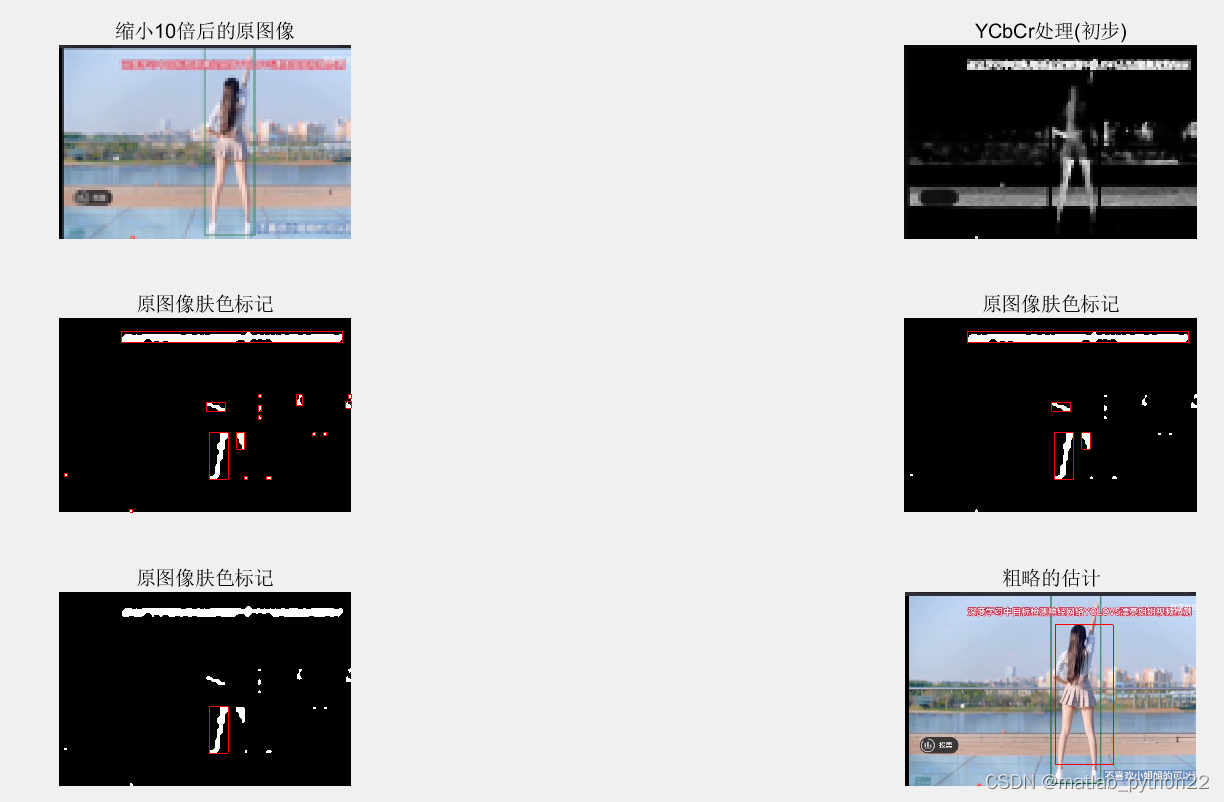
一 基于腿部定位的粗略估计方法
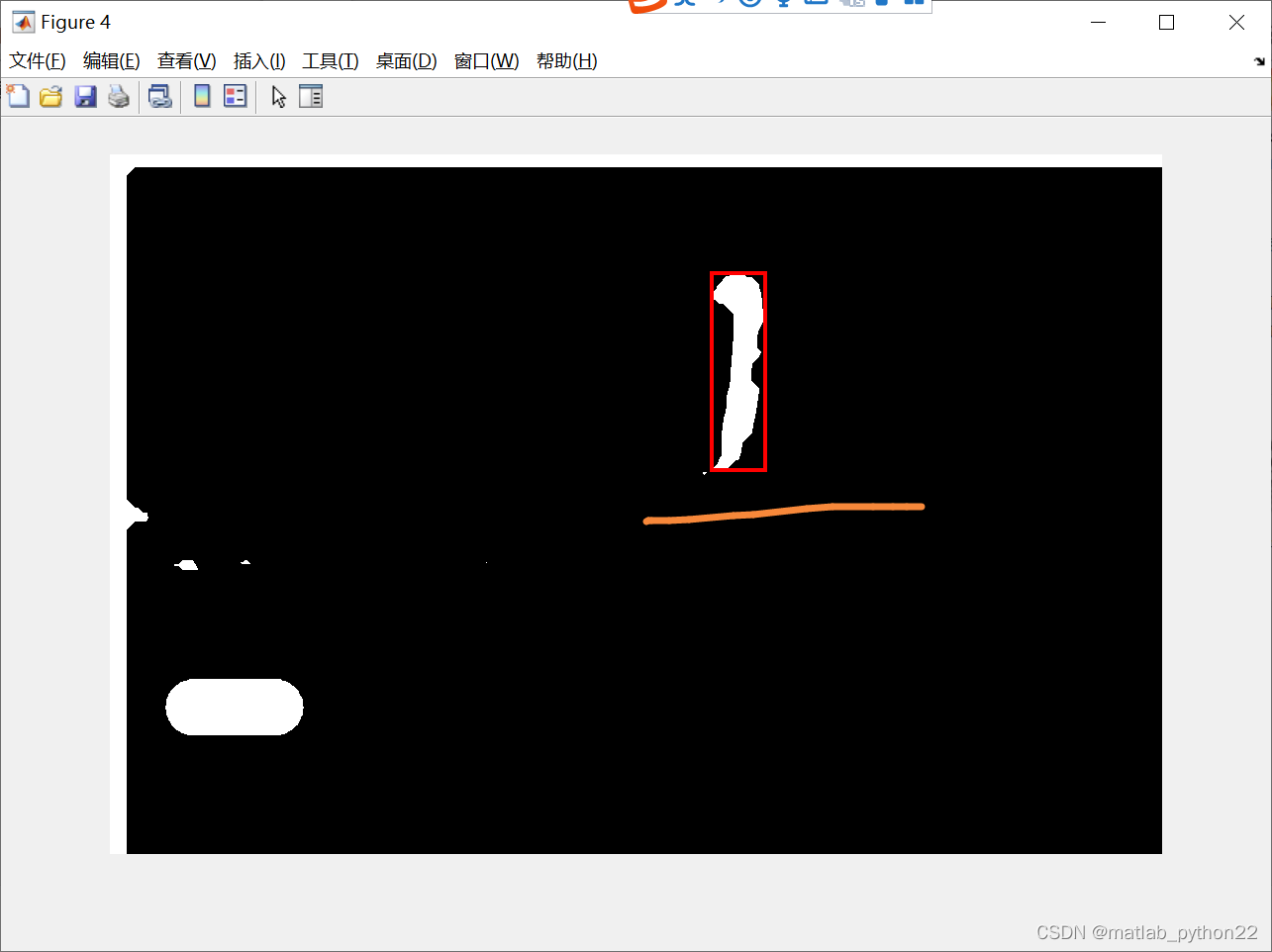
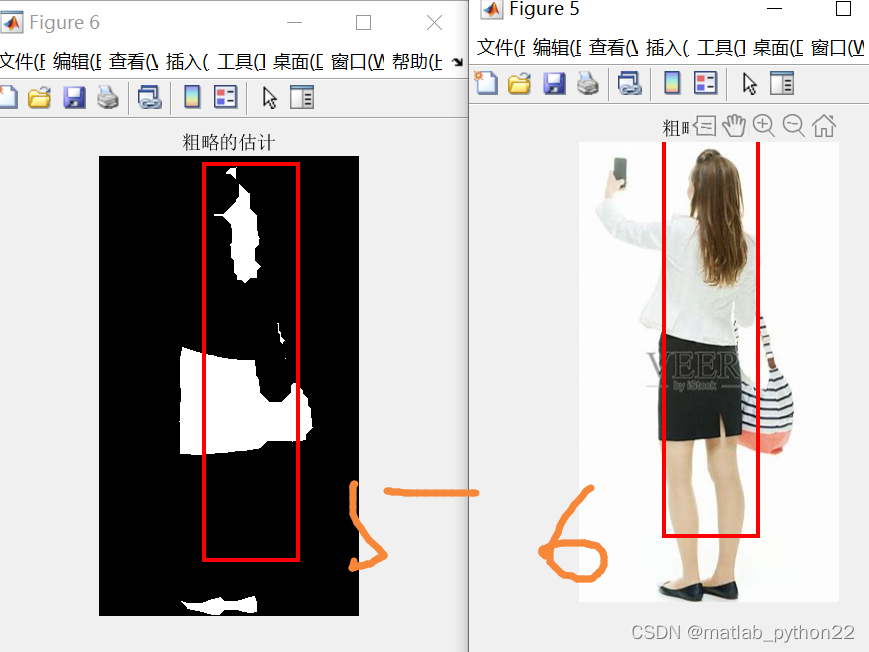
这是进行粗略估计的 结果
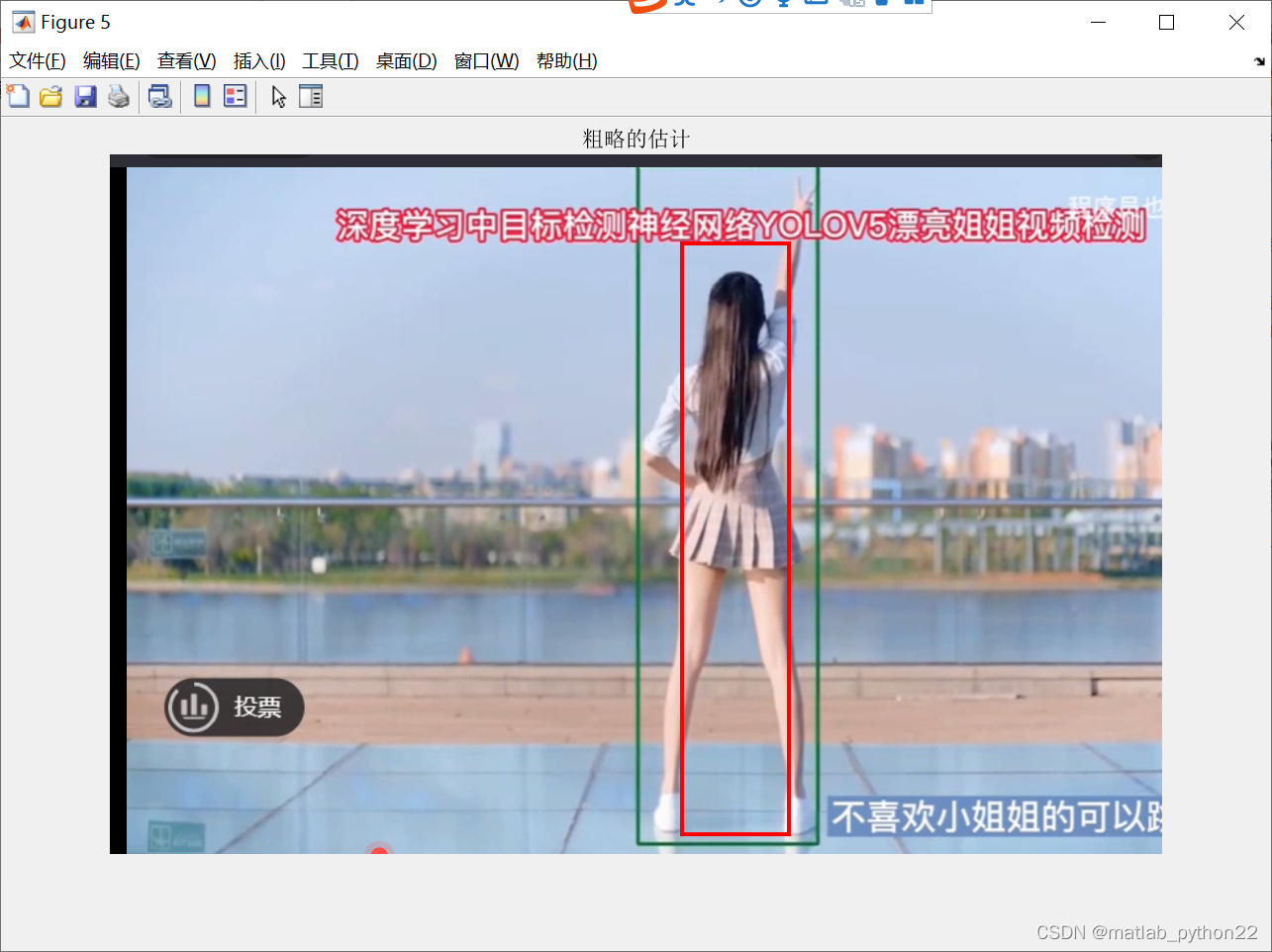
原始的视频是基于yolov5的结果
本文主要采取图像处理的结果
通过观察视频,可以看出小姐姐的肤色腿部很明显
那么根据图像处理的基本常识,首先定位到肤色,基于ycbcr的模型 得到粗略的分割模型 也就是杉树图中的第二幅图
然后对分割的图进行一系列的操作,比如闭运算等,得到第三幅图,并且画出来连通域
通过观察第三幅图的连通域,可以知道很多小的连通域也被标记出来,因此删除了很小的面积的,得到了第四幅图
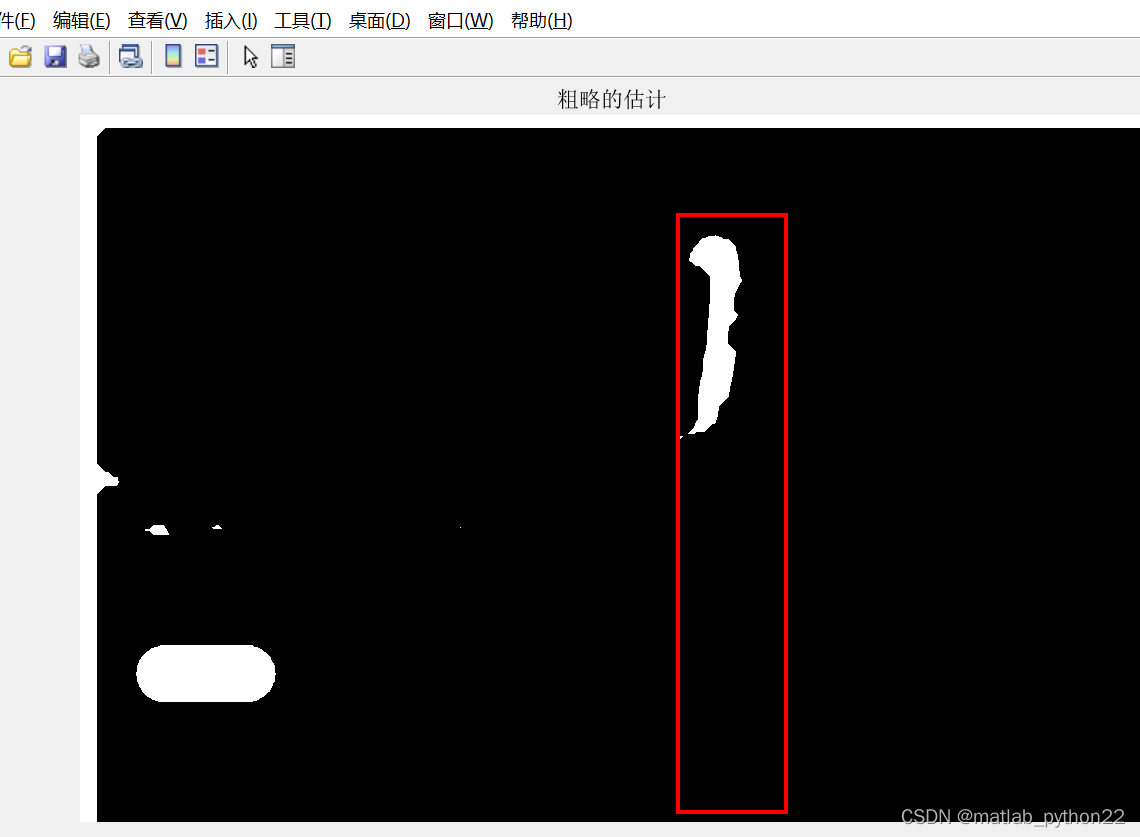
通过第四幅图,可以看出在上册有一个横幅是在干扰我们的识别,因此对于长宽比在大于2的时候,将横幅屏蔽,因此屏蔽后的结果图如上述的第五幅图
根据第五幅图,那么定位到腿部,然后根据人体的比例,将外接矩形的坐标和长宽进行设计,得到最后估算的结果数据。。
通过调整参数和配置,得到的其他数据的结果如下
code的下载地址
不用深度学习,基于图像处理的人体粗略估计-统计分析文档类资源-优快云文库
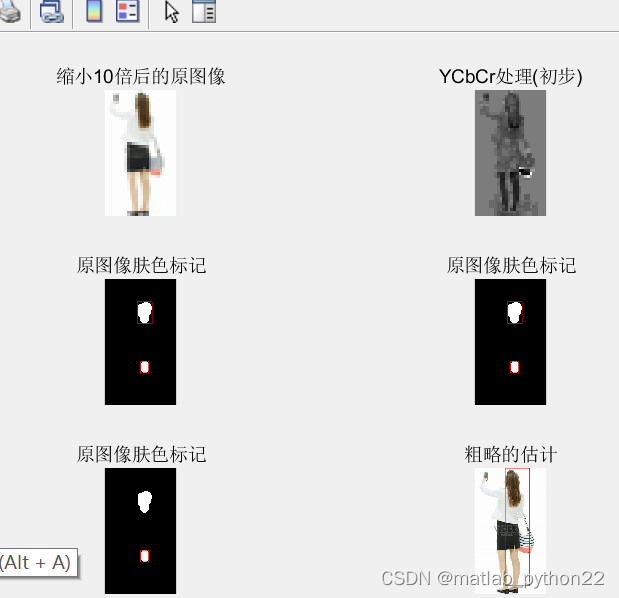
二 基于头发定位位的粗略估计方法
方法为粗略的定位到头发
然后去除干扰区域
然后根据身体的特征,得到数据的结果
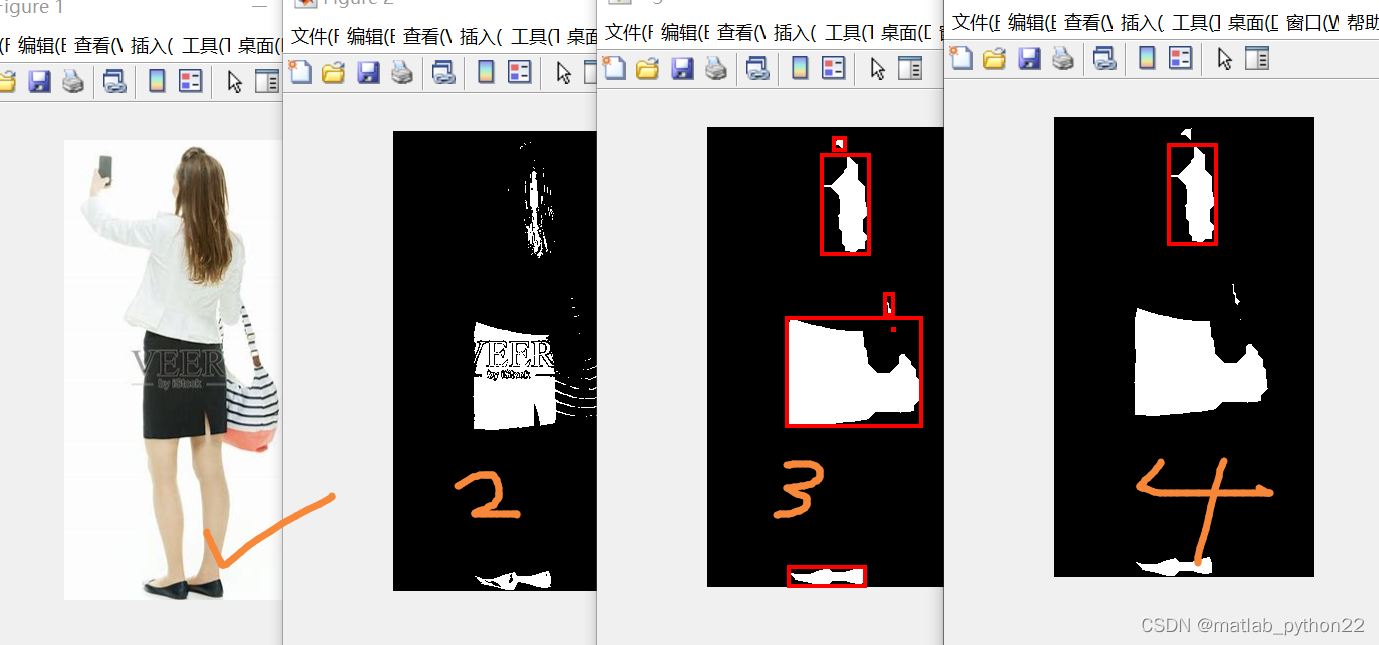
图 袁术图像
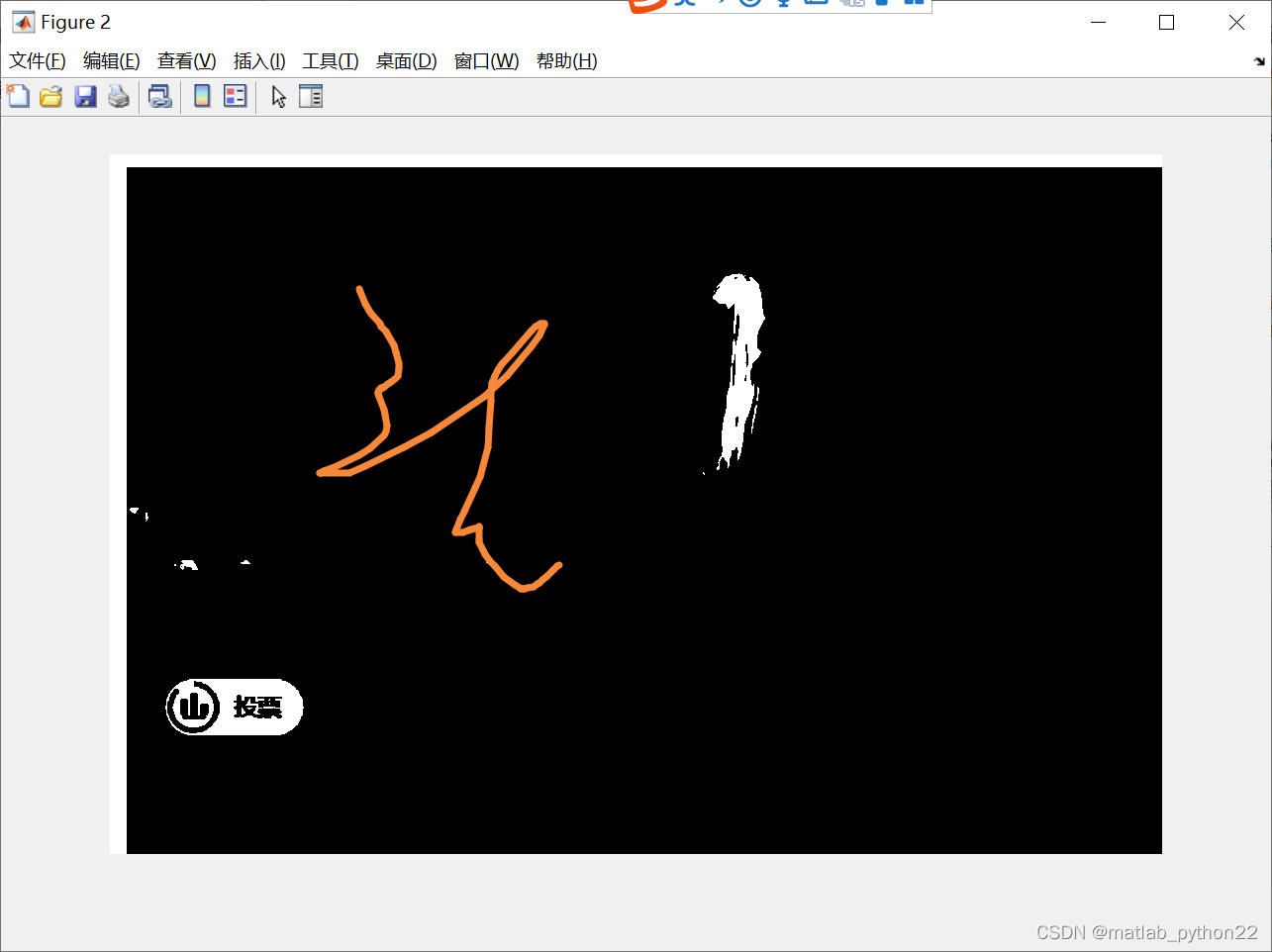
他 定位到头发区域
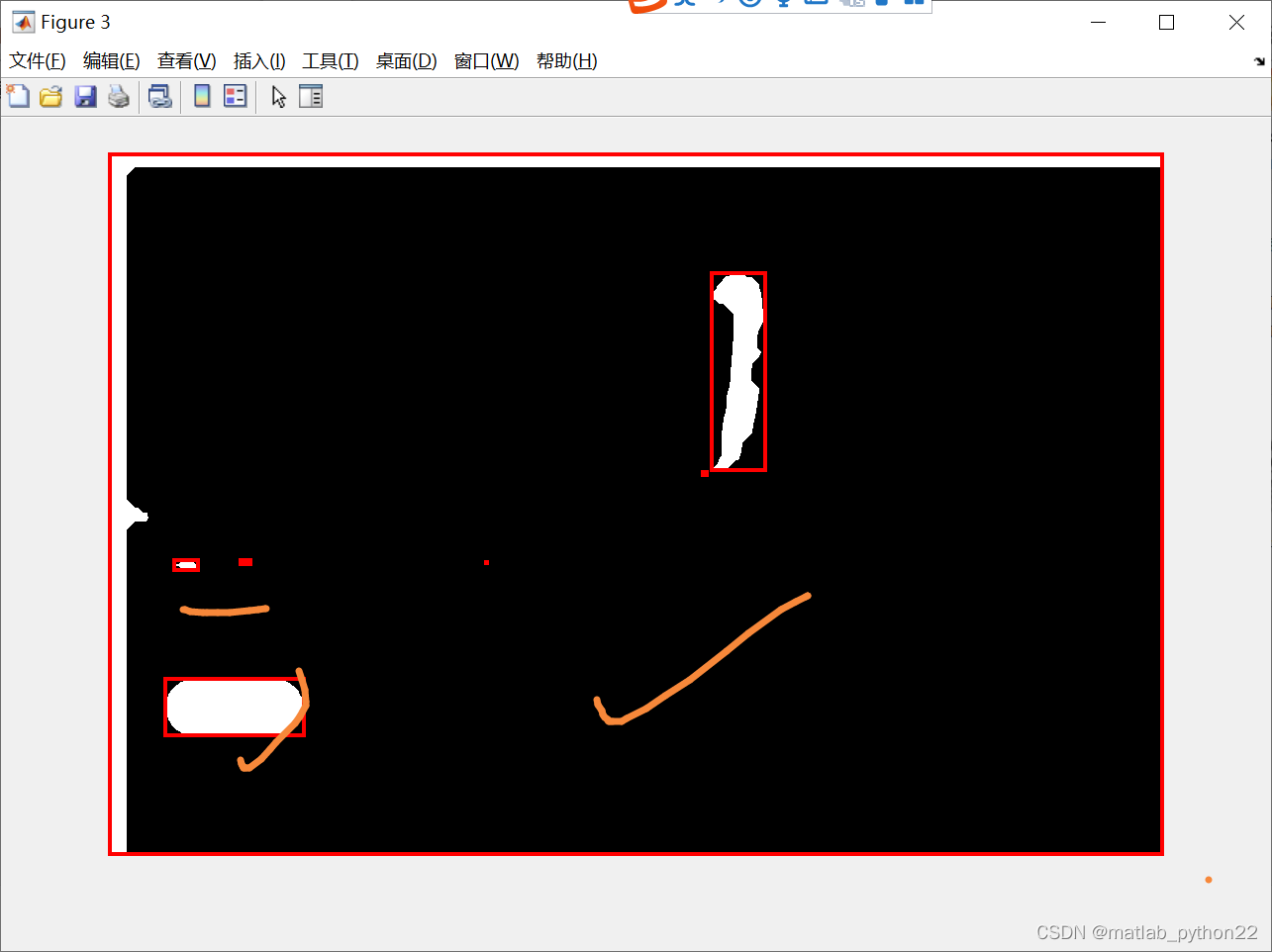
粗略得到连通域
删除无关的连通域
根据体型得到粗略估计
得到原来的图像得到人体的估计
可以看出能粗略得到人体数据吧
其他数据的结果见
可以看出可以通过头发 粗略的得到数据
所有的试验原始图像来源于网络 如果有侵权,请联系作者删除
详细code见
(2条消息) 二基于头发定位位的粗略估计方法-其它文档类资源-优快云文库
---------------------2022.5.29-------
----------------------持续更新---------------------------
三 基于图像图形二值化—+灰度投影法的结果
持续更新
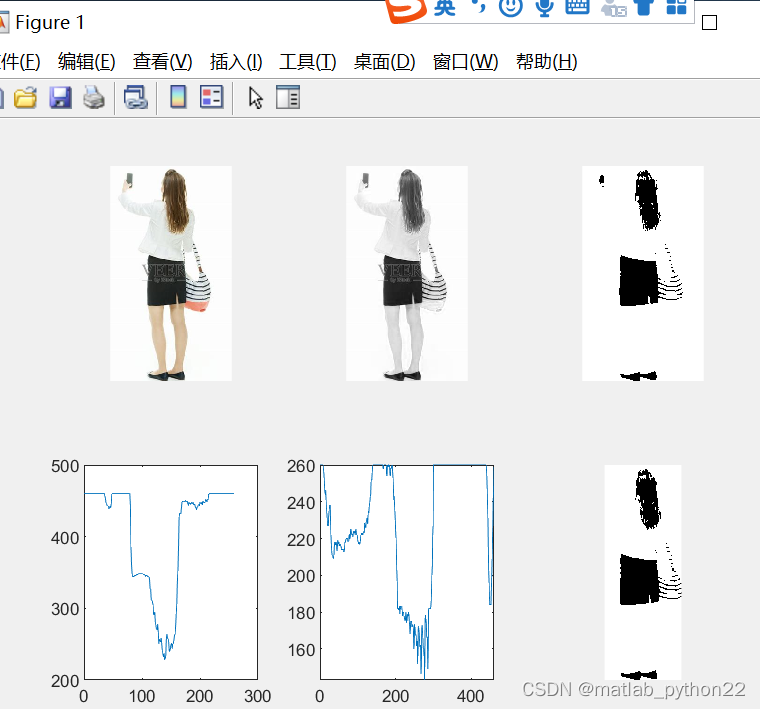
首选得到RGB 然后选择r通道做实验
对r通道,进行二值化
然后求求解得到灰度投影曲线,垂直投影和水平投影曲线
得到的结果如上所示
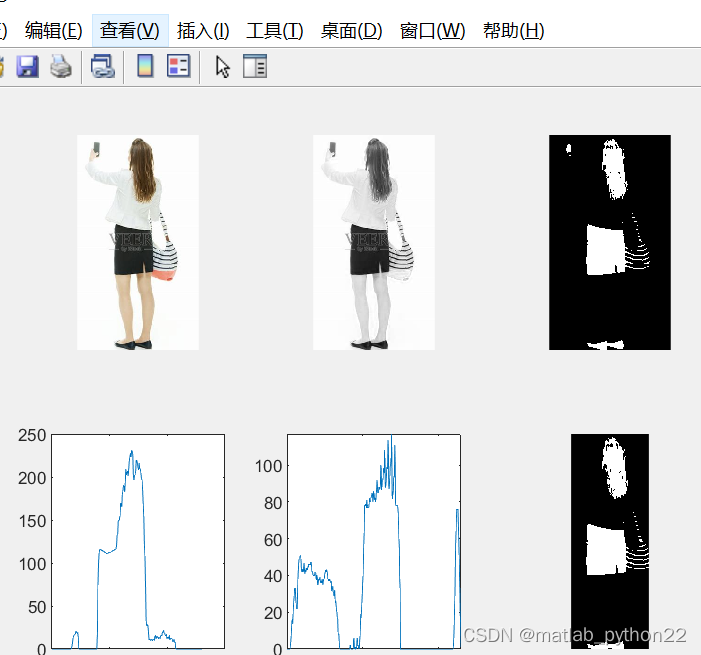
图 经过二值化翻转后的数据结果,可以看出,在第四个图像上,可以很明显的可以看出来人体的大概的卷度,因此对于人员的定位骐达了关键的作用
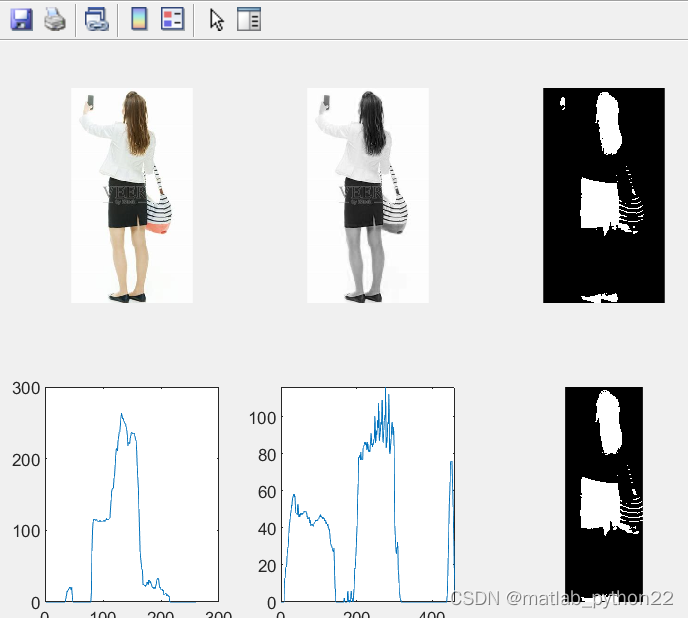
图 采取的第三个通道做的数据研究
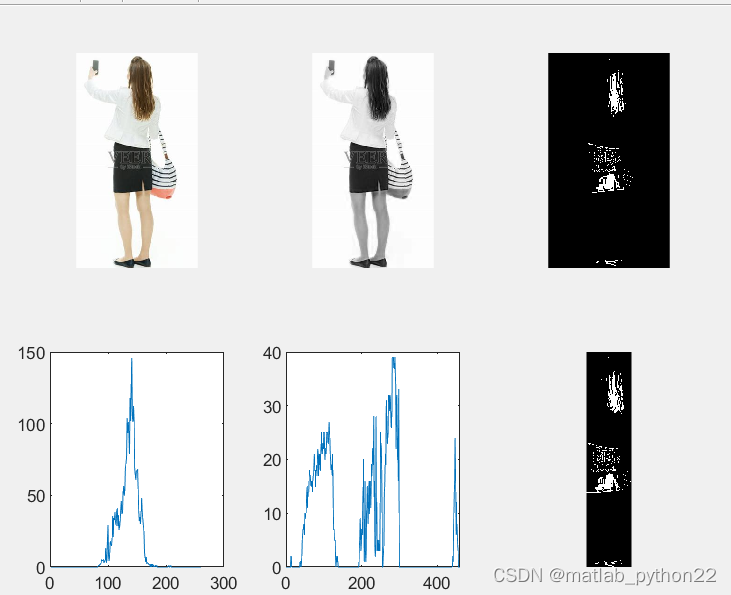
图 当改变otsu的阈值时候,这时候的阈值是0.13.得到的数据结果如上所示
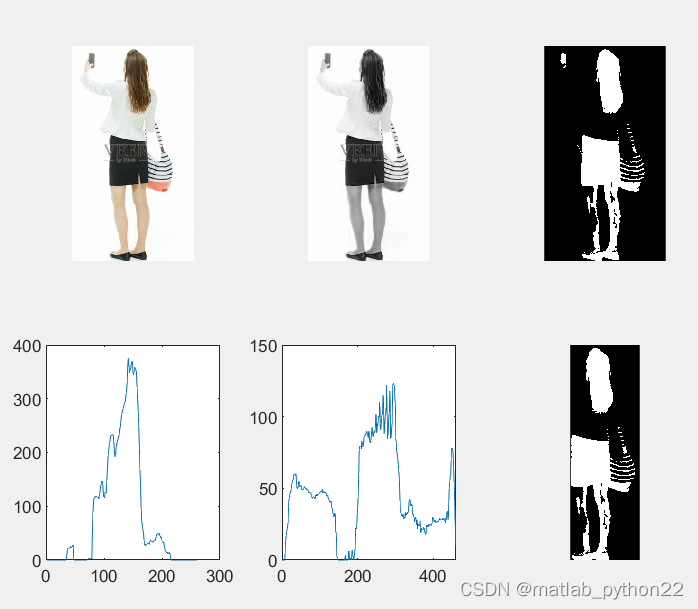
阈值是0.53的数据结果
详细的code
四 基于kmeans聚类分割+图像处理的结果
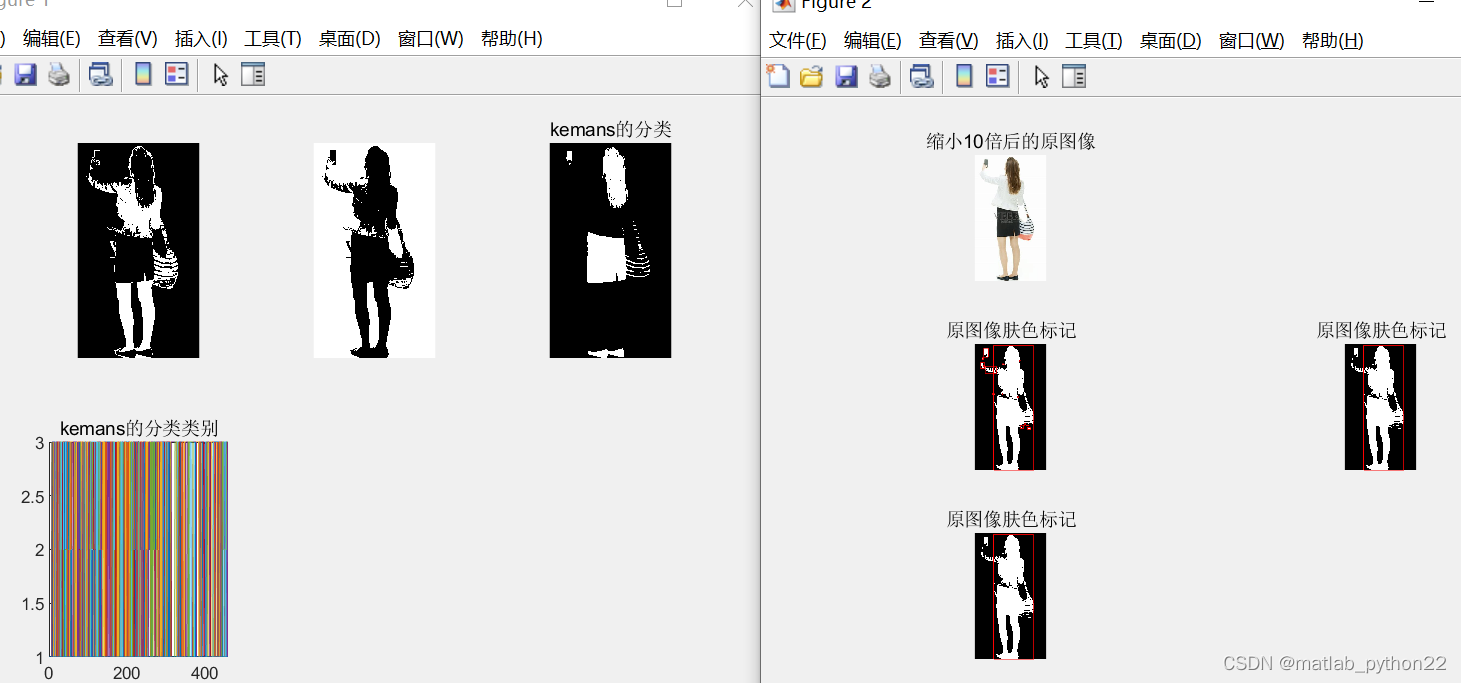
上述的图 第一个是kmeans的数据结果
这里聚类成三类,可以卡出第二个图像的数据较好,可以聚类很明显的区分出来
右侧的图,经过数据分析后,用二值化处理,加上膨胀操作,进一步得到了原始数据的边界框 ,得到人体
详细的code见
四基于kmeans聚类分割+图像处理的结果-其它文档类资源-优快云文库
五 边缘检测+图像腐蚀操作等确定人体位置
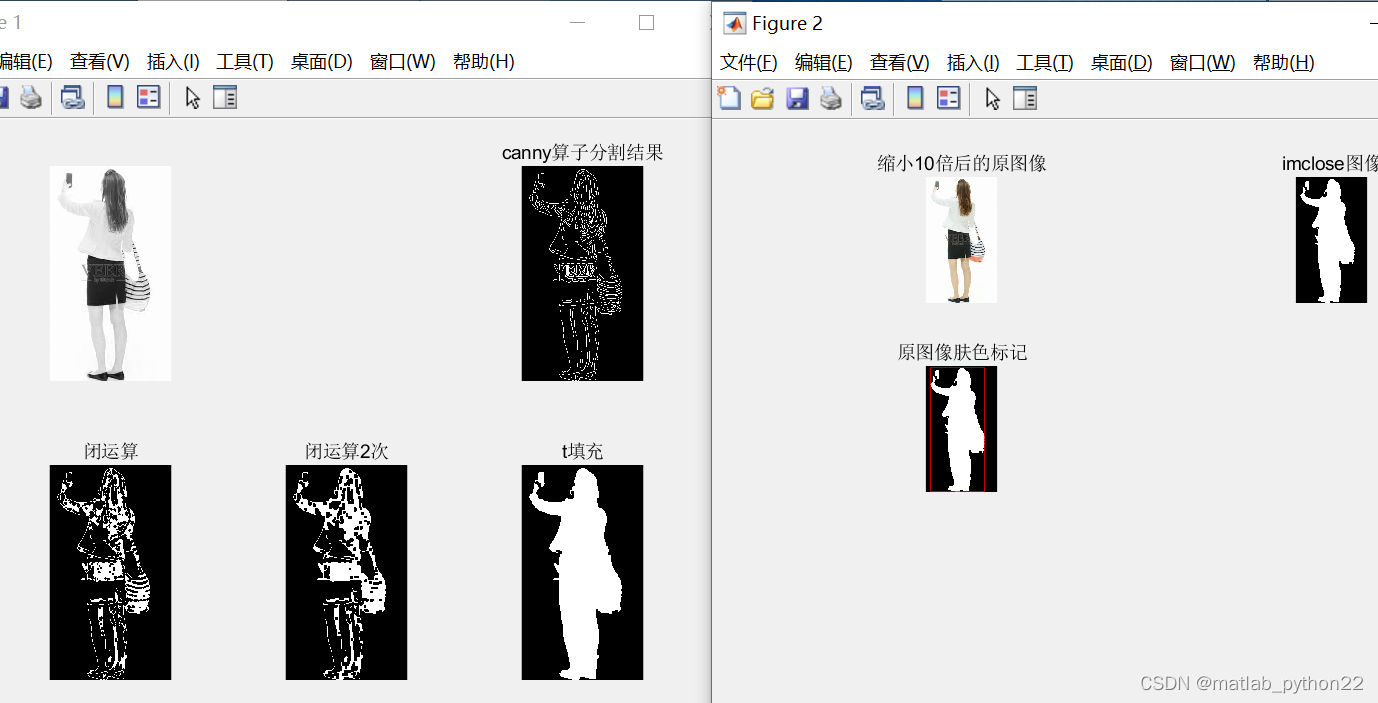
首选确定了candyB边缘检测
然后进行闭运算
进行闭运算后,进一步进行填充操作
填充完毕,进一步进行imclose操作,求解外接矩形,得到最后的数据结果
当然选择其他的边缘检测时候
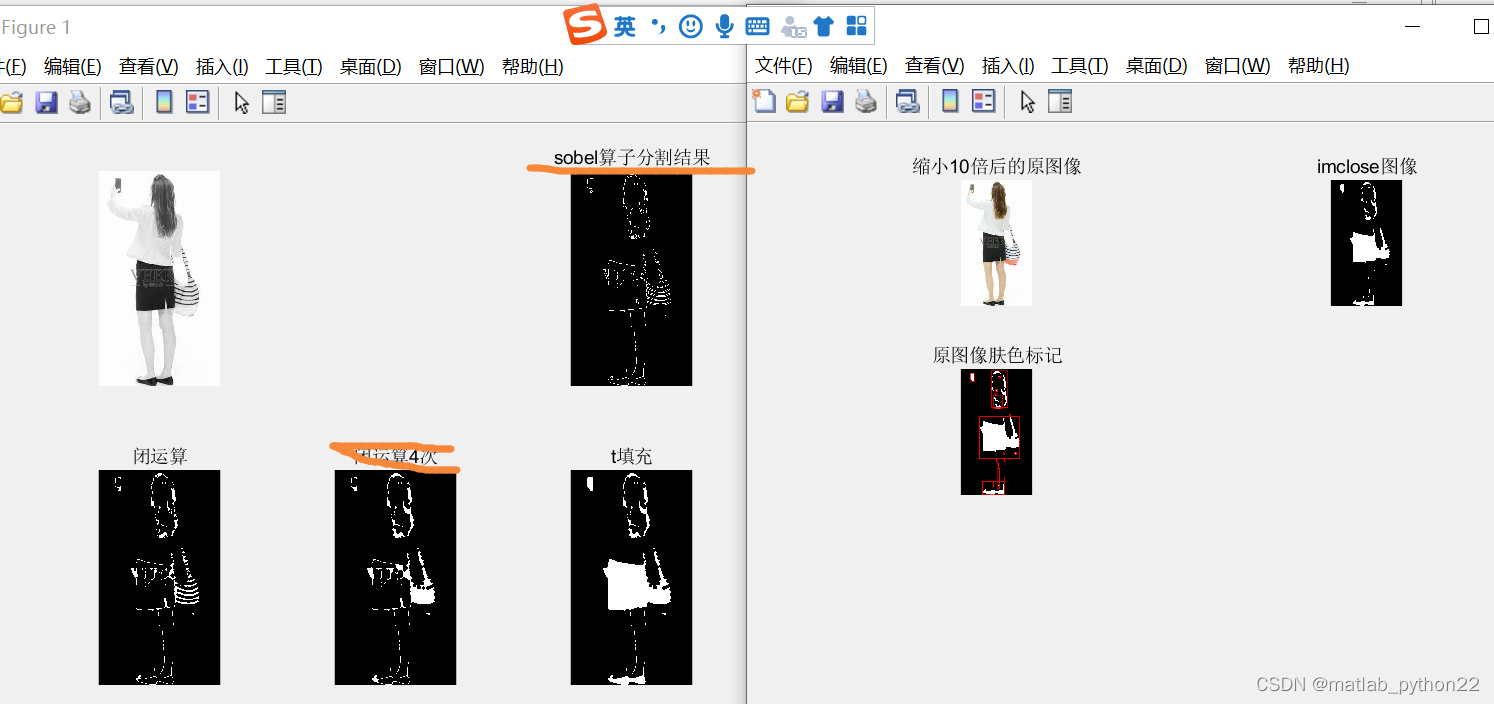
效果不是很好
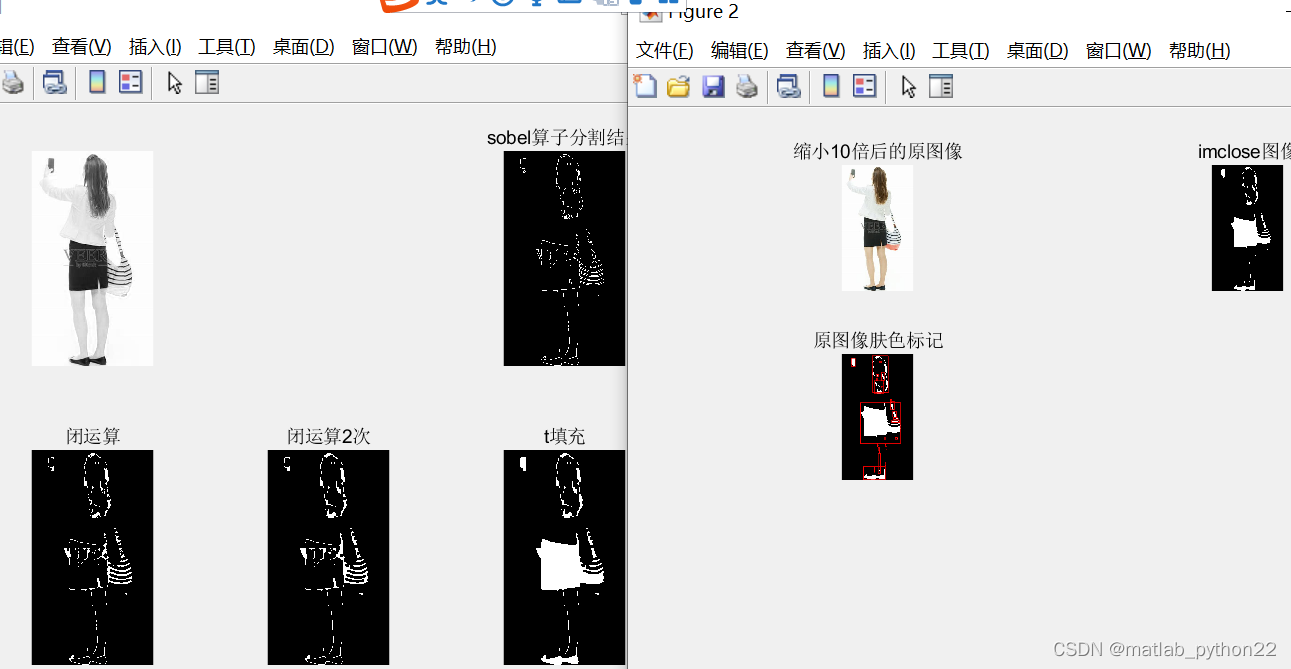
当采取soble算法,采取4次闭运算的时候结果,如上所示
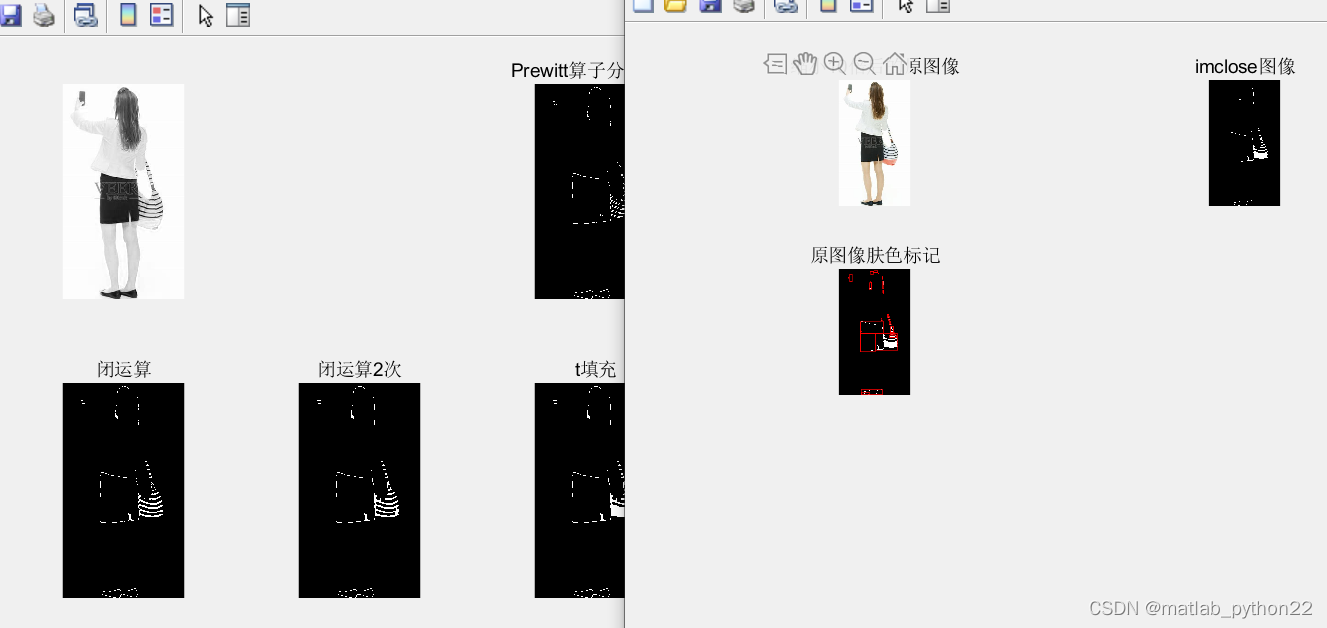
当选择 prewitte算法的时候,得到的结果也不好

当选择log算子,并且最后进行区域面积筛选,得到的结果较好
详细的code见
基于边缘检测和图形处理的,人体区域定位和检测-机器学习文档类资源-优快云文库


















 2861
2861

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











