




 本文介绍了随着计算机技术的发展,语音识别尤其是说话人识别技术的重要性日益凸显。说话人识别作为一种生物认证技术,利用语音特征进行身份验证,具有非接触性、便捷性和经济性。预处理步骤包括预加重、分帧、加窗和端点检测,其中端点检测对于提高识别精度至关重要。此外,文章还提到了一种用于计算两个音频相似度的欧氏距离方法。说话人识别技术在互联网时代有着广泛的应用前景,特别是在安全和便捷的身份验证需求中。
本文介绍了随着计算机技术的发展,语音识别尤其是说话人识别技术的重要性日益凸显。说话人识别作为一种生物认证技术,利用语音特征进行身份验证,具有非接触性、便捷性和经济性。预处理步骤包括预加重、分帧、加窗和端点检测,其中端点检测对于提高识别精度至关重要。此外,文章还提到了一种用于计算两个音频相似度的欧氏距离方法。说话人识别技术在互联网时代有着广泛的应用前景,特别是在安全和便捷的身份验证需求中。
1 简介
伴随着计算机技术和信息化技术的蓬勃发展,人机交互技术扮演着越来越重要的角
色,人类希望计算机和人之间的交互能够突破鼠标和键盘等外围设备的局限,希望以一个智能化的方式使得计算机和人之间能够畅通无阻地交流,于是,语音,作为人的自然属性,是一个上上之选。众所周知,语音,是人与人之间进行信息交互的一种最直接的手段,通过语音,使计算机和人能够直接交流,必然离不开语音识别技术。广义的语音识别是指计算机能够对人的语音指令进行正确的响应的一种技术,它包括有语音识别技术(识别语音的内容)、说话人识别(也称为声纹识别,用来鉴定说话人身份的一种技术)、语种识别(能够对待识别的语音的种类进行识别)以及说话评分(对语音的标准程度打分)。
在数字信息化时代,互联网技术的发展使得对身份验证技术有更高的要求,不仅需
要安全性好,而且需要便捷和经济,同时由于传统的基于密码的身份验证方法具有很多不安全性,因此,基于信息技术和生物学的新一代身份验证方式。目前使用广泛的基于人的生理特征的生物认证方法有指纹识别、虹膜识别、人脸识别和说话人识别等,这些生物认证方法在身份鉴定时,安全性和识别准确性更高。说话人识别是一种生物认证技术,它从采集到的语音信号中提取出能够反映说话人生理和行为特征的特征参数,从而对说话人身份进行自动鉴别。在互联网技术和信息技术的快速发展趋势的推动下,说话人识别技术成为当今语音信号处理领域中的研究热点,它在各个领域中以其独特的方便性、经济性和准确性,将会受到世人瞩目。
因为每位说话人的发音器官都有一定的生理差异,在后天的生活中,都具有一定的
发音习惯和行为差异,因此使用语音来进行说话人身份验证,有着独特的优点,不仅由于语音是人的自然属性,具有非接触性和方便性,这种身份认证方式更容易让用户接受,而且采集人的语音的设备成本不高,同时采集方便,更重要的是,可以远程进行身份验证,通过移动电话、电信网络或者其他设备,可以实现远程的客户服务,相比其他的生物验证,说话人识别技术有着广阔的应用前景。说话人识别技术是一种综合性的课题,从中涉及到模式识别、统计学理论、人工智能、生理学以及语音信号处理等知识领域。
在对语音信号进行分析处理之前,需要对语音信号进行预处理,预处理步骤包括对
语音信号进行预加重、分帧、加窗和端点检测等。
(1) 预加重
因为发声过程中声带和嘴唇的效应,语音信号在 8000Hz 以上的高频时约按 6dB/oct衰减,为此需要在预处理中进行预加重。预加重的目的是提升高频部分,使信号的频谱变得平坦,有利于进行频谱分析或声道参数的分析。预加重可以在防混叠滤波与 A/D 转换之前进行,这样,不仅能够进行预加重,而且可以压缩信号的动态范围,有效地提高信噪比,预加重也可以在 A/D 转换之后进行,用具有 6dB/oct 地提升高频特征预加重数字滤波器实现。其公式为
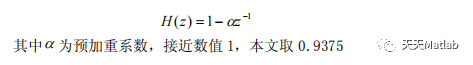
(2) 分帧和加窗
语音信号是一种非平稳的时域信号,但是具有短时平稳性,即语音信号在短时间内
可以看做是平稳信号,研究发现,在 5~50ms 的范围内,语音频谱特征和一些物理特性参数基本保持不变,因此需要对语音信号进行分帧,即将语音信号划分为很多短时间的语音段,每个短时间的语音段称为一个分析帧,在一帧的语音信号中,可以采用平稳过程的分析处理方法来处理每一帧的信号。帧既可以是连续的,也可以是交叠分帧,一般帧长为 10~30ms,取数据时,前后两帧的交叠部分称为帧移,帧移一般取帧长的 0~1/2。
信号进行分帧处理截短后,将会产生能量泄漏现象,分帧后的加窗处理,就是用一
个窗函数与信号相乘,从而形成加窗信号,其作用是减少分帧处理所带来的频谱泄露,对提取的语音信号进行研究。在分帧的时候,相当于用一个矩形窗与语音信号进行频谱的周期卷积,由于矩形窗频谱的旁瓣较高,信号的频谱会产生“拖尾”,即频谱泄漏,泄漏与窗函数频谱的两侧旁瓣有关,如果两瓣的高度趋于零,而使得能量相对集中在主瓣,就可以接近真实的频谱。因此可以采用不同的窗函数进行加窗处理,可以减低频谱泄露的影响,得到平滑的频谱。设窗长为 N,窗函数主要有下面几种:
z矩形窗

语音端点检测是通过数字化处理方法去检测语音的端点,把语音中的干扰和噪声去
除,区分噪声段和语音段,把需要的语音部分提取出来的一种语音处理方法。端点检测是语音分析、合成和识别中不可缺少的一部分。端点检测的准确性直接影响到识别系统的性能,较高的端点检测能够在识别中防止噪声的影响,提高识别精度,同时可以在语音分析中能够减少计算量和处理时间,优化系统性能,在应用环境下,难以得到纯净的语音段,由于录音环境、音频收集设备和其他的传输系统,都会带来一定的噪声影响,因此如何在噪声的影响下,如何得到准确的检测语音的端点,是语音信号处理的一个重要的研究方向。
目前,在时域上,常用的端点检测方法有基于短时能量法、基于过零率法、基于短
时能量和过零率的双门限端点检测方法。在频域上,常用的端点检测方法有基于子带谱熵和基于频带方差的端点检测算法等。这些方法在背景噪声的影响下,不是识别准确性不高,就是计算量大,影响系统的整体性能。
在实际应用中,有效的端点检测具体要求是:(1)设置的门限值要根据背景噪声的变化做自适应调整,满足在不同的环境下进行端点检测;
(2)不能丢失语音的一些能量较低的有效成分,比如爆破音和鼻音等,否则会影响最后的识别效果;
(3)能够在各种噪声环境下都具有准确的检测效果;
(4)计算量小,应用方便。在说话人识别中,端点检测的主要是为了得到说话人语音的起始端点。有效的端点检测方法,不仅能减少整个系统的计算量,而且有利于系统的实时识别,提高系统的整体性能。






2 部分代码
function d = disteu(x, y)[M, N] = size(x); %1音频x赋值给【M,N】[M2, P] = size(y); %音频y赋值给【M2,P】if (M ~= M2)error('不匹配!') %两个音频时间长度不相等endd = zeros(N, P);if (N < P)%在两个音频时间长度相等的前提下copies = zeros(1,P);for n = 1:Nd(n,:) = sum((x(:, n+copies) - y) .^2, 1);endelsecopies = zeros(1,N);for p = 1:Pd(:,p) = sum((x - y(:, p+copies)) .^2, 1)';end%%成对欧氏距离的两个矩阵的列之间的距离endd = d.^0.5;
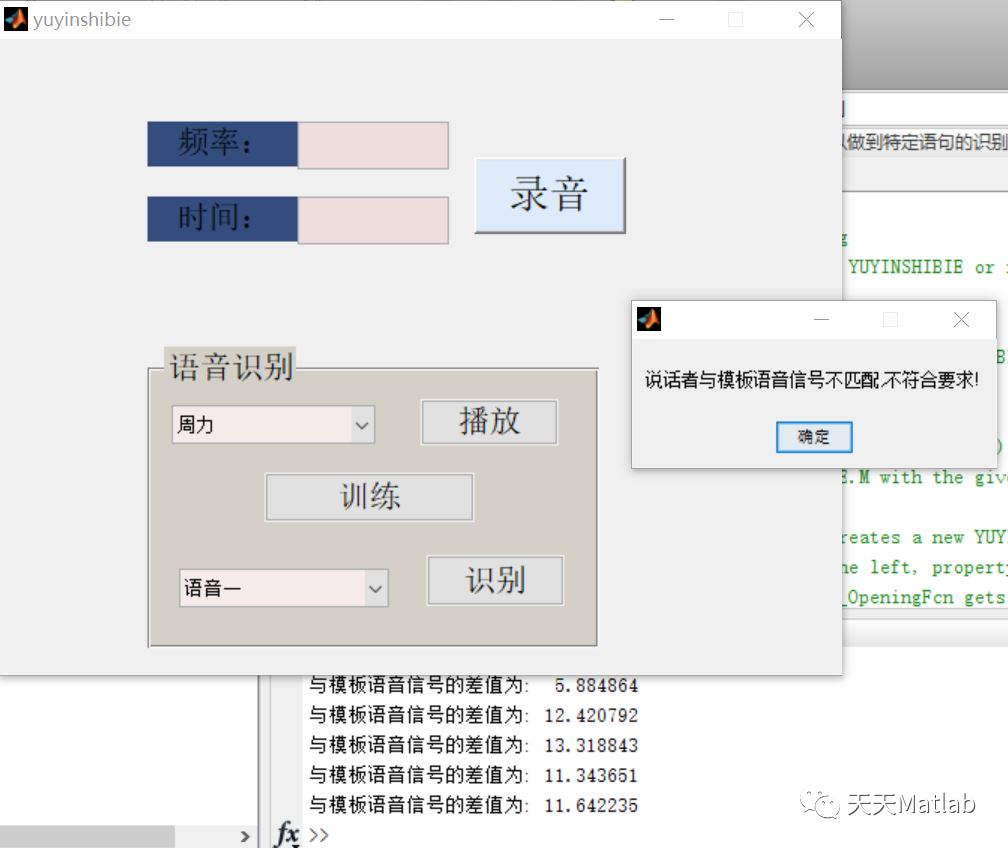
3 仿真结果
4 参考文献
[1]王伟, 邓辉文. 基于MFCC参数和VQ的说话人识别系统[C]// 第四届全国信息获取与处理学术会议. 0.
博主简介:擅长智能优化算法、神经网络预测、信号处理、元胞自动机、图像处理、路径规划、无人机等多种领域的Matlab仿真,相关matlab代码问题可私信交流。
部分理论引用网络文献,若有侵权联系博主删除。


















 1523
1523

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











