








《人工智能AI之计算机视觉:从像素到智能》· 模块一:视觉之门——从经典特征到CNN革命 · 第 4 篇
在上一篇,我们一起回顾了那个属于“工匠”的“蛮荒时代”。我们致敬了SIFT与HOG,那些由天才工程师们“手动”设计出来的精妙特征。
那是一个充满智慧,但也充满“无奈”的时代。
作为一名在IT/SaaS行业摸爬滚打了30多年的从业者,亲身经历过那个“天花板”。2010年左右为一家银行开发票据识别系统,我们动用了当时所有的“军火库”——HOG、SIFT、SURF、SVM……花了数月时间,把几十种手工特征像搭积木一样组合、调参,最终在测试集上达到了一个“还不错”的识别率。
但这个系统的“脆弱”只有我们自己知道:
- 换一种打印字体,识别率就可能掉10%。
- 扫描仪的光线暗一点,训练好的模型就“集体失明”。
- 客户上传一张用手机拍的、略微倾斜的照片,系统就完全“崩溃”。
这时陷入了一个“打地鼠”的困局:每解决一个问题,真实世界总会冒出十个新问题。
这不是我们一个团队的困境,这是当时整个计算机视觉领域的困境。我们这些“工匠”,造出的工具太“精巧”了,精巧到一碰就碎。
我们都隐约知道,一定有更好的办法。我们需要的不是更锋利的“小刀”(SIFT/HOG),而是一把能开山辟地的“巨斧”。
然后,2012年,这把“巨斧”从天而降。
一、 黎明前的“天花板”:手工特征的“组合爆炸”
为什么SIFT和HOG这样的精妙算法,最终还是走到了尽头?
答案是:它们试图用“有限的规则”去对抗“无限的现实”。
在上一篇我们知道,机器视觉最大的挑战是“不变性”——要抵抗尺度、旋转、光照的变化。但现实中的挑战远不止于此。
我把它总结为“视觉识别的十大酷刑”:
- 光照(Illumination):正光、逆光、阴影。
- 尺度(Scale):物体忽远忽近。
- 旋转(Rotation):物体任意旋转。
- 遮挡(Occlusion):物体被部分挡住。
- 背景混淆(Clutter):物体和背景长得太像。
- 视角(Viewpoint):从正面看、从侧面看、从俯视看。
- 形变(Deformation):物体本身是柔性的(比如一只猫在奔跑)。
- 材质与纹理:反光、透明、毛茸茸。
- 运动模糊(Motion Blur):运动中拍摄。
- 压缩伪影(Compression):上篇文章讲的JPEG压缩。
每一个挑战都是一个“变量”。当它们“组合”在一起时,其复杂性会呈指数级爆炸。
- (熟悉元素):一个“在傍晚”、“被树影遮挡”、“正在奔跑”的“黑猫”。
- (冷思考与洞察):用手工特征去解决这个问题,就像试图用Excel里的IF函数去写一个覆盖全世界所有可能的程序。你永远也写不完。
更致命的是,这些手工特征是“死的”。你给它1万张新数据,它不会变得更聪明。它是一个“固化”的工具,不是一个“成长”的大脑。
整个领域都在等待一个东西:一个能让机器自己去学习“如何应对这十大酷刑”的系统。
二、 历史的“完美风暴”:为什么是2012年?
这个系统,就是CNN(卷积神经网络, Convolutional Neural Network)。
但有趣的是,CNN并不是一个新东西。它的核心思想,早在1989年(LeNet)就被Yann LeCun提出来了,当时用来识别手写邮政编码。
那么问题来了:为什么1989年的CNN默默无闻,而2012年的CNN却引爆了“创世爆炸”?
这不是一个“天才的灵光一闪”,而是一场“完美风暴”。一场革命的爆发,往往不是因为“引擎”被发明了,而是因为三件事同时成熟了:燃料、引擎、和道路。
2.1 燃料:ImageNet——“复杂世界”的数据投喂
2012年以前,我们训练模型用的是什么?MNIST(手写数字)、CIFAR-10。几万张、几百个类别、裁剪得整整齐齐的小图片。
- (熟悉元素):这就像你只教一个孩子看“识字卡片”。
- (意外创新):2010年,李飞飞团队主导的 ImageNet 诞生了。它不是“识字卡片”,它是一部“现实世界的百科全书”:
- 1000个类别(狗、猫、汽车、杯子、轮船……)
- 120万张训练图片
- 这些图片不是裁剪好的,而是充满了我们前面说的“十大酷刑”——遮挡、模糊、背景混淆。
思考小札
ImageNet的贡献是历史性的。它第一次给了AI一个“足够残酷”的考场。你用手工特征(SIFT/HOG)去跑ImageNet,准确率惨不忍睹。
它逼着所有人承认:老办法不行了。它为“巨斧”的登场,提供了最完美的舞台。
2.2 道路:GPU——“蛮力计算”的平民化
CNN的计算量是极其恐怖的。在1998年,用CPU训练一个LeNet识别手写数字都要花几天。如果用它来训练120万张的ImageNet呢?
答案是:等同于“不可能”。
- (熟悉元素):GPU(图形处理器)。这东西本是NVIDIA为游戏玩家设计的,用来渲染《魔兽世界》里绚丽的魔法。
- (意外创新):2006年后,学者们(尤其是吴恩达团队)发现,GPU的“并行计算”架构,简直是为神经网络“量身定做”的。
- 2012年,一块NVIDIA GTX 580显卡,能把训练AlexNet(我们马上会讲到)的时间,从180天(CPU估算)缩短到6天。
- 这不是“量变”,这是“质变”。GPU的出现,让“大力出奇迹”这条路,第一次变得“可行”。
2.3 引擎:算法的“激活剂”
有了“燃料”(ImageNet)和“道路”(GPU),“引擎”(CNN)本身也需要一次关键迭代。
老式的CNN(如LeNet)有一个致命缺陷:梯度消失(Vanishing Gradient)。
- (比喻):这就像你站在100层高楼上对楼下的人喊话。你的声音(梯度)传到第50层就弱到听不见了。楼下的人(浅层网络)不知道该往哪走,训练就失败了。
- (激活剂):2011年,一种新的“激活函数” ReLU 被发掘出来。它极其简单(f(x) = max(0, x)),但效果拔群。
- 它就像一个超级扩音器,能让你的“声音”从100层清晰地传到1层。它让“深度”训练第一次变得“可能”和“高效”。
2012年,三件事奇迹般地汇聚在了一起:
- 一个足够难的“考场”(ImageNet)。
- 一条足够快的“公路”(GPU)。
- 一台加装了“扩音器”的“引擎”(CNN + ReLU)。
完美风暴已然形成。只差一道闪电。
三、 “创世爆炸”:AlexNet的“维度碾压”
这道闪电,就是 AlexNet 。
2012年,ImageNet大规模视觉识别挑战赛(ILSVRC)。多伦多大学的Alex Krizhevsky、Ilya Sutskever和Geoffrey Hinton(深度学习“三巨头”之一)提交了他们的模型“AlexNet” 。
比赛结果震惊了整个学术界 :
- 第二名(用的是SIFT等手工特征)的错误率是 26.2% 。
- AlexNet 的错误率是 15.3% 。
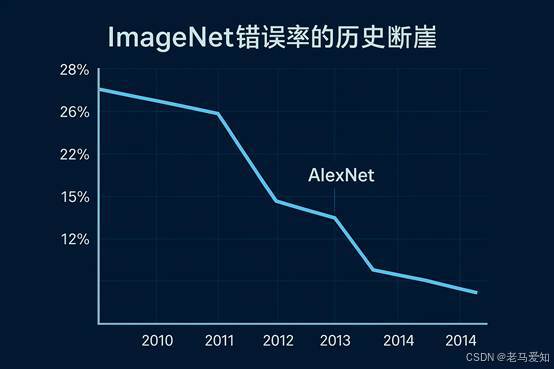
ImageNet错误率的历史断崖
思考小札
在学术界,每年能把错误率降低0.5%或1%都是值得发一篇顶会论文的成就。而AlexNet一次性把错误率降低了10%! 这不是“改进”(Improvement),这是“碾压”(Domination)。 它就像在一群冷兵器(SIFT/HOG)的战场上,扔下了一颗小型原子弹。 从这一刻起,计算机视觉的“古典时代”宣告结束。手工特征,这个词,几乎在一夜之间,从“主流”变成了“历史”。
四、 解构CNN:它到底做对了什么?
AlexNet的胜利,就是CNN的胜利。为什么这个结构如此强大?它究竟是如何解决“十大酷刑”的?
CNN的核心,就是我们以前提到的“三大法宝” 。它完美地模拟了(虽然是简化版)人类视觉皮层的感知机制。
4.1 法宝一:局部感知(Local Perception)
- 手工特征的“愚蠢”:传统算法在看图时,是“全局”看的,试图一次性理解所有像素。
- CNN的“智慧”:CNN模仿人眼。你不会一次性“看”清这整篇文章,你是在“逐字阅读”。
- CNN用一个“卷积核”(Kernel)——你可以想象成一个“带放大镜的识别戳”——在图像上滑动。它一次只看一个5x5或3x3的“局部”小窗口 。
- 它在干嘛? 它在找“模式”。这个“戳”可能是“边缘检测戳”,那个“戳”可能是“红色斑点检测戳”。
4.2 法宝二:参数共享(Parameter Sharing)
这是CNN最天才的设计,也是它和传统神经网络的根本区别。
- 传统方式:如果一张图有100万个像素,传统神经网络可能需要几亿个参数(连接),每个参数都得单独学。
- CNN的方式:CNN说:“我不需要100万个不同的‘边缘检测戳’。我只需要一个‘边缘检测戳’,然后用它滑过(共享)整张图片就行了。”
- 结果:参数量从“几亿”骤降到“几百个”。这让模型变得极其高效,且天生就具备了“平移不变性”——“边缘”无论出现在左上角还是右下角,我这个“戳”都能认出来。
4.3 法宝三:池化(Pooling / Subsampling)
这是CNN解决“不变性”难题的“粗暴”但有效的方法 。
- 问题:我找到了一个“猫耳朵”的特征,但如果猫往左移了2个像素,这个特征也跟着移了,AI还是会“困惑”。
- 池化的解决办法:“眯着眼”看!
- 它把一个4x4的区域,强行“压缩”成一个1x1的区域。它只保留这个区域里“最重要”的信息(比如“最大值”,即Max Pooling)。
- (熟悉元素):你用手机拍全景照。
- (比喻):池化,就是在做“有损压缩”。它在主动“扔掉”信息!它扔掉了“特征的精确位置”,只保留了“特征是否出现”。
- 结果:猫耳朵往左移了2个像素?没关系,反正都在这个“压缩”区域里。AI“看”到的结果是一样的。它牺牲了“精度”,换来了“鲁棒性” 。
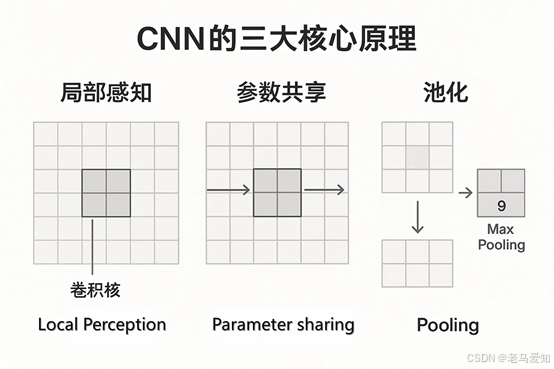
CNN的三大核心原理
五、 真正的“革命”:从“设计特征”到“学习特征”
我们来做一个总结,这也是本篇的核心认知升级。
- SIFT/HOG的时代:我们是“工匠”。我们“教”机器:“边缘长这样,角点长这样”。我们把“鱼”(特征)做好,喂给机器。
- CNN的时代:我们是“园丁”(或“教练”)。我们“不教”机器具体怎么做,我们只给它:
- 一个“环境”(ImageNet,海量数据)
- 一个“规则”(CNN架构:卷积、池化)
- 一个“目标”(“你要把猫和狗分开”)
CNN最伟大的地方,是它自己“学会”了如何看世界。
当我们把CNN训练好,再把它“解剖”开,我们会看到一幅奇妙的景象 :
- 第一层卷积核:自动学会了识别“边缘”、“角点”、“色块”。(它“重新发明”了HOG!)
- 第二层卷积核:学会了把“边缘”和“角点”组合成“纹理”、“圆圈”、“方块”。
- 第三层卷积核:学会了把“纹理”组合成“眼睛”、“鼻子”、“耳朵”。
- 更高层:学会了把“五官”组合成一张“脸”。
CNN,就是一部“自动化的特征提取机” 。它把SIFT和HOG时代需要几代博士生手工完成的工作,全自动地完成了,而且做得好一万倍。
这不是“范式改良”,这是“范式革命” 。
六、 结语:爆炸的回响,与我们的下一站
2012年的那场“创世爆炸”,其意义远不止于“识别猫狗” 。
- 对于产业(我的亲身感受):
- 作为SaaS从业者,我深切感受到,2012年后,AI第一次从“实验室玩具”变成了“可交付的工程产品” 。
- 在银行,我们终于可以用“刷脸”取代“密码” 。
- 在保险,我们可以用“拍照”取代“人工定损” 。
- 在电信,我们可以用“无人机+CV”取代“人工爬塔巡检” 。
- 这一切,都是因为CNN这个“通用钥匙”被找到了。
- 对于技术史:
- AlexNet推开的大门,至今没有关闭。
- 2014年的VGG、2015年的ResNet、2017年的Transformer……直到今天的AIGC(如Sora, DALL-E 3)和自动驾驶,我们今天所享受的一切AI成果,都是站在2012年那场“爆炸”的余波之上 。
那么,下一站呢?
AlexNet虽然强,但它还很“粗糙”。它证明了“深度”是可行的。但它留下了一个新问题:
“网络是不是越深越好?如果我想堆到100层、1000层,会发生什么?”
这个问题,在三年后被一个更伟大的模型所回答。
下一篇,我们将进入专栏的第5篇,去看看现代CV的“中流砥柱”:《视觉“骨架网”的进化——从VGG、GoogLeNet到ResNet》。我们将去解密,为什么简单的VGG能成为“万能骨架”,以及ResNet那个“天才”的残差连接,是如何解决“深度诅咒”的。

新旧范式的交替


















 1219
1219

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











