







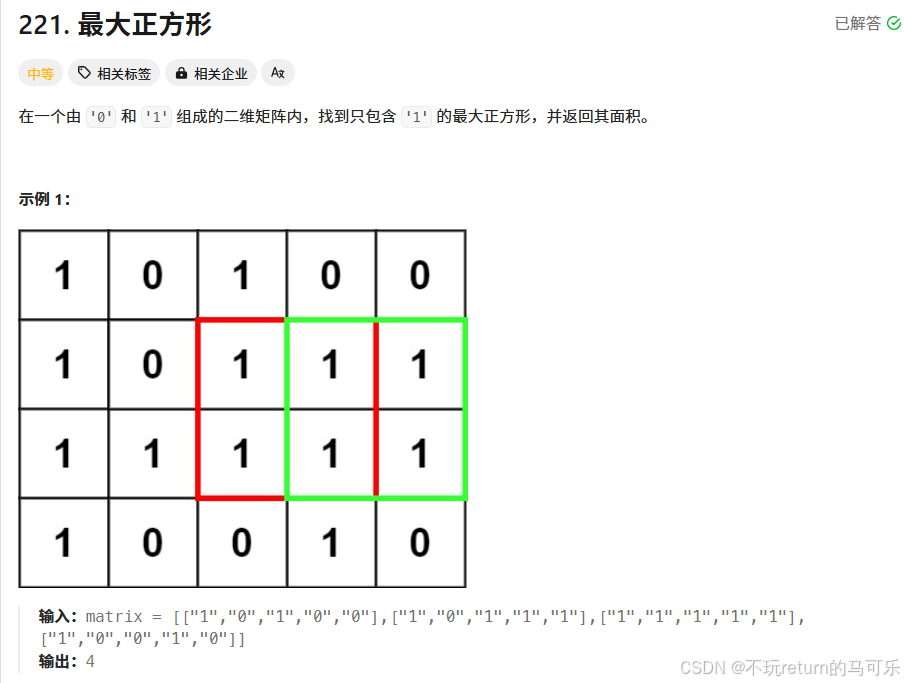
问题描述
解题思路
动态规划
-
定义状态:
dp[i][j]表示矩阵中以(i, j)为右下角的最大正方形的边长。 -
状态转移方程:如果
matrix[i][j]为'1',则dp[i][j] = min(dp[i-1][j], dp[i][j-1], dp[i-1][j-1]) + 1。 -
初始化:第一行和第一列的
dp值等于matrix中的对应值。 -
遍历:从第二行第二列开始遍历矩阵,根据状态转移方程更新
dp值。 -
结果:遍历结束后,找到
dp中的最大值,即为最大正方形的边长,返回其面积。
代码实现
class Solution {
public:
int maximalSquare(vector<vector<char>>& matrix) {
int r = matrix.size();
int c = matrix[0].size();
int maxSide = 0;
vector<int> prev(c, 0);
vector<int> curr(c, 0);
for (int i = 0; i < r; i++) {
for (int j = 0; j < c; j++) {
if (matrix[i][j] == '1') {
if (i == 0 || j == 0) {
curr[j] = 1;
}
else {
curr[j] = min({prev[j - 1], prev[j], curr[j - 1]}) + 1;
}
maxSide = max(maxSide, curr[j]);
}
else {
curr[j] = 0;
}
}
prev = curr;
}
return maxSide * maxSide;
}
};复杂度分析
-
时间复杂度:
O(m * n),其中m和n分别是矩阵的行数和列数。 -
空间复杂度:
O(n),用于存储dp数组。
总结
本题通过动态规划的方法,利用 dp 数组存储以每个点为右下角的最大正方形边长,从而找到最大正方形的边长,最终计算出面积。这种方法在处理类似问题时非常有效,关键在于正确定义状态和状态转移方程。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









