






提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
论文链接
https://arxiv.org/pdf/2105.08595
摘要
本博客通过阅读和总结论文《ACAE-REMIND for Online Continual Learning with
Compressed Feature Replay》,针对当前持续学习面临的挑战,如灾难性遗忘等,提出ACAE - REMIND方法用于在线持续学习中的压缩特征重放。博客首先介绍相关工作包括自动编码器和乘积量化、REMIND。然后阐述ACAE - REMIND模型的特征重放位置、在线持续学习设置、模型结构及训练过程。通过在多个数据集上的实验,与多种方法比较,结果表明该模型在多任务评估中达到先进水平,在少任务设置中也有竞争力。
Abstract
This blog begins by reading and summarizing the paper “ACAE-REMIND for Online Continual Learning with Compressed Feature Replay”, aiming at the current challenges of continuous learning, such as catastrophic forgetting, the ACAE-REMIND method is proposed for compressed feature replay in online continuous learning. The blog begins with a description of related work, including classification of continuous learning methods, autoencoders, and product quantization. Then, the feature replay position, online continuous learning setting, model structure and training process of the ACAE-REMIND model are described. Through experiments on multiple datasets and comparison with multiple methods, the results show that the model reaches the advanced level in multi-task evaluation and is also competitive in the less-task setting.
一、理论方法介绍
1.自动编码器和乘积量化
自动编码器是一种用于无监督学习的神经网络模型,旨在通过压缩输入数据并再生成输出的方式进行数据的特征学习。其目标是通过一个低维度的表示(编码)来捕捉输入数据的主要特征,从而实现对数据的有效压缩和去噪。 自动编码器通过鼓励模型重建输入数据以无监督的方式学习表示。编码器将高维输入投影到低维空间,解码器尝试投影回原始空间,以最小化重建误差。自动编码器常用的损失函数包括均方误差MSE和交叉熵损失。
乘积量化是一种有效的量化方法,它将高维空间分解为一系列子空间的笛卡尔积,并分别量化它们。
2.压缩功能回放
在自动编码器中,压缩与回放可以被看作是数据处理过程的两个核心部分:
1.压缩是指将输入数据通过编码器(Encoder)转化为低维度的潜在空间表示(latent representation)。这个过程涉及对输入数据的特征提取和简化。压缩的目标是保留数据的主要信息,而丢弃冗余部分。压缩后的数据通常比原始数据的维度小,因此可以用于数据存储、传输或者进一步的分析。
2.回放是指通过解码器(Decoder)将压缩后的低维表示还原为原始数据的近似。这个过程可以视为对数据的“重构”或“恢复”,其目的是尽可能地恢复压缩前的输入数据。在理想情况下,回放出来的数据与原始输入数据非常接近。
3.REMIND: Replay using Memory Indexing
REMIND是一种新颖的大脑启发方法,用于在使用重放的流设置中训练CNN的参数。REMIND主要包括两个步骤:
1.压缩当前输入。
2.重构先前压缩的表示的子集,将它们与当前输入混合,并且用该混合来更新网络的塑性权重。
REMIND框架图如下所示: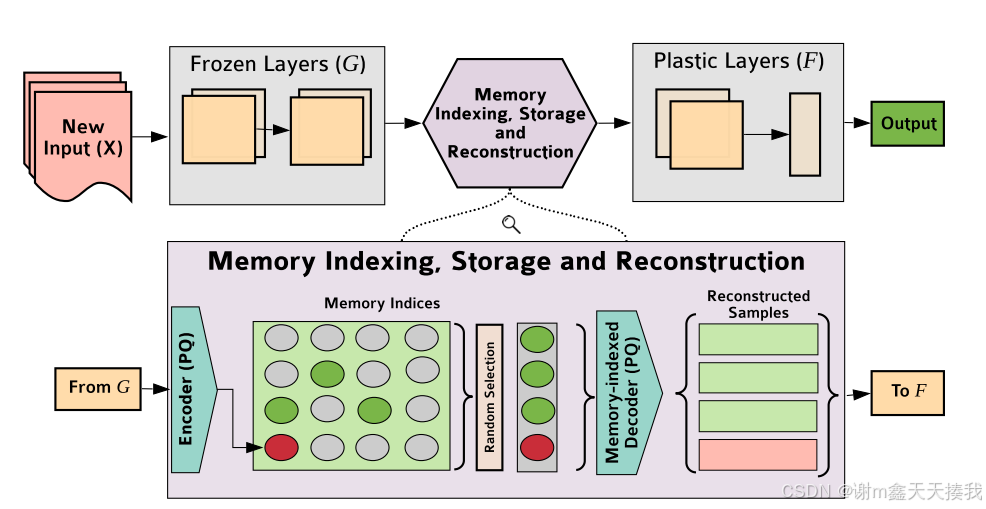
REMIND接收输入图像,并将其通过网络(G)的冻结层以获得张量表示(特征图)。然后,它通过乘积量化来量化张量,并将索引存储在内存中以供将来重放。解码器从存储的索引中重构张量,以在进行最终预测之前训练网络的塑性层(F)。
REMIND(以及一般的特征重放)的主要缺点之一是这些方法在训练第一个任务之后冻结骨干特征提取器(即特征重放之前的层)。它们只训练功能重播层之后的层,以完成剩余的任务。
4.ACAE-REMIND
为了解决特征重放的限制,研究者在REMIND的基础上提出了一种辅助分类器自动编码器ACAE-REMIND。允许在网络的中间层进行压缩特征重放,这与当前的特征重放方法形成对比,当前的特征重放方法专注于重放最后层中的特征。ACAE-REMIND的主要优点是可以在重放层之后联合训练所有层。这解决了特征重放方法的一个重要问题,即由于大型固定骨干网络而降低的性能。
为了克服特征重放的局限性,研究者提出的 ACAE-REMIND 模型旨在将重放应用于中间块。 为了重建中间层的特征,引入了更强的压缩模块,它实现了降维和特征逼近,同时保持了重放特征的分类特征。 该方法是 REMIND 的扩展,基于带有辅助分类器 (ACAE) 的自动编码器。可以在重放层之后的所有层上执行联合训练,这减轻了固定骨干神经网络的缺点。下图是对一些特征重放方法进行比较: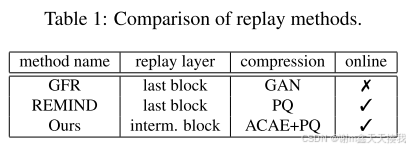
4.1用于压缩功能回放的 ACAE-REMIND
ACAE-REMIND 模型专为以高效记忆的方式进行在线任务无关的持续学习而设计。研究者所提出的基于 ACAE 模块的改进压缩机制训练过程如下:
1.首先是分类模型,采用Resnet-18来进行训练:
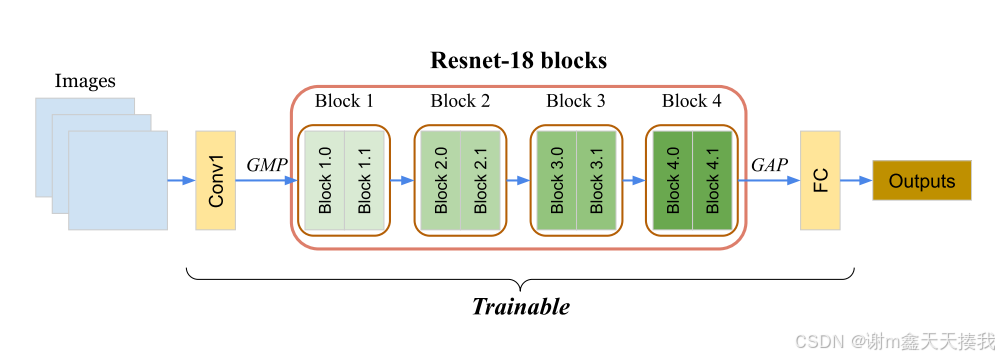
2.接着要对ACAE和PQ模块进行初始化,如下图所示:
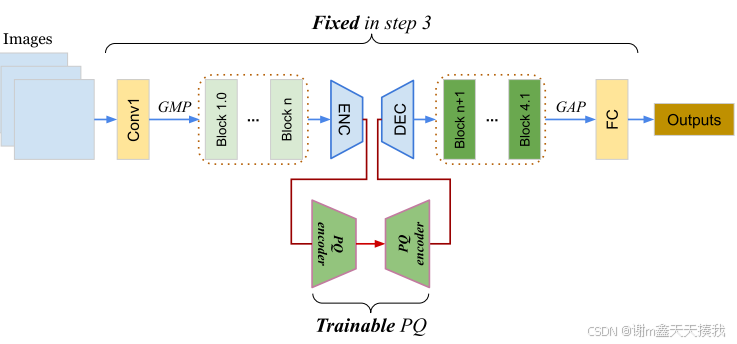
在初始化过程中,分类模型、ACAE 和 PQ 使用第一个任务 t = 1 中的数据 xi 1, yi 1 进行顺序训练。第一步,以离线方式优化整个分类模型。 此步骤的目的是为未来的任务学习一个强大的预训练模型(类似于 REMIND)。 通过最小化交叉熵损失来更新参数 θ:
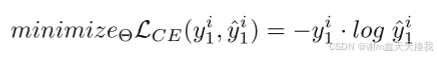
其次,ACAE 模块被插入到我们将重放特征的层中。重放层之前和之后的层表示为 g (x; θ1) 和 h (z; θ2),其中 θ 是步骤 1 中 θ1 加 θ2 和 z = g (x; θ1) 的并集。ACAE 的编码器和解码器表示为 u = Denc (z; Γ) 和 ˆz = Ddec (u; Π)。然后通过最小化 ACAE 损失来计算参数 Γ、Π: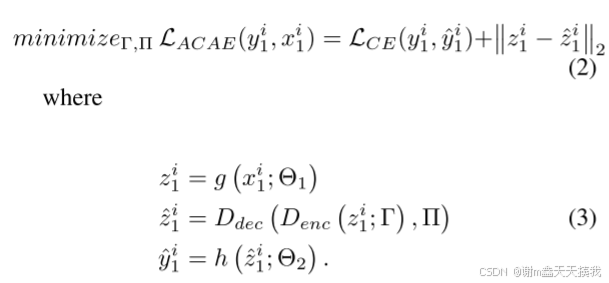
之后,最后一步是训练 PQ 编码器-解码器对 Penc (u; Υ) 和 Pdec (v; Ψ) 以近似从 ACAE 编码器中提取的潜在表示。 这里Y,Ψ是从PQ MSE损失的目标函数中学习到的:
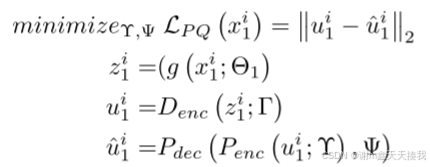
3.最后将分类和初始化后的模型进行在线持续学习:
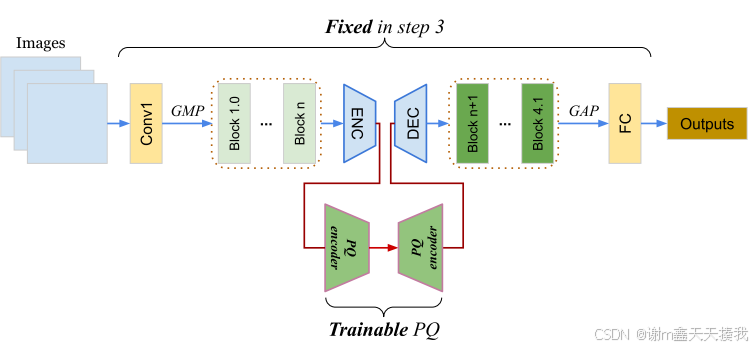
在在线持续学习中,只有ACAE解码器之后的层可以自由调整以适应新任务(θ2中的参数),其他模块(包括参数θ1,Г,Π,Υ,Ψ)在训练期间都是固定的。 来自数据流的新图像通过较低层、ACAE 编码器和 PQ 编码器,以获得它们的潜在表示 vi t 以及相应的整数索引。 计算如下: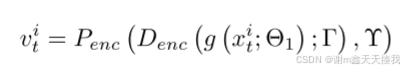
然后将其表示与从存储库中随机选择的 N 个先前样本 vj t^ (^t< t) 混合,以通过 PQ 解码器和 ACAE 解码器重建特征。 这些特征将被用来优化可训练参数 θ2,交叉熵损失 LCE yi t 、 ˆyi t ˆ 和 yˆ i t 形成为: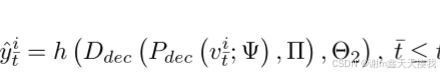
二、实验部分
1.数据集和评估指标
研究者使用ACAE在ImageNet - Subset、CIFAR100和CIFAR10数据集上进行评估,采用不同的任务划分设置,对比多种已有方法(如iCaRL、REMIND等),采用当前任务之前的类的 top-1 准确率平均值 (AOC) 和上一个任务之后的 top-1 准确率 (LAST)作为评估指标。
2.具体实施和实验结果
研究者使用 Resnet-18 作为 ImageNet-Subset 的分类网络。 对于CIFAR10和CIFAR100,我们分别使用改编后的Resnet-18和Resnet-32。 在初始化期间,使用 SGD 从头开始学习主干网络,然后使用 Adam 训练 ACAE。 对于 PQ 训练,使用 Facebook Faiss 库 中的实现。 在在线持续学习阶段我们使用SGD。
2.1在少任务和多任务中的性能表现
研究者在 Imagenet-Subset 上进行比较,显示了以 50 个类作为第一个任务的类平均值 (AOC),每个步骤有 5/25/50 个步骤,每个步骤有 10/2/1 个类,结果如下:
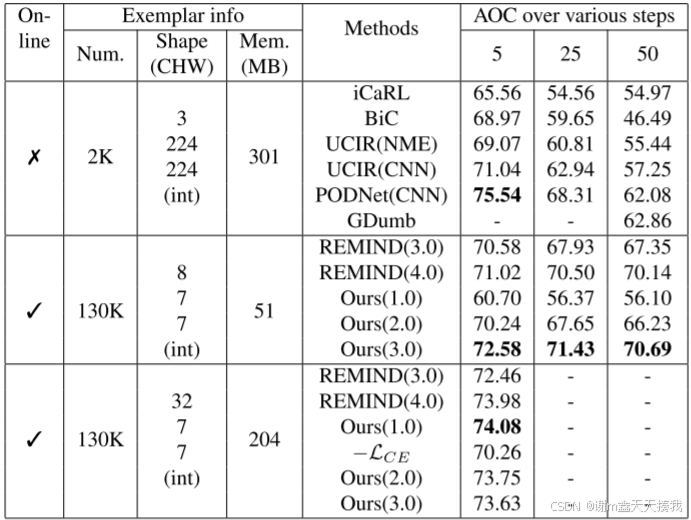
可以看出,.ACAE - REMIND的方法优于 REMIND,并且特别是对于较大的内存,可以通过重放较低层来获得优异的结果。
在多步骤的任务中,ACAE - REMIND方法获得了最先进的结果,分别比 PODNet、REMIND(块 4.0)和 REMIND(块 3.0)高 3.12%、0.93% 和 4.50%。
对于5步的CIFAR100,实验结果如下图所示:
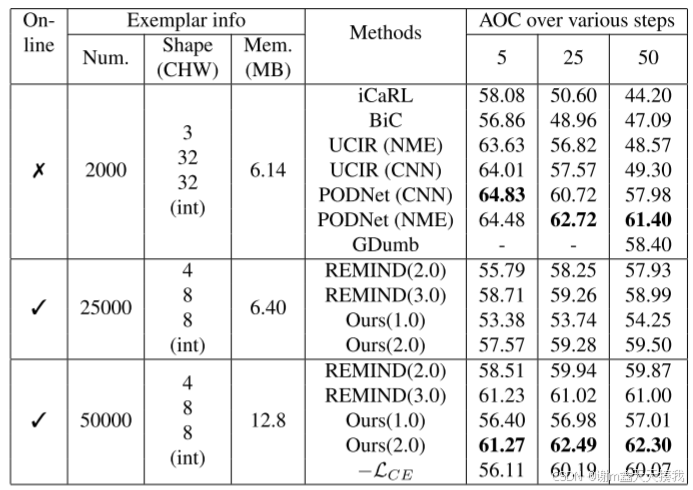
对于5步的CIFAR100,由于图像尺寸较小,压缩率不如ImageNet-Subset那么高。 在这种情况下,在相同的内存分配下,离线持续学习(PODNet)的性能比在线设置大得多。 此外,PODNet 在数据上运行了 160 个 epoch,而在线方法只能运行 1 个 epoch。 在在线方法中,,ACAE - REMIND的方法的性能比 REMIND(3.0) 差。 这是因为第一个任务包含许多类和更多数据,使得 REMIND 也能够学习高质量的骨干网络。 对于较大的内存设置 ,ACAE - REMIND方法的方法的性能与 REMIND(3.0) 相当。
对于多任务的CIFAR100,ACAE - REMIND在 50 个步骤中比 PODNet 稍好,在 25 个步骤中比 PODNet 稍差。 通过较低的内存分配,ACAE - REMIND仍然获得有竞争力的性能。 总之,从多任务评估中,研究者观察到偏差校正方法随着时间步长的增加而性能下降,而模型获得了更好的结果,并且当任务数量增加时性能没有太大下降。
2.2在均等分任务中的性能表现
ImageNet-Subset 上等分 10 个任务,研究员以 10 个类作为第一个任务,展示了前 5 名的准确率,每个步骤有 10 个类,共 9 个步骤,结果如下图所示: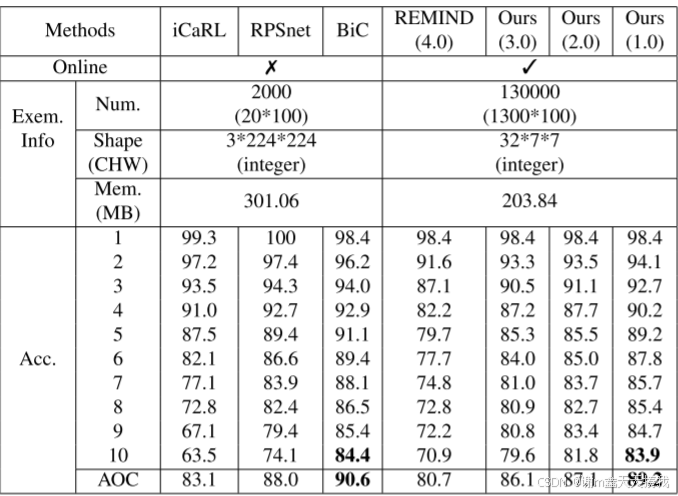
对于这种更具挑战性的设置,REMIND 获得的结果比我们低 8.5%,这是由于骨干模型不太灵活。
在 CIFAR10 上平均分配 5 个任务(4 个步骤)。ACAE - REMIND方法在该设置下达到48.4%,比GDumb报告的最佳结果高2.6%,比REMIND方法高出3%以上,结果如下图所示: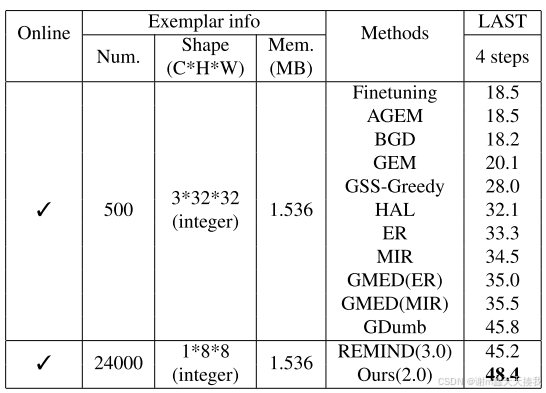
2.3消融研究
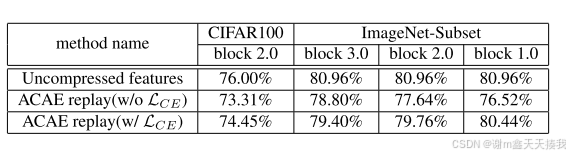
分类损失的影响:CAE - REMIND方法中的辅助分类损失对确保压缩不删除对分类至关重要的特征有重要作用。通过有无该损失的压缩后分类准确率对比,以及在最佳性能设置下的消融实验,结果表明分类损失可减轻因压缩导致的分类性能下降,能使性能提高2 - 5%,如下图所示:
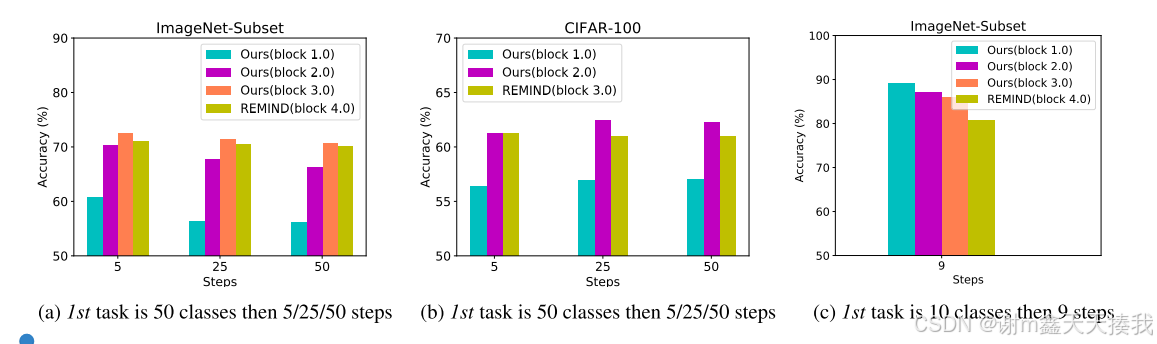
块编号n的影响:通过在ImageNet - Subset和CIFAR - 100的不同设置下进行实验,结果表明在这些设置下,从第一个块到倒数第二个块进行特征重播时性能提高,在最后一个块重播时性能下降。在第一个任务数据量减少时,较难学习到良好的骨干网络,最优的n值会降低。
总结
1.ACAE - REMIND方法,是对REMIND方法的扩展。基于辅助分类器自动编码器的更强压缩模块,可将特征重放移至较低层,该方法内存高效且性能更好。在多指标比较中,高压缩率下能保存更多特征样本,在某些任务场景下显著优于REMIND。
2.ACAE - REMIND方法,采用辅助分类器自动编码器实现更强的压缩模块,将特征重放位置移到中间层,可联合训练重放层后的所有层,解决了因固定骨干网络导致性能下降的问题。
3.可将此框架扩展到其他持续学习问题;进一步探索在不同类型数据、更多复杂场景下的应用;研究如何更好地优化ACAE - REMIND的参数以提高性能;探索与其他持续学习方法结合的可能性。

















 1352
1352

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









