






提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
摘要
本周完整地学习了卷积神经网络CNN的所有内容,理解影响卷积结果的各种因素,理解卷积层和池化层的工作原理和过程,能够使用代码来构建卷积操作和池化操作。还学习了如何使用非线性函数对我们的矩阵和图像进行处理。
Abstract
This week, I learned everything about convolutional neural network CNN in its entirety, understood the various factors that affect convolution results, understood the working principle and process of convolutional layers and pooling layers, and was able to use code to build convolution and pooling operations. We also learned how to use nonlinear functions to process our matrices and images.
一、CNN
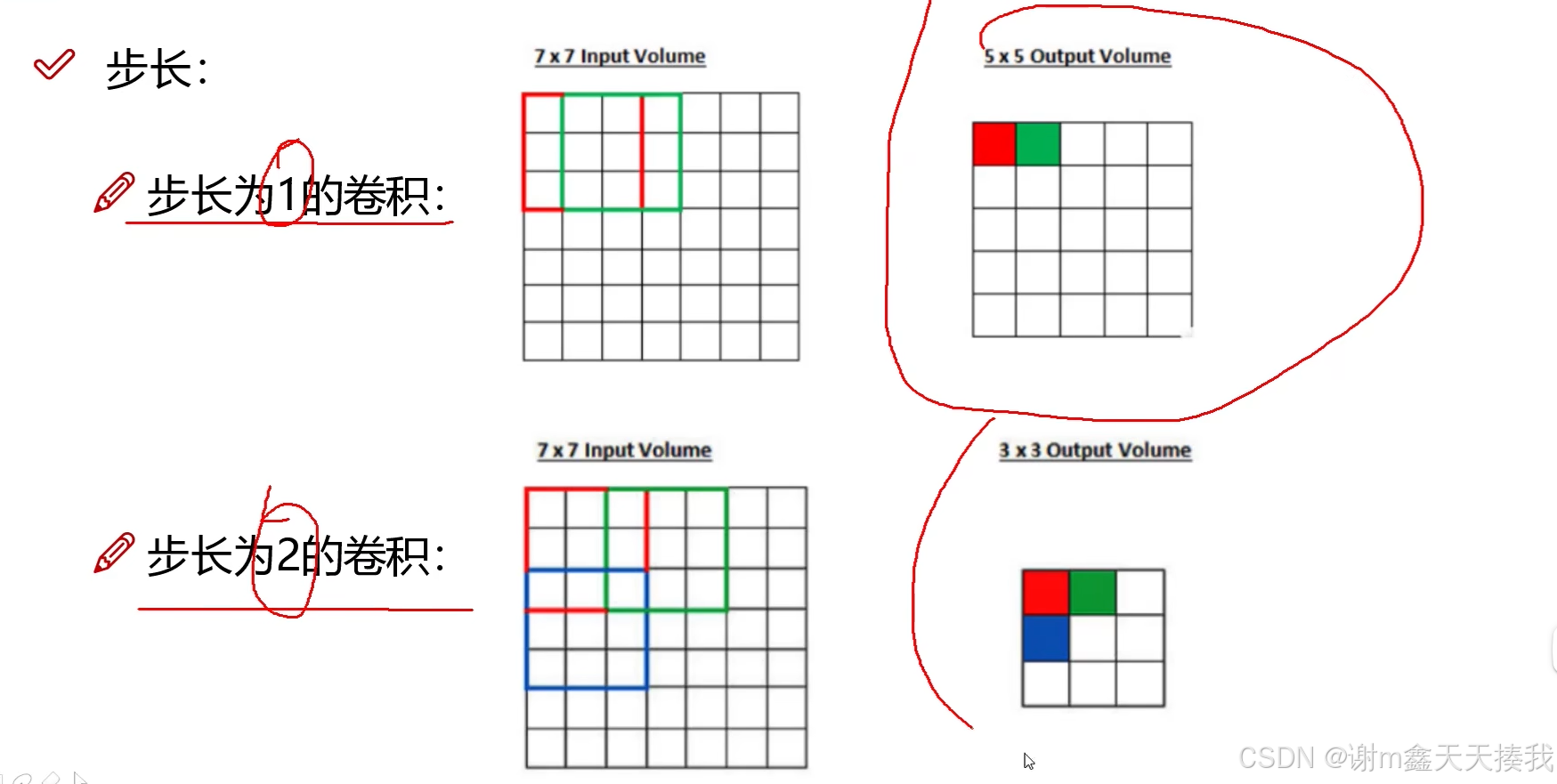
1.步长与卷积核大小对结果的影响
在卷积神经网络中,我们经常要进行多次地卷积,以下的参数都会对我们卷积的结果造成影响:
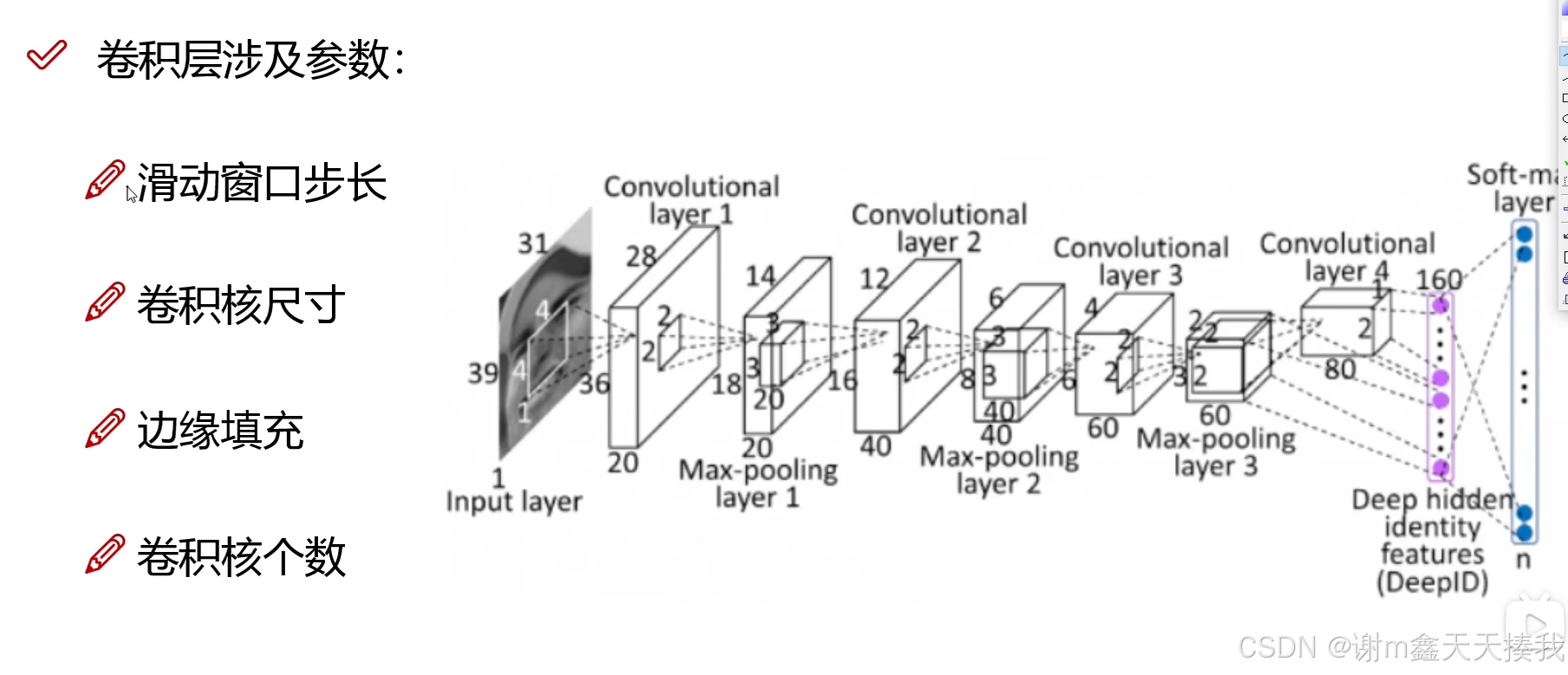
步长越小,我们要移动和提取的次数就会越多,而得到的特征值就越多,特征图就会越大。步长越大则反之。
卷积核的大小决定提取粒度的大小。卷积核越大,提取的特征粒度就越大,计算起来也更加复杂。卷积核越小,提取的特征粒度就越小,计算更加简便,多层小卷积核堆叠相较于大卷积核可以引入更多的非线性。(效果更好)
2.边界填充
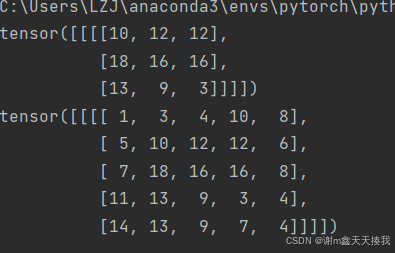
原本我们输入的是5x5的数据,根据卷积操作的过程我们可以得知,在不断地滑动卷积的过程中,中间的数据特征被利用的次数更多,下图中间的1和2会参与最后特征3和-5的计算。此时我们在原来5x5数据的外边加一圈0,此时的边界就都是0而原来5x5数据的边界就被规划到中间区域,原来的边界就不是边界了,可以参与更多次的特征提取和计算,一定程度上弥补了边界信息缺失的问题。这就是我们边界填充的作用。
我们可以用如下代码来表示:
import torch
import torch.nn.functional as F
input=torch.tensor([[1,2,0,3,1],
[0,1,2,3,1],
[1,2,1,0,0],
[5,2,3,1,1],
[2,1,0,1,1]])#[[]]表示这是一个二维的矩阵,定义输入图片
juanjihe=torch.tensor([[1,2,1],
[0,1,0],
[2,1,0]])#定义卷积核
# print(input.shape)
# print(juanjihe.shape)
input=torch.reshape(input,(1,1,5,5))#图片数量为1,通道数为1,高5,宽5
juanjihe=torch.reshape(juanjihe,(1,1,3,3))
output=F.conv2d(input,juanjihe,stride=1)#stride为每次滑动卷积的步数
output2=F.conv2d(input,juanjihe,stride=2)
output3=F.conv2d(input,juanjihe,stride=1,padding=1)#边缘填充
print(output)
# print(output2)
print(output3)
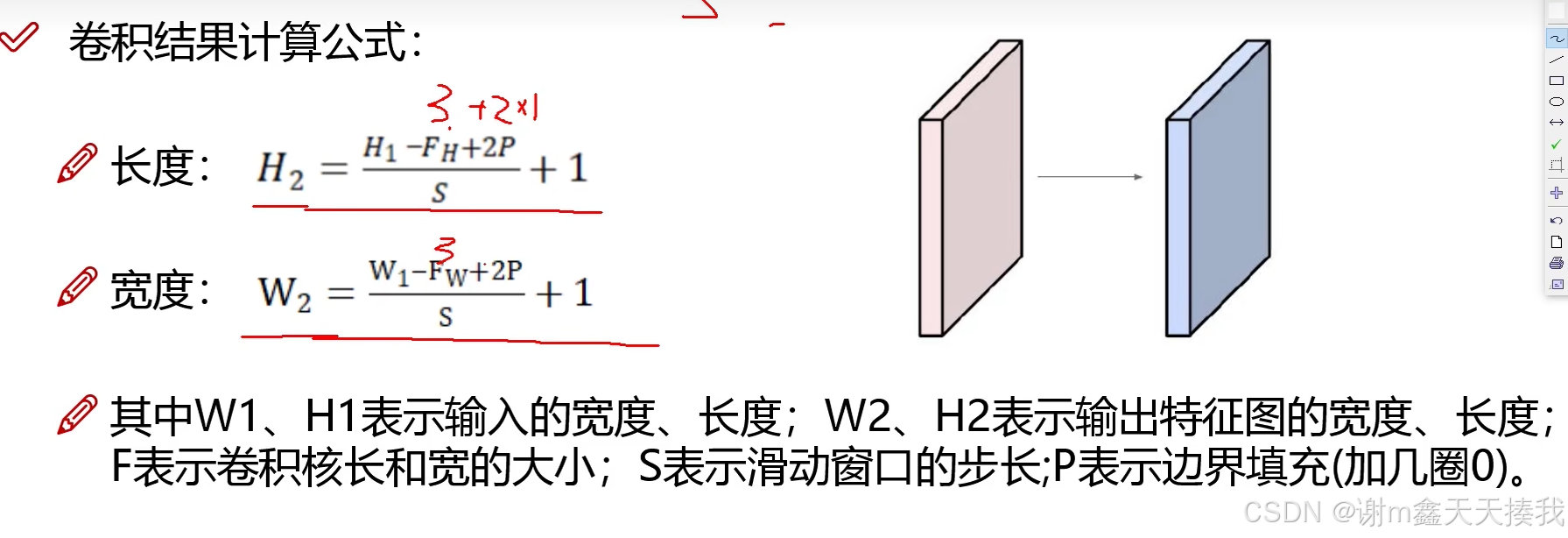
3.特征图尺寸的计算
4.池化层
池化层(Pooling Layer)是卷积神经网络(CNN)中的一个重要组成部分,主要用于减少特征图的空间尺寸,从而降低计算量和防止过拟合。池化层通过对输入特征图进行下采样,提取关键特征,同时保持图像的主要特征不变。
池化层又可以分为最大池化和平均池化。
我们选择一个4x4的数据,规定池化窗口为2x2,步幅为二。于是我们就可以将我们不断地滑动池化窗口,将数据分割为4块,每块取最大值得到我们的特征图,这就是最大池化。
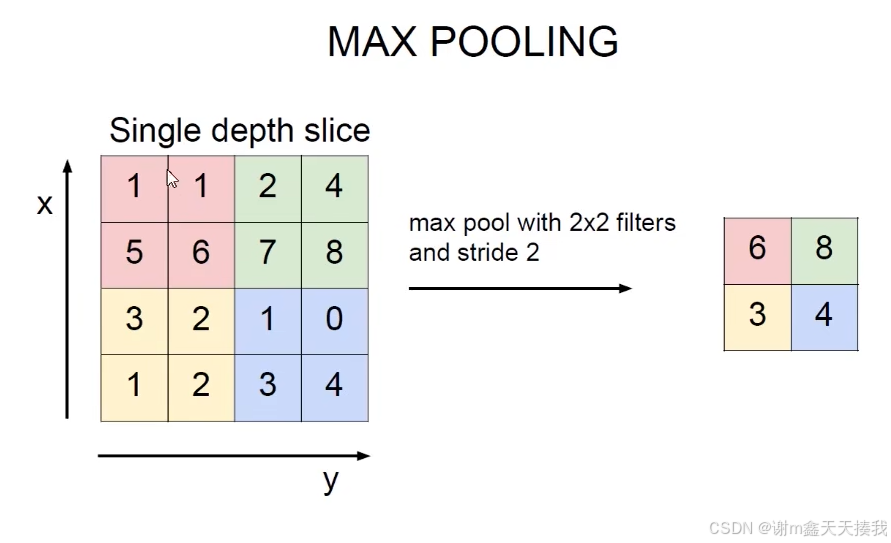
平均池化的原理类似,只不过是将最大值换成了平均值。平均池化会对特征图中的信息进行更平滑的处理,但可能会导致一些细节丢失。
目前广泛使用的还是最大池化。
5.感受野
感受野通常指的是某个特定神经元或神经网络中单个单元所响应的输入刺激的区域或范围。在深度学习和卷积神经网络(CNN)中,感受野的概念同样适用。这里的感受野指的是卷积神经元能够“看到”的输入图像的区域。随着网络的层数加深,感受野会逐渐增大,从而使得高层神经元能够捕捉到更大的空间上下文信息。
6.如何选择激活函数
当我们预测的问题是一个二分问题时,sigmoid函数就是我们的不二选择,他很好地能够体现0或1的概率。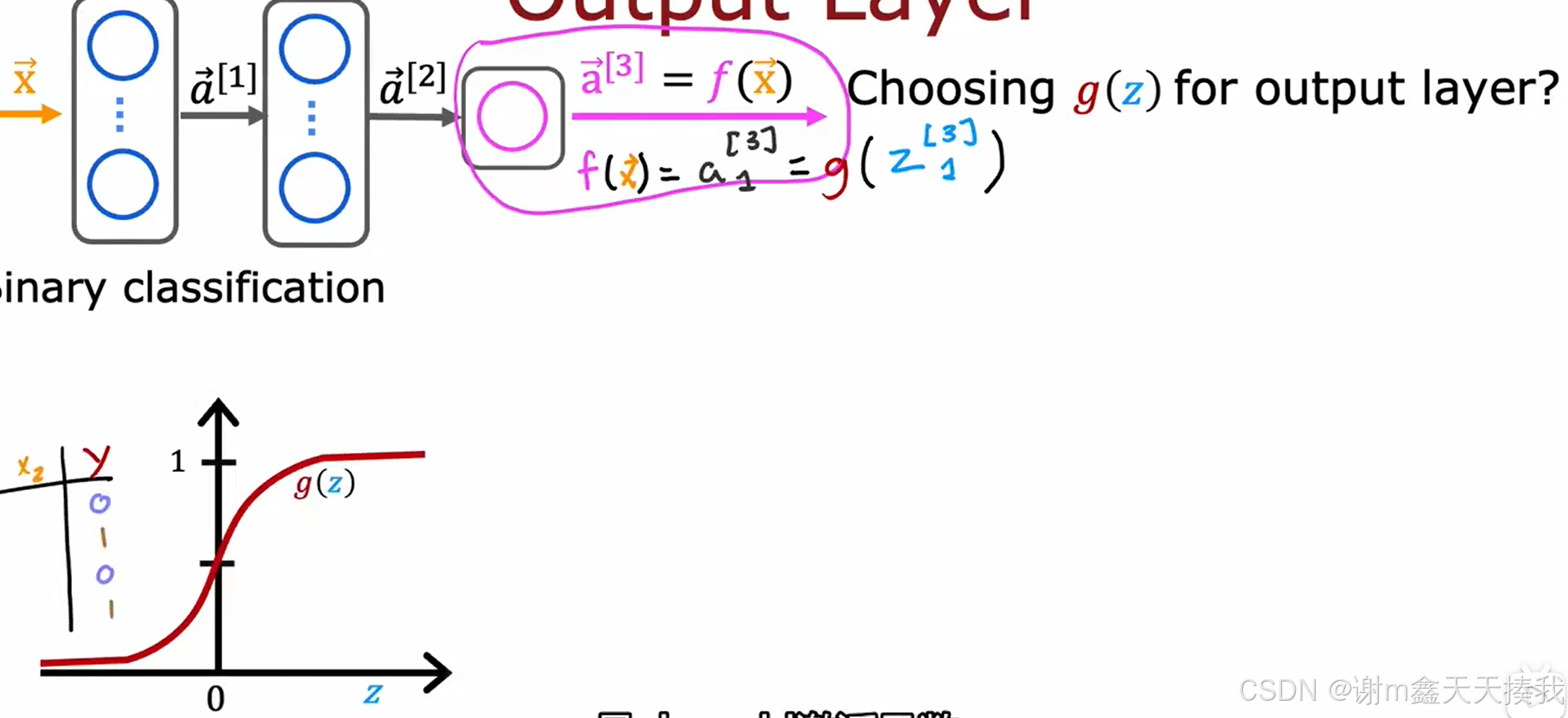
如果我们要预测回顾问题,结果可能有正有负有增有减,就比如预测股票的走势,此时我们可以选择线性回归函数。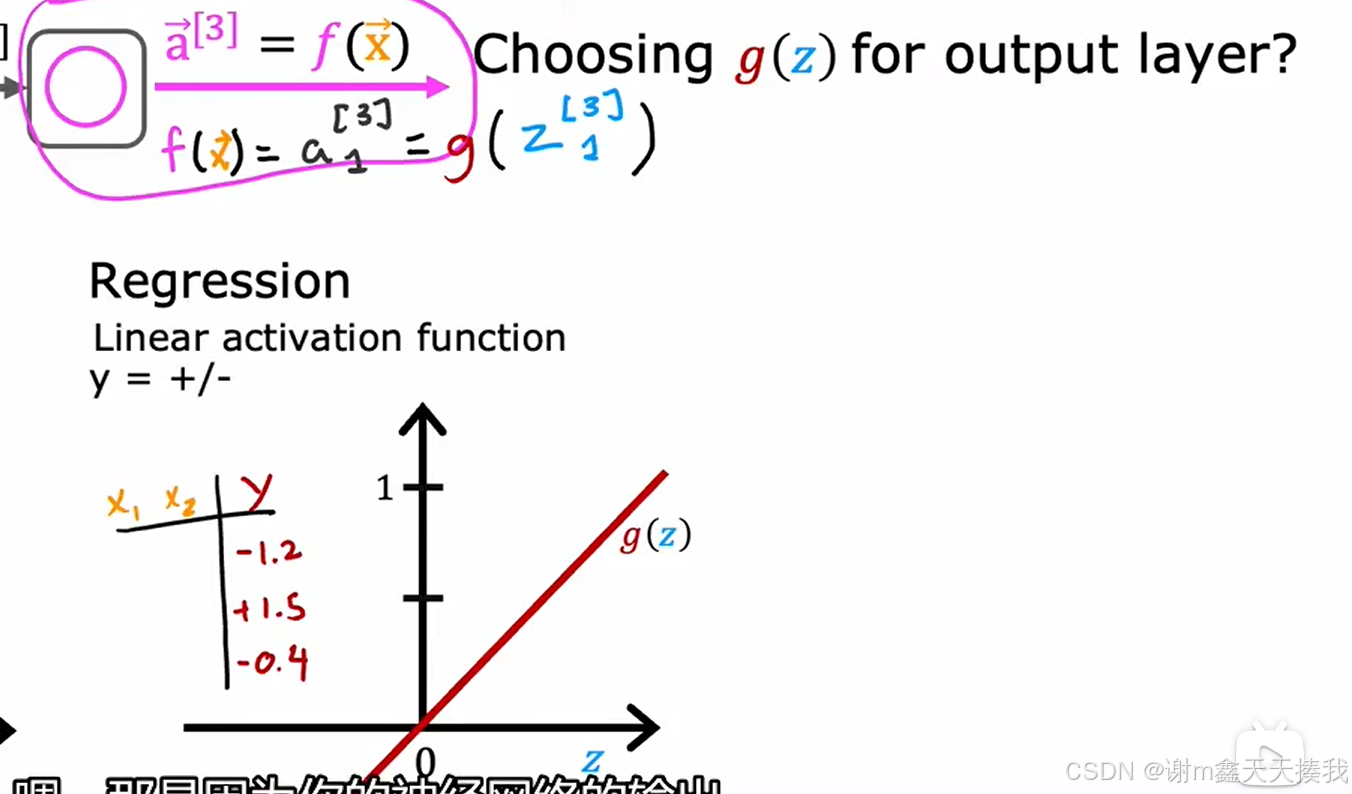
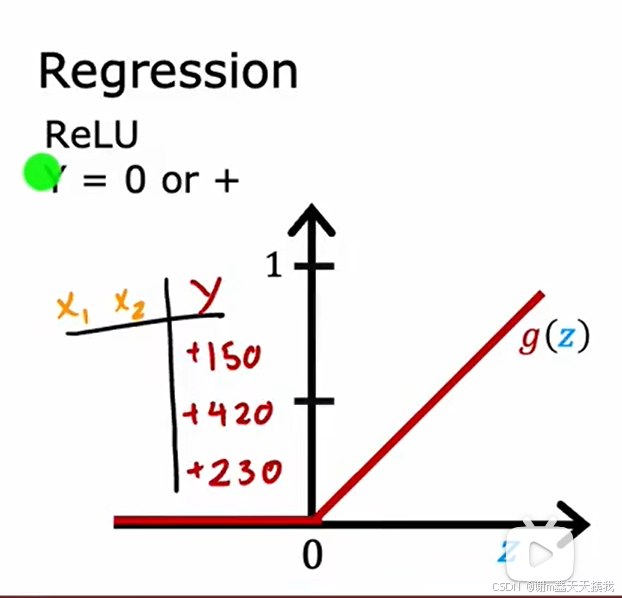
如果我们要预测的值没有负数,那我们可以选择RELU函数。
7.softmax
Softmax 函数是一种广泛用于多类分类问题的激活函数,尤其是在神经网络的输出层中。它将一个实数向量转换为概率分布,常常用于多类别分类任务中,其表达式如下:
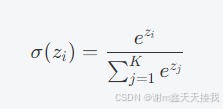
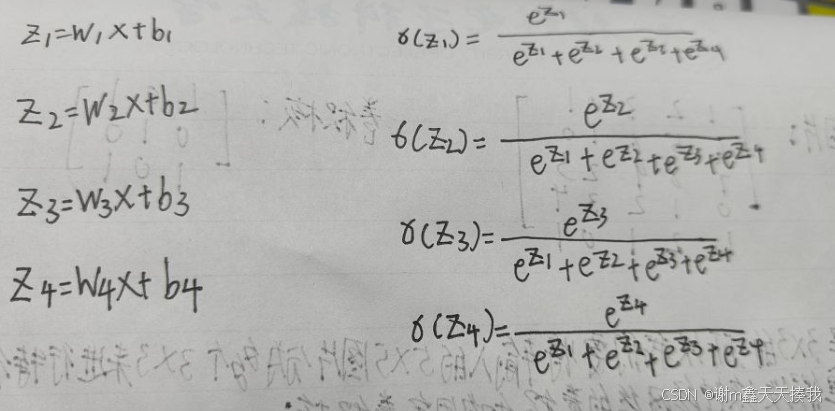
z1到z4四个经过softmax处理过后的值的总和仍为1,softmax的代价函数如下: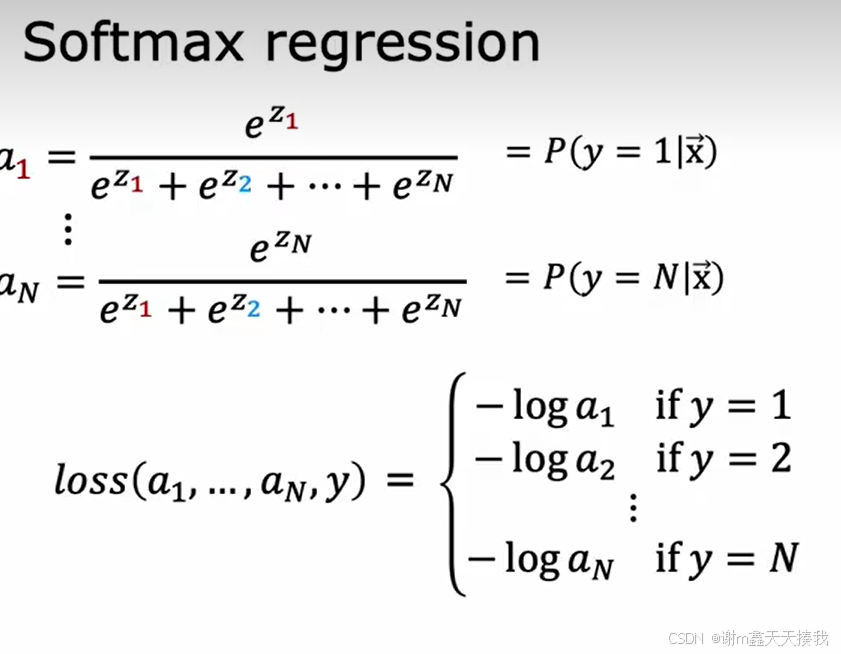
注意:国外的log其实就是我们的ln
8.多类分类问题
当我们有不止两种分类时(也就是
y
=
1
,
2
,
3
…
.
y=1,2,3….
y=1,2,3….),比如以下这种情况,该怎么办?如果我们要训练一个神经网络算法来识别路人、汽车、摩托车和卡车,在输出层我们应该有4个值。例如,第一个值为1或0用于预测是否是行人,第二个值用于判断是否为汽车。
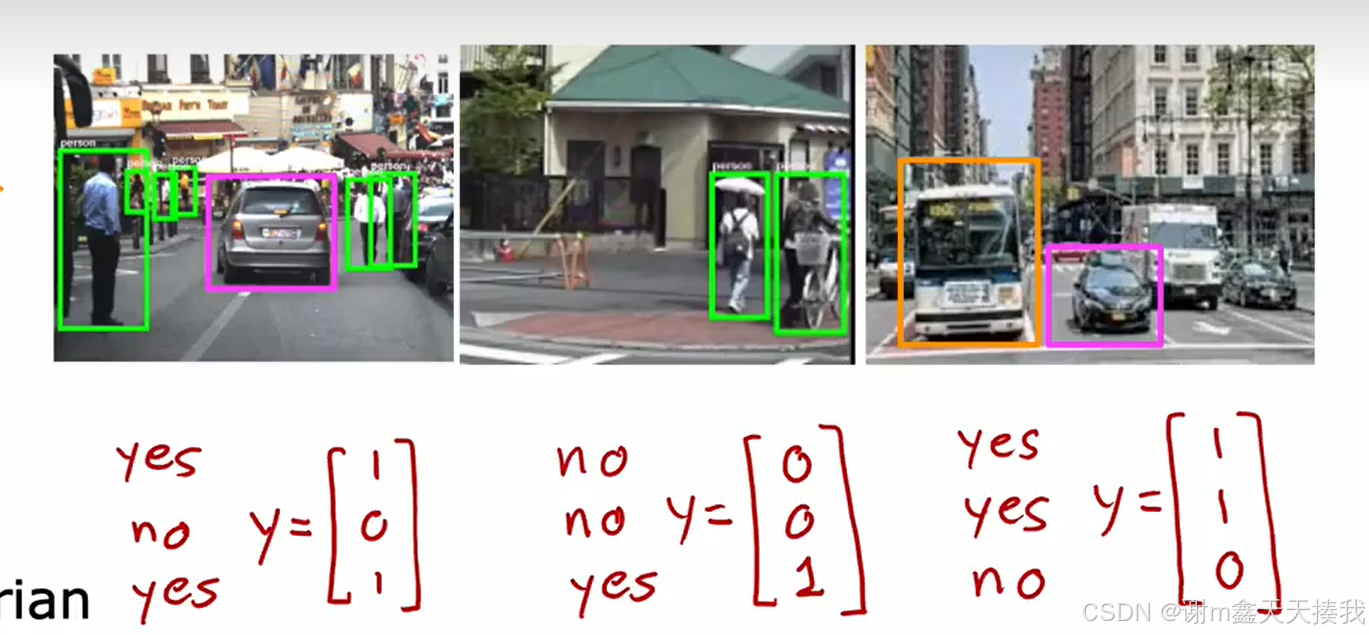
我们可以将这三个二分问题统一归结到一个向量中,并训练单个神经网络来表示。

二、卷积池化
1.用pytorch来表示卷积操作
代码如下(示例):
首先我们定义一个5x5的图像,表示为一个二维矩阵。在定义一个3x3的卷积核。因为conv2d中接受的输入和卷积核要有四个参数(batchsize,chanel,H,W),所以我们调用torch中的reshape()方法对输入和卷积核进行处理,处理图片的数量为1,batchsize=1,灰色图片通道数为1,chanel=1,在输入长和宽,将处理好的图像和卷积核用conv2d,让每次滑动卷积的步长为1,来进行卷积操作得到我们的结果。
import torch
import torch.nn.functional as F
input=torch.tensor([[1,2,0,3,1],
[0,1,2,3,1],
[1,2,1,0,0],
[5,2,3,1,1],
[2,1,0,1,1]])#[[]]表示这是一个二维的矩阵,定义输入图片
juanjihe=torch.tensor([[1,2,1],
[0,1,0],
[2,1,0]])#定义卷积核
# print(input.shape)
# print(juanjihe.shape)
input=torch.reshape(input,(1,1,5,5))#图片数量为1,通道数为1,高5,宽5
juanjihe=torch.reshape(juanjihe,(1,1,3,3))
output=F.conv2d(input,juanjihe,stride=1)#stride为每次滑动卷积的步数
print(output)

2.用pytorch来表示池化操作
目前我们常用的池化为最大池化,调用torch中的MaxPool2d()方法,代码示例如下
import torch
import torch.nn as nn
input=torch.tensor([[1,2,0,3,1],
[0,1,2,3,1],
[1,2,1,0,0],
[5,2,3,1,1],
[2,1,0,1,1]],dtype=torch.float32)#[[]]表示这是一个二维的矩阵,定义输入图片
# juanjihe=torch.tensor([[1,2,1],
# [0,1,0],
# [2,1,0]])#定义卷积核
input=torch.reshape(input,(-1,1,5,5))#-1自动计算channel的大小
# juanjihe=torch.reshape(juanjihe,(1,1,3,3))
class Lzj(nn.Module):
def __init__(self):
super(Lzj, self).__init__()
self.maxpool1=nn.MaxPool2d(kernel_size=3,ceil_mode=True)#采用最大池化
def forward(self,input):
output=self.maxpool1(input)
return output
lzj=Lzj()
output=lzj(input)
print(output)
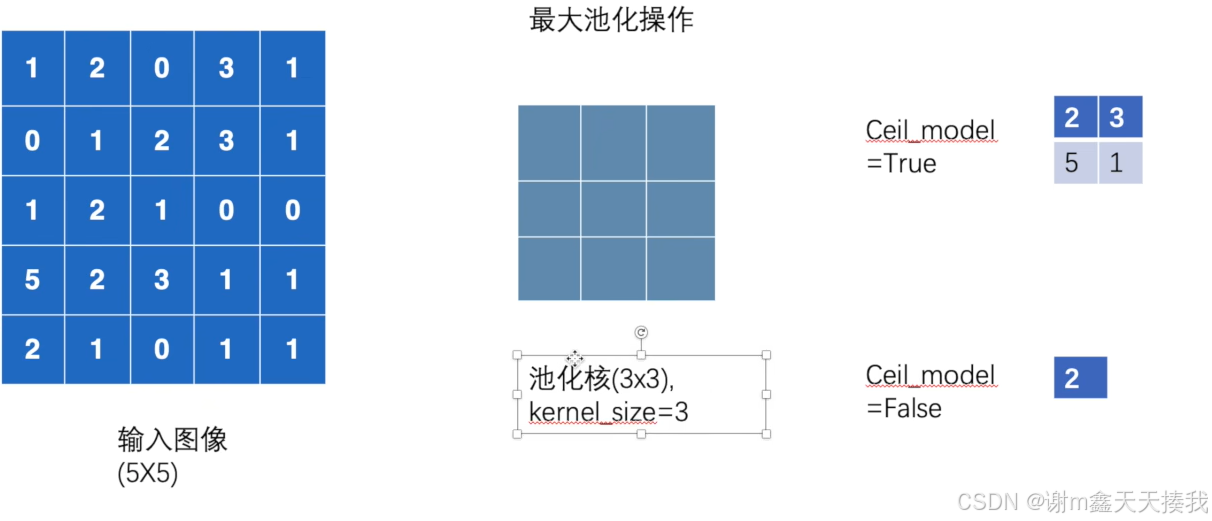
ceil_mode的作用就是当池化到边缘的尺寸不够3x3时依然能够进行最大池化操作,如果为false则无法进行最大池化。
在进行图片处理的过程中,最大池化提取了卷积后的图片的最重要特征,类似于1080p的视频,我们直接发送太久了,于是系统就给我们压缩成720p发送出去,我们可以通过几张图片来看看:
import torch
import torch.nn as nn
import torchvision
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
dataset_transform=torchvision.transforms.ToTensor()
dataset=torchvision.datasets.CIFAR10(root="./dataset",train=True,transform=dataset_transform,download=True)
dataloader=DataLoader(dataset,batch_size=64)
# input=torch.tensor([[1,2,0,3,1],
# [0,1,2,3,1],
# [1,2,1,0,0],
# [5,2,3,1,1],
# [2,1,0,1,1]],dtype=torch.float32)#[[]]表示这是一个二维的矩阵,定义输入图片
# juanjihe=torch.tensor([[1,2,1],
# [0,1,0],
# [2,1,0]])#定义卷积核
# input=torch.reshape(input,(-1,1,5,5))#-1自动计算channel的大小
# juanjihe=torch.reshape(juanjihe,(1,1,3,3))
class Lzj(nn.Module):
def __init__(self):
super(Lzj, self).__init__()
self.maxpool1=nn.MaxPool2d(kernel_size=3,ceil_mode=True)#采用最大池化
def forward(self,input):
output=self.maxpool1(input)
return output
lzj=Lzj()
writer=SummaryWriter("log_maxpool")
setp=0
for data in dataloader:
img,targets=data
writer.add_images("input",img,setp)
output=lzj(img)
writer.add_images("output",output,setp)
setp=setp+1
writer.close()
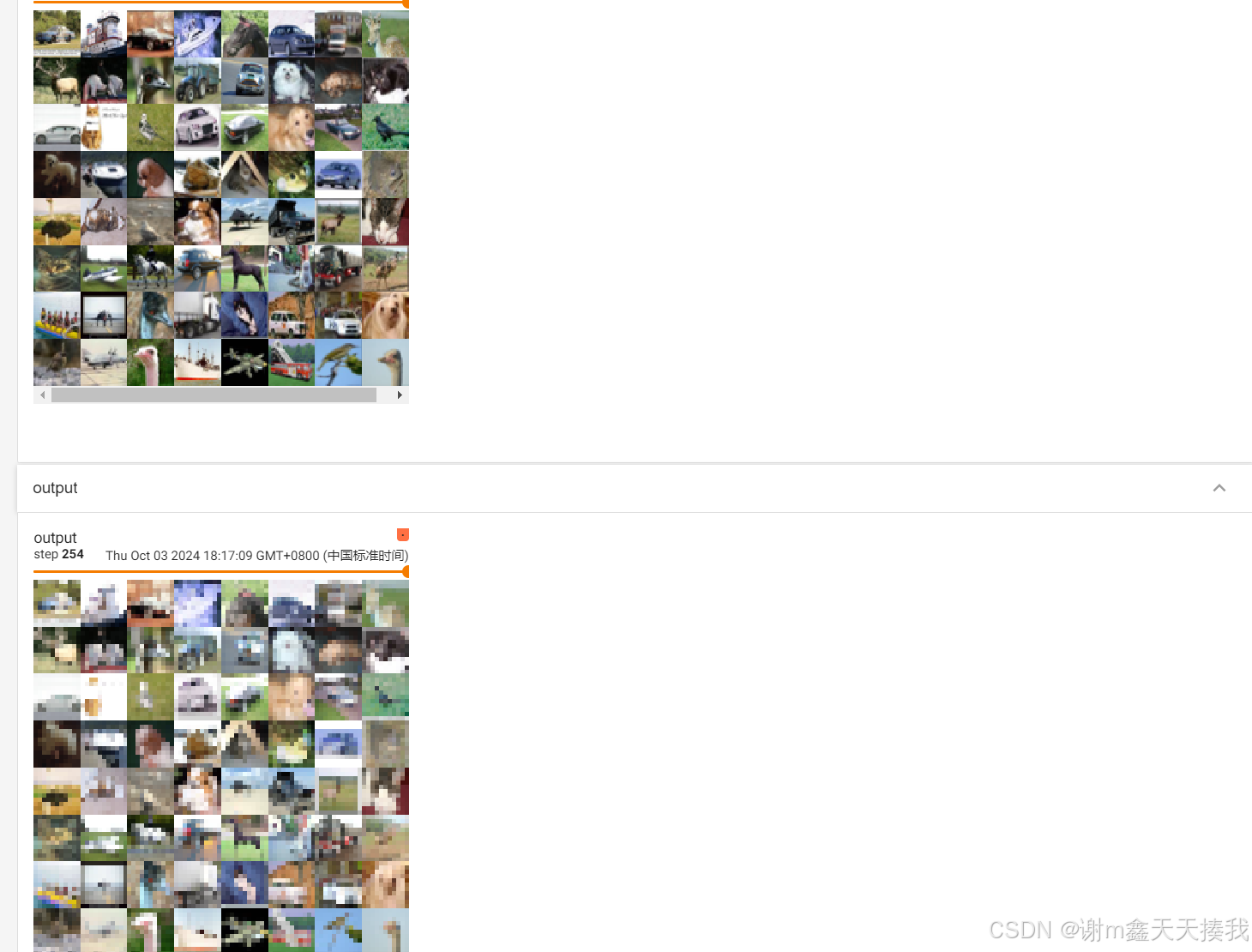
可以看出经过最大池化处理过后的图片有点像压缩后的视频,变得模糊了,最大池化将图片的最大特征成功提取了出来。
3.非线性激活
在神经网络中我们经常采用非线性的激活函数如RELU,sigmoid,softmax,我们来看以下示例:
import torch
import torch.nn as nn
input=torch.tensor([[1,-3,-9],
[4,-5,-7],
[-5,6,8]])
shuru=torch.reshape(input,(-1,1,3,3))#-1用来自动计算batch_size
print(shuru.shape)
class Lzj(nn.Module):
def __init__(self):
super(Lzj, self).__init__()
self.relu1=nn.ReLU()
def forward(self,input):
output=self.relu1(input)
return output
lzj=Lzj()
output=lzj(shuru)
print(output)
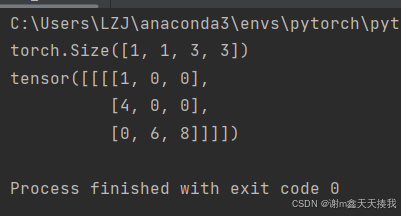
该神经网络的激活层采用relu函数将矩阵中的负值都归为0。
import torch
import torch.nn as nn
# input=torch.tensor([[1,-3,-9],
# [4,-5,-7],
# [-5,6,8]])
#
# shuru=torch.reshape(input,(-1,1,3,3))#-1用来自动计算batch_size
# print(shuru.shape)
import torchvision
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
dataset_transform=torchvision.transforms.ToTensor()
dataset=torchvision.datasets.CIFAR10(root="./dataset",train=True,transform=dataset_transform,download=True)
dataloader=DataLoader(dataset,batch_size=64)
class Lzj(nn.Module):
def __init__(self):
super(Lzj, self).__init__()
self.sigmoid1=nn.Sigmoid()
def forward(self,input):
output=self.sigmoid1(input)
return output
lzj=Lzj()
writer=SummaryWriter("sigmoid")
setp=0
for data in dataloader:
imgs,targets=data
writer.add_images("input",imgs,setp)
output=lzj(imgs)
writer.add_images("output",output,setp)
setp=setp+1
writer.close()
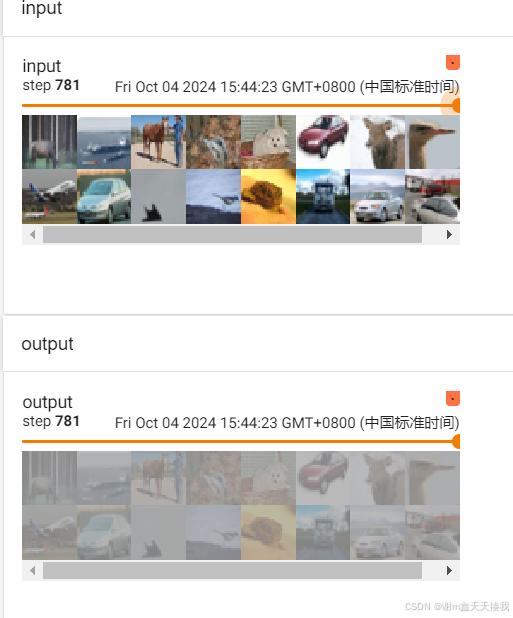
上述例子是我们运用sigmoid来处理图片,经过读取图像以后,会将彩色图像转变为灰度图,然后将图片的像素应用sigmoid函数。
总结
下周开始尝试构建一整个完整的CNN来对数据集进行训练,并且准备开始对RNN进行学习。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









