






提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
文章链接
摘要
经验重放(ER)当前面临着噪声转换、大内存和不稳定返回的挑战。基于ER的经验重放优化(ERO)是一种新颖的强化学习算法,它使用深度重放策略进行经验选择。然而,ERO 依赖于简单的先进先出 (FIFO) 保留策略,该策略旨在通过不断保留最近的经验来管理重放内存,而不管它们与代理的学习有何相关性。 当回放内存已满时,FIFO 会依次用新的体验覆盖最旧的经验。 针对这一问题,本博客介绍了论文《Experience Replay Optimization via ESMM for Stable Deep Reinforcement Learning》所提出的强顺序内存管理的经验重放优化(ERO-ESMM)。ERO-ESMM 使用改进的顺序保留策略来有效管理重放内存并稳定 DRL 代理的性能。实验结果表明,ESMM 的表现优于其他五种基本保留策略。
Abstract
Experience replay (ER) is currently facing the challenges of noise conversion, large memory, and unstable returns. ER-based Experience Replay Optimization (ERO) is a novel reinforcement learning algorithm that uses deep replay strategies for empirical selection. However, ERO relies on a simple first-in, first-out (FIFO) retention strategy that is designed to manage replay memory by continuously retaining recent experiences, regardless of their relevance to the agent’s learning. When the playback memory is full, the FIFO overwrites the oldest experience with the new experience in turn. In response to this problem, this blog introduces the Experience Replay Optimization (ERO-ESMM) proposed in the paper “Experience Replay Optimization via ESMM for Stable Deep Reinforcement Learning”. ERO-ESMM uses an improved sequential retention policy to effectively manage replay memory and stabilize the performance of DRL agents. Experimental results show that ESMM outperforms the other five basic retention strategies.
一、相关理论
1.经验重放(ER)
“经验重放”(ER)是强化学习( RL)中的一种技术,主要用于提升学习效率和稳定性,尤其是在深度强化学习(Deep Reinforcement Learning, DRL)中。
通过 ER,智能体以特定的时间间隔使用探索-利用方法生成经验,并将其存储在固定大小的重播内存中。 然后,智能体从重放缓冲区中均匀随机地采样这些经验到小批量中,并重复使用它们来训练 RL 算法。 这种随机选择防止了采样体验之间的高度相关性。
经验重放(ER)通过经验池来保存智能体与环境交互的历史经验,该经验池通常以四元组**(s_t, a_t, r_t, s_{t+1})**的方式来储存经验。
s_t:在时间步 t 时的状态
a_t:在时间步 t 时采取的动作
r_t:执行动作 a_t 后,环境反馈的奖励
s_{t+1}:执行动作后的下一个状态
2.经验回放优化(ERO)
ERO 是一种依赖奖励和 TDE(时间差误差) 进行优先级排序的经验选择方法。与其他倾向于具有较高 TD 错误的体验的 TDE 优先级采样策略不同,ERO 选择较少意外的 TDE 经验,并使用新颖的重放策略网络进行优先级划分过程。 创建了一个小批量的高优先级转换,并对其元素进行统一采样以训练智能体 。 代理与环境交互后,转换将存储在重播缓冲区中,随后使用重播策略通过布尔 (0, 1) 向量化过程确定优先级。 在训练期间,重放策略接收来自环境的反馈以进行策略评估。
ERO 算法新颖性取决于其重放策略网络,该网络依赖于以下(1)-(4)式方程:


(1)式中
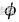
表示函数近似器,λ表示优先级参数,θ^是函数近似器的参数,B表示重放缓冲器
(2)式中B^s表示采样转换的指定批量大小
(3)式中从左到右分别是重放奖励当前策略的累积奖励和前一策略的累积奖励
3.优先随机内存管理(PSMM)
设计不当的保留技术可能会对学习代理的性能产生负面影响,为了能够更好地配合经验重放算法,研究者使用了种有效重放内存管理的建议方法是优先随机内存管理(PSMM)。PSMM 采用随机方法来删除具有最少 TDE 的历史记录,或者使用等式 1 中计算的概率在重放内存已满时返回。
PSMM中计算消除概率的公式如下:

该方法采用多个超参数,如α actor 、α critic 和 ρ,这些超参数经过优化以提高性能。α actor和α critic 分别确定分配给 actor 和 critic 组件的相对权重,而 ρ 表示概率调整参数。这种方法确保了历史数据的有效利用,并有助于优化方法的参数。
4.经验重放优化(ERO-ESMM)
研究者进一步研究了ESMM、PSMM(α)和PSMM(ρ)三种新的保留策略。将这些策略与FIFO、Full DB、Resv一起研究对ERO - 增强DDPG算法的影响,找出平均回报最高的策略(ESMM)并将其纳入ERO框架构建ERO - ESMM,ERO-ESMM框架图如下所示:
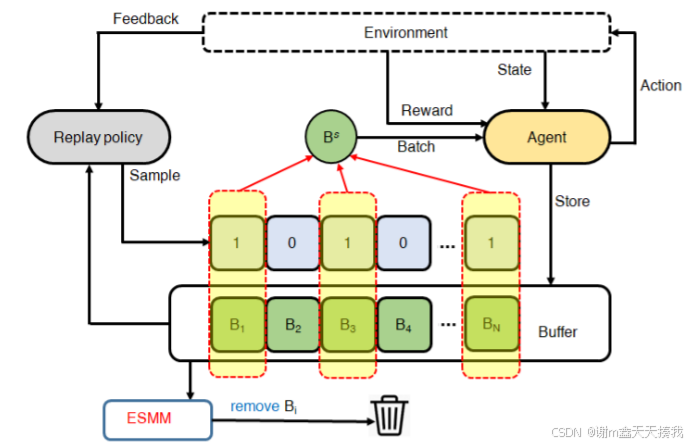
来自环境的转换存储在重播缓冲区中, 来自转换的小批量被矢量化,根据重放策略确定优先级,并随机均匀采样以训练代理。 训练后,重放策略会收到反馈以进行策略评估。 当内存已满时,ESMM 确保重放内存前半部分的转换按顺序被新的转换覆盖。
二、实验部分
1.实验概况
为了验证所提出的经验重放优化(ERO-ESMM)框架,研究者在OpenAI Gym的Pendulum - v0、MountainCarContinuous - v0、LunarLanderContinuous - v2和BipedalWalker - v3环境中进行实验来完成相应的强化学习任务。基于ERO - 增强DDPG算法,采样和保留方法的超参数分别与ERO和PSMM一致,调整内存大小和时间步长。
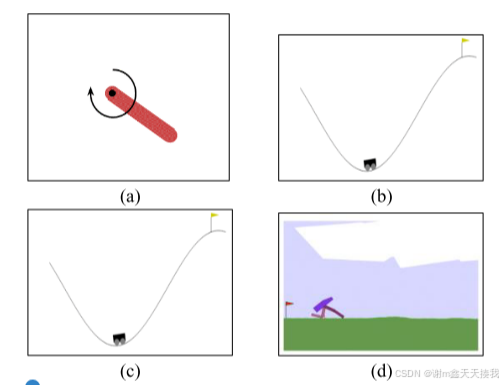
(a)Pendulum-v0提出了一个经典的倒立摆摆动问题,要求智能体从初始任意位置持续摆动摆锤直到达到直立位置。
(b)MountainCarContinously-v0 环境是另一个基准经典控制环境,它要求 RL 代理对汽车应用动作以尽快到达山顶。
©LunarLanderContinously-v2 是原始 Box2D 离散动作空间 LunarLander-v2 环境的扩展,其中代理控制月球着陆器尝试降落在月球表面指定的着陆垫上。强化学习代理会因靠近着陆场而获得正向奖励,并因安全着陆而获得显着的正向奖励。 使用燃料会给予负奖励,并且每个时间步都会给予轻微的负奖励。
(d)BipedalWalker-v3 类似于 Box2D 环境,其中要求强化学习代理控制具有四条腿的双足机器人,并且必须学会让它在复杂的地形中行走和导航,同时避开障碍物。
2.评估指标
回报,也称为累积奖励或累积回报,是强化学习代理在实现其目标方面总体成功程度的衡量标准,它是智能体在从剧集开始到结束的每个时间步收到的奖励的总和。返回值通常用于评估和比较特定强化学习任务中不同算法和策略的性能,平均回报可按下式计算:
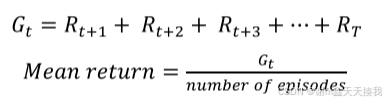
其中,Gt 是回报, Rt+1是时间步 t 的奖励,T 是最终时间步。
3.实验结果
实验的代码如下:
from tensorflow.python.keras.models import Model
from tensorflow.python.keras.layers import Dense, Multiply
from ...feature_column import build_input_features, input_from_feature_columns
from ...layers.core import PredictionLayer, DNN
from ...layers.utils import combined_dnn_input
def ESMM(dnn_feature_columns, tower_dnn_hidden_units=(256, 128, 64), l2_reg_embedding=0.00001, l2_reg_dnn=0,
seed=1024, dnn_dropout=0, dnn_activation='relu', dnn_use_bn=False, task_types=('binary', 'binary'),
task_names=('ctr', 'ctcvr')):
Instantiates the Entire Space Multi-Task Model architecture.
:param dnn_feature_columns: An iterable containing all the features used by deep part of the model.
:param tower_dnn_hidden_units: list,list of positive integer or empty list, the layer number and units in each layer of task DNN.
:param l2_reg_embedding: float. L2 regularizer strength applied to embedding vector.
:param l2_reg_dnn: float. L2 regularizer strength applied to DNN.
:param seed: integer ,to use as random seed.
:param dnn_dropout: float in [0,1), the probability we will drop out a given DNN coordinate.
:param dnn_activation: Activation function to use in DNN
:param dnn_use_bn: bool. Whether use BatchNormalization before activation or not in DNN
:param task_types: str, indicating the loss of each tasks, ``"binary"`` for binary logloss or ``"regression"`` for regression loss.
:param task_names: list of str, indicating the predict target of each tasks. default value is ['ctr', 'ctcvr']
:return: A Keras model instance.
"""
if len(task_names) != 2:
raise ValueError("the length of task_names must be equal to 2")
for task_type in task_types:
if task_type != 'binary':
raise ValueError("task must be binary in ESMM, {} is illegal".format(task_type))
features = build_input_features(dnn_feature_columns)
inputs_list = list(features.values())
sparse_embedding_list, dense_value_list = input_from_feature_columns(features, dnn_feature_columns,
l2_reg_embedding, seed)
dnn_input = combined_dnn_input(sparse_embedding_list, dense_value_list)
ctr_output = DNN(tower_dnn_hidden_units, dnn_activation, l2_reg_dnn, dnn_dropout, dnn_use_bn, seed=seed)(
dnn_input)
cvr_output = DNN(tower_dnn_hidden_units, dnn_activation, l2_reg_dnn, dnn_dropout, dnn_use_bn, seed=seed)(
dnn_input)
ctr_logit = Dense(1, use_bias=False)(ctr_output)
cvr_logit = Dense(1, use_bias=False)(cvr_output)
ctr_pred = PredictionLayer('binary', name=task_names[0])(ctr_logit)
cvr_pred = PredictionLayer('binary')(cvr_logit)
ctcvr_pred = Multiply(name=task_names[1])([ctr_pred, cvr_pred]) # CTCVR = CTR * CVR
model = Model(inputs=inputs_list, outputs=[ctr_pred, ctcvr_pred])
return model
在各个环境中的实验结果如下:
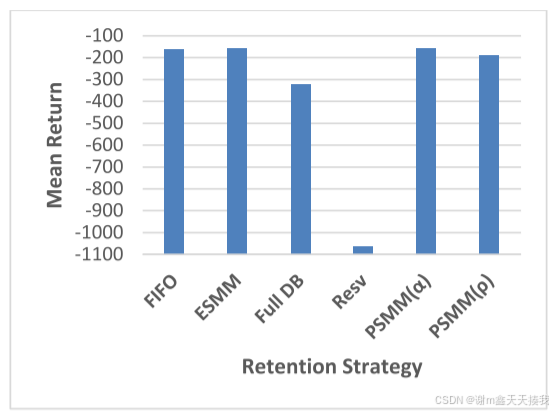
在 Pendulum 环境中,如图所示,ESMM 和 PSMM(α) 策略与 FIFO 相比表现出优越的性能,而 Full DB 和 PSMM(ρ) 策略表现较差。 Resv 策略的有效性有限,因为它在学习最佳策略以稳定钟摆方面面临挑战。
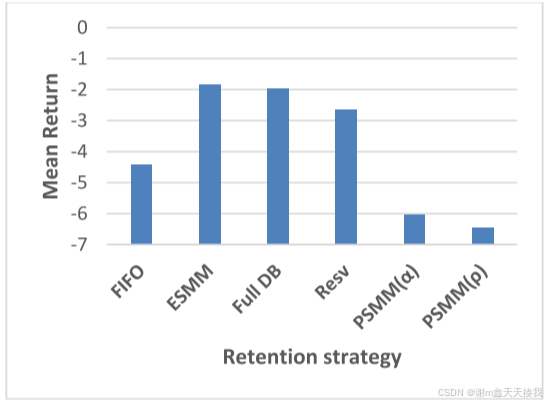
在 MountainCarContinously-v0 环境中,ESMM 策略优于所有其他模型,包括 FIFO。 Full DB 和 Resv 策略比 FIFO 有一些改进,而 PSMM(α) 和 PSMM(ρ) 表现较差,奖励分别为 -6.05 和 -6.46。
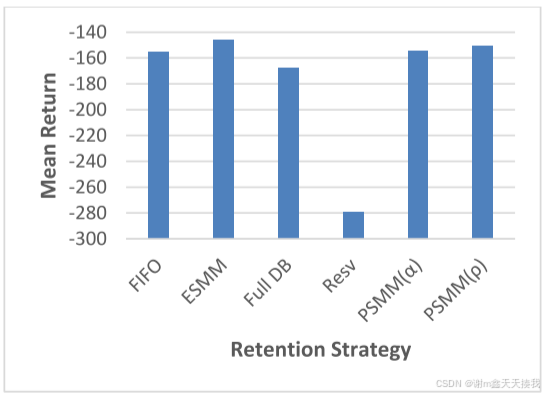
在 LunarLanderContinously-v2 环境中,如图所示,ESMM、PSMM(α) 和 PSMM(ρ) 策略与 FIFO 相比表现出优越的性能。 Full DB 模型的性能比 FIFO 和 PSMM(ρ) 差,而 Resv 模型的性能最差。
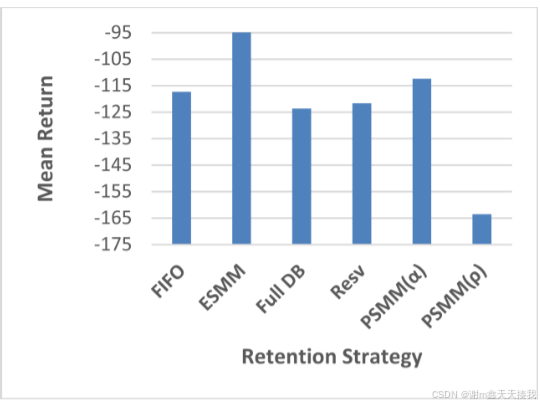
在 BipedalWalker-v3 环境中,ESMM 和 PSMM(α) 模型的性能优于 FIFO 策略。 然而,Full DB 和 Resv 模型的性能比 ESMM 和 PSMM(α) 差,其中 PSMM(ρ) 在该环境下的所有模型中表现最差。
结果表明,不同 OpenAI Gym 环境中的模型性能存在显着差异。 ESMM 策略通常在实验环境中表现出更好、更稳定的性能,这可以归因于其在重放缓冲区中公平分配经验。 虽然 PSMM(α) 模型在 Pendulum 环境中表现更好,但在 Lunar Lander Continuous-v2 环境中,PSMM(ρ) 策略比除 ESMM 之外的其他模型表现更好相反,全数据库模型在大多数环境中往往表现较差,因为所有经验都被存储,包括在 RL 代理训练的早期阶段获得的最差经验。 Resv 策略的性能在各个环境中表现出不一致,因为它采用完全随机的策略来识别重播缓冲区已满时要删除的体验。
总结
1、研究者开发了ESMM、PSMM(α)和PSMM(ρ)三种新的留存策略以提高经验回放的有效性,研究了六种不同留存策略对ERO - 增强DDPG算法的影响,提出将性能最高的留存策略纳入ERO框架的增强框架ERO - ESMM,实验结果表明开发新留存策略并融入现有框架可提升强化学习算法性能。
2、开发三种新留存策略,为强化学习中管理智能体记忆提供新选择;提出的ERO - ESMM框架整合了最优留存策略,优化经验回放,提升强化学习任务性能。可使用单独神经网络预测回放缓冲区超限需删除经验的索引;进一步探索不同环境下策略的泛化能力;研究如何更好地平衡记忆使用和相关经验留存;探索新的策略组合以提升强化学习算法性能。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









