






提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
摘要
本博客主要通过阅读了论文《DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning》介绍了关于deepseek的研究背景和理论方法,《DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning》是一篇由 DeepSeek 团队发表的论文,聚焦于通过强化学习RL提升大语言模型的推理能力。论文提出了一种创新方法——群体相对策略优化(GRPO),旨在减少对人工标注数据的依赖,同时显著增强模型在复杂推理任务中的表现。DeepSeek-R1 以 DeepSeek 67B 模型为基础,通过纯 RL 训练,跳过了传统的监督微调和人类偏好优化的步骤,直接利用数学和代码任务的自动化反馈信号进行优化。GRPO 通过在模型生成的多条回答中进行相对排序,构建奖励机制,避免了传统 RL 中对绝对奖励模型的复杂需求。
Abstract
This blog mainly introduces the research background and theoretical methods of deepseek by reading the paper “DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning”. Reinforcement Learning is a paper published by the DeepSeek team that focuses on improving the inference capabilities of large language models through reinforcement learning (RL). This paper proposes an innovative method, Population Relative Strategy Optimization (GRPO), which aims to reduce the dependence on manually annotated data and significantly enhance the performance of the model in complex inference tasks. Based on the DeepSeek 67B model, DeepSeek-R1 bypasses the traditional steps of supervised fine-tuning and human preference optimization through pure RL training, and directly leverages automated feedback signals from mathematical and code tasks for optimization. GRPO constructs a reward mechanism by ranking multiple responses generated by the model, avoiding the complex need for an absolute reward model in traditional RL.
一、DeePSeek R1介绍
1.DeepSeek研发背景和概括
近年来,大型语言模型LLMS一直在经历快速的迭代和进化,逐渐减少了对人工通用情报AGI的差距。OpenAI的O1系列模型是第一个通过增加链条进行推理过程的长度来引入推理时间扩展的模型。 这种方法在各种推理任务,例如数学,编码和科学推理方面取得了重大改进。 但是,有效测试时间扩展的挑战仍然是研究界的一个悬而未决的问题。
在论文中,开发者团队迈出了使用纯强化学习(RL)提高语言模型推理能力的第一步。目标是探索LLMS在没有任何监督数据的情况下开发推理能力的潜力,并通过纯RL过程着重于他们的自我进化。
开发团队一Deepseek-v3为基键作为基本模型,并使用GRPO作为RL框架来提高推理中的模型性能。 在培训期间,DeepSeek-R1-Zero自然出现了许多强大而有趣的推理行为。
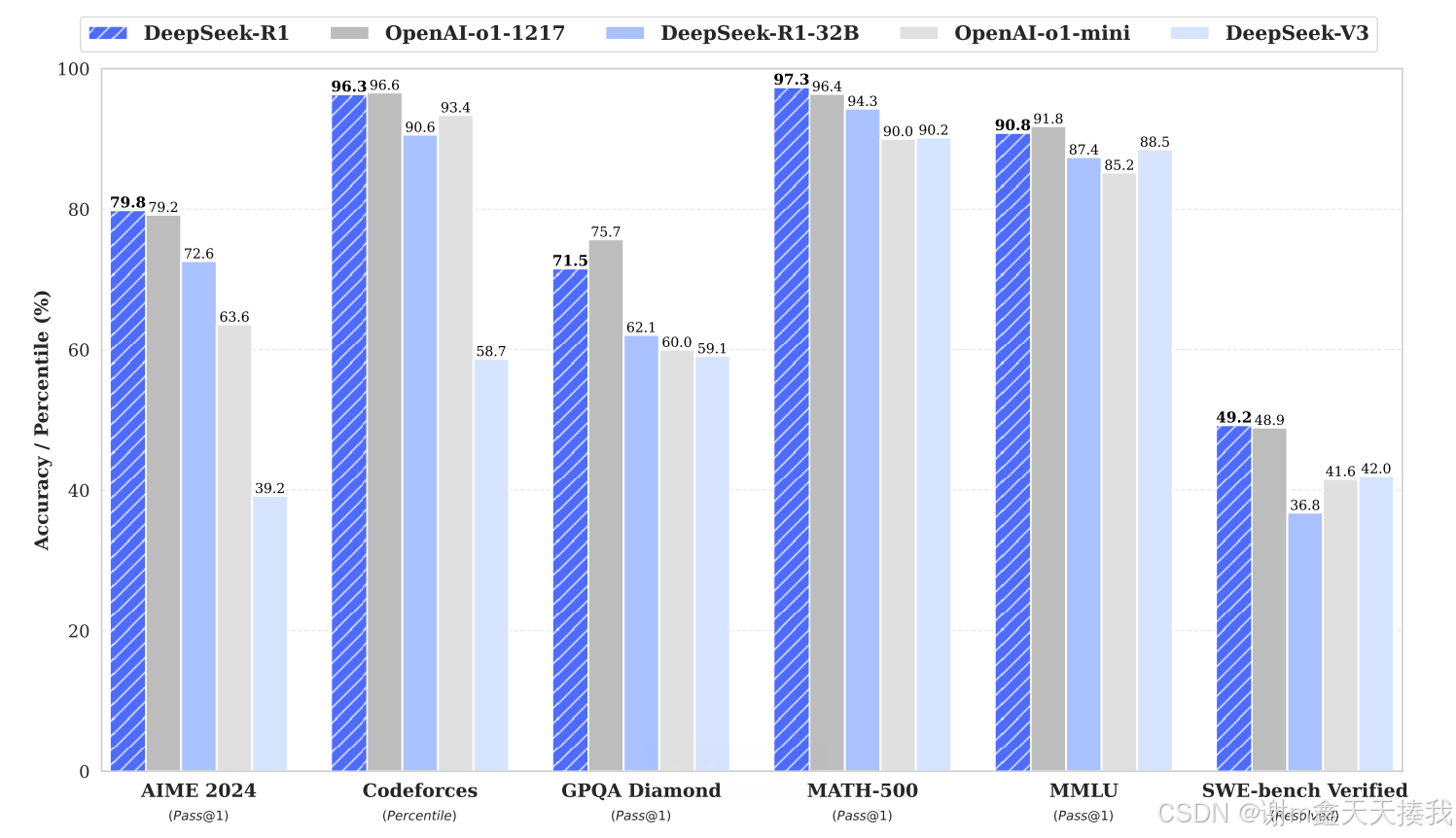
但是,DeepSeek-R1-Zero遇到了挑战,例如不良的可读性和语言混合。 为了解决这些问题并进一步提高推理性能,开发团队引入了DeepSeek-R1,其中包含了少量的冷启动数据和多阶段培训管道。具体来说,就是当deepseek-r1-zero在多次RL收敛以后,通过在RL检查点上拒绝采样来创建新的SFT数据,并结合来自DeepSeek-V3的监督数据,然后重新验证DeepSeek-V3 - 基本模型。 对新数据进行了微调后,从所有情况下考虑了提示,检查点会经历一个额外的RL进程。 在这些步骤之后,获得了一个称为DeepSeek-R1的检查点,下图为deepseek-r1性能的基准表现:
2.模型蒸馏
开发团队还发现,与小型模型上通过RL发现的推理模式相比,较大模型的推理模式可以蒸馏成较小的模型。 开源DeepSeek-R1及其API将使研究界有益于将来更好的较小模型。
开发团队将Deepseek-r1模型蒸馏出了多个型号,分别为1.5b,7b,8b,14b,32b,671b如下图所示: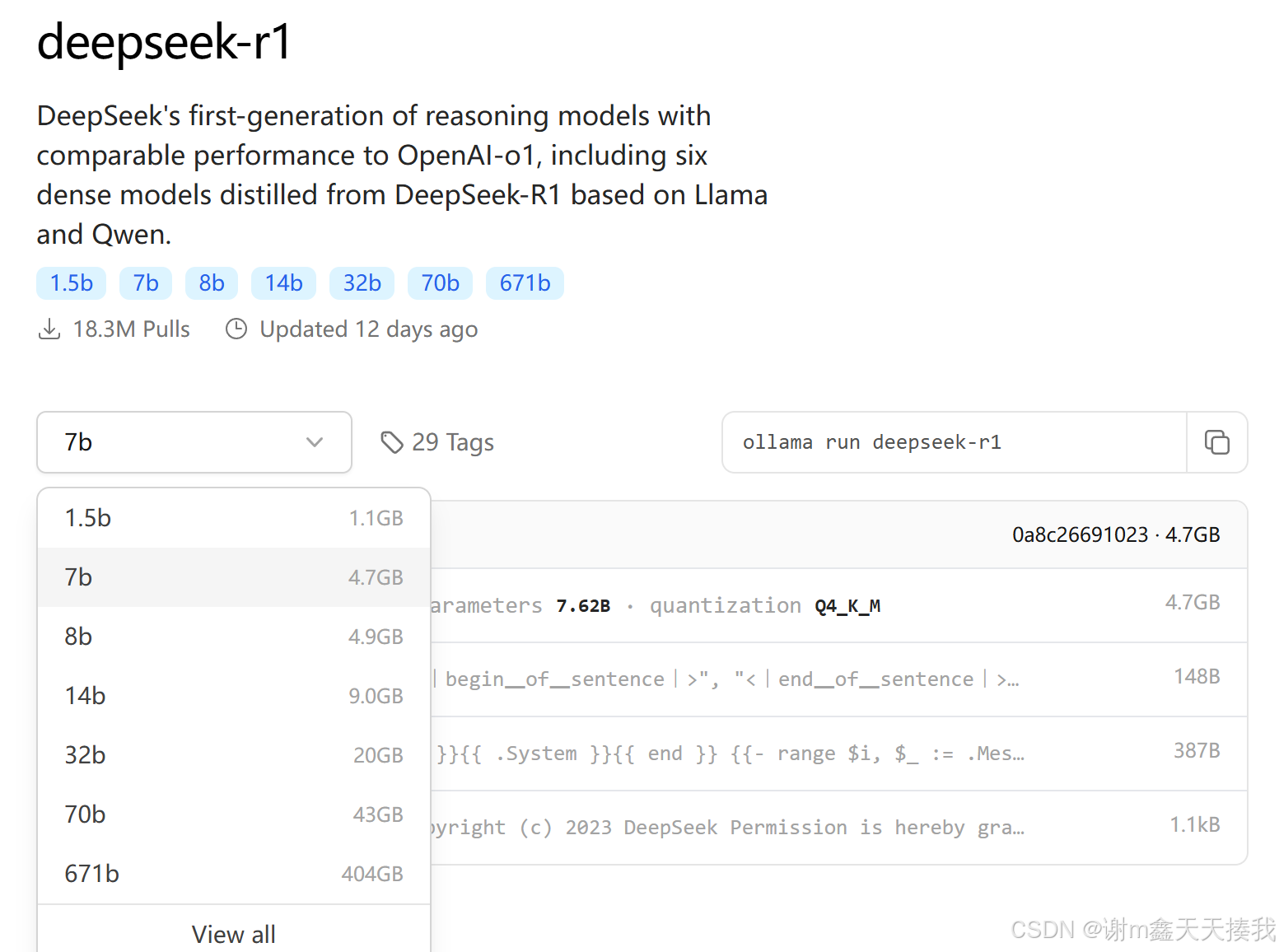
使用DeepSeek-R1生成的推理数据,开发团队微调了几种在研究社区中广泛使用的密集模型。 评估结果表明,蒸馏的较小密度模型在基准上表现出色。 DeepSeekr1-Distill-Qwen-7b在AIME 2024上获得55.5%,超过了QWQ-32b-preview。 此外,DeepSeek-R1-Distill-QWEN-32B在AIME 2024上的得分为72.6%,Math-500的分数为94.3%,LiveCodeBench的得分为57.2%。 这些结果的表现明显优于先前的开源模型,并且与OpenAI-O1相当。
3.实现算法
3.1增强学习算法(RL)
为了减少增强学习的训练成本,开发团队采用了组相对策略优化(GRPO),GRPO放弃了通常与策略模型大小相同的批评者模型,而是根据组分数来估计基线。GRPO从旧策略模型中抽取一组输出,然后通过最大化以下目标来优化策略模型,其公式如下:
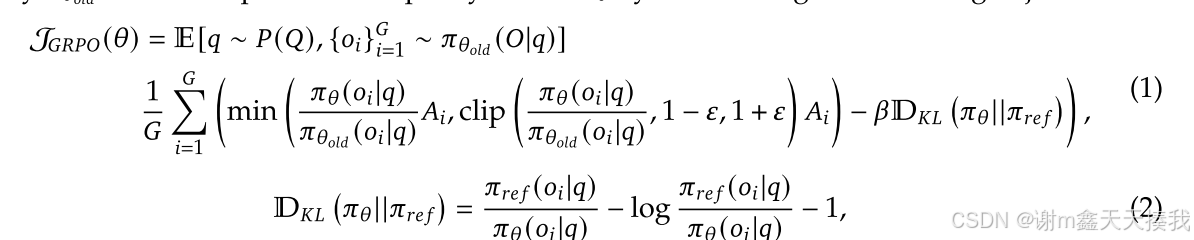
其中𝜀和𝛽是超参数,而𝐴𝑖是使用一组奖励{𝑟1,𝑟2,。 。 。 ,𝑟𝐺}对应于每个组中的输出:
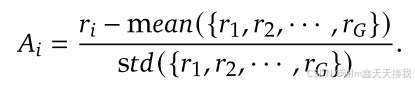
(上述公式由于目前个人所学有限,只能作为知识拓展,还有待更好地去学习和理解)
3.2奖励建模
奖励是训练信号的来源,它决定RL的优化方向,开发团队为了训练Deepseek-R1-zero,采用了一个基于规则的奖励系统,该系统主要由两种类型的奖励组成:
精确度奖励:准确性响应模型负责评估回答是否正确。例如对于有固定正确结果的数学问题,除了评估模型最后的回答是否符合答案,还要从对应的理论依据或者整个解题的过程来评估回答,实现了基于可靠的规则的正确性验证正确性。
格式奖励:除了准确的奖励模型外,开发团队还采用了一种格式奖励模型,该模型可以强制该模型在“ ”和“ ”标签之间放置其思维过程。
3.3训练模板
在使用deepseekR1的时候,可以发现模型首先会进行不断地思考并给出思考的逻辑和思路,最后再给出答案:

这是因为在训练Deepseek-r1-zero时,开发团队就已经设计好了训练模板,此模板需要DeepSeek-R1-Zero首先产生推理过程,然后是最终答案,如下图所示:
3.4自我进化过程和Deepseek-R1-Zero的AHA
在AIME 2024基准测试中,DeepSeekr1-Zero的性能轨迹如图所示,随着RL训练的进步,DeepSeek-R1-Zero表现出稳定且一致的性能增强。
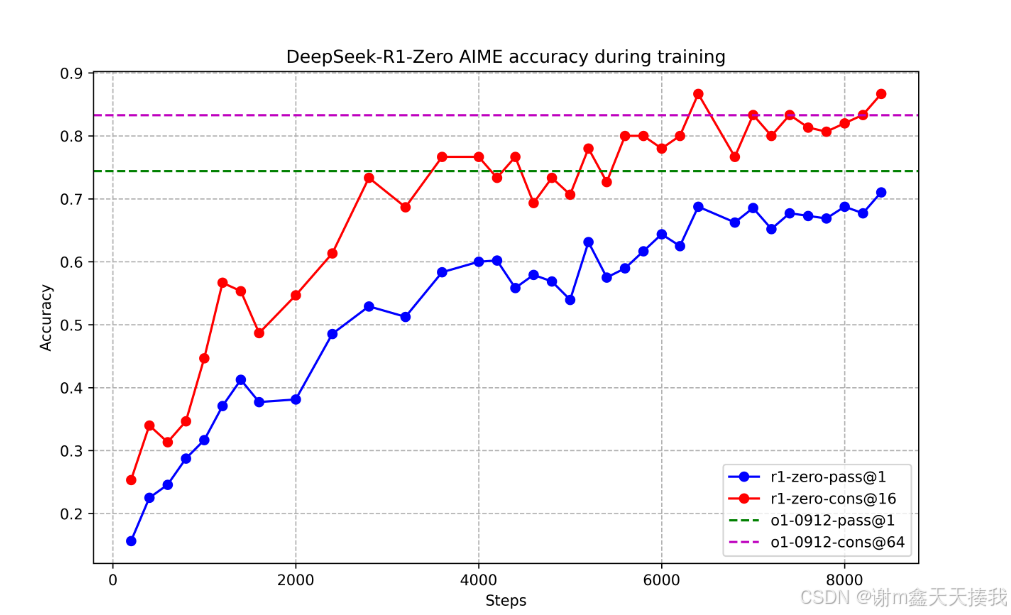
AIME 2024的平均通过@1得分显示出显着增加,从最初的15.6%跃升到71.0%,达到的性能水平与OpenAI-O1-0912相当。 这种重大的改进突出了我们的RL算法在随着时间的推移优化模型性能方面的功效。
DeepSeek-R1-Zero的自我进化过程是RL如何驱动模型以自动提高其推理能力的演示。通过直接从基本模型启动RL,开发团队可以密切监视模型的进展,而不会受到监督微调阶段的影响。 这种方法清楚地了解了该模型如何随着时间的流逝而演变,尤其是在处理复杂推理任务的能力方面。
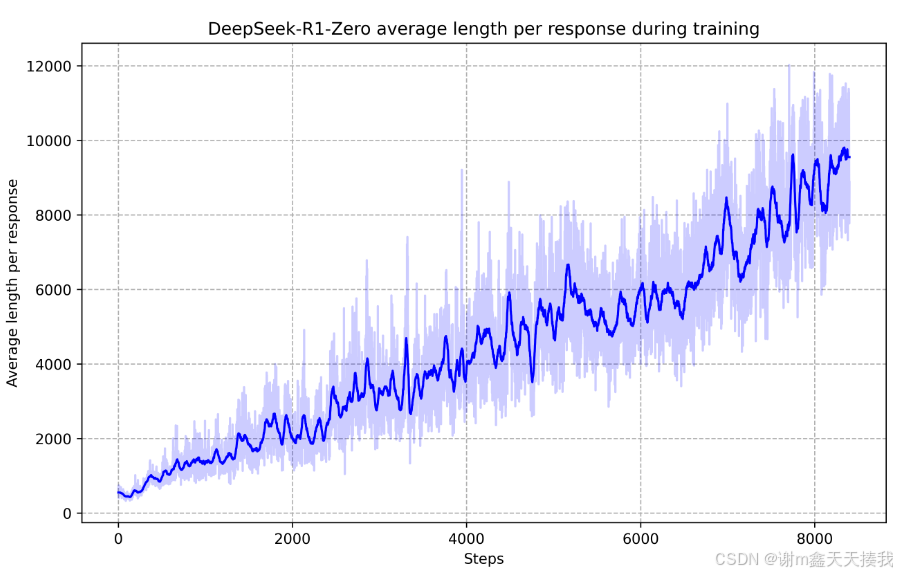
在RL过程中,DeepSeek-R1-Zero的平均响应长度。 DeepSeek-R1-Zero自然学会了以更多的思考时间来解决推理任务。DeepSeek-R1-Zero自然可以通过利用扩展的测试时间计算来获得解决日益复杂的推理任务的能力。 该计算范围从生成数百到数千个推理token,允许该模型更深入地探索和完善其思维过程。
DeepSeek-R1-Zero自我进化最明显的体现在于是随着测试时间计算的增加而复杂行为的出现。 例如反思之类的行为,并自发地探索了解决问题的替代方法。 这些行为不是明确编程的,而是由于模型与增强学习环境的相互作用而出现的。 这种自发的发展显着增强了DeepSeek-R1-Zero的推理能力,从而使其能够以更高的效率和准确性来应对更具挑战性的任务。
3.5 冷启动
冷启动是指在系统或模型的初始阶段,由于缺乏足够的历史数据或用户交互信息,导致其无法有效运行或做出准确预测的问题。
为了防止基本模型的RL训练的早期不稳定的冷启动阶段,对于DeepSeek-R1,开发团队构建并收集了少量的长COT数据,以微调该模型作为初始RL Actor。 为了收集此类数据,可采用以下方法:使用较少的弹药提示为一个示例,直接提示模型以反射和验证生成详细的答案,以可读的格式收集DeepSeek-R1Zero输出,并完善结果并完善结果。
二、本地部署和调用deepseek模型
1.本地部署deepseek
首先我们先打开Ollama的官网:ollama
点击下载将ollama下载到本地,然后点开命令行输入ollama,弹出以下界面说明安装成功:
安装好ollama以后,在网页上点击deepseek-r1模型,根据自己电脑的配置和性能选择相应的蒸馏模型,参数越多的蒸馏模型,对于电脑的配置要求更高: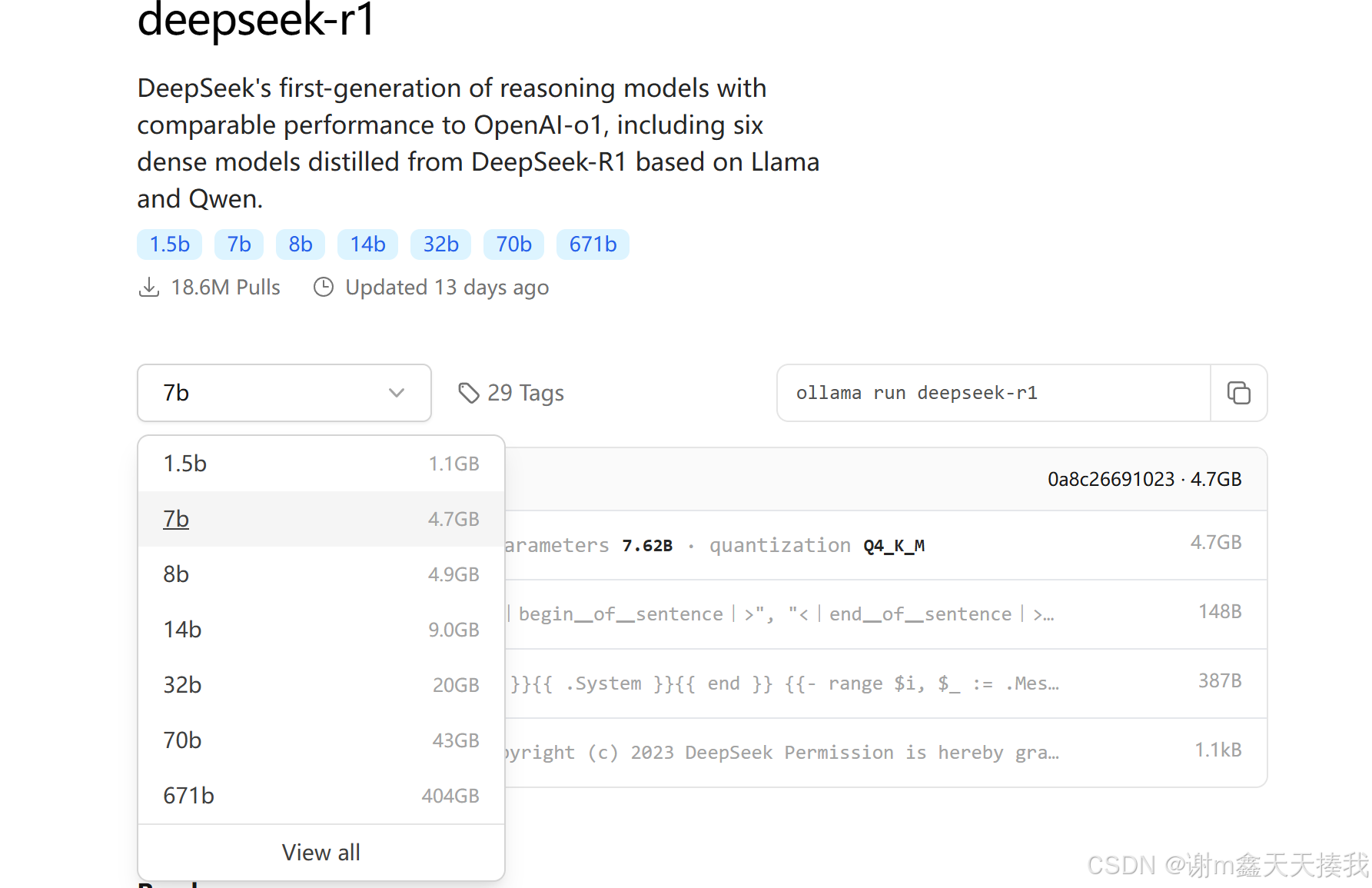
以我选择的32b蒸馏模型为例,在选择好模型复制以下命令并粘贴到命令行运行:
ollama run deepseek-r1:32b
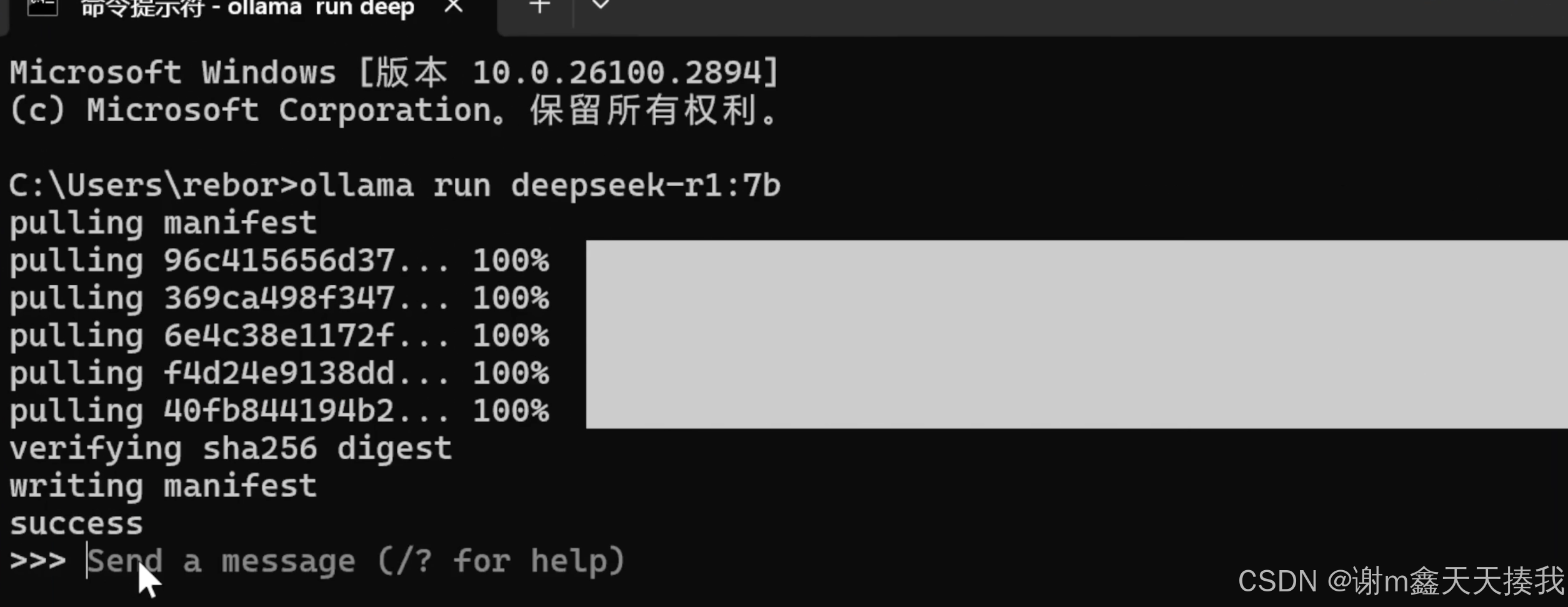
由于我本地的已经下载完成,所以我截取了网上其他用户下载的图片,下载完成以后可以在命令行直接开始对话:
为了获得更好地模型体验,可以选择一些支持llm的应用来作为容器,这里我选择的是cherry studio。
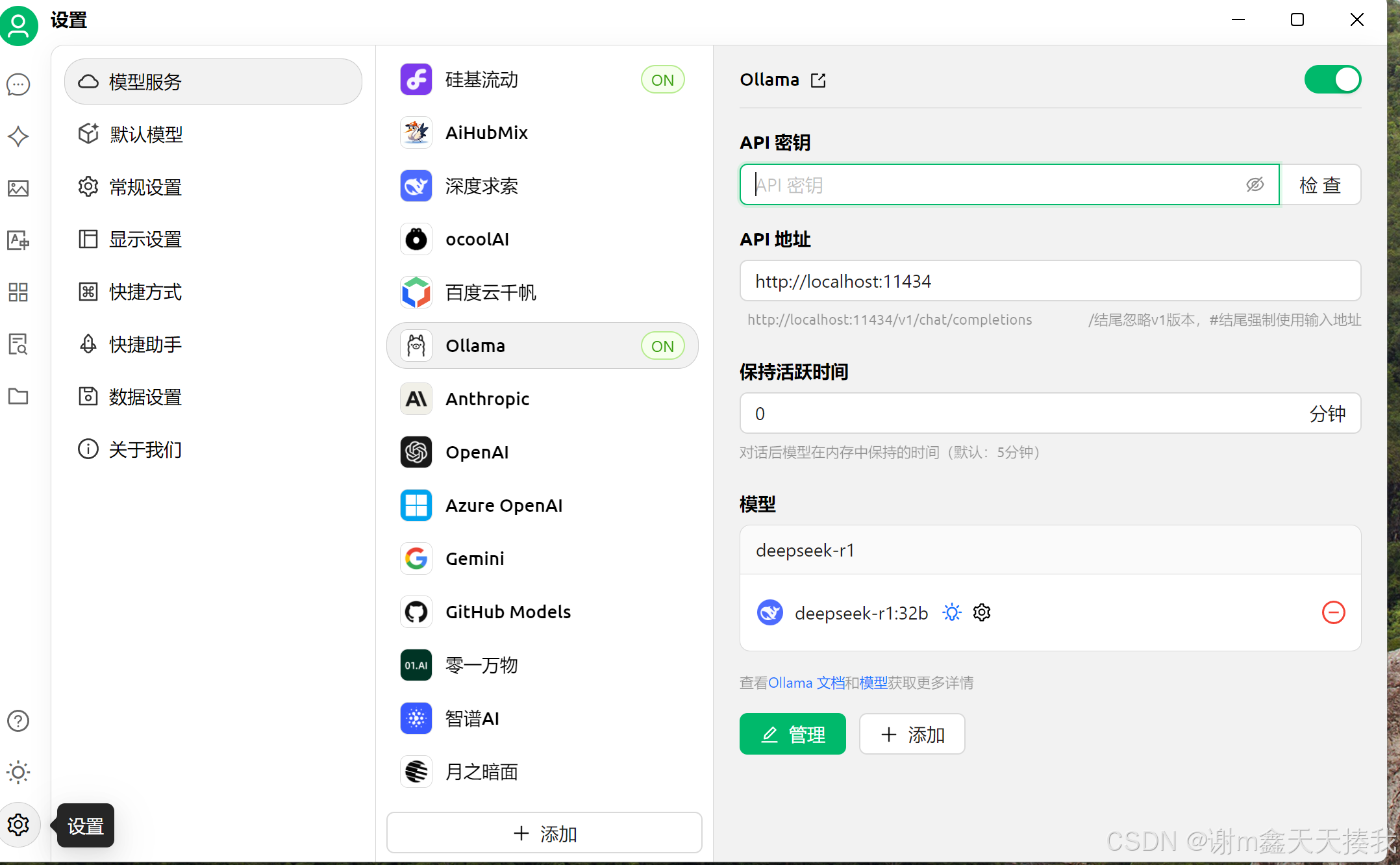
安装好后点击设置,选择ollama,将ollama开关打开,选择下载到本地的模型即可开始对话。
另外通过网上相关资料的查询,32b参数的deepseek本地模型的性能约为完整模型的70%左右。
2.deepseek 调用
除了在本地部署deepseek模型,我们也可以通过调用deepseek api来搭建自己的大模型,以下是本地调用deepseek的完整代码:
import requests
from openai import OpenAI
import time
def get_model_key(api_key):
url="https://api.deepseek.com/models"
payload={}
headers={'Accept':'application/json',
'Authorization':"Bearer{}".format(api_key)
}
response=requests.request(url=url,method='GET',headers=headers,data=payload)
print(response.text)
def deepseek_chat(api_key,messsage):
client=OpenAI(api_key=api_key,base_url="https://api.deepseek.com")
response=client.chat.completions.create(
model='deepseek-chat',
messages=[
{"role":"system","content":"你是一个聪明的系统,你现在需要回复我的问题"},
{"role":"user","content":"你好"}
],
stream=False
)
print(response.choices[0].message.content)
if __name__ == '__main__':
api_key='sk-d86171e93c7140e29dc8728d20de26ee'
print("你好请问有何贵干:")
message=input()
start_time=time.time()
# get_model_key(api_key)
deepseek_chat(api_key,message)
end_time=time.time()
print(f"deepseek_chat 此次调用花费时间为:{(end_time-start_time):.4f}秒")
get_model_key(api_key)负责获取对应的api密钥,在输入对应的url和密钥以后可以测试一下调用是否成功:
deepseek_chat(api_key,messsage)负责获取deepseek的回复:
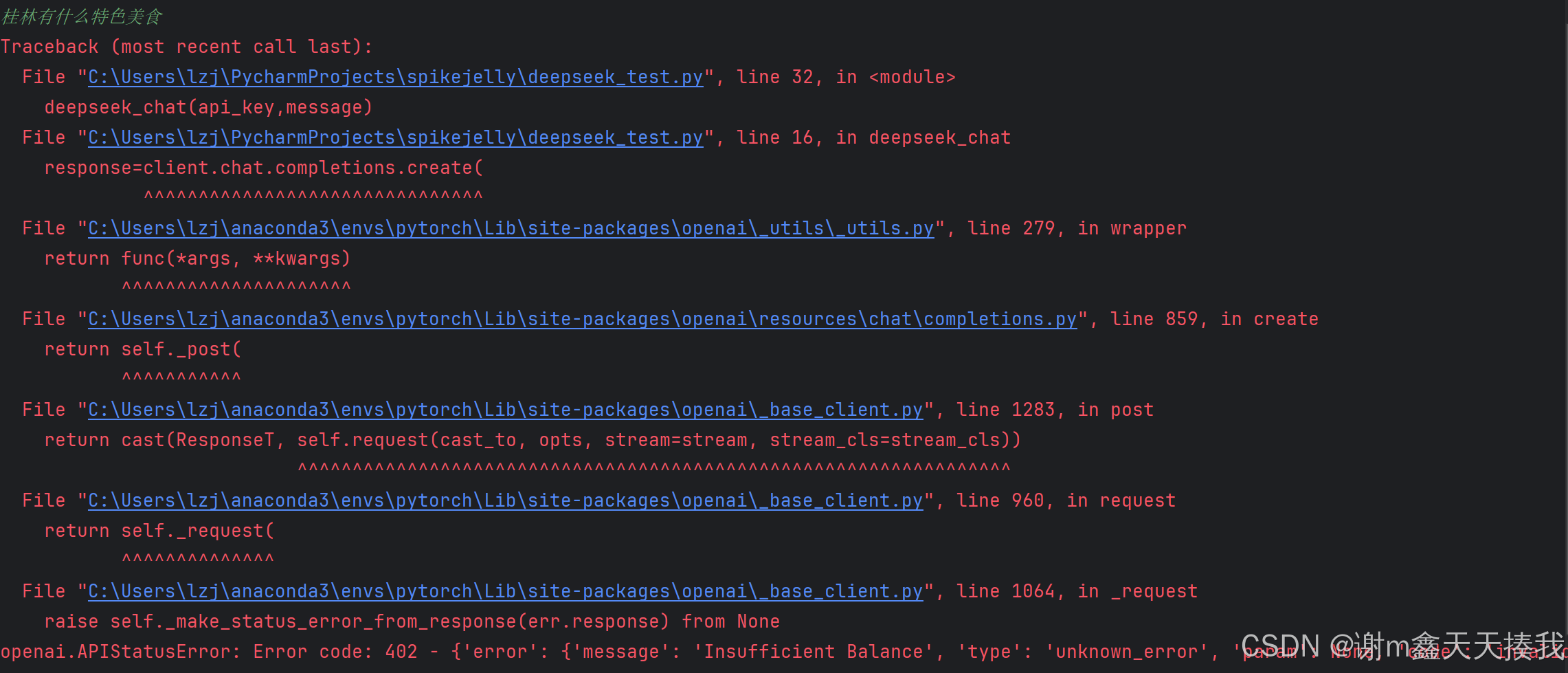
由于我调用deepseek时,由于服务器紧张开发团队已经暂停了api充值服务,所以出现了402报错。
总结
1.deepseek-R1不同于以往LLM专注于监督数据的训练过程,而是采用了多次强化学习(RL)的方式,更注重于大语言模型的自我进化,而无需依靠监督的微调(SFT)。 DeepSeekr1-Zero展示了自我验证,反思和产生长的COTS等能力,这标志着研究界的重要里程碑。 这是第一次验证LLM的推理能力可以纯粹通过RL激励,而无需SFT。
2.DeepSeek-R1-Zero代表了一种纯RL方法,而无需依靠冷启动数据,从而在各种任务中实现了强劲的性能。 DeepSeek-R1更强大,并利用迭代RL微调来利用冷启动数据。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









