






在草稿箱发现了这篇写到一半的文章,最近要备赛,又逢期中有考试,所以放在草稿箱没有动。今天把这个实战记录下来,也供大家学习。当然,如果我写的有什么不对,大家可以评论区交流指导我。钢材缺陷的数据集在各大网站都是公开的,但是数据是混在一起的。因为我们做的是分类任务,训练过程中6类钢材缺陷的训练集要分类好,也就是要做一步整合,代码很简单。当然,为了方便小伙伴们学习,处理好的数据集我放在资源里面了,需要的小伙伴可以自行下载。
数据集:
https://download.youkuaiyun.com/download/luoying189/92393727
一、理解模型
一开始本来不想写,但是我觉得理解底层原理是很重要的。用模型很简单,直接导包用,但是用了又不知道怎么个事,所以这里写一下供自己理解,也供大家学习。如果想直接实战的小伙伴移步数据预处理就好啦。
卷积神经网络是一种专门为处理图像、视频等网格结构数据而设计的深度学习模型。它的核心思想是:通过卷积操作,自动提取图像中的局部特征,并逐层组合成更高级、更抽象的特征,最终完成分类、检测或分割等任务。
举个简单的小例子:
我这里有一些小猫的图片
第一层CNN会识别出边缘(比如猫的轮廓)。
第二层会组合边缘,识别出耳朵、眼睛、鼻子。
第三层会进一步组合,识别出这是一只小猫咪。
整个过程不需要我来告诉它猫有尖尖的小耳朵,长长的胡须之类的,它自己从大量图片中学会了这些特征。
卷积神经网络有三个核心的东西:
1、卷积层
我们把图像切成很多小块,用同一组数字跟卷积核做“乘加”运算,得到一张新图。想象一下,你拿着手电筒在图像上逐格滑动,每照一个小区间就得到一个小数值,全部滑完就拼成一张特征图。
这里手写一个计算过程,供大家理解卷积层是怎么运算的(字有点丑,勿喷)
2、池化层
对每张特征图做压缩,把 2×2(或 3×3)窗口压成 1 个数,长宽减半、深度不变,甩掉冗余信息。在池化层,我们一般选取最大值,在特征图里,数值越大代表这个地方跟卷积核越匹配,也就是特征越强烈,我们就把同一片小区域里最强的那个数保留下来。
也是写一个计算过程。
3、全连接层
前面卷积+池化已经把图像变成了若干张“特征图”,全连接层的工作只有三步:
首先是拉直
把所有特征图按顺序排成一条长向量,不再保留二维形状。
比如呢,2×2 的图拉直后就是 4 个数字的一维列表。
然后加权投票
每个输出神经元都要跟这 4 个数字分别做一次“乘加”:结果 = w₁×x₁ + w₂×x₂ + w₃×x₃ + w₄×x₄ + b
然后激活输出
把投票结果送进激活函数(常用 ReLU 或 Softmax),得到最终概率。如果是分类任务,最后一层 Softmax 会把概率和调成 1,谁最大就判给谁。
二、数据预处理
相信你已经有点理解卷积神经网络的原理了,那么接下来我们开始实战。数据集移步我的资源:https://download.youkuaiyun.com/download/luoying189/92393727
1、导包
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.preprocessing import MinMaxScaler
from sklearn.model_selection import train_test_split
from tensorflow import keras
from tensorflow.keras.layers import Dense,Flatten,Conv2D,MaxPool2D
from tensorflow.python.keras.utils.np_utils import to_categorical
from sklearn.metrics import classification_report
plt.rcParams['font.sans-serif']=['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus']=False # 用来正常显示负号
import warnings
warnings.filterwarnings("ignore")
import pathlib2、导入数据集,给数据类别放到列表当中
data_train = './NEU/train'
data_train = pathlib.Path(data_train)
# 读取验证集的数据
data_test = './NEU/test'
data_test = pathlib.Path(data_test)
# 给数据类别放到列表当中
CLASS_NAMES = np.array(['Cr','In','Pa','ps','Rs','SC'])3、设置片大小和批次数,给整个训练流程定统一规格和一次喂多少张图
# 设置图片大小和批次数
BATCH_SIZE = 64
IMG_HEIGHT = 32
IM_WIDTH = 324、数据归一化处理
卷积核权重初始都是小数(-0.2~0.8 左右),如果输入像素 0~255,数值太大就会梯度爆炸。所以先把像素压到 0~1,与权重同一量级,方便梯度稳定下降。
image_generator = keras.preprocessing.image.ImageDataGenerator(rescale=1.0/255)5、数据生成器
# 训练集生成器
train_data_gen = image_generator.flow_from_directory(directory=
str(data_train),
batch_size=BATCH_SIZE,
shuffle=True,
target_size=(IMG_HEIGHT,IM_WIDTH),
classes=list(CLASS_NAMES))
# 验证集生成器
test_data_gen = image_generator.flow_from_directory(directory=
str(data_test),
batch_size=BATCH_SIZE,
shuffle=True,
target_size=(IMG_HEIGHT,IM_WIDTH),
classes=list(CLASS_NAMES))三、模型搭建
卷积层—池化层—卷积层—池化层—卷积层
第一次 Conv2D(6, 5×5),输出 28×28×6
第一次 MaxPool2D(2×2, strides=2),28×28×6 → 14×14×6
第二次 Conv2D(16, 5×5),10×10×16
第二次 MaxPool2D(2×2, strides=2),10×10×16 → 5×5×16
第三次 Conv2D(120, 5×5),1×1×120
接着拉直变成一维,1×1×120 →120
接着我们搭建全连接层,把 120 个数先压缩成 84 个高层特征,再映射成 6 个是哪类缺陷的概率,完成最终分类。
# 利用keras搭建卷积神经网络
model = keras.Sequential()
# 卷积核的数量filters,卷积的尺寸kernel_size
model.add(Conv2D(filters=6,kernel_size=5,input_shape=(32,32,3),activation='relu'))
# strides步幅
model.add(MaxPool2D(pool_size=(2,2),strides=(2,2)))
model.add(Conv2D(filters=16,kernel_size=5,activation='relu'))
model.add(MaxPool2D(pool_size=(2,2),strides=(2,2)))
model.add(Conv2D(filters=120,kernel_size=5,activation='relu'))
model.add(Flatten())
# 全连接层
model.add(Dense(84,activation='relu'))
model.add(Dense(6,activation='softmax'))最后编译卷积神经网络
# 编译卷积神经网络
# Adam优化器
model.compile(loss='binary_crossentropy',optimizer='Adam',metrics=['accuracy'])四、模型训练并保存
history = model.fit(train_data_gen,validation_data=test_data_gen,epochs=50)
model.save('model.h5')五、可视化
我们可视化一下模型的损失值和精确度,由图可以看出来到最后,模型的准确度保持在0.9左右,还是蛮不错的。
plt.plot(history.history['loss'],label='train')
plt.plot(history.history['val_loss'],label='val')
plt.title('CNN神经网络loss图')
plt.legend()
plt.show()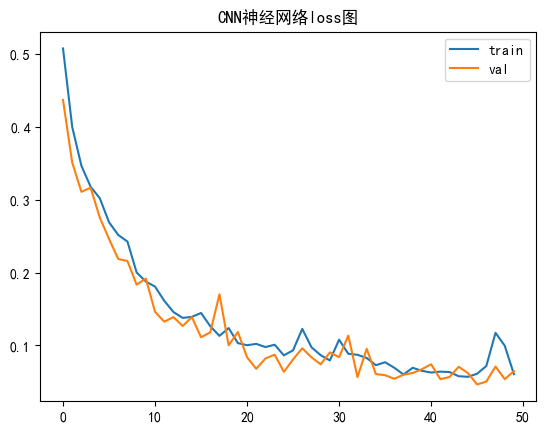
plt.plot(history.history['accuracy'],label='train')
plt.plot(history.history['val_accuracy'],label='val')
plt.title('CNN神经网络accuracy图')
plt.legend()
plt.show()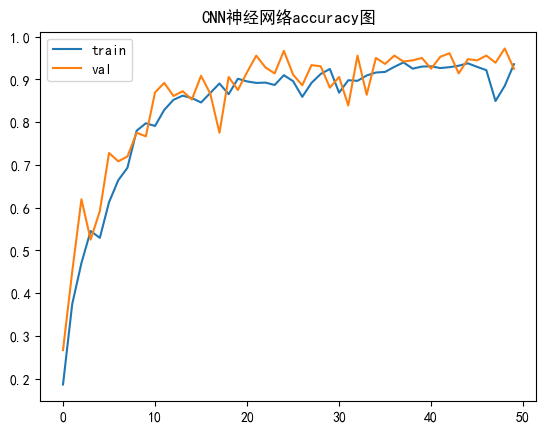
六、模型验证
新建一个test.ipynb用于模型的验证
1、导包
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.preprocessing import MinMaxScaler
from sklearn.model_selection import train_test_split
from tensorflow import keras
import tensorflow as tf
from tensorflow.keras.layers import Dense,Flatten,Conv2D,MaxPool2D
from tensorflow.python.keras.utils.np_utils import to_categorical
from sklearn.metrics import classification_report
plt.rcParams['font.sans-serif']=['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus']=False # 用来正常显示负号
import warnings
warnings.filterwarnings("ignore")
import pathlib
import cv2
from keras.models import load_model2、预处理
# 给数据类别放到列表当中
CLASS_NAMES = np.array(['Cr','In','Pa','ps','Rs','SC'])
IMG_HEIGHT = 32
IM_WIDTH = 323、加载模型
我们选取测试集(test)的任意一张图片进行测试,看看出来的结果是不是正确的,路径你们自己改好。
# 加载模型
model = load_model('model.h5')
src = cv2.imread('./NEU/test/Rs/rolled-in_scale_14.jpg')
src = cv2.resize(src,(32,32))
src = src.astype('int32')
src = src/255
# 扩充数据的维度
test_img = tf.expand_dims(src,0)
print(test_img.shape)4、模型测试
preds = model.predict(test_img)
print(preds)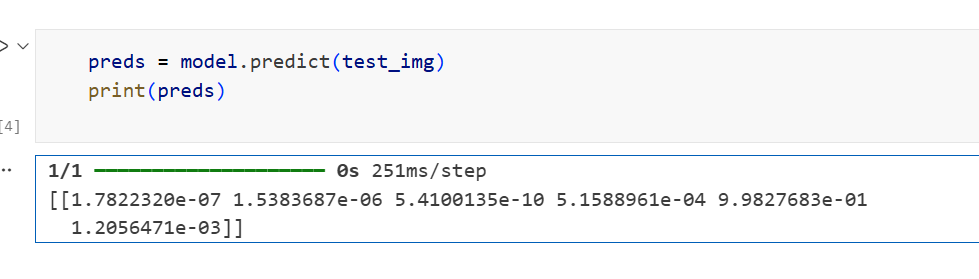
我们可以打印6个分类的概率分数,更加直观地看到
score = preds[0]
score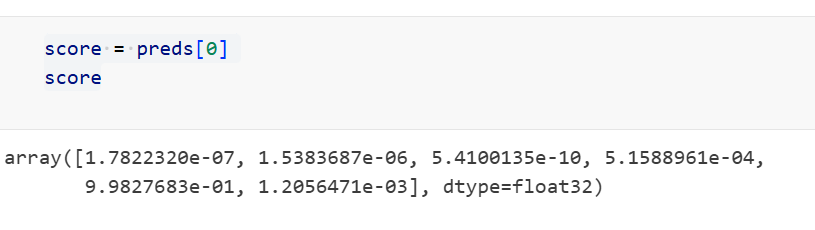
概率越大,就越证明该钢材是属于这个分类。所以我们输出概率最大的分类名称。回到测试集选取的图片是Rs/rolled-in_scale_14.jpg,和预测结果是不是一样的呢,这就表明预测成功啦,该钢材缺陷标签为Rs的概率大约是0.998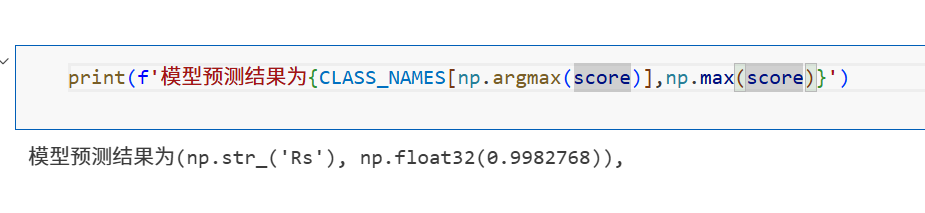
那么整个实战到这里就结束了,相信你一定有所体会啦
结束,完结撒花

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









