






一、Flume安装
我们使用ssh连接工具Termora进行连接,连接成功后,切换到home目录创建一个hadoop的文件夹。mkdir hadoop
 打开SFTP。注意,Termora的连接这一步在我的上一篇文章有详细教程,这里不多赘述,不会的小伙伴可以前往我的上一篇文章学一下~当然啦,有的人用Xshell或者FinalShell连接也是可以的,这个看个人喜好。
打开SFTP。注意,Termora的连接这一步在我的上一篇文章有详细教程,这里不多赘述,不会的小伙伴可以前往我的上一篇文章学一下~当然啦,有的人用Xshell或者FinalShell连接也是可以的,这个看个人喜好。
Termora连接教程博客:
https://blog.youkuaiyun.com/luoying189/article/details/153841667
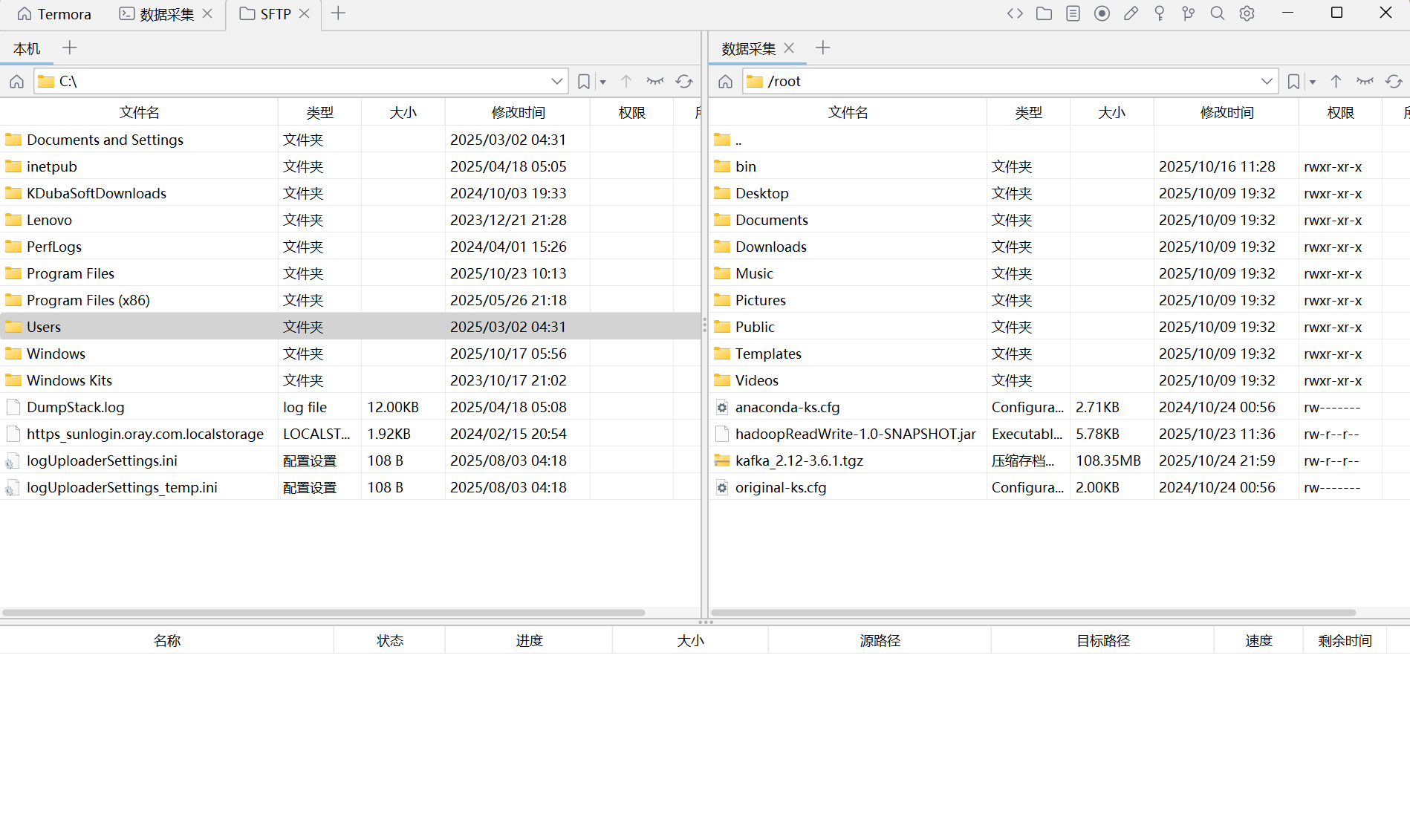
将右边的/root切换到/home/hadoop目录下,然后把flume的压缩包拉到右边来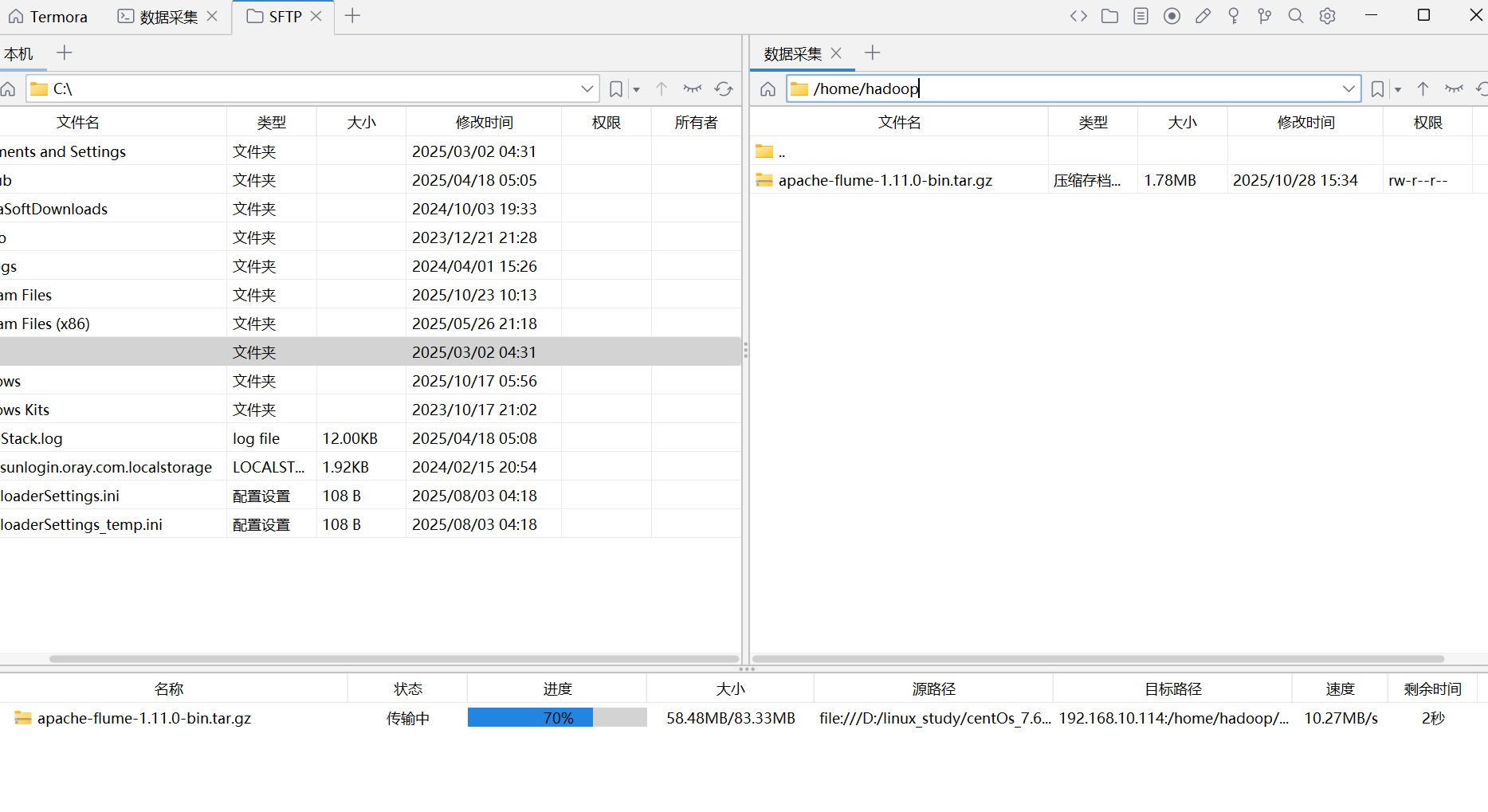
回到第一台连接(数据采集)确定目录下有flume的压缩包
解压 tar -zxvf apache-flume-1.11.0-bin.tar.gz 
cd 进去flume
cd apache-flume-1.11.0-bin/
接着输入命令,出现版本号则证明安装成功
./bin/flume-ng version

如果有小伙伴在这里安装失败,可能是jdk没有配好。
需要配置jdk,建议选择jdk1.8适配,自行到官网下载。文件上传解压跟flume的步骤差不多。不同的是要加入环境变量
输入命令 nano ~/.bashrc
到最下面去添加环境变量,注意jdk解压后重命名一下哈(mv 你的jdk jdk),注意JAVA_HOME的jdk路径和你自己的路径一致哦
export JAVA_HOME=/usr/local/jdk
export PATH=${JAVA_HOME}/bin:$PATH
保存退出,再输入命令生效source ~/.bashrc
最后 javac验证一下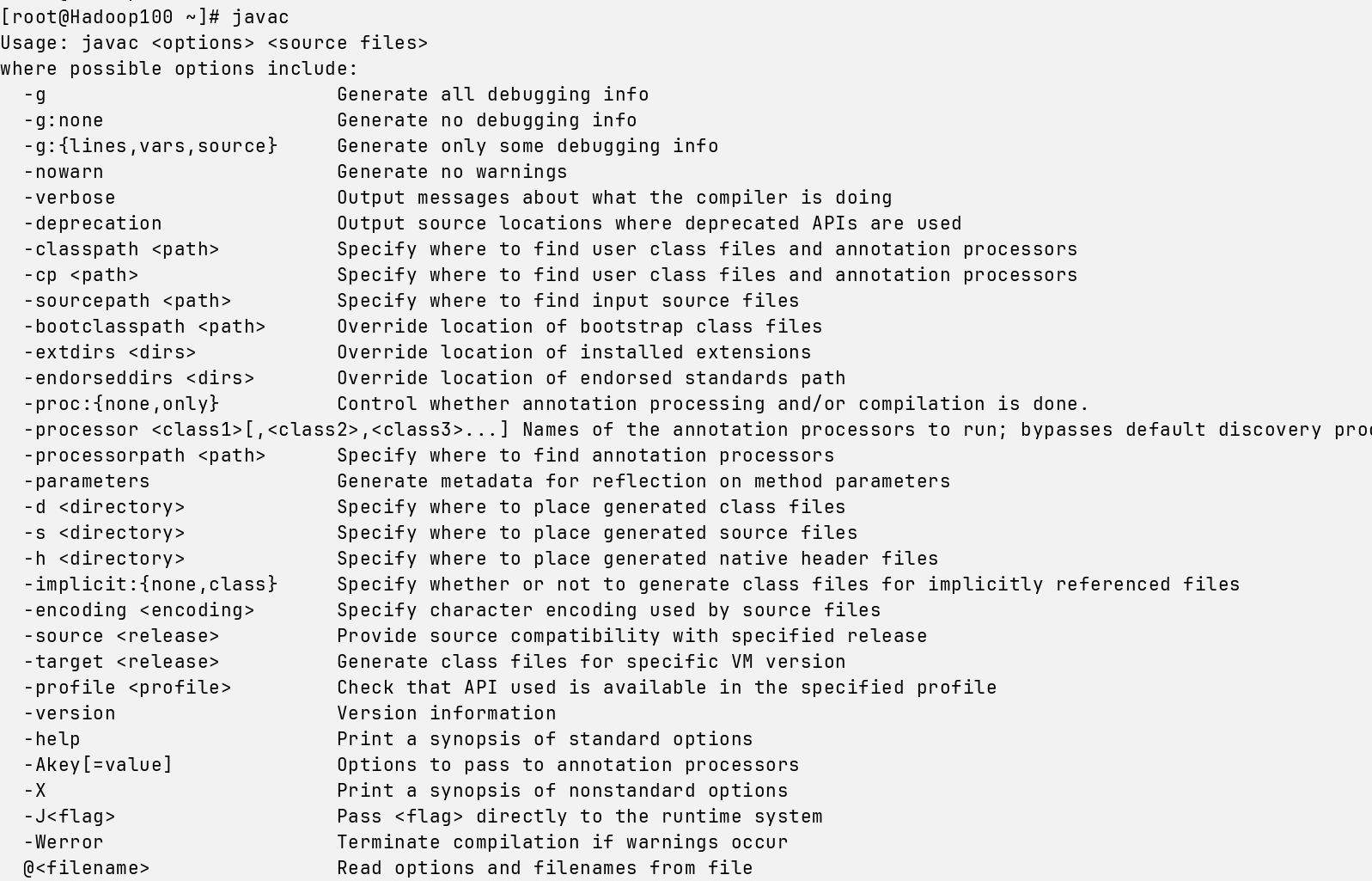
再次输入命令./bin/flume-ng version
出现版本号就好啦,然后
cd /home/hadoop/apache-flume-1.11.0-bin/conf/
nano log4j2.xml

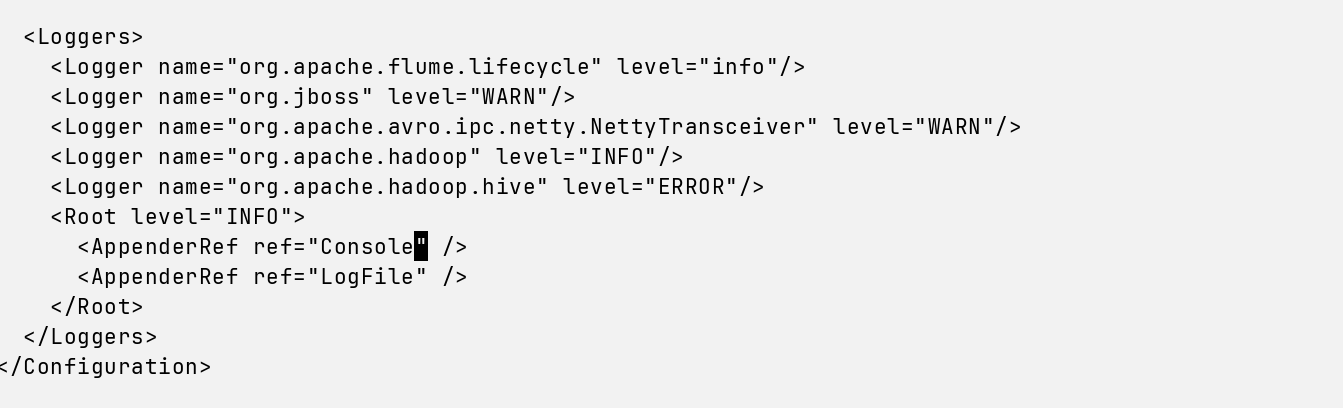
增加一行
<AppenderRef ref="Console" />
二、Flume的使用(学习)
这一步仅仅练习测试~~知道flume怎么用的,如果熟悉的小伙伴可以跳过,进入下一标题。
我们在flume目录cd进入conf,再在其conf目录下新建一个文件
touch example.conf
输入命令编辑文件
nano example.conf
将下面这段粉色的复制到example.conf文件里面,然后ctrl+x,输入y,再enter一下保存
#设置Agent上的各组件名称
a1.sources = r1
a1.sinks = k1
a1.channels = c1
#配置Source
a1.sources.r1.type = netcat
a1.sources.r1.bind = localhost
a1.sources.r1.port = 44444
#配置Sink
a1.sinks.k1.type = logger
#配置Channel
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
#把Source和Sink绑定到Channel上
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
接着cd.. (注意有两个点)回到flume目录,输入命令:
./bin/flume-ng agent --conf ./conf --conf-file ./conf/example.conf --name a1 -Dflume.root.logger = INFO,console
我们再开一个连接终端,点击克隆
在第二台终端连接,输入命令:nc localhost 44444
写点东西上去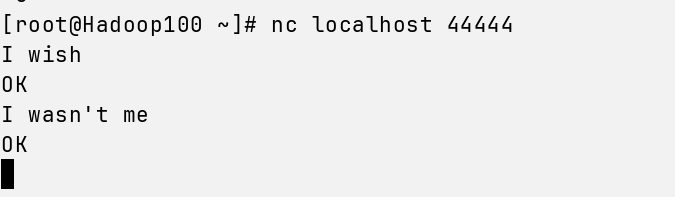
回到第一台终端连接,下面出现了你写的东西,成功~
到了这里,相信你已经成功掌握如何使用flume了~让我们继续
三、kafka安装、配置和启动
kafka官网下载:kafka.apache.org/downloads
点击右上角的文件图标(SFTP)
这里在右边的/root,修改为/home切换到home路径
找到你的kafka压缩包的位置,拖到右边上传
上传完就是这样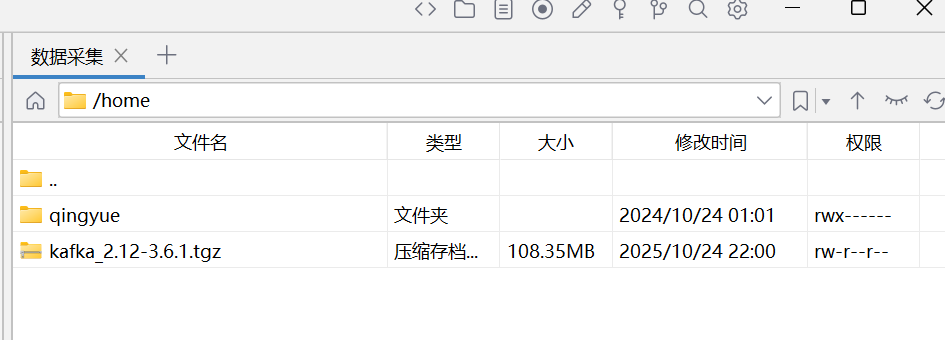 回到连接这里,cd到home目录,ls查看一下压缩包是不是存在
回到连接这里,cd到home目录,ls查看一下压缩包是不是存在
解压kafka, tar -zxvf kafka_2.12-3.6.1.tgz -C /usr/local/
解压完后cd到/usr/local/查看,重命名一下,mv kafka_2.12-3.6.1/ kafka
然后ls查看一下
cd 进入kafka
cd kafka
拷贝一份配置文件
cp config/kraft/server.properties config/kraft/server-local.properties
然后 查看一下,出现这四个就可以了
ls config/kraft/

接着,我们编辑local配置文件
nano config/kraft/server-local.properties
确保你的配置文件这几个部分和我的一致~

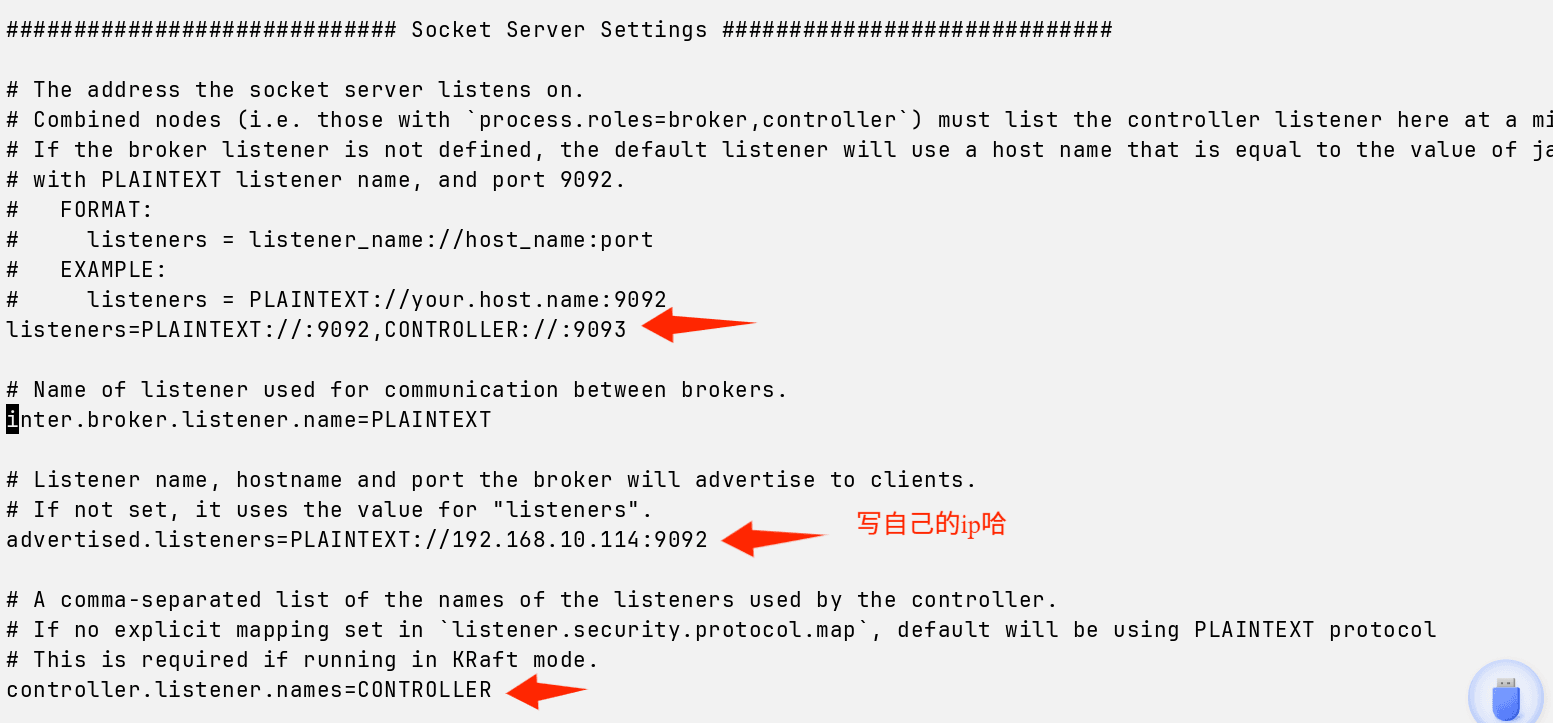
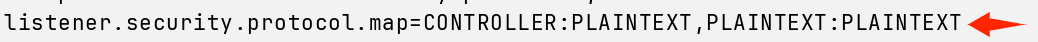

接着,在kafka的根目录生成UUID,echo查看一下
CLUSTER_ID=$(bin/kafka-storage.sh random-uuid)
echo $CLUSTER_ID

用id格式化一下
bin/kafka-storage.sh format -t $CLUSTER_ID -c config/kraft/server-local.properties

最后,启动kafka,验证kafka启动成功,可以监听9092 9093端口(这是kafka的端口号)
bin/kafka-server-start.sh -daemon config/kraft/server-local.properties
ss -lntp | grep 909
四、配置Flume
接下来,我们cd回去flume目录下的conf目录,创建一个flume的配置文件
cd /home/hadoop/apache-flume-1.11.0-bin/conf
touch kafka_flume.conf

编辑配置文件
nano kafka_flume.conf
将下面粉色部分写入配置文件
# flume.conf —— Kafka(普通字符串/JSON文本) -> 本地滚动文件
agent.sources = kafka-source
agent.channels = memory-channel
agent.sinks = file-sink
# ---- Source: Kafka ----
agent.sources.kafka-source.type = org.apache.flume.source.kafka.KafkaSource
agent.sources.kafka-source.kafka.bootstrap.servers = localhost:9092
# 二选一:用具体topic,或用正则
agent.sources.kafka-source.kafka.topics = your-kafka-topic
# agent.sources.kafka-source.kafka.topics.regex = ^log-.*
# 消费组与位点策略(新组想从头读就 earliest;已有位点不会回溯)
agent.sources.kafka-source.kafka.consumer.group.id = your-consumer-group
agent.sources.kafka-source.kafka.consumer.auto.offset.reset = earliest
agent.sources.kafka-source.batch.size = 100
agent.sources.kafka-source.batch.timeout = 1000
# 如果你的 Kafka 消息不是“Flume JSON 事件格式”,就不要配置 JSONEventDeserializer
#(否则会解析失败)
# agent.sources.kafka-source.deserializer = org.apache.flume.source.kafka.JSONEventDeserializer
# ---- Channel ----
agent.channels.memory-channel.type = memory
agent.channels.memory-channel.capacity = 10000
agent.channels.memory-channel.transactionCapacity = 1000
# ---- Sink: 本地滚动文件(注意是 file_roll 不是 file)
agent.sinks.file-sink.type = file_roll
agent.sinks.file-sink.sink.directory = /tmp/flume-kafka-output
agent.sinks.file-sink.sink.rollInterval = 60
# ---- 绑定 ----
agent.sources.kafka-source.channels = memory-channel
agent.sinks.file-sink.channel = memory-channel
保存好配置文件,接下来我们回到根目录
cd ~
创建文件夹
mkdir -p /tmp/flume-kafka-output
然后进入flume目录,输入命令启动
cd /home/hadoop/apache-flume-1.11.0-bin/
./bin/flume-ng agent --conf ./conf --conf-file ./conf/kafka_flume.conf --name agent -Dflume.root.logger=INFO,console
五、发送消息到kafka-flume
我们到vscode里面,写一个python程序(pycharm也可以的,这个随意)
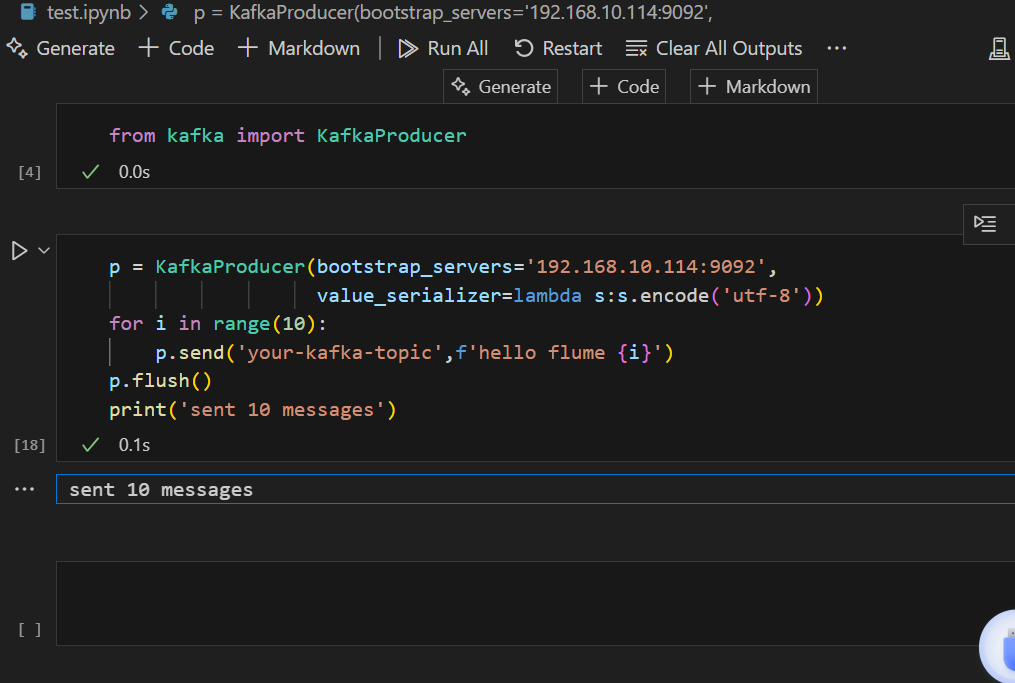
可能遇到的bug:发送不成功
随便克隆一台连接,输入命令查看防火墙状态
systemctl status firewalld.service
如果看到running,把防火墙关闭
systemctl stop firewalld.service
再次运行代码,发送成功后,我们在随意克隆的连接上,输入命令
cd /tmp/flume-kafka-output
ls
有东西的话,我们打开第一个看一下,注意每个人的文件都是不一样的,别跟着我写
cat 1761666060991-1
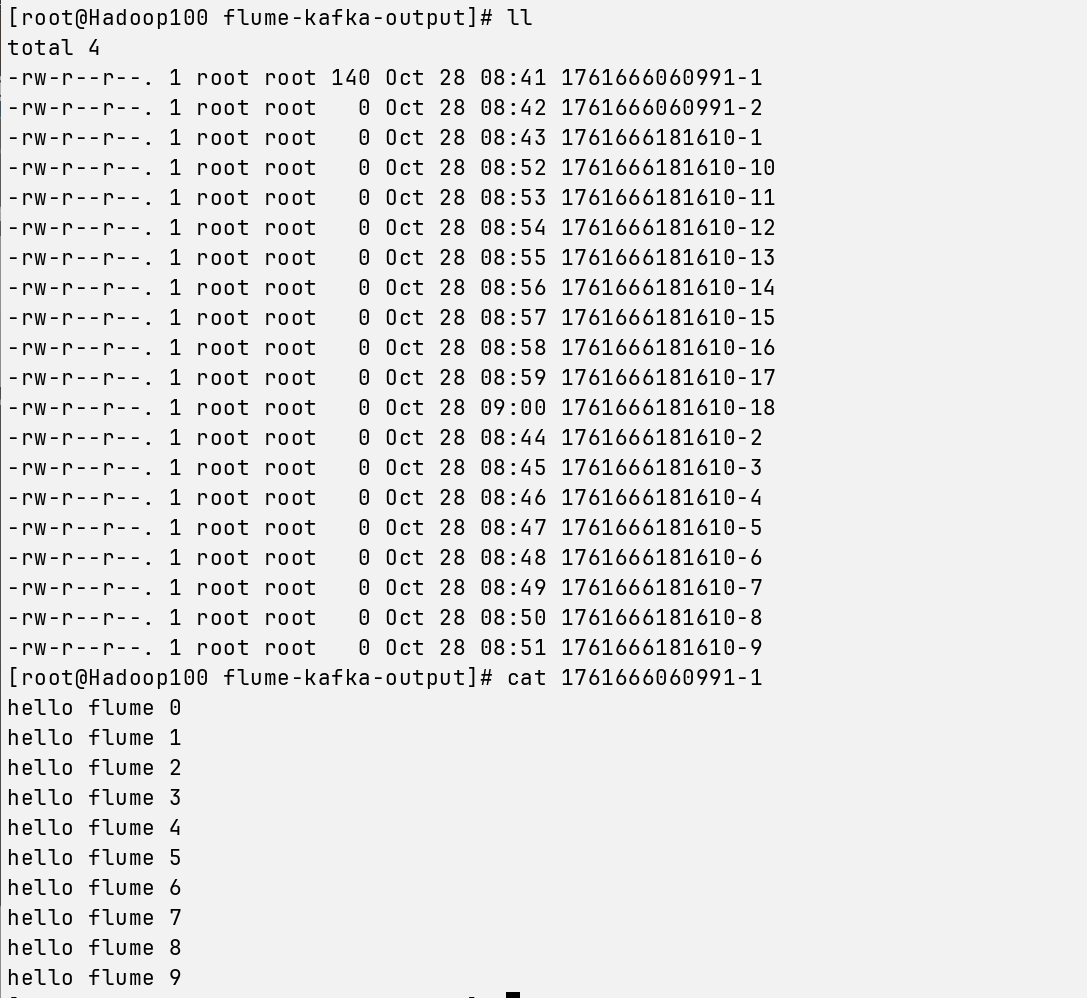
当出现这些写进去的东西,我们就成功啦~~
完成这一步,我们就实现了通过VScode写python代码发送消息到kafka-flume
结束,完结撒花~

















 1366
1366

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









