




最近学校的hadoop课程在学习idea环境下编写读写HDFS文件代码,但是现在网上大部分教程的idea版本都比较老,大部分对不上,所以这里写一个教程,也供自己熟悉理解。废话不多说,我们开始~
一、启动集群
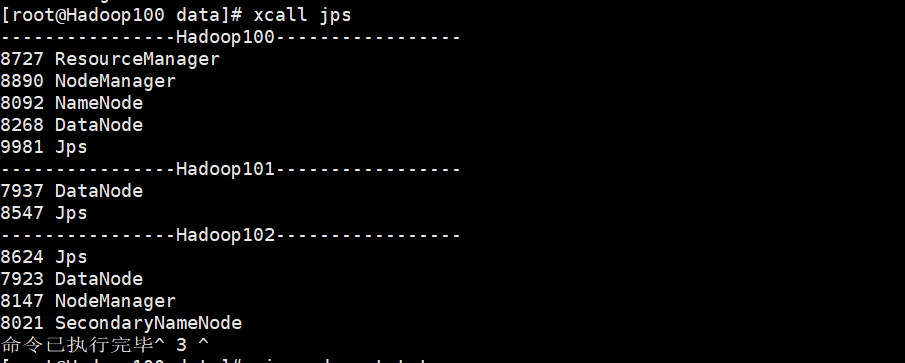
首先,确保你的集群启动成功,这里xcall jps,三台机子上面的东西缺一不可。
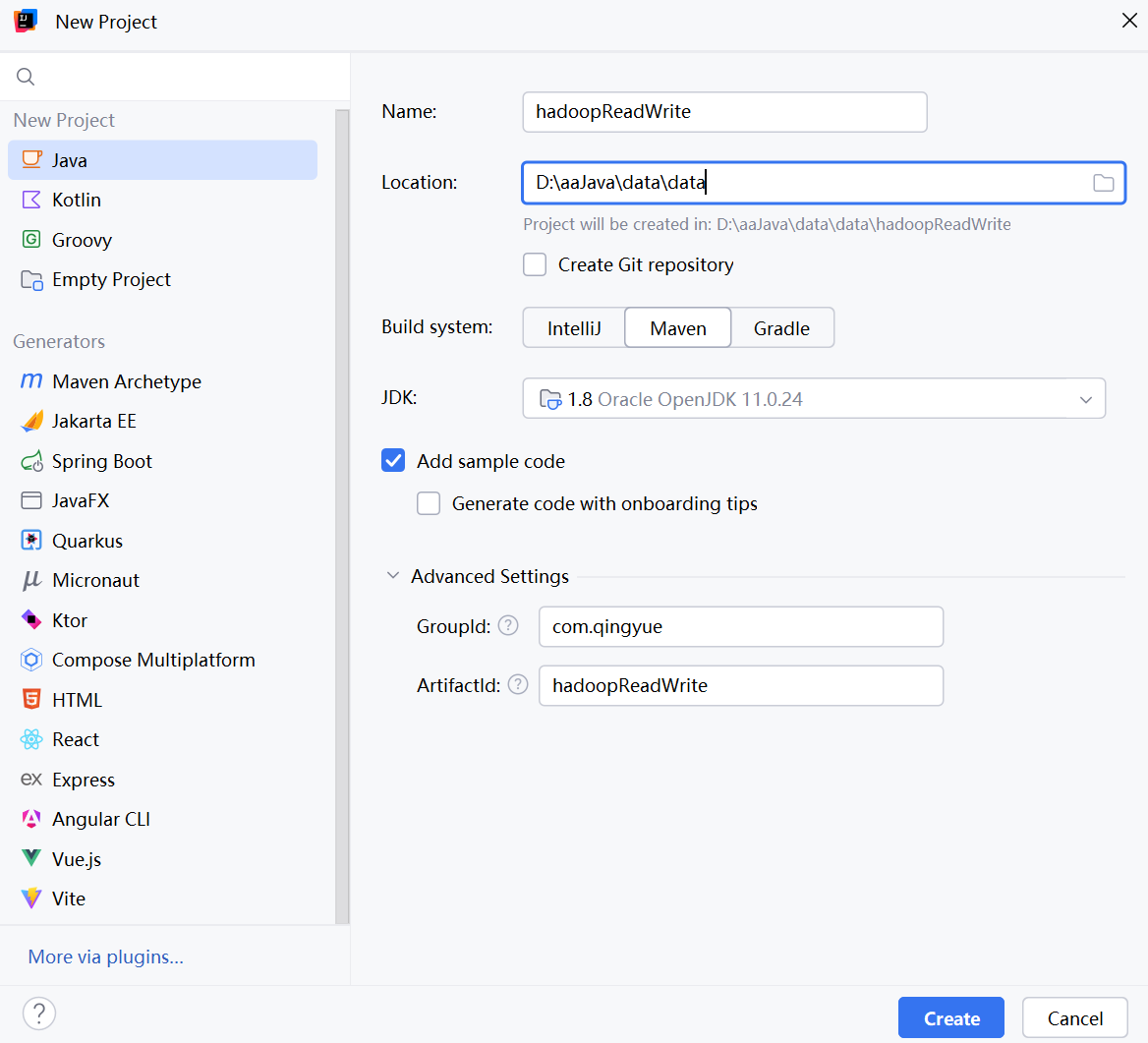
二、创建Maven工程
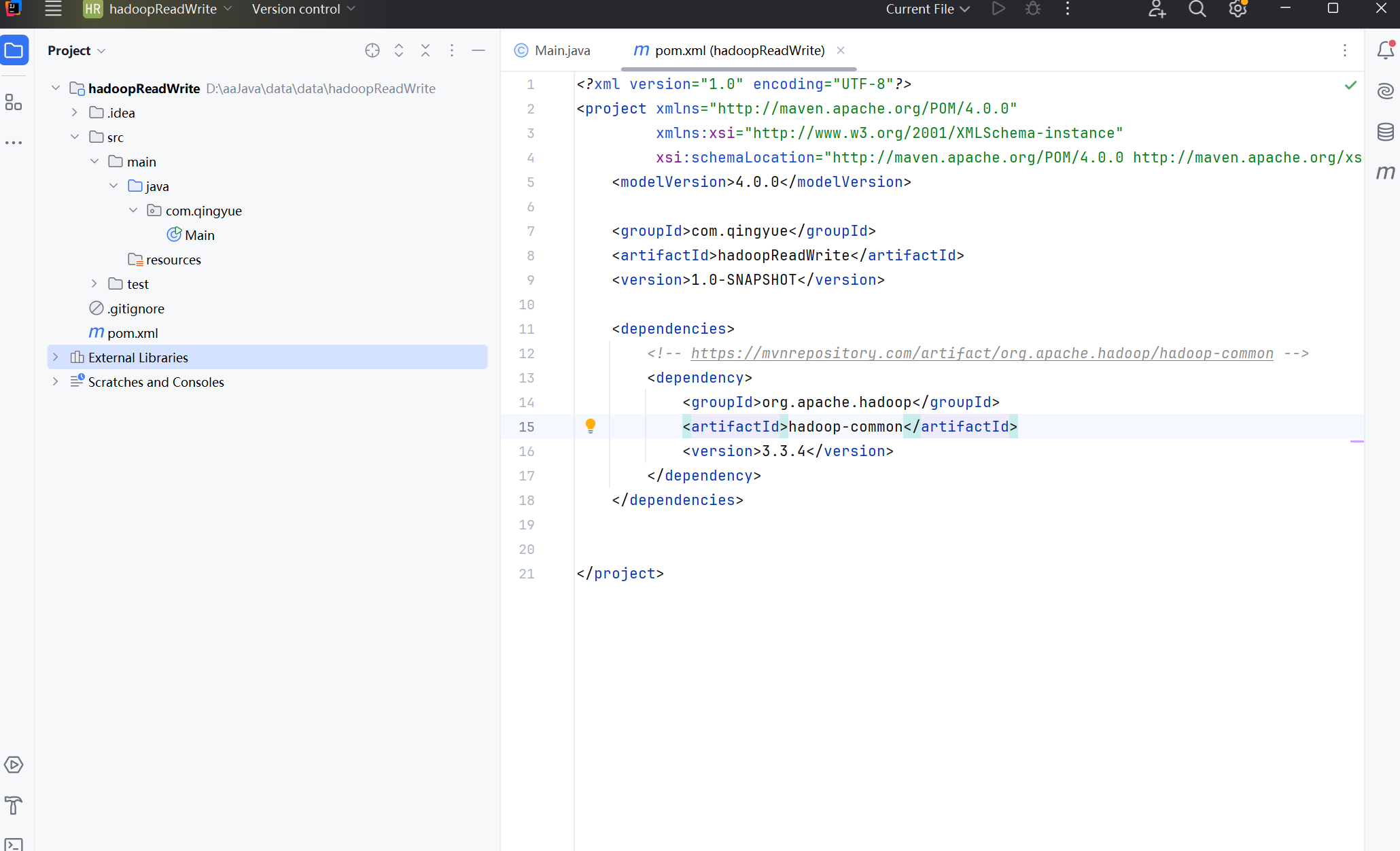
三、修改pro.xml文件
在pro.xml文件中,将下面这段部分粘贴上去,多余部分删除。
<!-- https://mvnrepository.com/artifact/org.apache.hadoop/hadoop-common -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>3.3.4</version>
</dependency>
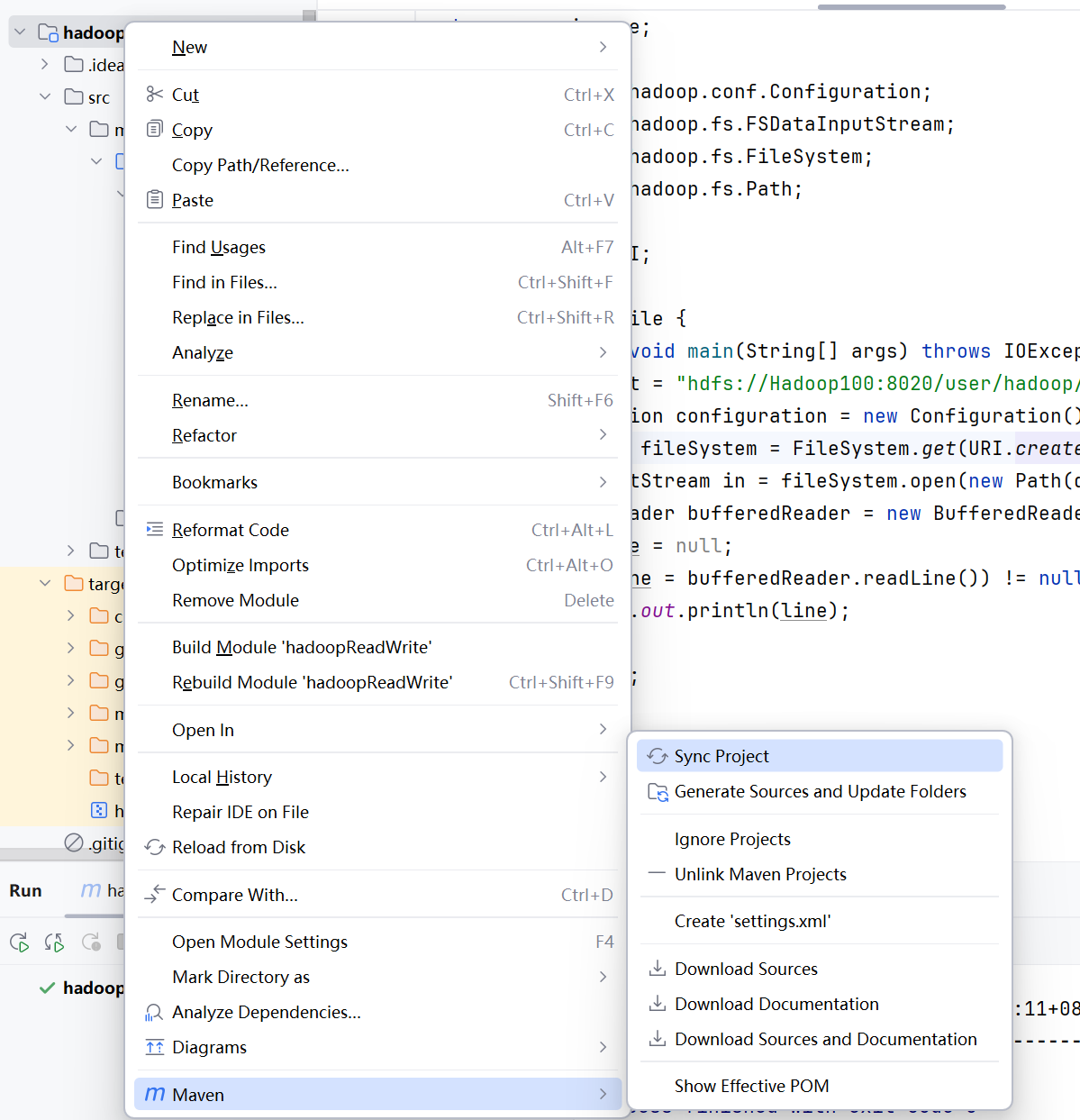
然后右击你的项目,最下面有一个maven,悬浮后点击Sync Project,稍等片刻,,如果你的pro.xml不会爆红,证明ok了。
四、写Java文件
在java目录下面点击新建一个类,输入com.qingyue.WriteFile,把下面代码部分粘贴进去。注意,如果你的主机不叫Hadoop100,不要跟着我写,把String dest = "hdfs://Hadoop100:8020/user/hadoop/text1.txt";
其中的Hadoop100修改为你的主机
package com.qingyue;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataOutputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import java.io.IOException;
import java.net.URI;
public class WriteFile {
public static void main(String[] args) throws IOException {
String content = "Hello,xunfang!\n";
String dest = "hdfs://Hadoop100:8020/user/hadoop/text1.txt";
Configuration configuration = new Configuration();
FileSystem fileSystem = FileSystem.get(URI.create(dest), configuration);
FSDataOutputStream out = fileSystem.create(new Path(dest));
out.write(content.getBytes("UTF-8"));
out.close();
}
}
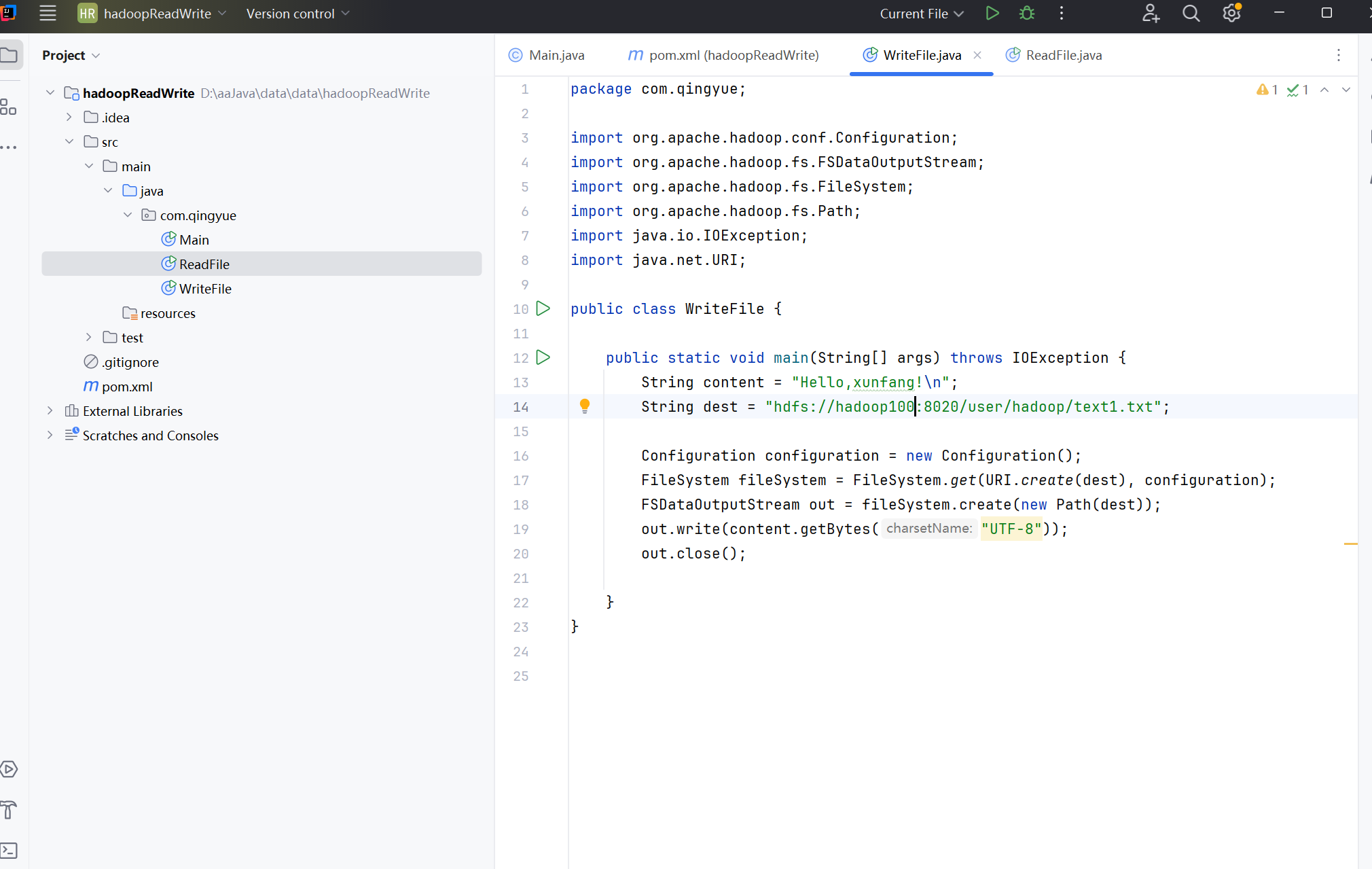
再点击新建一个类,输入com.qingyue.ReadFile
package com.qingyue;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import java.io.*;
import java.net.URI;
public class ReadFile {
public static void main(String[] args) throws IOException {
String dest = "hdfs://Hadoop100:8020/user/hadoop/text1.txt";
Configuration configuration = new Configuration();
FileSystem fileSystem = FileSystem.get(URI.create(dest), configuration);
FSDataInputStream in = fileSystem.open(new Path(dest));
BufferedReader bufferedReader = new BufferedReader(new InputStreamReader(in));
String line = null;
while ((line = bufferedReader.readLine()) != null) {
System.out.println(line);
}
in.close();
}
}
把上面代码部分粘贴进去。注意,如果你的主机不叫Hadoop100,不要跟着我写,把String dest = "hdfs://Hadoop100:8020/user/hadoop/text1.txt";
其中的Hadoop100修改为你的主机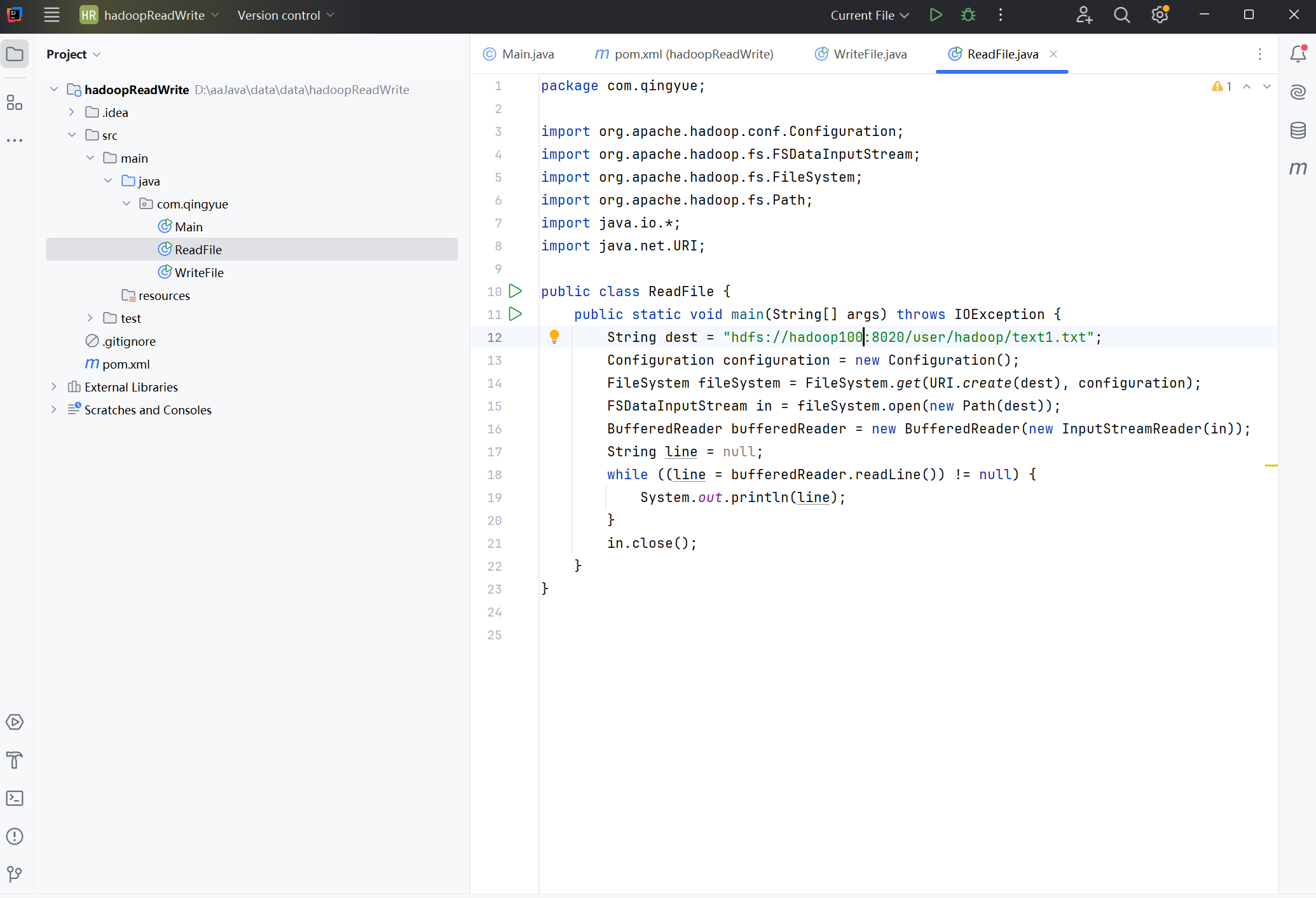
保证你的目录没有target这个文件夹,如果有,删除。
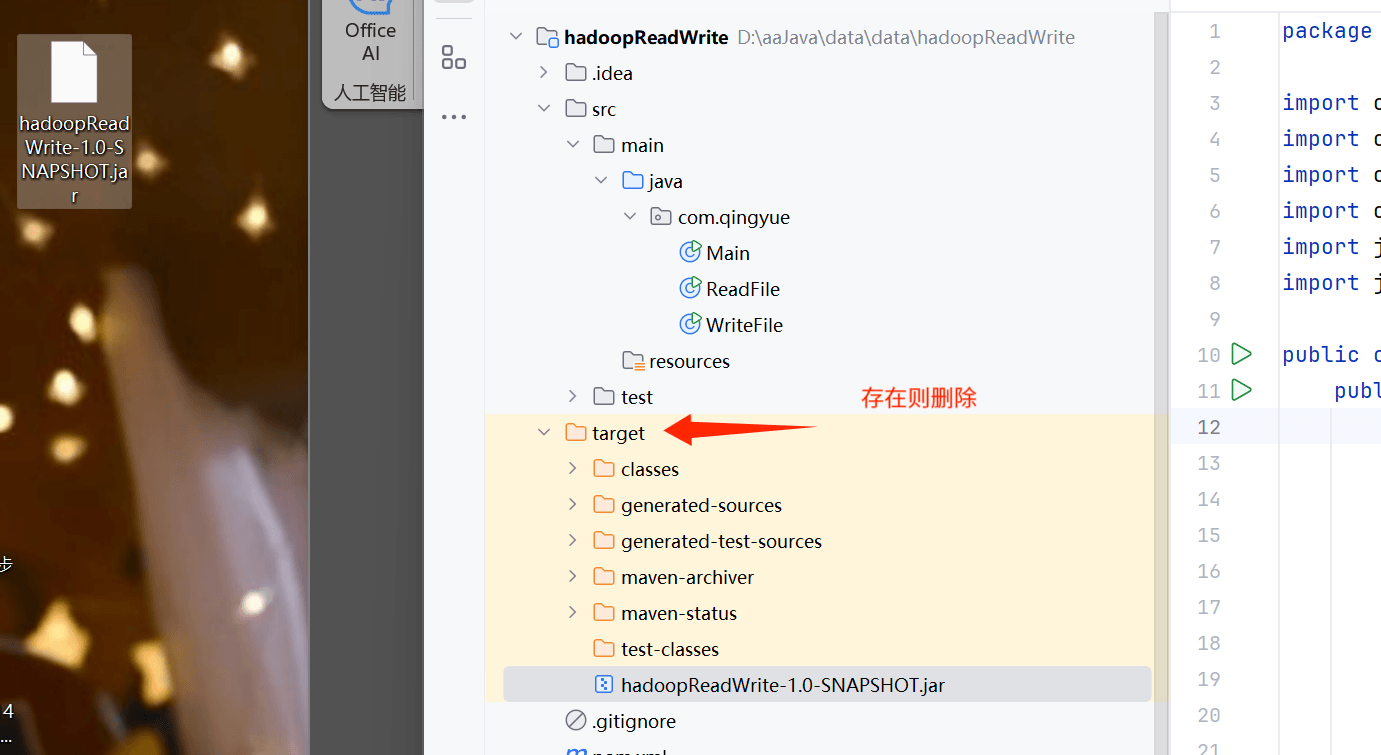
你的右边有一个m的标识,我们点击一下。
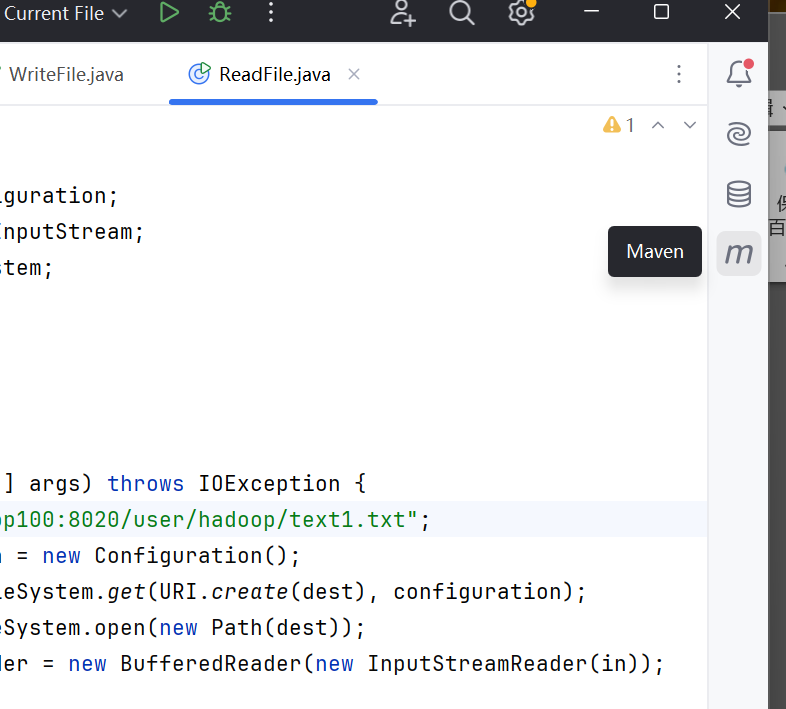
打开Liftcycle,然后点击package
打包成功后,在后台会看到BUILD SUCCESS的提示,在目录会出现一个target文件夹。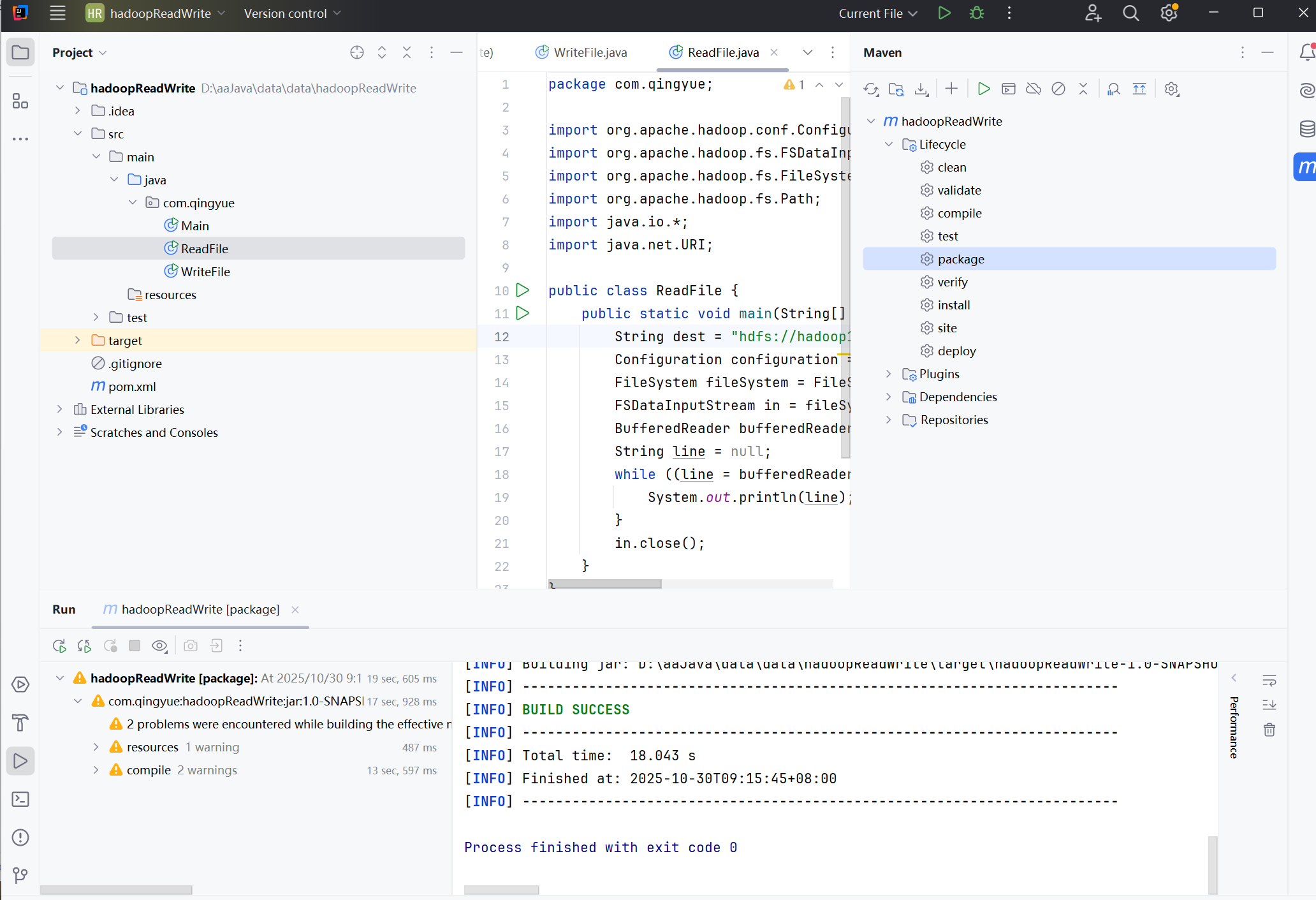
点开target文件夹,最下面有一个jar文件,我们复制到桌面上(方便找,你也可以复制到其它地方)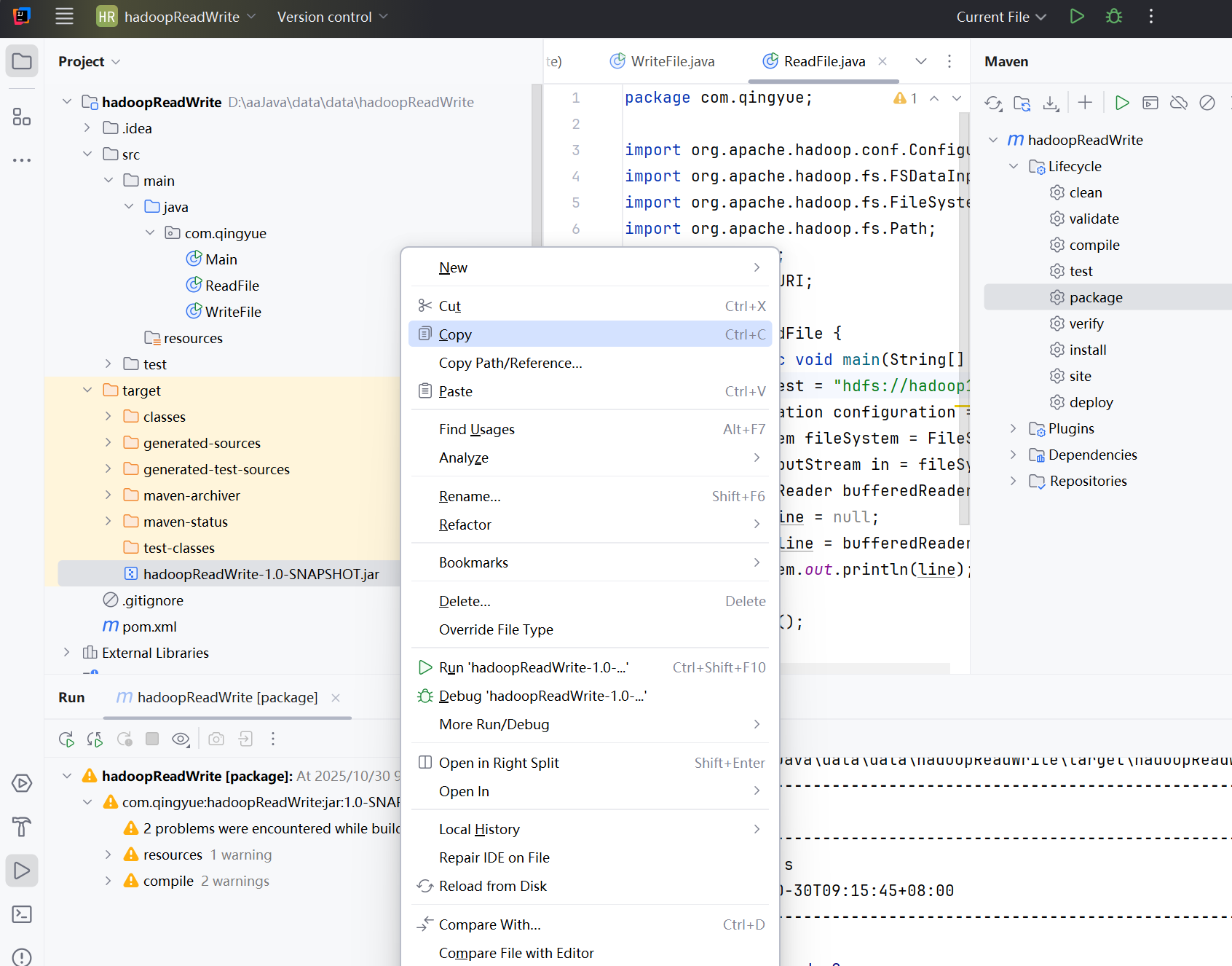 粘贴到桌面,桌面出现jar文件,粘贴成功
粘贴到桌面,桌面出现jar文件,粘贴成功
五、通过Java文件读写HDFS
打开我们的Xshell连接,如果你第一步忽略了没有启动集群的话,这里一定要做
输入命令
start-all.sh
启动
确保下面每台虚拟机上面的东西缺一不可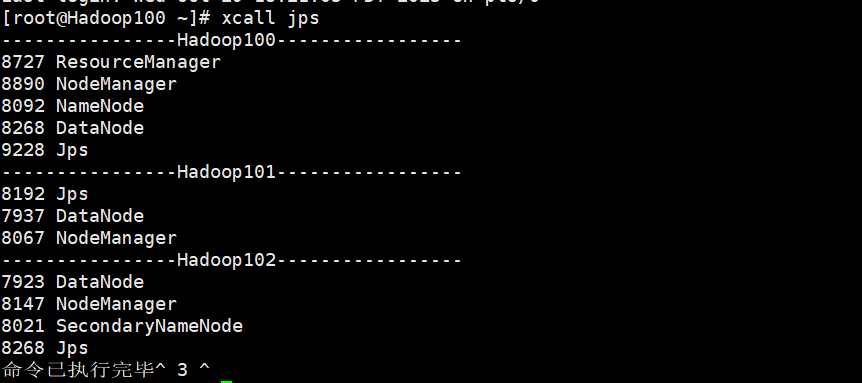
切换目录到 cd /usr/local/hadoop/data
如果没有这个目录,自己创建一下
输入rz上传刚刚的jar文件
可能遇到的bug:rz传输失败
rz上传失败,那就不输入rz命令,直接把你的jar文件拖进去Xshell
输入命令
hadoop jar hadoopReadWrite-1.0-SNAPSHOT.jar com.qingyue.WriteFile
然后查看一下这个文件
hadoop fs -cat /user/hadoop/text1.txt

如果出现你在java写进去的东西,成功~
可以看看ReadFile,出现则成功
hadoop jar hadoopReadWrite-1.0-SNAPSHOT.jar com.qingyue.ReadFile

那么到这里,相信你已经学会怎么通过编写java代码读写HDFS文件了~
可能遇到的bug:找不到这个类
我们可以ls 查看一下当前目录的东西,如果存在多个同名的jar,全部删干净
rm -rf 你的jar包

重新rz传输一下,再次ls一下,确保只有这一个名字的jar文件,text2.txt是我之前做的测试东西,如果你没有别慌,没关系。
再次输入命令
hadoop jar hadoopReadWrite-1.0-SNAPSHOT.jar com.qingyue.WriteFile
然后查看一下这个文件
hadoop fs -cat /user/hadoop/text1.txt

结束,完结撒花~

















 8077
8077

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









