 AdaSpeech3:自适应语音合成应对即兴风格挑战
AdaSpeech3:自适应语音合成应对即兴风格挑战





声明:语音合成论文优选系列主要分享论文,分享论文不做直接翻译,所写的内容主要对文章简略概括。如有转载,请标注来源。
欢迎关注微信公众号:低调奋进
AdaSpeech 3: Adaptive Text to Speech for Spontaneous Style
本文为Microsoft Research Asia, China在2021.07.06更新的文章,主要做spontanous-style的adaptive tts,具体的文章链接 https://arxiv.org/pdf/2107.02530.pdf
以前对谭旭的AdaSpeech和AdaSpeech2介绍过,可参考
AdaSpeech 主做个性化工作
https://mp.weixin.qq.com/s?__biz=MzAxNjY3NjQwOQ==&mid=2247484779&idx=1&sn=8bcf8bb31ff77652e39ee64d16fb50ec&chksm=9bf0663dac87ef2b79ceafbf8829f1e2ca1e7e7e7cc1d97c5b8812486069abf815f78e107642&token=1286519892&lang=zh_CN#rd
AdaSpeech 2 在AdaSpeech基础上只使用audio来做个性化工作
https://mp.weixin.qq.com/s?__biz=MzAxNjY3NjQwOQ==&mid=2247485115&idx=1&sn=a16dd1064018efe7683081166c85c0e0&chksm=9bf065edac87ecfb604e40bd3183c5927c24eabcd82a98e55655041ebd6b20fa9ac142b3d312&token=818681779&lang=zh_CN#rd
另外谭旭更新了一篇survey,我本打算写这篇survey,但我不想按文章翻译,所以就没写,大家可以阅读原文
https://arxiv.org/pdf/2106.15561.pdf
1 背景
spontanous-style 语音其主要特点 1)存在大量um,uh等filled pauses(FP) 2)更多样的韵律(语速语调)。虽然tts在阅读风格语音合成效果很好,但对spontanous-style (podcast or conversation)研究很少。另外spontanous-style的数据相比阅读数据可训练的数据较少,因此本文提出adaspeech3 。adaspeech3使用较少的spontanous-style 数据在阅读风格tts上进行自适用,从而合成较高质量的spontanous-style 语音。
2 详细设计
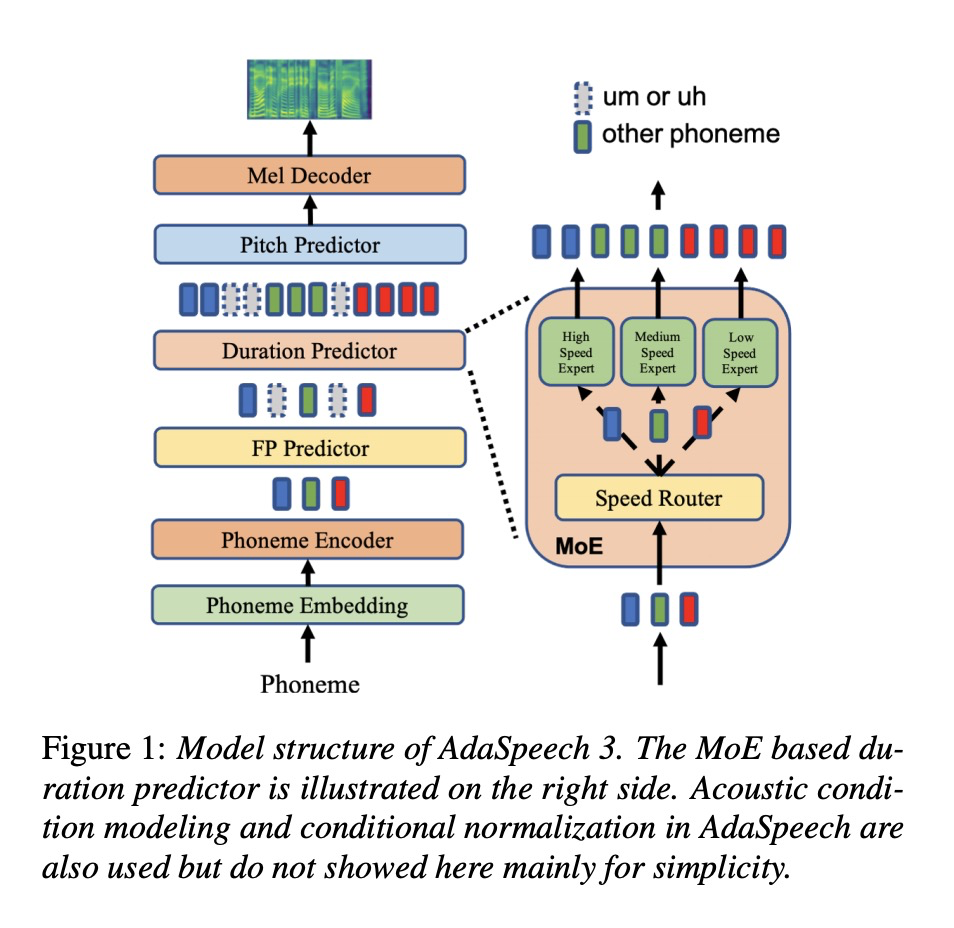
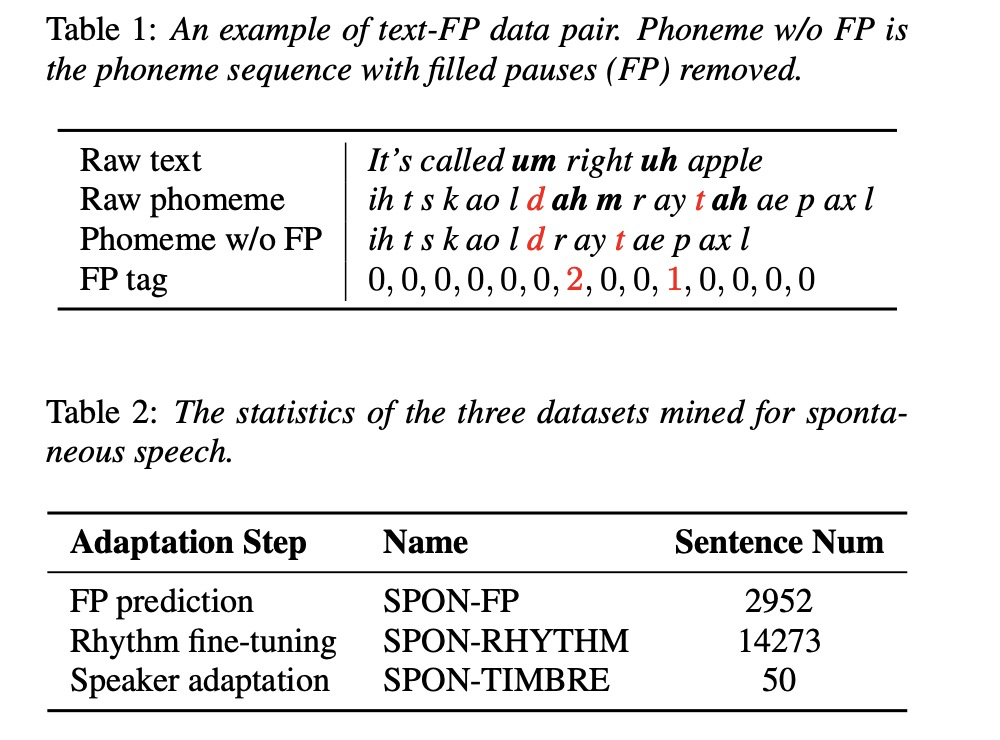
根据spontanous-style 语音的特点,本文在AdaSpeech上添加FP predictor模块,并修改了duration predictor结构为MoE(mixed of expert),具体如图1所示。为了做spontanous-style 自适应,需要三类数据:SPON-FP, SPON_PHYTHM和SPON-TIMBER。SPON-FP数据的格式为<text, FP>, 本文主要分为三类,0代表没有FP, 1代表uh,2代表um,具体格式为table 1所示,该数据主要用于FP Predictor的训练。SPON_PHYTHM包括pitch,duration和phoneme,该部分主要对duration predictor和pitch predictor进行更新。SPON-TIMBE主要为phoneme和对应的speech,进行音色的更新。这三类数据的数量如table 2所示。
3 实验
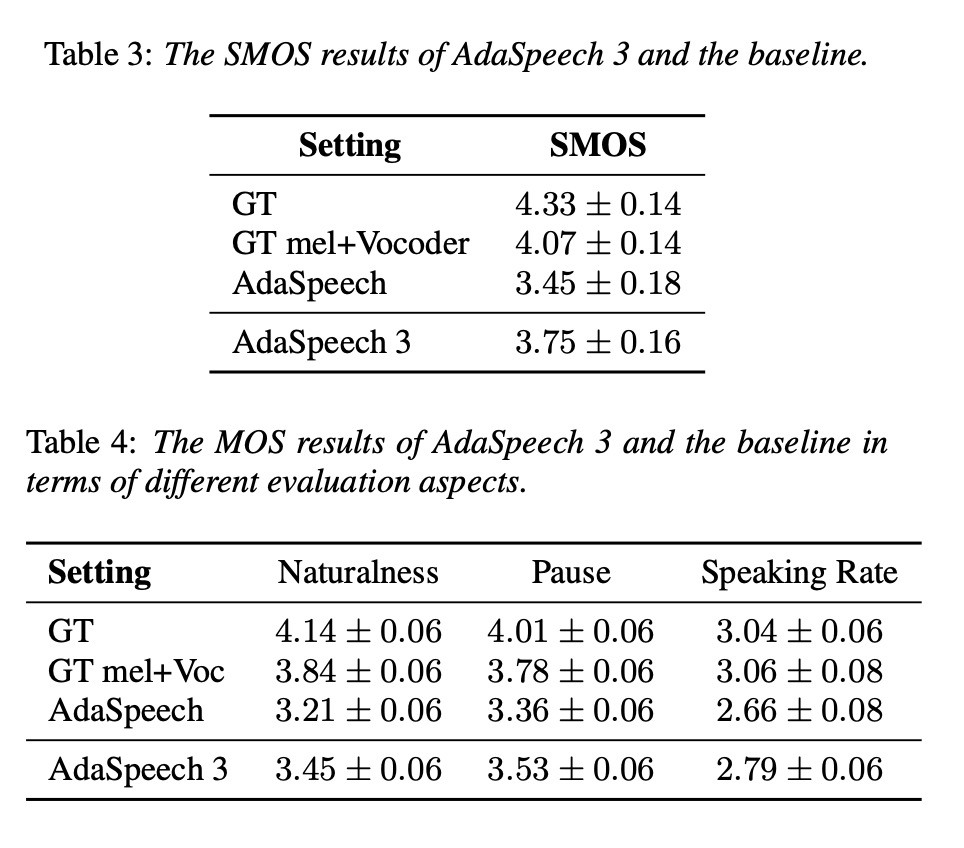
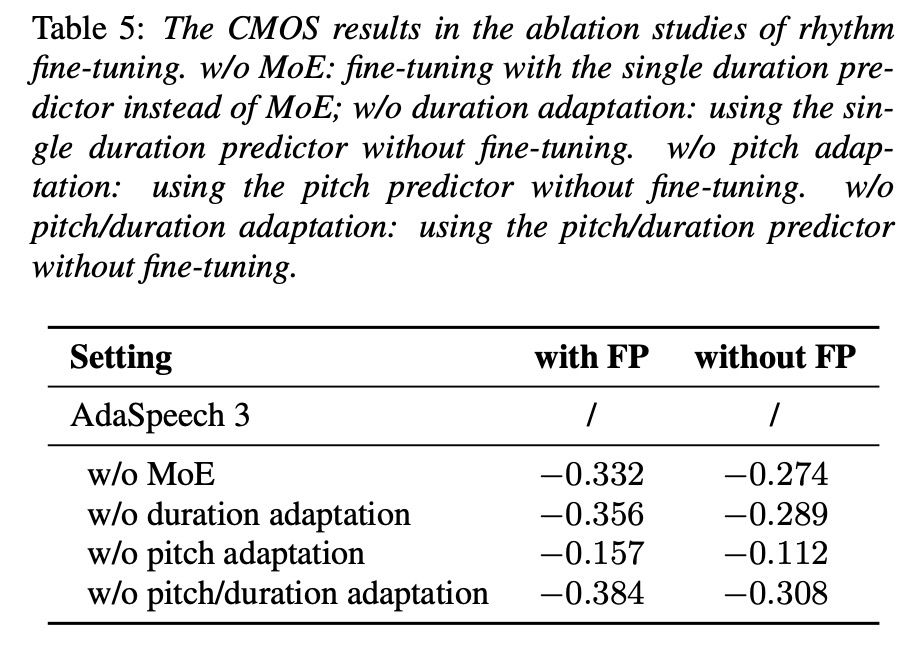
首先对比一下SMOS,table 3展示本文AdaSpeech 3合成的spontanous-style语音更好,table 4展示本文在各方面的MOS都比AdaSpeech好。table 5验证每个模块作用大小。
4 总结
本文主要对spontanous-style的语音合成进行研究,可以使用较少数据合成较高质量的spontanous-style语音。























 到【灌水乐园】发言
到【灌水乐园】发言









