




声明:平时看些文章做些笔记分享出来,文章中难免存在错误的地方,还望大家海涵。平时搜集一些资料,方便查阅学习:http://yqli.tech/page/speech.html。如转载,请标明出处。欢迎关注微信公众号:低调奋进
SynthASR: Unlocking Synthetic Data for Speech Recognition
本文为Alexa Speech, Amazon.com在2021.06.14更新的文章,主要使用tts合成的语料来优化ASR,从而提高ASR的性能,具体的文章链接
https://arxiv.org/pdf/2106.07803.pdf
1 背景
e2e的asr比传统的hybird asr在性能显出突出的优势,但训练ASR模型需要大量的标注数据,这将需要很大的成本开销。同时,tts系统合成的语音质量可以媲美人类的自然语音,而且可以合成不同风格和韵律的语音,因此使用TTS合成的语音来优化ASR成为本文研究的重点。
2 详细设计
本文使用的tts为multi-speaker tts,其中包括对prosody和speaker建模的encoder,具体的结构如图2所示。另外asr使用了rnn-t的结构,具体如图1所示,tts合成的不同风格不同说话人的语料来给rnn-t来训练。另外,本文使用multi-stage 训练策略来适用不同domain的应用,避免了 catastrophic forgetting问题,为了避免使用合成数据造成参数更新范围太大,提出了如公式2的elastic penalty。
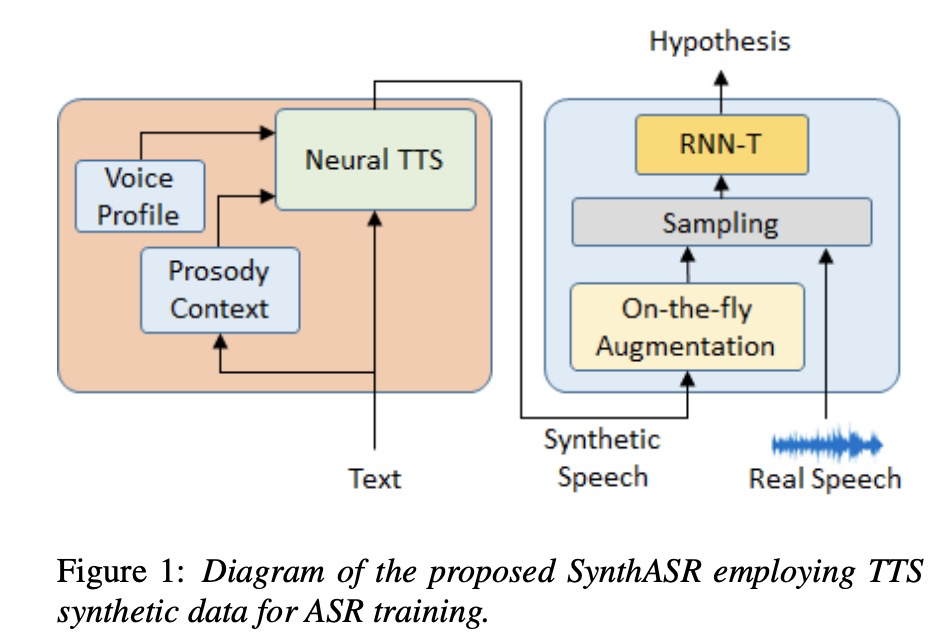
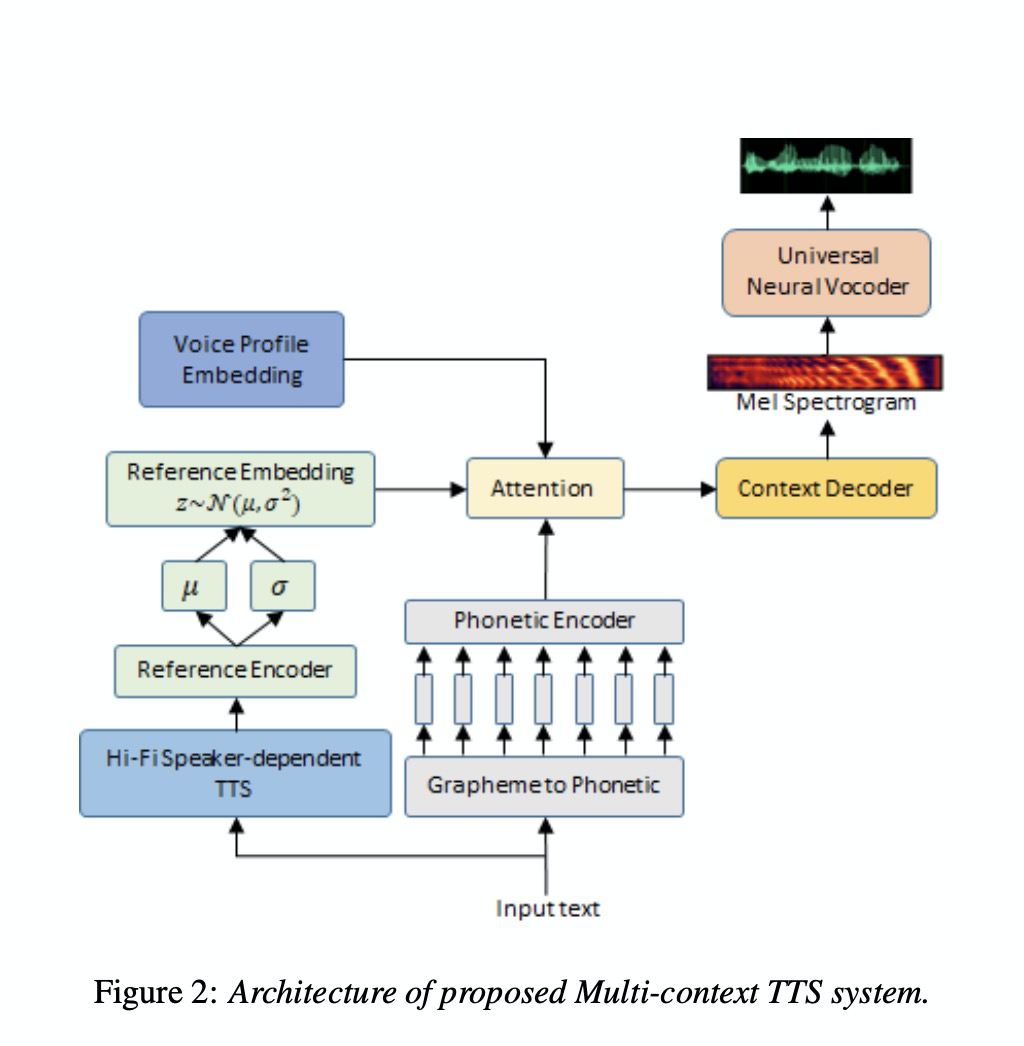

3 实验
本文使用LibriSpeech 960h数据来训练rnn-t作为benchmark,然后使用480h数据训练rnn-t作为baseline,然后使用480h+syn 1150h小时训练rnn-t,结果如table1 所示,使用480h+syn 1150h比只使用480h的效果较好。 table 2使用multi-stage来训练rnn-t的效果,结果显示使用multi-stage可以提高性能。
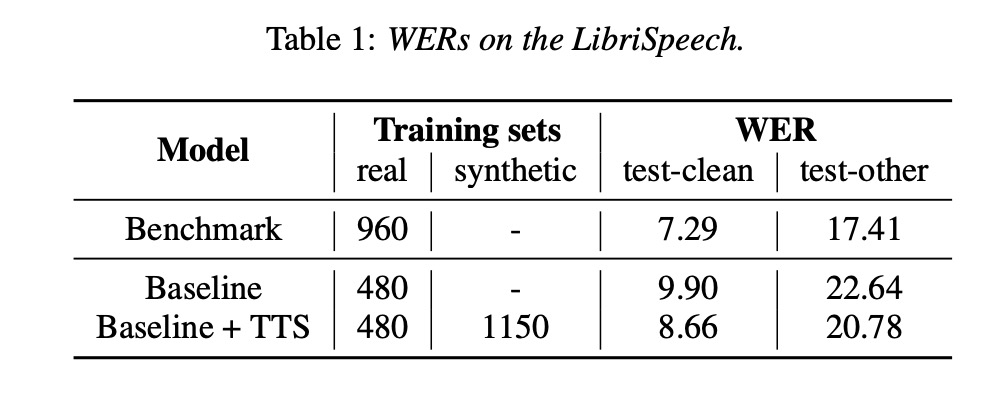
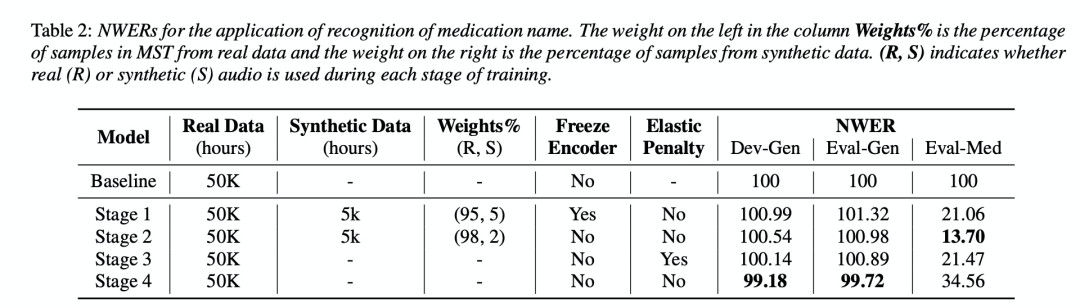
4 总结
本文使用TTS合成的语音和multi-stage 训练方法来优化ASR的性能,从而降低其wer。


















 1109
1109




 到【灌水乐园】发言
到【灌水乐园】发言









