 仅音频个性化语音合成AdaSpeech2:无转录数据的适应性文本到语音
仅音频个性化语音合成AdaSpeech2:无转录数据的适应性文本到语音





声明:语音合成论文优选系列主要分享论文,分享论文不做直接翻译,所写的内容主要是我对论文内容的概括和个人看法。如有转载,请标注来源。
欢迎关注微信公众号:低调奋进
AdaSpeech 2: Adaptive Text to Speech with Untranscribed Data
本文是清华大学和亚洲微软在2021.04.20更新的文章,主要的工作是只使用音频而不存在对应标注文件的语料进行个性化定制,具体文章链接
https://arxiv.org/pdf/2104.09715.pdf
本文需要阅读AdaSpeech这篇文章
题外话:现在需要的工作都做多任务联合学习,比如tts,asr,vc等等联合起来,本文的思想稍微有点跟这篇vc文章相似
1 背景
语音合成个性化是使用少量数据(几分钟或者几秒钟语音)进行语音定制,现有的方案都是先进行basemodel的训练,然后使用少量数据进行微调。但现实中的数据只存在音频而不存在对应的标注文件,因此本文设计了只使用音频进行个性化定制。
2 详细设计
本文系统主体架构是AdaSpeech,在此基础上添加mel encoder,具体如图1所示。整个的流程如图2所示,第一步,训练AdaSpeech;第二步,使用phoneme encoder来训练mel encoder;第三步,进行少数据量数据的微调(个性化);第四步,推理部分。
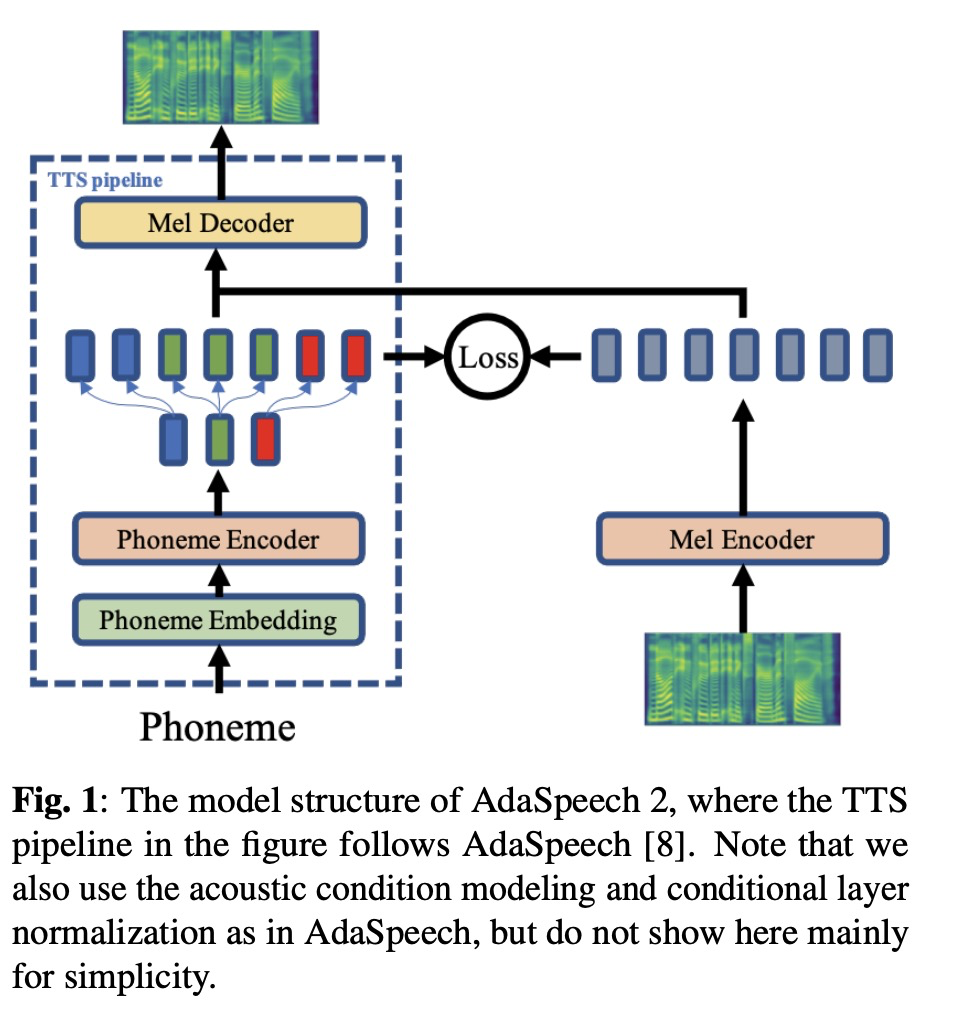
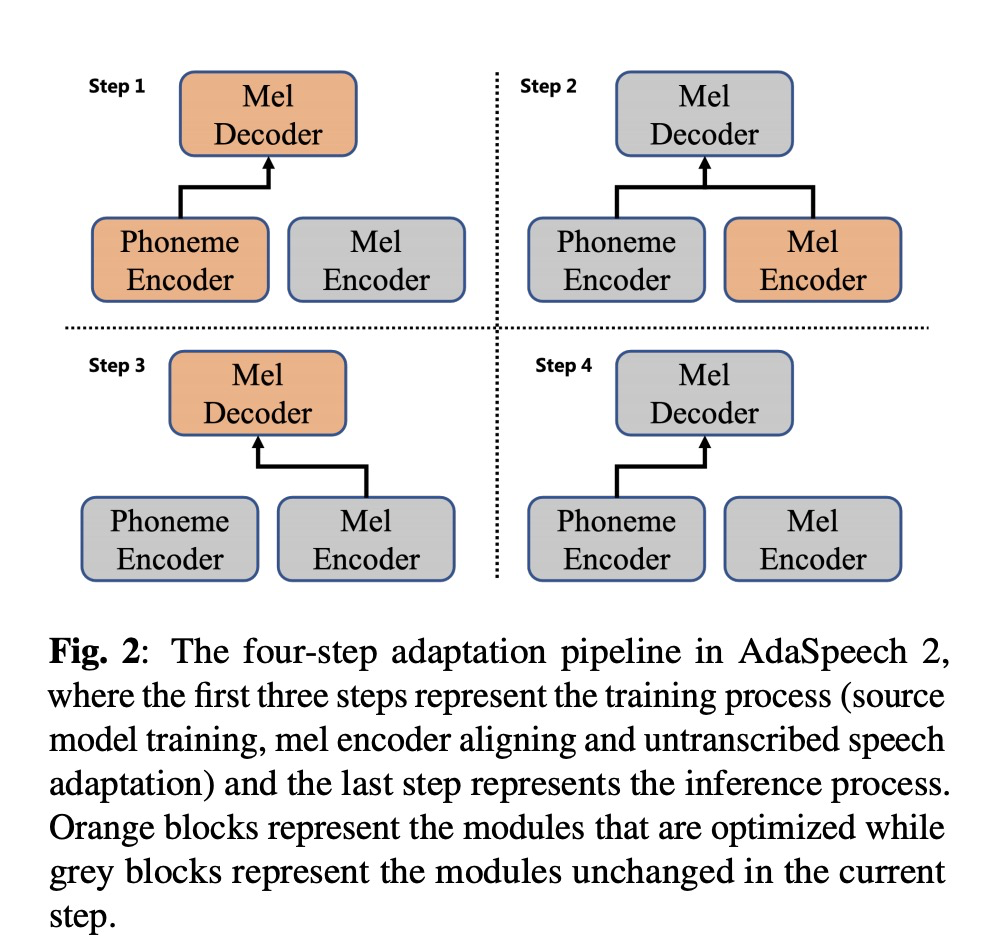
3 实验结果
本文对比以往的几种方案,其中MOS和相似度SMOS对比,adapspeech2接近adapspeech的方案。table 2是显示使用l2 loss和只微调mel decoder的作用。图3显示使用数据量对结果的影响。
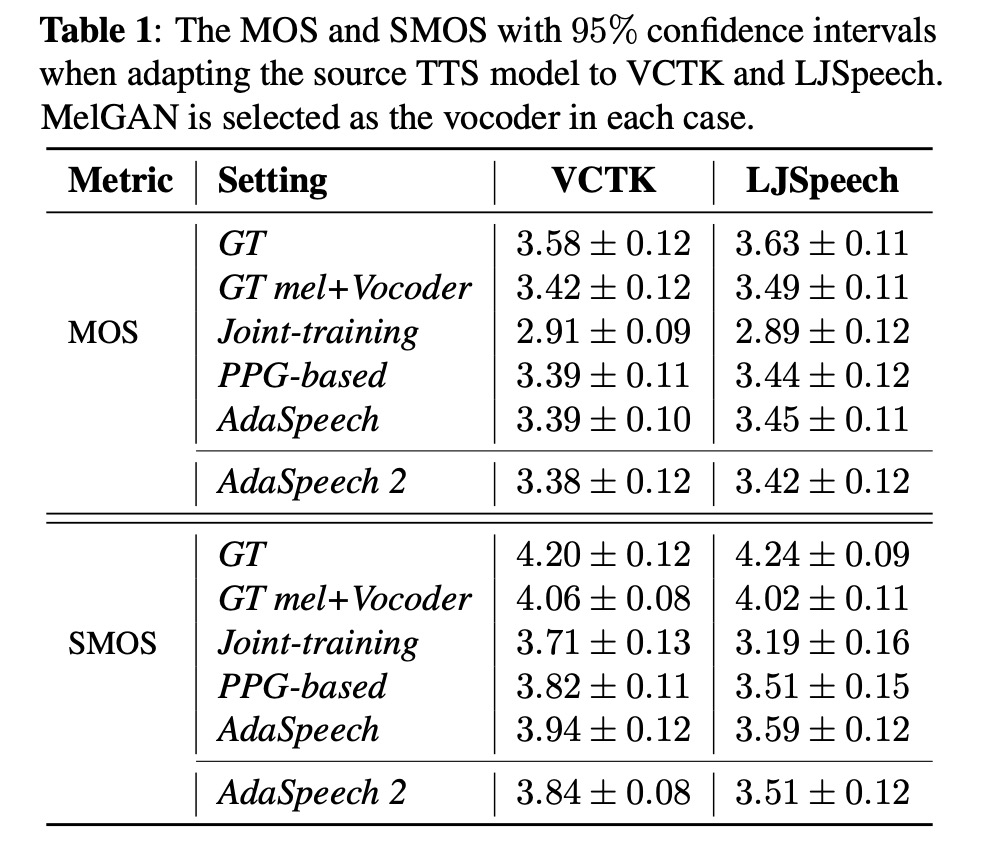

4 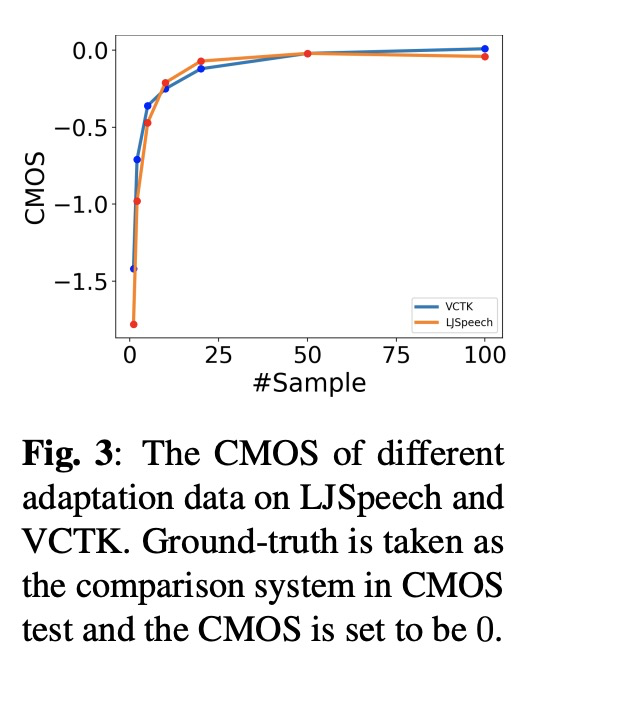
4 总结
现实中的数据只存在音频而不存在对应的标注文件,因此本文设计了只使用音频进行个性化定制,其效果接近使用带文本的训练语料。



















 359
359

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











