




 本文介绍了Johns Hopkins University的一篇2021年研究,探讨如何使用blockwise非自回归模型和mask-ctc优化流式语音识别(ASR)。研究提出的新方法在降低错误率方面优于mask-ctc,通过blockwise注意力编码器和动态映射策略处理音频块,结合mask语言模型进行结果调整。实验在TEDLIUM2和aishell1数据集上展示了优于传统方法的性能。
本文介绍了Johns Hopkins University的一篇2021年研究,探讨如何使用blockwise非自回归模型和mask-ctc优化流式语音识别(ASR)。研究提出的新方法在降低错误率方面优于mask-ctc,通过blockwise注意力编码器和动态映射策略处理音频块,结合mask语言模型进行结果调整。实验在TEDLIUM2和aishell1数据集上展示了优于传统方法的性能。
声明:平时看些文章做些笔记分享出来,文章中难免存在错误的地方,还望大家海涵。平时搜集一些资料,方便查阅学习:http://yqli.tech/page/speech.html。如转载,请标明出处。欢迎关注微信公众号:低调奋进
Streaming End-to-End ASR based on Blockwise Non-Autoregressive Models
本文为Johns Hopkins University在2021.07.20更新的文章,主要做使用blockwise和mask-ctc 来优化streaming asr的工作,具体的文章链接https://arxiv.org/pdf/2107.09428.pdf
1 背景
非自回归的模型受到极大的关注,尤其在rtf的优势,但其结果往往弱于自回归模型。本文结合mask-ctc和blockwise-attention,提出新的streming e2e asr,其结果相比于mask-ctc,其错误率更低。
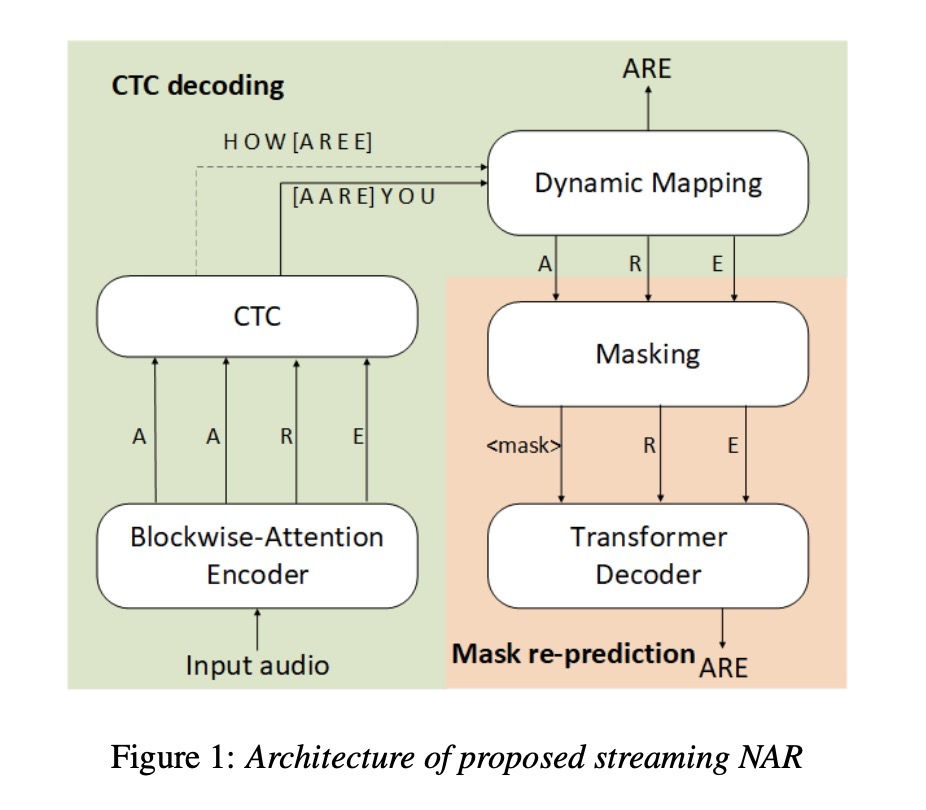
2 详细设计
图1为本文的详细设计,我们先看一下整体流程。输入的audio先进行block的划分,按照以往经验,block的边缘部分常会出现插入和删除错误,因此本文设计block之间存在50%的重叠部分,即每一帧被处理两遍。每个block数据经过blockwise-attention encoder处理后(每次处理都看到前一个block和当前block内容)使用greedy算法进行处理,对于重叠部分的处理本文采用算法1所示的dynamic map。接下来对预测的token输入到被称为masked language model(MLM),该模型对dynamic mapping的结果具有较低的confidence的token进行重新预测,经过多轮调整输出最终的结果。训练函数为公式3所示。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 1224
1224

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











