




目录

🎬 攻城狮7号:个人主页
🔥 个人专栏:《AI前沿技术要闻》
⛺️ 君子慎独!
🌈 大家好,欢迎来访我的博客!
⛳️ 此篇文章主要介绍 OpenAI开源0.4B参数Circuit-Sparsity模型
📚 本期文章收录在《AI前沿技术要闻》,大家有兴趣可以自行查看!
⛺️ 欢迎各位 ✔️ 点赞 👍 收藏 ⭐留言 📝!
前言
不管是写代码、画图还是聊天,现在的AI大模型都已经强得离谱。但有一个问题始终悬在所有人心头:我们不知道它到底是怎么想的。
我们喂给它数据,它吐出答案,中间的过程就像一个密封的黑箱。这种“不可解释性”,让医生不敢完全信任AI的诊断,让银行不敢把风控全权交给算法。
最近,OpenAI干了一件反直觉的事。他们没有去造更大、更复杂的模型,而是发布了一个参数只有0.4亿(0.4B)、且99.9%的连接都被剪断的“残缺”模型——Circuit-Sparsity。
这个看似“偷工减料”的模型,其实是OpenAI为了看懂AI大脑而进行的一次大胆手术。
一、告别“身兼数职”的混乱
要理解OpenAI为什么要删掉99.9%的权重,我们先得看看传统的AI模型长什么样。
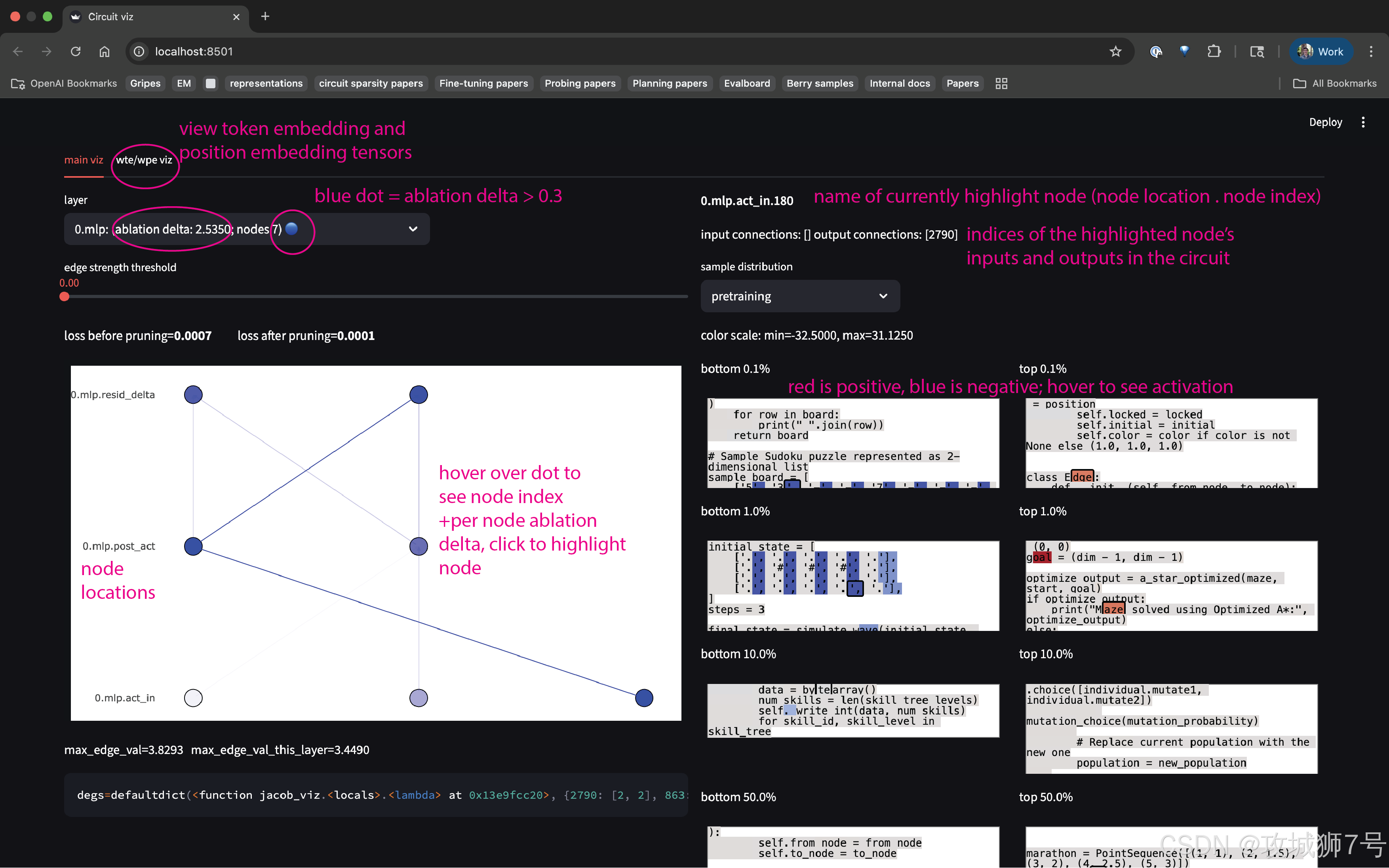
目前的AI大模型(如GPT-4),其内部结构通常是“密集(Dense)”的。这就好比一个拥挤的办公室,里面的几千亿个神经元全都纠缠在一起。为了存下海量的知识,每个神经元都被迫通过“叠加态(Superposition)”来工作——也就是说,同一个神经元可能既要负责识别“猫的胡须”,又要负责理解“莎士比亚的十四行诗”,还要顺便处理一下“Python代码的缩进”。
这种“身兼数职”的状态,导致当你试图去分析某个神经元时,根本搞不清它到底在干嘛。整个模型就像一团乱麻,牵一发而动全身,根本理不清楚逻辑流向。
OpenAI的新思路是:强行拆散它们。
通过“权重稀疏化(Weight Sparsity)”,OpenAI强制要求每个神经元只能和极少数的其他神经元“说话”。这就好比把那个拥挤的办公室拆了,给每个员工分配了独立的隔间,并且规定每个人只能干一件事。
如果一个神经元只负责识别“猫”,那它就绝对不能去管“代码”。因为连接被切断了,它想管也管不了。

二、当“黑箱”变成“电路板”
经过这种极致的“剪枝”后,奇迹发生了。
OpenAI发现,在这个稀疏模型内部,自然涌现出了一种被称为“电路(Circuits)”的结构。这些电路不再是纠缠不清的乱网,而是像我们物理课上学的电路图一样,逻辑清晰、路径分明。
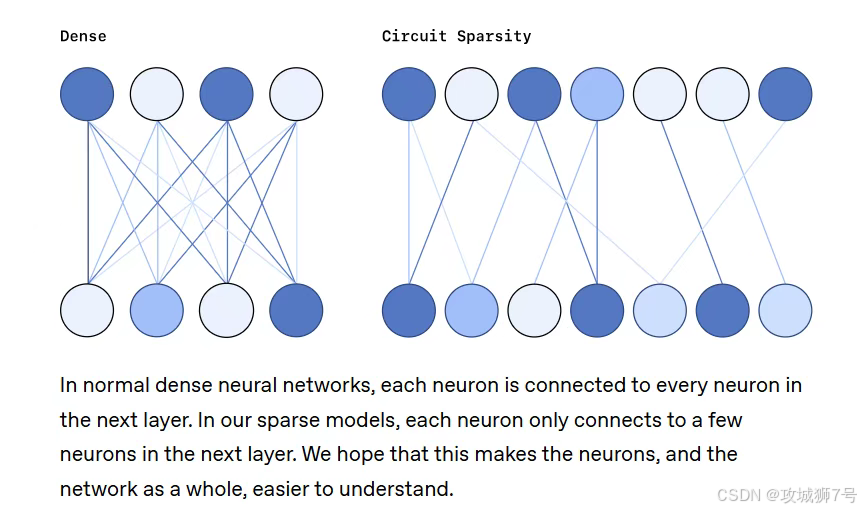
举个栗子:引号闭合任务
为了验证这个模型是不是真的“变透明”了,研究人员给它布置了一个任务:检查一段Python代码里的字符串引号是否闭合(比如开头是单引号,结尾也得是单引号)。
在以前的密集模型里,这个任务可能需要调动成百上千个神经元,混在各种无关的计算里,根本没法追踪。
但在Circuit-Sparsity模型里,研究人员看到了一个令人感动的极简流程:
(1)检测:有专门的神经元负责发现“哦,这里有个单引号”。
(2)记录:另一个神经元像记账员一样,记下“现在的状态是单引号开启中”。
(3)搬运:注意力机制把这个状态搬运到字符串结尾。
(4)匹配:输出层根据状态,填上闭合的单引号。
整个过程只用了十几个节点,就像一条精简的流水线。研究人员甚至做了个破坏性实验:把这条流水线上的关键节点切断,模型立马就不会做这题了;但如果切断其他几千个无关节点,模型毫发无损。
这意味着,我们终于确切地找到了控制AI某项能力的“物理开关”。
三、代价昂贵的“透明”
听到这里,你可能会问:既然稀疏模型这么好,逻辑清晰又可控,为什么大家不都用它?
这就涉及到了理想与现实的差距。Circuit-Sparsity目前更像是一个实验室里的“概念车”,离量产上路还有很远的距离。
核心痛点在于:慢,且贵。
现在的GPU(图形处理器)是专门为密集矩阵运算设计的。对于GPU来说,算一个全是数字的矩阵,和算一个99%都是0的矩阵,花的时间其实差不多,甚至因为稀疏矩阵的数据结构不规则,读取起来反而更费劲。
这就导致Circuit-Sparsity模型的运行效率极低,比同等规模的普通模型慢了100到1000倍。如果想把这一套用到GPT-4那种级别的千亿参数模型上,目前的算力成本是完全无法承受的。
这就好比我们为了让电线走线整齐,不得不把原本的一根粗电缆拆成一万根细电线单独铺设,工程量和维护成本直接爆炸。
四、未来的路:搭建“桥梁”
既然直接用稀疏模型太慢,那这个研究是不是就没用了?
并不是。OpenAI提出了一种“曲线救国”的方案——桥梁网络(Bridges)。
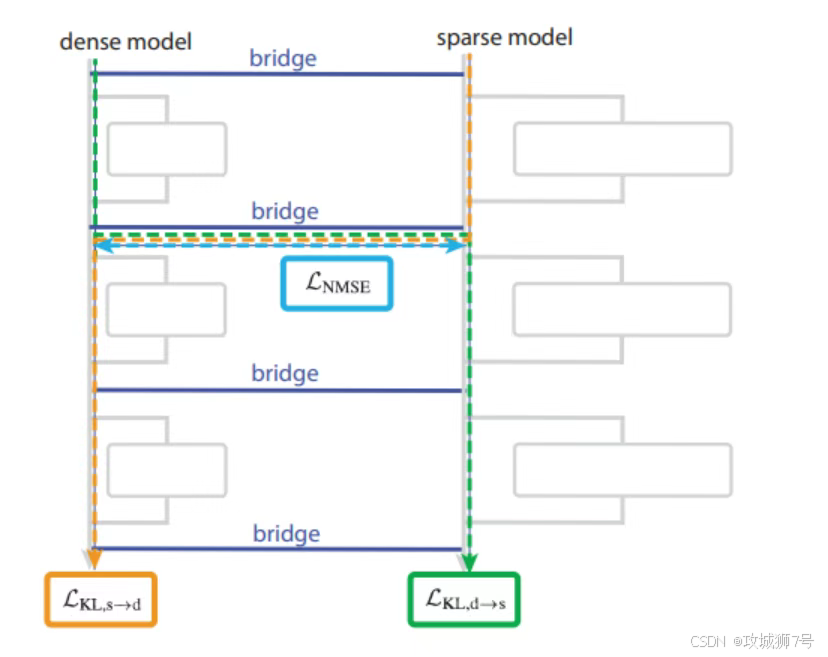
既然我们看不懂强大的密集模型,那我们可以训练一个稀疏模型作为“替身”或“翻译官”。我们可以尝试建立一种映射关系,把密集模型里那些混乱的激活状态,翻译成稀疏模型里清晰的电路语言。
或者,我们可以利用在稀疏模型里学到的原理,去反向“修剪”那些已经训练好的大模型,把那些不重要的乱七八糟的连接剪掉,只保留核心电路,从而在不重新训练的情况下提升可解释性。
结语
OpenAI这次开源的Circuit-Sparsity,与其说是一个可以用的产品,不如说是一份在这个AI狂飙突进时代里的“冷静声明”。
它告诉我们,人工智能不应该永远是一个充满玄学的黑箱。通过精心的设计和约束,我们完全有能力让机器的思维过程变得像钟表一样精确可见。
虽然距离让GPT-5变得完全透明还有很长的路要走,但至少,我们现在知道第一步该迈向哪里了。从“知其然”到“知其所以然”,这或许才是AI通向真正安全的必经之路。
开源地址:https://github.com/openai/circuit_sparsity
模型下载:https://huggingface.co/openai/circuit-sparsity
看到这里了还不给博主点一个:
⛳️ 点赞☀️收藏 ⭐️ 关注!
💛 💙 💜 ❤️ 💚💓 💗 💕 💞 💘 💖
再次感谢大家的支持!
你们的点赞就是博主更新最大的动力!



















 1660
1660

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











