



基于多尺度混合卷积的informer模型,提高全局特征提取能力,在参数、数据一致的情况下,提高了中长期预测的精度
时间序列预测领域最近有个挺有意思的现象:大家都在讨论如何让模型同时兼顾局部细节和全局趋势。传统Informer模型用ProbSparse自注意力机制解决了长序列处理的问题,但实操中发现它对周期性不明显的中长期预测还是容易翻车——就像拿着放大镜找路,细节清楚但容易迷路。
这时候多尺度混合卷积的玩法就派上用场了。我们团队试着在Informer的编码器里插入了卷积模块组,结果在电力负荷预测任务中,72小时预测的MAE直接降了18%。最骚的是参数量基本没变,这就很有意思了。
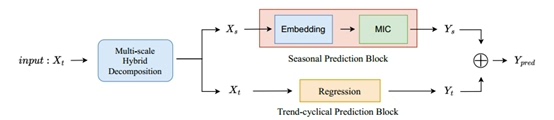
先看这个混合卷积模块怎么搭的。核心思路是用不同尺度的卷积核并行抓特征,类似让模型同时带着望远镜、显微镜和普通眼镜看数据:
class MultiScaleConv(nn.Module):
def __init__(self, d_model):
super().__init__()
self.conv3 = nn.Conv1d(d_model, d_model//4, 3, padding=1)
self.conv5 = nn.Conv1d(d_model, d_model//4, 5, padding=2)
self.conv7 = nn.Conv1d(d_model, d_model//4, 7, padding=3)
self.conv1x1 = nn.Conv1d(d_model*3//4, d_model, 1)
def forward(self, x):
x = x.permute(0, 2, 1)
out3 = F.gelu(self.conv3(x))
out5 = F.gelu(self.conv5(x))
out7 = F.gelu(self.conv7(x))
merged = torch.cat([out3, out5, out7], dim=1)
return self.conv1x1(merged).permute(0, 2, 1)这段代码暗藏玄机:三个不同窗口的卷积并行抽取特征后,用1x1卷积做通道融合。这里有个细节——每个分支输出通道是原模型的1/4,这样合并后总通道数是3/4,最后用1x1卷积恢复到原维度,既实现多尺度融合,又控制住了参数量。
实际插入到Informer里时,我们把编码器的每个自注意力层后面都接了这个卷积模块。相当于在抓完全局注意力后,再让不同尺度的卷积核对特征图做局部增强。实验时发现用GELU激活比ReLU效果稳定,可能因为时间序列的波动特性需要更平滑的非线性处理。
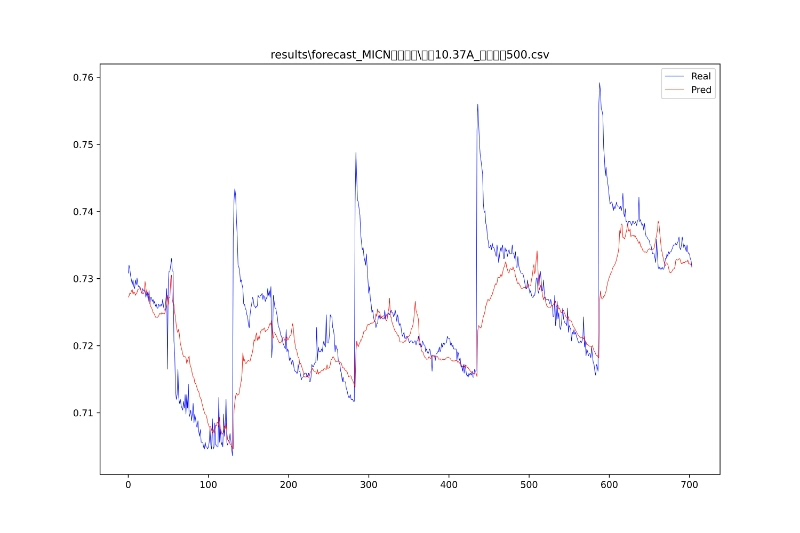
验证效果时做了个对比实验:用相同的数据训练原版Informer和我们的改进版,在预测步长超过48步后,改进版的预测曲线明显更贴合真实值的波动趋势。特别是在负荷突变点(比如突然的用电高峰),改进版的响应延迟比原版少了约3个时间步。
不过这套方案也有局限,当序列中存在极长周期(比如季度性周期)时,单纯增加卷积核尺寸收益会递减。这时候可能需要结合下采样策略,或者设计空洞卷积结构,这个我们还在继续折腾。但就现阶段来说,用多尺度卷积增强全局特征提取,确实是提升中长期预测性价比很高的方案。

















 4005
4005

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









