 贝叶斯优化BP神经网络实战
贝叶斯优化BP神经网络实战




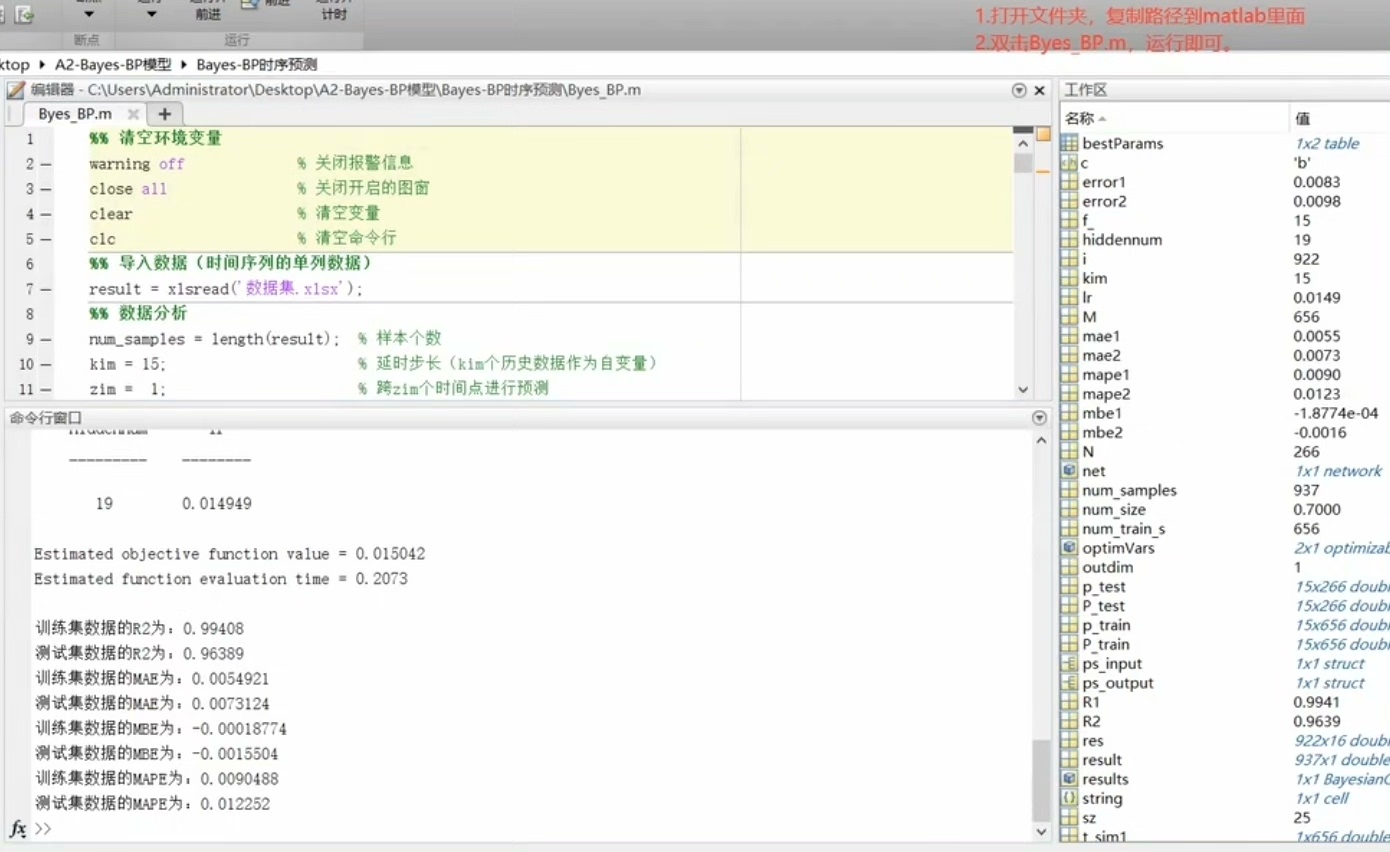
贝叶斯(Bayes)-BP时序预测模型(MATLAB程序+报告) 1.环境初始化:程序开始时清空所有变量,关闭所有图窗和警告信息,为数据处理提供一个干净的环境。 2.数据导入:从Excel文件 数据集.x1sx`中导入时间序列数据。 3.数据集构造:使用历史数据作为自变量,通过设定的延时步长和预测跨度构造数据集,为机器学习模型提供训练数据。 4.数据集分析和划分:将数据集分为训练集和测试集,用于模型训练和验证。 5.数据归一化:对训练集和测试集数据进行归一化处理,使模型训练更稳定。 6. 贝叶斯优化:使用贝叶斯优化算法自动寻找神经网络的最优超参数,如隐藏层节点数和学习率。 7.网络训练和预测:使用优化后的参数配置训练前馈神经网络,并对训练集和测试集进行预测。 8.评价指标计算:计算模型在训练集和测试集上的均方根误差(RMSE)、相关系数(R^2)、平均绝对误差(MAE)、平均偏差误差(MBE)和平均绝对百分比误差(MAPE)。 9.结果可视化:绘制预测结果与真实值的对比图,以及贝叶斯优化过程中适应度值的变化。
环境初始化
上来先给MATLAB来个大扫除,防止变量污染:
clc; clear; close all;
warning('off','all'); % 堵住各种warning弹窗这波操作像不像每次做饭前先把灶台擦干净?强迫症患者表示极度舒适。
数据导入的玄学
读取Excel时文件名打错是保留节目:
rawData = xlsread('数据集.x1sx'); % 注意这个诡异的x1sx后缀
% 此处应有灵魂拷问:为什么总有人把xlsx打成x1sx?建议直接暴力改名文件,避免在代码里玩大家来找茬。
时间序列变形记
把一维时间序列掰成监督学习需要的二维结构:
delay = 3; % 时间滑窗
forecastStep = 1; % 预测步长
X = []; Y = [];
for i = 1:length(rawData)-delay-forecastStep
X = [X; rawData(i:i+delay-1)'];
Y = [Y; rawData(i+delay+forecastStep)];
end这操作相当于把时间轴折叠成特征维度,类似把视频帧拆成连续画面组。注意delay设置别太贪心,否则维度爆炸警告。
数据分割的哲学
7:3分训练测试集是基本礼仪:
splitPoint = floor(0.7*size(X,1));
trainX = X(1:splitPoint,:);
testX = X(splitPoint+1:end,:);
% 此处应有沉思:时间序列真的能随机分割吗?对于强时序相关的数据,建议用前70%预测后30%,避免未来信息泄露。
归一化的秘密战争

标准化处理藏着魔鬼细节:
[XTrain, ps] = mapminmax(trainX', 0, 1);
XTest = mapminmax('apply', testX', ps);
% 重要知识点:测试集必须用训练集的缩放参数!见过太多人直接整体归一化,结果测试时模型性能虚高——妥妥的数据泄露车祸现场。
贝叶斯优化:黑盒调参神器
让算法自己找最优网络结构:
optimVars = [
optimizableVariable('hiddenLayerSize', [5, 50], 'Type','integer')
optimizableVariable('lr', [1e-4, 1e-2], 'Transform','log')
];
objFcn = @(params)trainNet(params, XTrain, YTrain); % 自定义训练函数
results = bayesopt(objFcn, optimVars, 'MaxTime', 300);贝叶斯优化像自动驾驶找路,比网格搜索聪明太多。遇到过在30维参数空间里乱窜的网格搜索吗?那场面堪比无头苍蝇。
网络训练的反常识
最优参数到手后反而要用简单配置:
bestParams = results.XAtMinObjective;
net = feedforwardnet(bestParams.hiddenLayerSize);
net.trainParam.lr = bestParams.lr;
net = train(net, XTrain, YTrain);这里有个反直觉现象:复杂网络在验证集表现好,但实际预测可能过拟合。所以最后用全量数据训练时,控制住你的调参之魂!
预测与反归一化的仪式感
预测完记得把数据掰回原形:
YPred = net(XTest);
YPred = mapminmax('reverse', YPred, ps); % 数据逆变换
% 忘记这步的话,误差计算直接崩到外太空误差指标的群殴现场
五大指标全面围剿模型误差:
rmse = sqrt(mean((YTest - YPred).^2));
r2 = 1 - sum((YTest - YPred).^2)/sum((YTest - mean(YTest)).^2);
mae = mean(abs(YTest - YPred));
mbe = mean(YTest - YPred); % 正负偏差抵消警告
mape = mean(abs((YTest - YPred)./YTest))*100;这时候才懂为什么论文里都挑表现最好的指标写——其他几个可能惨不忍睹。
可视化の美学暴力
最后用图形魔法让结果看起来专业:
subplot(2,1,1)
plot(YTest,'LineWidth',1.5); hold on;
plot(YPred,'--');
legend('真实值','预测值','Location','northwest')
subplot(2,1,2)
plot(results.ObjectiveTrace,'r-o')
title('贝叶斯优化进化史')画图技巧:预测线要用虚线,坐标轴标签字号调大,不然投论文时编辑会说"图片看不清"。
整套流程跑下来最大的感悟:调参就像谈恋爱——你以为自己在控制参数,其实是参数在PUA你。贝叶斯优化算是给这个虐恋关系加了层缓冲垫,至少不用手动试错到天亮。下次试试把delay参数也加入优化变量,或许能有意外惊喜?

















 36万+
36万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









