









 本文介绍YOLO(You Only Look Once)实时目标检测算法,它将对象识别与定位合二为一,通过预定义预测区与边框回归,实现快速准确的目标检测。YOLO采用一步走策略,直接对输入图像应用算法并输出类别与定位。
本文介绍YOLO(You Only Look Once)实时目标检测算法,它将对象识别与定位合二为一,通过预定义预测区与边框回归,实现快速准确的目标检测。YOLO采用一步走策略,直接对输入图像应用算法并输出类别与定位。
什么是YOLO
对象识别和定位,可以看成两个任务:
-
找到图片中某个存在对象的区域;
-
识别出该区域中具体是哪个对象。
解决方法:
-
遍历图片,不同大小,不同位置的每个区域,选择最大概率的结果作为输出。
-
RCNN:候选区(Region Proposals)方法。先找到可能存在对象的候选区(Selective Search),然后对每个候选区进行对象识别。候选区域生成 --> 特征提取 --> 类别判断 --> 位置微调。
-
YOLO:将两个任务合并,使用预定义的预测区(类似于RCNN的候选区),后使用边框回归,对边框进行微调。
目前,基于深度学习算法的一系列目标检测算法大致可以分为两大流派:
-
两步走(two-stage)算法:先产生候选区域然后再进行CNN分类(RCNN系列)。
-
一步走(one-stage)算法:直接对输入图像应用算法并输出类别和相应的定位(YOLO系列)。
YOLO是实时目标检测,它的意思是You Only Look Once。YOLO到目前为止已经发展到了YOLOv3。
YOLO的主页为https://pjreddie.com/darknet/yolo/。
论文下载:http://arxiv.org/abs/1506.02640。
代码下载:https://github.com/pjreddie/darknet 。
YOLO
YOLO核心思想
就是利用整张图作为网络的输入,直接在输出层回归 bounding box(边界框)的位置及其所属的类别。

YOLO实现
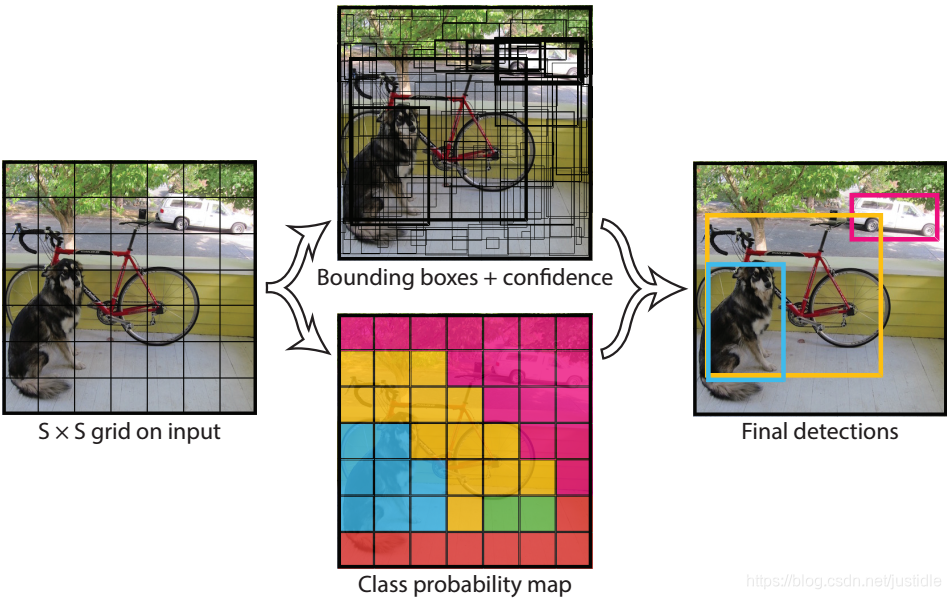
将一幅图像分成 S x S 个网格(grid cell),如果某个 object 的中心落在这个网格中,则这个网格就负责预测这个 object。
我们的模型将检测作为一个整体问题。将一幅图像分成 S x S 个网格(grid cell),每个网格预测 B 边界框(bounding boxes),信任这些边界框和 C 类可能性(class probabilities)。这些预测将编码为 S x S x (B * 5 + c) 个张量(tensor)。
YOLO对 PASCAL VOC 的检测,S = 7,B = 2,C = 20,我们最终的预测张量将为 7 x 7 x 30 个。
网络架构
相较于其他网络,YOLO去掉候选区步骤之后,结构非常简单,就是单纯的卷积、池化,加上最后两层全连接。单看网络结构的话,和普通的CNN对象分类网络几乎没有本质区别.最大的差异是最后输出层用线性函数作为激活函数(其他的层都使用leaky rectified线性激活函数),因为需要预测边界框的位置(数值型),而不仅仅是对象的概率。所以粗略来说,YOLO的整个结构就是输入图片经过神经网络的变换得到一个输出的张量。
YOLO有24个卷积层,后面是2个全连接层(FC)。部分卷积层交替使用1 * 1缩减层以减少特征图的深度。对于最后一个卷积层,它输出一个形状为(7, 7, 1024)的张量。张量然后变平,使用2个全连接层作为线性回归的形式,输出7 * 7 * 30个参数,然后重新变换为(7, 7, 30),即每个位置2个边界框的预测。
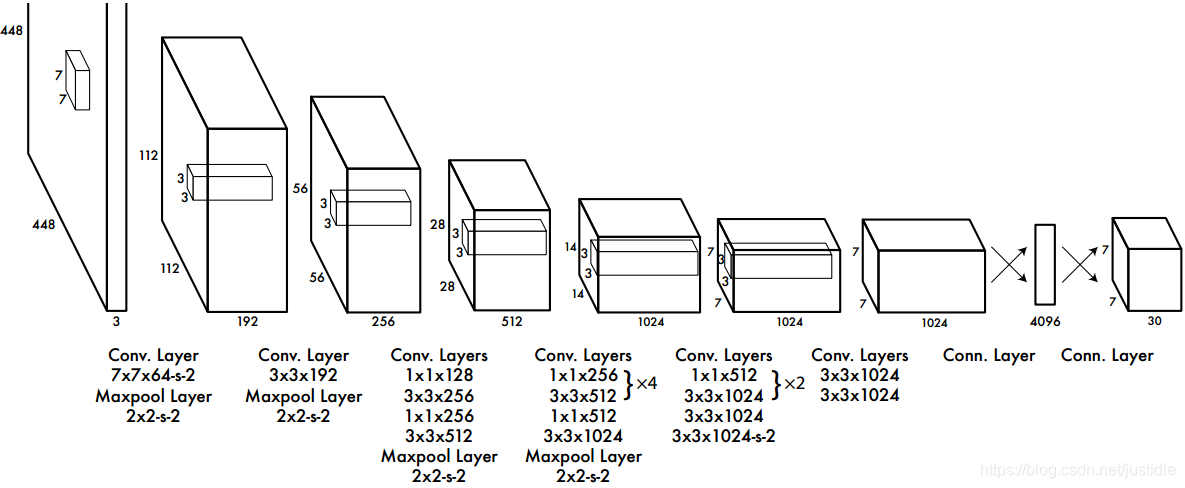
进一步细节请参考YOLO论文,http://arxiv.org/abs/1506.02640。
P.S.
文章中的图片全部来自YOLO论文。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











