




当大模型开始“边找边想”,检索与推理不再是单向流程,而是一场实时对话。百篇论文、几十个基准、4 大踩坑指南,为你画出一张从“幻觉”到“协同”的完整路线图。

大家好我是肆〇柒。在AI领域,大型语言模型(LLM)已经展现出卓越的语言生成能力,并在诸多任务中取得了显著成果。然而,LLM 存在两大局限:一是知识幻觉,因其知识存储静态且参数化,易生成错误内容;二是复杂推理能力不足,难以应对现实世界的复杂问题。
为突破这些局限,研究者们提出了协同 RAG-Reasoning 系统,该系统深度融合检索(Retrieval)与推理(Reasoning),摒弃了传统 “先检索、后推理” 的线性模式,转而采用动态交织的迭代框架,使检索与推理相互促进,显著提升了模型在知识密集型任务中的表现。
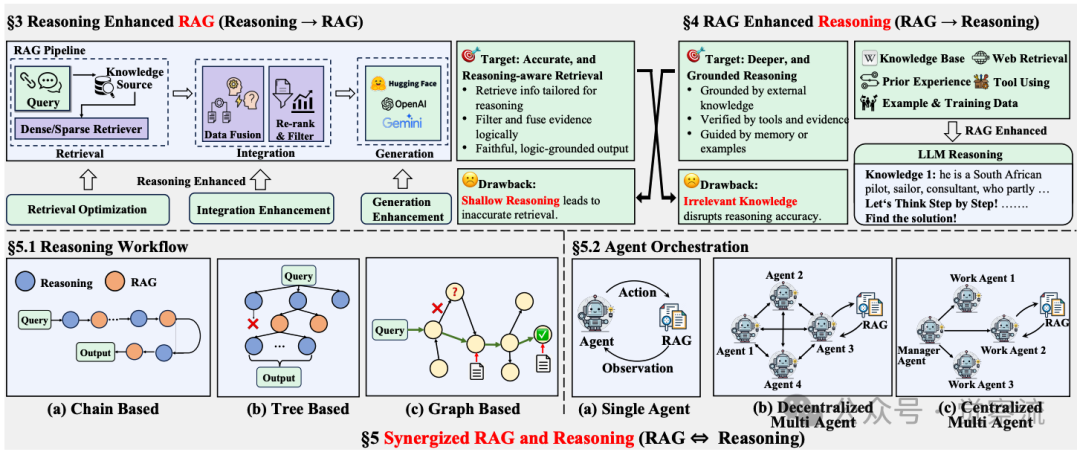
RAG-Reasoning 系统概述。推理增强 RAG 方法和 RAG 增强推理方法代表单向增强。相比之下,协同 RAG-Reasoning 系统迭代地执行推理和检索,实现相互增强。
大家在落地 AI 应用的时候,在一些场景中可能会遇到幻觉问题,知识幻觉问题在复杂的推理任务中尤为突出,例如在需要多跳推理的医学诊断或法律推理场景中,传统 LLM 经常会因为其内部知识的静态性和不完整性而生成错误或不准确的结论。同时,在处理诸如科学发现、商业战略规划等复杂现实问题时,模型的推理能力不足会导致其无法有效整合多源信息并进行深层次的逻辑推理。这些问题限制了 LLM 在实际应用中的可靠性和有效性。
为应对上述挑战,研究者们逐渐认识到检索与推理的协同作用是提升模型性能的关键。协同 RAG-Reasoning 系统通过允许推理过程动态引导检索方向,并利用新检索到的知识持续精炼推理逻辑,从而实现了对复杂问题的逐步拆解和深入分析,显著提升了模型在多跳推理、事实核查、代码生成等知识密集型任务中的表现。这种动态交互模式不仅增强了模型的逻辑推理能力,还有效降低了知识幻觉的风险,使得模型能够更加可靠地处理现实世界的复杂问题。
下面本文就将这一“协同”理念拆解为可落地的技术路径,从“为什么需要协同”到“如何协同”,再到“协同后能带来哪些质变”,逐层展开综述。我们将首先回顾传统 RAG 与纯推理系统的局限,指出协同设计的必要性;随后以三类演进框架为坐标,展示协同机制如何从“单向增强”走向“双向闭环”;最后通过一个端到端的 DeepResearcher 案例,演示协同系统如何在真实任务中完成“问题分解—检索—验证—整合—再推理”的完整循环。
三类框架的演进视角:从传统到协同的技术跃迁
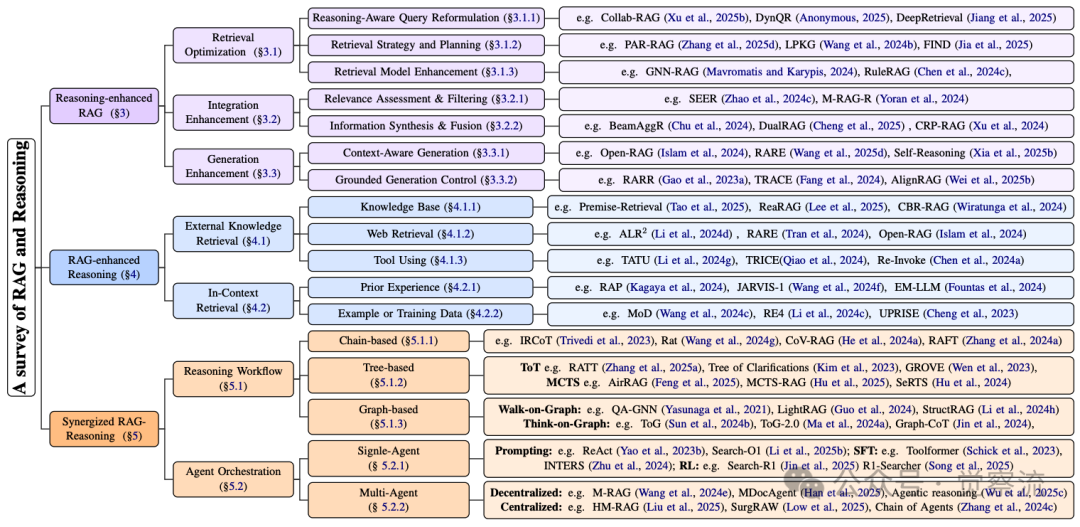
RAG-Reasoning 系统的最新进展分类
传统静态 RAG:初代尝试与固有局限
传统静态 RAG 系统采用线性模式,先从外部知识库检索信息,再与原始查询结合生成答案。其 Retrieval-Then-Reasoning (RTR) 流程为一次性过程,分为检索、整合、生成三个阶段。在复杂任务中,该流程无法动态调整,常导致检索与推理需求错配。
例如,在处理需要多跳推理的科学问题时,传统 RAG 系统可能在初次检索时无法获取到所有相关的知识点,但系统缺乏根据推理进展实时优化检索策略的能力,导致后续推理步骤无法得到有效支撑。这种局限性在开放域问答中表现得尤为明显,模型可能生成与问题相关但不够准确或全面的答案。此外,传统静态 RAG 系统的整合阶段往往只是简单地将检索到的知识与原始查询拼接,缺乏对知识的相关性、准确性和逻辑连贯性的深度评估,这进一步影响了最终生成答案的质量。
单向增强:局部优化的有益探索
为突破传统静态 RAG 的局限,研究者们提出了两种单向增强策略。推理增强 RAG(Reasoning → RAG)利用推理能力优化 RAG 流程的各个环节,如在检索阶段通过深度推理重塑检索请求,在生成阶段确保答案紧扣证据,避免知识幻觉。例如,通过自然语言处理技术对原始查询进行语义分析和扩展,生成更精准的检索关键词,从而提高检索到的相关知识的质量。在生成阶段,利用推理模型对检索到的知识进行逻辑验证和整合,确保生成的答案与证据严格对应,减少幻觉现象。
RAG 增强推理(RAG → Reasoning)则利用检索到的外部知识为推理提供事实依据,帮助模型跨越逻辑鸿沟,生成更精准的推理结果。例如,在处理数学证明或逻辑推理问题时,从外部知识库检索相关的定理、公式和推理规则,为推理过程提供必要的支撑。然而,这两种策略均未打破单向信息流,仅在局部进行优化,无法从根本上解决传统静态 RTR 的弊端,如推理过程无法动态反馈给检索模块以获取更有针对性的知识。
协同 RAG-Reasoning:动态交互的智能跃迁
协同 RAG-Reasoning 系统构建了迭代式的检索 - 推理循环框架(RAG ⇔ Reasoning)。在此框架下,推理主动引导检索方向,检索根据推理需要动态调整,新检索到的知识持续精炼推理逻辑。例如,在解答复杂医学问题时,系统首先依据初步推理生成针对性的检索请求,精准定位医学文献;接着对检索结果进行深度分析和筛选,提取相关知识片段;然后基于这些知识展开新一轮推理,细化问题分解;若发现关键证据缺失,再次启动检索,直至推理链条完整闭合。这种动态交互模式有效克服了传统静态 RAG 的缺陷,使模型在面对复杂问题时能够灵活应对、深入剖析,显著提升了解决问题的能力。
协同 RAG-Reasoning 系统通过引入深度强化学习和自适应控制机制,实现了推理与检索的紧密耦合和协同进化。在每一步推理过程中,系统会根据当前推理状态动态评估所需的知识类型和深度,并据此调整检索策略,确保检索到的知识能够精准匹配推理需求。同时,检索到的新知识会即时反馈给推理模块,用于更新推理路径和验证中间结果,从而形成一个高效的闭环优化过程。这种机制在提升模型处理复杂问题能力的同时,还增强了其在动态环境中的适应性和鲁棒性。
三类框架对比表
| 框架类型 |
流程特点 |
优势 |
局限性 |
| 传统静态 RAG |
Retrieval-Then-Reasoning (RTR) |
简单线性模式,缓解知识过时问题 |
检索准确性难以保障,推理深度受限,系统适应性不足 |
| 单向增强 |
Reasoning → RAG 或 RAG → Reasoning |
局部优化 RAG 流程或推理过程 |
未打破单向信息流,无法根本解决传统 RTR 的弊端 |
| 协同 RAG-Reasoning |
iteratively interleave search and reasoning |
动态交互,相互促进,提升问题解决能力 |
系统复杂度增加,需平衡效率与准确性 |
至此,我们已看清三类框架的静态差异。但 “协同” 究竟如何落地?下面将拆解推理增强 RAG 的 “精准优化” 细节——它正是协同系统的第一块拼图。
推理增强 RAG:精准优化的多维策略
检索优化:深度推理驱动的精准知识定位
推理增强 RAG 在检索阶段通过引入深度推理机制,显著提升了检索请求的质量和针对性。例如,Collab-RAG 利用多轮对话机制和深度推理模型,对用户的原始查询进行语义扩展和上下文关联分析,生成包含多个关键概念和隐含语义的检索请求,从而从知识库中检索到更全面、更精准的相关知识。PAR-RAG 则采用逐步规划的方法,将复杂问题分解为多个子问题,并针对每个子问题生成独立的检索请求,通过多轮检索逐步收敛到最终答案。GNN-RAG 借助图神经网络编码知识图谱,能够捕捉知识之间的复杂关系和语义关联,支持多跳推理中的知识追踪和扩展,为推理过程提供丰富的结构化知识。
整合优化:高信噪比知识集合的构建
在整合阶段,SEER、BeamAggR、CRP-RAG 等方法通过对检索到的知识进行深度评估和筛选,构建高
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 431
431

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









