 小红书开源多语言文档解析模型dots.ocr
小红书开源多语言文档解析模型dots.ocr





dots.ocr 是一款功能强大、支持多语言的文档解析模型,它在单一的视觉语言模型中统一了布局检测和内容识别,同时能保持良好的阅读顺序。

dots.ocr 是一款功能强大、支持多语言的文档解析模型,它在单一的视觉语言模型中统一了布局检测和内容识别,同时能保持良好的阅读顺序。尽管其基础模型是一个17亿参数的“小模型”,但它依然实现了业界领先(SOTA)的性能。dots.ocr对多语言识别的良好性能弥补了开源社区的空白,不错的检测、识别能力也为多模态和大模型社区提供了宝贵的基础。
01、简介
dots.ocr 是一款功能强大、支持多语言的文档解析模型,它在单一的视觉语言模型中统一了布局检测和内容识别,同时能保持良好的阅读顺序。尽管其基础仅是一个17亿参数的”小模型“,但依然在多个benchmark上获得了匹配超大参数量闭源模型的业界领先(SOTA)性能。
- 性能强大:dots.ocr 在 OmniDocBench 基准测试上,针对文本、表格和阅读顺序三方面均取得了业界领先(SOTA)的性能,同时其公式识别效果可与豆包-1.5(Doubao-1.5)和 gemini2.5-pro 等更大规模的模型相媲美。
- 多语言支持:dots.ocr 在小语种上展现出强大的解析能力,在我们内部的多语言文档基准测试中,无论是在布局检测还是内容识别方面,都取得了显著的优势。
- 统一且简洁的架构:通过利用单一的视觉语言模型,dots.ocr 提供了一个比依赖复杂多模型流水线的方法更为精简的架构。任务切换仅需通过更改输入提示词(prompt)即可完成,证明了视觉语言模型(VLM)同样可以取得与 DocLayout-YOLO 等传统检测模型相媲美的检测效果。
- 高效与快速:dots.ocr 基于一个17亿参数的大语言模型构建,因此其推理速度优于多种更大规模的 VLM 方案。
github:
https://github.com/rednote-hilab/dots.ocr
hugginface:
https://huggingface.co/rednote-hilab/dots.ocr
demo:
https://dotsocr.xiaohongshu.com
多语种端到端识别性能对比
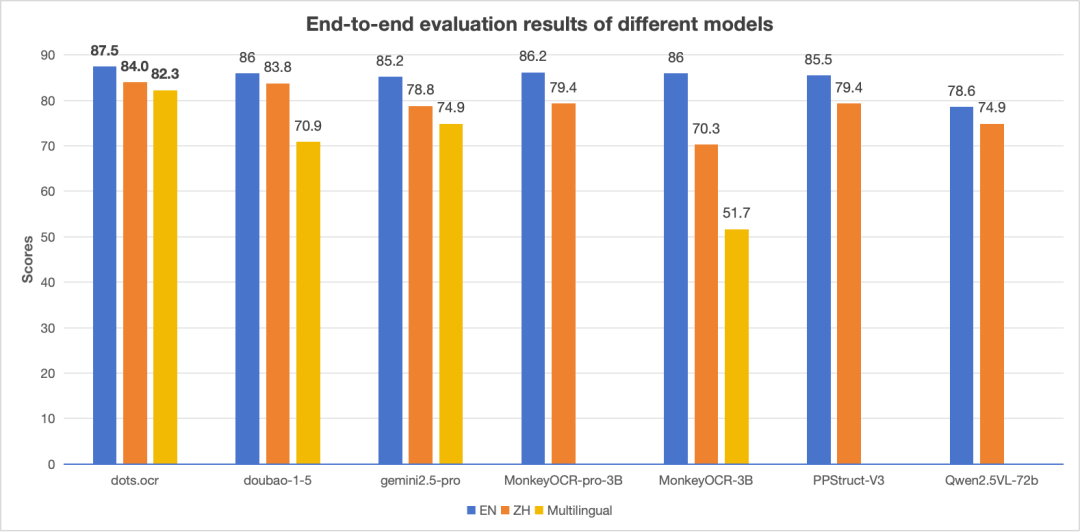
注:英文(EN)和中文(ZH)的指标是 OmniDocBench的端到端指标,多语言(Multilingual)的指标是dots.ocr-bench的端到端指标。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 3474
3474

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









