



目录
系列篇章💥
前言
一、项目概述
二、技术原理
(一)混合专家(MoE)架构
(二)扩散模型(Diffusion Model)
(三)高压缩率3D VAE
(四)大规模数据训练
(五)美学数据标注
三、主要功能
(一)文生视频(Text-to-Video)
(二)图生视频(Image-to-Video)
(三)统一视频生成(Text-Image-to-Video)
(四)电影级美学控制
(五)复杂运动生成
四、应用场景
(一)短视频创作
(二)广告与营销
(三)教育与培训
(四)影视制作
(五)新闻与媒体
五、性能表现
(一)生成质量
(二)计算效率
(三)泛化能力
(四)与同类模型比较
六、快速使用
(一)环境准备
(二)模型下载
(三)文生视频(Text-to-Video)生成实践
(四)图生视频(Image-to-Video)生成实践
(五)统一视频生成(Text-Image-to-Video)实践
(六)多GPU推理
七、结语
前言
在人工智能飞速发展的当下,AI视频生成技术正逐渐成为内容创作领域的热门研究方向。阿里巴巴开源的通义万相Wan2.2项目,凭借其强大的多模态生成能力和创新的技术架构,为AI视频生成领域带来了新的突破,有望为创作者和企业带来更高效、更优质的视频创作体验。
一、项目概述
通义万相Wan2.2是阿里巴巴开源的先进AI视频生成模型,包含文生视频(Wan2.2-T2V-A14B)、图生视频(Wan2.2-I2V-A14B)和统一视频生成(Wan2.2-IT2V-5B)三款模型,总参数量达270亿 。该项目首次引入混合专家(MoE)架构,有效提升生成质量和计算效率,同时首创电影级美学控制系统,能精准控制光影、色彩、构图等美学效果,支持文本和图像生成视频,可在消费级显卡上运行,为视频创作带来了前所未有的灵活性和高效性。

二、技术原理
(一)混合专家(MoE)架构
通义万相Wan2.2引入了Mixture-of-Experts(MoE)架构,将模型分为高噪声专家和低噪声专家。高噪声专家负责视频的整体布局,低噪声专家负责细节完善。在保持计算成本不变的情况下,大幅提升模型的参数量和生成质量。这种架构设计使得模型在处理复杂的视频生成任务时,能够更好地平衡整体结构与细节表现,从而生成更高质量的视频内容。
(二)扩散模型(Diffusion Model)
基于扩散模型作为基础架构,通过逐步去除噪声来生成高质量的视频内容。MoE架构与扩散模型结合,能进一步优化生成效果。扩散模型在视频生成过程中,通过逐步降低噪声,逐步构建出清晰、连贯的视频帧序列,使得生成的视频在视觉上更加自然、流畅。
(三)高压缩率3D VAE
为提高模型的效率,通义万相2.2基于高压缩率的3D变分自编码器(VAE)。架构实现了时间、空间的高压缩比,让模型能在消费级显卡上快速生成高清视频。这种高压缩率的设计使得模型在不牺牲生成质量的前提下,大幅降低了对硬件资源的需求,使得更多的用户能够在普通的消费级设备上使用该模型进行视频创作。
(四)大规模数据训练
模型在大规模数据集上进行训练,包括更多的图像和视频数据,提升模型在多种场景下的泛化能力和生成质量。通过在海量数据上进行训练,模型能够学习到不同场景、不同风格的视频特征,从而在生成视频时能够更好地适应各种输入条件,生成更具多样性和真实感的视频内容。
(五)美学数据标注
基于精心标注的美学数据(如光影、色彩、构图等),模型能生成具有专业电影质感的视频内容,满足用户对视频美学的定制需求。这种美学数据的引入,使得模型在生成视频时能够更好地理解和应用电影级的美学原则,从而生成更具艺术感和观赏性的视频作品。
三、主要功能
(一)文生视频(Text-to-Video)
用户只需输入一段文本描述,如“一只猫在草地上奔跑”,模型便能根据文本内容生成相应的视频。这一功能极大地简化了视频创作的流程,使得创作者无需复杂的视频拍摄和剪辑技术,仅通过文字描述即可快速生成所需的视频内容,大大提高了创作效率。
(二)图生视频(Image-to-Video)
用户上传一张图片,模型会根据图片内容生成动态视频,让静态图片“活”起来。这一功能为图片创作者提供了一种全新的创作方式,能够将静态的图片转化为具有动态效果的视频,为观众带来更加生动、丰富的视觉体验。
(三)统一视频生成(Text-Image-to-Video)
结合文本描述和图片信息生成视频,能够生成更精准、更符合用户需求的视频内容。通过同时利用文本和图片两种模态的信息,模型能够更准确地理解用户的创作意图,从而生成更具针对性和表现力的视频作品。
(四)电影级美学控制
用户可以通过输入相关关键词(如“暖色调”“中心构图”)来定制视频的美学风格,生成具有专业电影质感的视频。这一功能使得用户能够根据自己的创作需求和审美偏好,对生成的视频进行个性化的美学调整,提升视频的艺术价值和观赏性。
(五)复杂运动生成
能够生成复杂的运动场景和人物交互,提升视频的动态表现力和真实感。这一功能使得模型在生成视频时能够更好地处理复杂的运动场景,生成更加自然、流畅的动态效果,为观众带来更加逼真的视觉体验。

四、应用场景
(一)短视频创作
创作者可以快速生成吸引人的短视频内容,用于社交媒体平台,节省创作时间和成本。在短视频竞争日益激烈的当下,通义万相Wan2.2能够帮助创作者快速产出高质量的视频作品,提升内容的吸引力和传播力。
(二)广告与营销
广告公司和品牌可以利用该模型生成高质量的广告视频,提升广告效果和品牌影响力。通过生成更具创意和吸引力的广告视频,能够更好地吸引消费者的注意力,提高品牌的知名度和美誉度。
(三)教育与培训
教育机构和企业可以生成生动的教育视频和培训材料,提升学习效果和培训质量。将复杂的知识点通过生动的视频形式呈现出来,能够更好地激发学习者的兴趣,提高学习效果。
(四)影视制作
影视制作团队可以快速生成场景设计和动画片段,提升创作效率,降低制作成本。在影视制作过程中,通义万相Wan2.2可以作为一种高效的创意工具,帮助制作团队快速实现创意构思,缩短制作周期,降低制作成本。
(五)新闻与媒体
新闻机构和媒体可以生成动画和视觉效果,增强新闻报道的视觉效果和观众参与度。通过生成更具视觉冲击力的新闻视频,能够更好地吸引观众的注意力,提升新闻报道的传播效果。
五、性能表现
(一)生成质量
通义万相Wan2.2在生成质量上表现出色,能够生成高质量、高分辨率的视频内容。无论是文生视频、图生视频还是统一视频生成,模型都能够生成符合用户输入条件的视频,并且在细节表现、动态效果等方面都具有较高的水平。与前一代模型相比,Wan2.2在生成质量上有显著提升,尤其是在复杂运动场景和人物交互的生成上,表现更加自然、流畅。
(二)计算效率
借助混合专家(MoE)架构和高压缩率3D VAE,通义万相Wan2.2在计算效率上也取得了显著的提升。模型能够在消费级显卡上快速运行,生成高清视频的速度明显加快。例如,5B参数的紧凑视频生成模型可以在单个RTX 4090 GPU上生成5秒720P视频,耗时不到9分钟,这使得模型在实际应用中具有更高的可用性和实用性。
(三)泛化能力
通过在大规模数据集上进行训练,通义万相Wan2.2在多种场景下的泛化能力得到了显著提升。模型能够适应不同的输入条件和创作需求,生成具有多样性和真实感的视频内容。无论是在不同的主题、风格还是场景下,模型都能够生成高质量的视频作品,展现出良好的泛化性能。
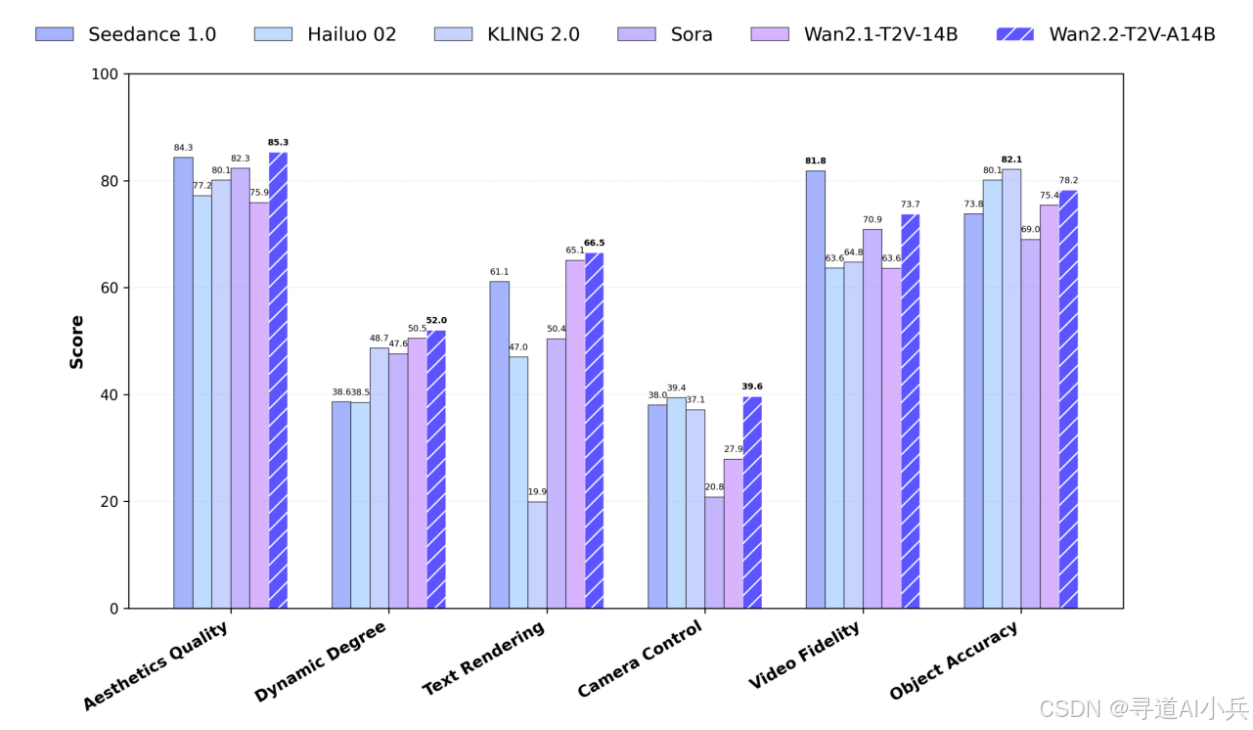
(四)与同类模型比较
在与同类AI视频生成模型的比较中,通义万相Wan2.2在多个方面都表现出色。在生成质量上,Wan2.2能够生成更加细腻、逼真的视频内容;在计算效率上,Wan2.2能够在更低的硬件资源消耗下实现更快的生成速度;在功能多样性上,Wan2.2提供了多种生成模式和美学控制功能,能够满足用户在不同场景下的创作需求。总体而言,通义万相Wan2.2在当前的AI视频生成领域中具有较强的竞争力。
六、快速使用
(一)环境准备
在开始使用通义万相Wan2.2之前,需要先准备好相应的开发环境。建议使用Python 3.8及以上版本,并确保安装了PyTorch 2.4.0及以上版本。此外,还需要安装一些依赖库,可以通过以下命令进行安装:
pip install -r requirements.txt
(二)模型下载
通义万相Wan2.2提供了多种模型可供选择,用户可以根据自己的需求下载相应的模型。例如,下载5B参数的统一视频生成模型(Wan2.2-TI2V-5B),可以通过以下命令进行下载:
pip install "huggingface_hub[cli]"
huggingface-cli download Wan-AI/Wan2.2-TI2V-5B --local-dir ./Wan2.2-TI2V-5B
或者使用ModelScope进行下载:
pip install modelscope
modelscope download Wan-AI/Wan2.2-TI2V-5B --local_dir ./Wan2.2-TI2V-5B
(三)文生视频(Text-to-Video)生成实践
以生成一段描述为“一只猫在草地上奔跑”的视频为例,用户可以使用以下命令进行生成:
python generate.py --task ti2v-5B --size 1280*704 --ckpt_dir ./Wan2.2-TI2V-5B --offload_model True --convert_model_dtype --t5_cpu --prompt "一只猫在草地上奔跑"
在执行该命令后,模型会根据输入的文本描述生成相应的视频内容,并将其保存在指定的路径下。用户可以通过调整--size参数来设置生成视频的分辨率,通过调整--prompt参数来输入不同的文本描述,从而生成不同内容的视频。
(四)图生视频(Image-to-Video)生成实践
如果用户想要根据一张图片生成视频,可以使用以下命令:
python generate.py --task ti2v-5B --size 1280*704 --ckpt_dir ./Wan2.2-TI2V-5B --offload_model True --convert_model_dtype --t5_cpu --image examples/i2v_input.JPG --prompt "描述图片内容的文本"
(五)统一视频生成(Text-Image-to-Video)实践
结合文本和图片生成视频时,用户可以使用以下命令:
python generate.py --task ti2v-5B --size 1280*704 --ckpt_dir ./Wan2.2-TI2V-5B --offload_model True --convert_model_dtype --t5_cpu --image examples/i2v_input.JPG --prompt "结合文本和图片描述的详细内容"
通过同时输入文本描述和图片,模型能够生成更加精准、更具表现力的视频内容。用户可以根据自己的创作需求,灵活地调整文本和图片的输入内容,以生成满足特定需求的视频作品。
(六)多GPU推理
对于需要更高生成速度的场景,通义万相Wan2.2支持多GPU推理。用户可以通过以下命令进行多GPU推理:
torchrun --nproc_per_node=8 generate.py --task ti2v-5B --size 1280*704 --ckpt_dir ./Wan2.2-TI2V-5B --dit_fsdp --t5_fsdp --ulysses_size 8 --image examples/i2v_input.JPG --prompt "描述内容"
在该命令中,--nproc_per_node参数用于指定每个节点上的GPU数量,--ulysses_size参数用于指定分布式训练的规模。通过多GPU推理,可以显著加快视频生成的速度,提高模型的运行效率。
七、结语
通义万相Wan2.2作为阿里巴巴开源的先进AI视频生成模型,凭借其强大的技术实力和丰富的功能特性,为AI视频生成领域带来了新的突破。无论是创作者、广告公司、教育机构还是影视制作团队,都可以通过使用通义万相Wan2.2,快速生成高质量的视频内容,提升创作效率和作品质量。随着技术的不断发展和优化,相信通义万相Wan2.2将在更多的领域发挥重要作用,为视频创作带来更多的可能性和创新。感兴趣的读者可以通过以下
项目地址
- GitHub仓库:https://github.com/Wan-Video/Wan2.2
- HuggingFace模型库:https://huggingface.co/Wan-AI/models

















 400
400

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









