







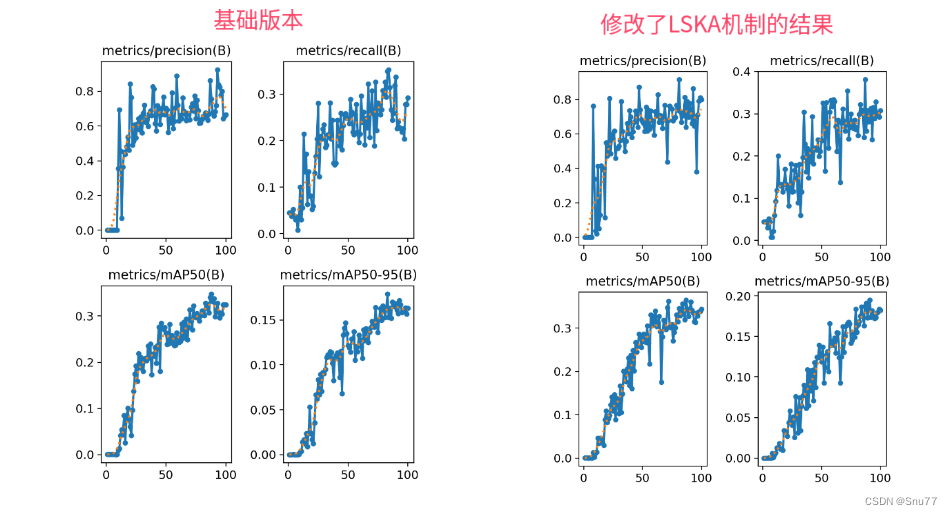
 本文介绍了如何将LSKAttention大核注意力机制应用于RT-DETR,以提升目标检测的效率和准确性。LSKAttention通过分解2D卷积核为1D卷积核,减少计算复杂性和内存占用。文章提供了详细的修改教程,包括修改ResNet主干网络和即插即用的方案,以及适用于ResNet18、50和HGNetV2的yaml配置文件。实验证明,LSKAttention能有效提高RT-DETR的性能。
本文介绍了如何将LSKAttention大核注意力机制应用于RT-DETR,以提升目标检测的效率和准确性。LSKAttention通过分解2D卷积核为1D卷积核,减少计算复杂性和内存占用。文章提供了详细的修改教程,包括修改ResNet主干网络和即插即用的方案,以及适用于ResNet18、50和HGNetV2的yaml配置文件。实验证明,LSKAttention能有效提高RT-DETR的性能。
一、本文介绍
在这篇文章中,我们将讲解如何将LSKAttention大核注意力机制应用于RT-DETR,以实现显著的性能提升。首先,我们介绍LSKAttention机制的基本原理,它主要通过将深度卷积层的2D卷积核分解为水平和垂直1D卷积核,减少了计算复杂性和内存占用。接着,我们介绍将这一机制整合到RT-DETR的方法,以及它如何帮助提高处理大型数据集和复杂视觉任务的效率和准确性。本文改进是基于ResNet18、ResNet34、ResNet50、ResNet101,文章中均以提供,本专栏的改进内容全网独一份深度改进RT-DETR非那种无效Neck部分改进,同时本文的改进也支持主干上的即插即用,本文内容也支持PP-HGNetV2版本的修改。
目录
四、手把手教你将LSKAttention添加到你的网络结构中
4.1 修改Basicclock/Bottleneck的教程
5.1 替换ResNet的yaml文件1(ResNet18版本)

 订阅专栏 解锁全文
订阅专栏 解锁全文


















 1926
1926

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











