







一、本文介绍
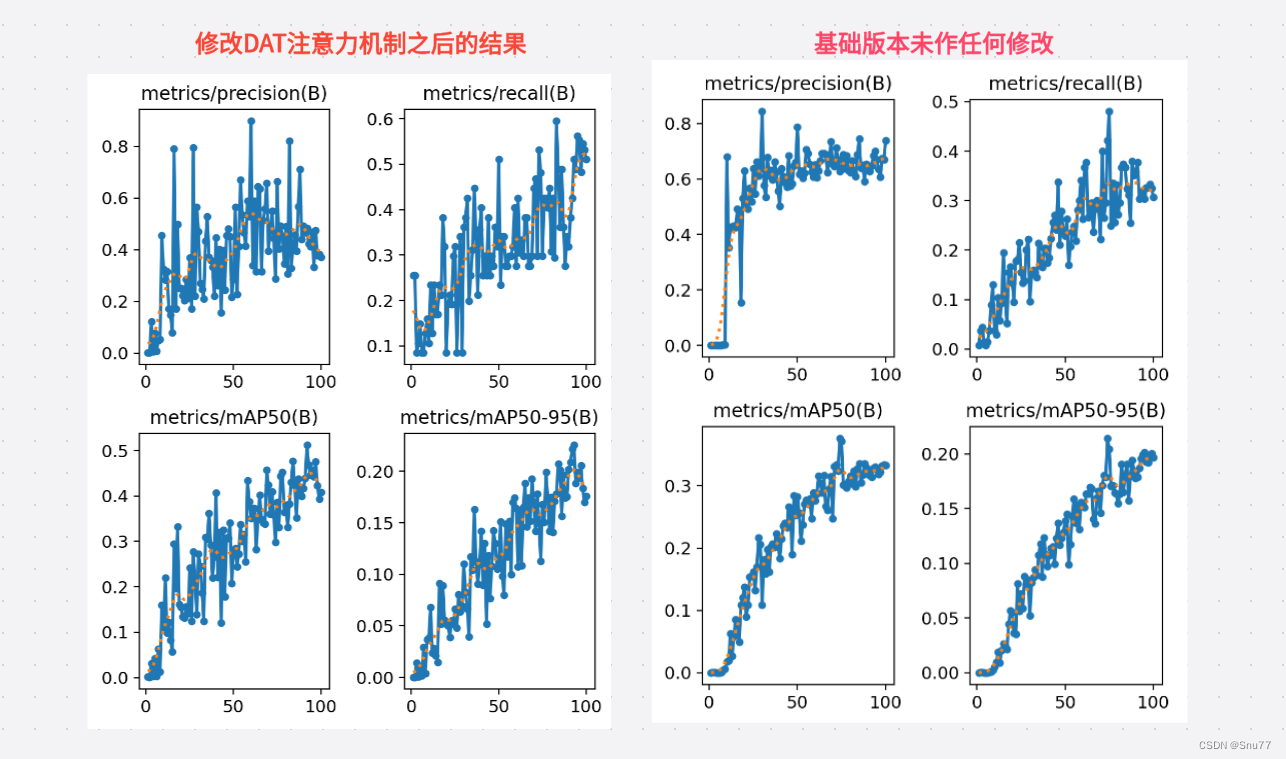
本文给大家带来的是RT-DETR改进DAT(Vision Transformer with Deformable Attention)的教程,其发布于2022年CVPR2022上同时被评选为Best Paper,由此可以证明其是一种十分有效的改进机制,其主要的核心思想是:引入可变形注意力机制和动态采样点(听着是不是和可变形动态卷积DCN挺相似)。本文的讲解主要包含三方面:DAT的网络结构思想、DAttention的代码复现,如何添加DAttention到你的结构中实现涨点,本文改进是基于ResNet18、ResNet34、ResNet50、ResNet101,文章中均以提供,本专栏的改进内容全网独一份深度改进RT-DETR非那种无效Neck部分改进,同时本文的改进也支持主干上的即插即用,本文内容也支持PP-HGNetV2版本的修改。
二、DAT的网络结构思想

论文地址: DAT论文地址
官方地址:官方代码的地址

2.1 DAT的主要思想和改进
DAT(Vision Transformer with Deformable Attention)是一种引入了可变形注意力机制的视觉Transformer,DAT的核心思想主要包括以下几个方面:
-
可变形注意力(Deformable Attention):传统的Transformer使用标准的自注意力机制,这种机制会处理图像中的所有像素,导致计算量很大。而DAT引入了可变形注意力机制,它只关注图像中的一小部分关键区域。这种方法可以显著减少计算量,同时保持良好的性能。
-
动态采样点:在可变形注意力机制中,DAT动态地选择采样点,而不是固定地处理整个图像。这种动态选择机制使得模型可以更加集中地关注于那些对当前任务最重要的区域。
-
即插即用:DAT的设计允许它适应不同的图像大小和内容,使其在多种视觉任务中都能有效工作,如图像分类、对象检测等。
总结:DAT通过引入可变形注意力机制,改进了视觉Transformer的效率和性能,使其在处理复杂的视觉任务时更加高效和准确。
2.2 DAT的网络结构图

(a) 展示了可变形注意力的信息流。左侧部分,一组参考点均匀地放置在特征图上,这些点的偏移量是由查询通过偏移网络学习得到的。然后,如右侧所示,根据变形点从采样特征中投影出变形的键和值。相对位置偏差也通过变形点计算,增强了输出转换特征的多头注意力。为了清晰展示,图中仅显示了4个参考点,但在实际实现中实际上有更多的点。
(b) 展示了偏移生成网络的详细结构,每层输入和输出特征图的大小都有标注(这个Offset network在网络的代码中需要控制可添加可不添加)。
通过上面的方式产生多种参考点分布在图像上,从而提高检测的效率,最终的效果图如下->

2.3 DAT和其他机制的对比
DAT与其他视觉Transformer模型和CNN模型中的DCN(可变形卷积网络)的对比图如下,突出了它们处理查询的不同方法(图片展示的很直观,不给大家描述过程了):

三、DAT即插即用的代码块
下面的代码是DAT的网络结构代码,官方的代码中存在许多bug而且参数都未定义,这里我替大家都行了修改而且在使用时无需手动添加任何参数(但是本文的方法需要按照有参的注意力机制添加但是只是不需要进行传入参数在yaml文件中,ya'm),我都设置了通过模型进行了自动计算,使用方法看章节四。
import numpy as np
import torch
import torch.nn as nn
import einops
from timm.models.layers import trunc_normal_
__all__ = ['DAttentionBaseline', 'BasicBlock_DAT', 'BottleNeck_DAT']
class LayerNormProxy(nn.Module):
def __init__(self, dim):
super().__init__()
self.norm = nn.LayerNorm(dim)
def forward(self, x):
x = einops.rearrange(x, 'b c h w -> b h w c')
x = self.norm(x)
return einops.rearrange(x, 'b h w c -> b c h w')
class DAttentionBaseline(nn.Module):
def __init__(
self, q_size=(224, 224), kv_size=(224, 224), n_heads=8, n_head_channels=32, n_groups=1,
attn_drop=0.0, proj_drop=0.0, stride=1,
offset_range_factor=-1, use_pe=True, dwc_pe=True,
no_off=False, fixed_pe=False, ksize=9, log_cpb=False
):
super().__init__()
n_head_channels = int(q_size / 8)
q_size = (q_size, q_size)
self.dwc_pe = dwc_pe
self.n_head_channels = n_head_channels
self.scale = self.n_head_channels ** -0.5
self.n_heads = n_heads
self.q_h, self.q_w = q_size
# self.kv_h, self.kv_w = kv_size
self.kv_h, self.kv_w = self.q_h // stride, self.q_w // stride
self.nc = n_head_channels * n_heads
self.n_groups = n_groups
self.n_group_channels = self.nc // self.n_groups
self.n_group_heads =  最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 1496
1496

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











