







 本文介绍了Triplet Attention机制,一种用于深度学习目标检测模型RT-DETR的多维度注意力机制。该机制通过三个分支关注图像的宽度、高度和深度,增强模型对特征的理解。文章提供了详细的原理、代码实现和修改教程,适用于ResNet和HGNetV2等模型,旨在提高模型性能。
本文介绍了Triplet Attention机制,一种用于深度学习目标检测模型RT-DETR的多维度注意力机制。该机制通过三个分支关注图像的宽度、高度和深度,增强模型对特征的理解。文章提供了详细的原理、代码实现和修改教程,适用于ResNet和HGNetV2等模型,旨在提高模型性能。
一、本文介绍
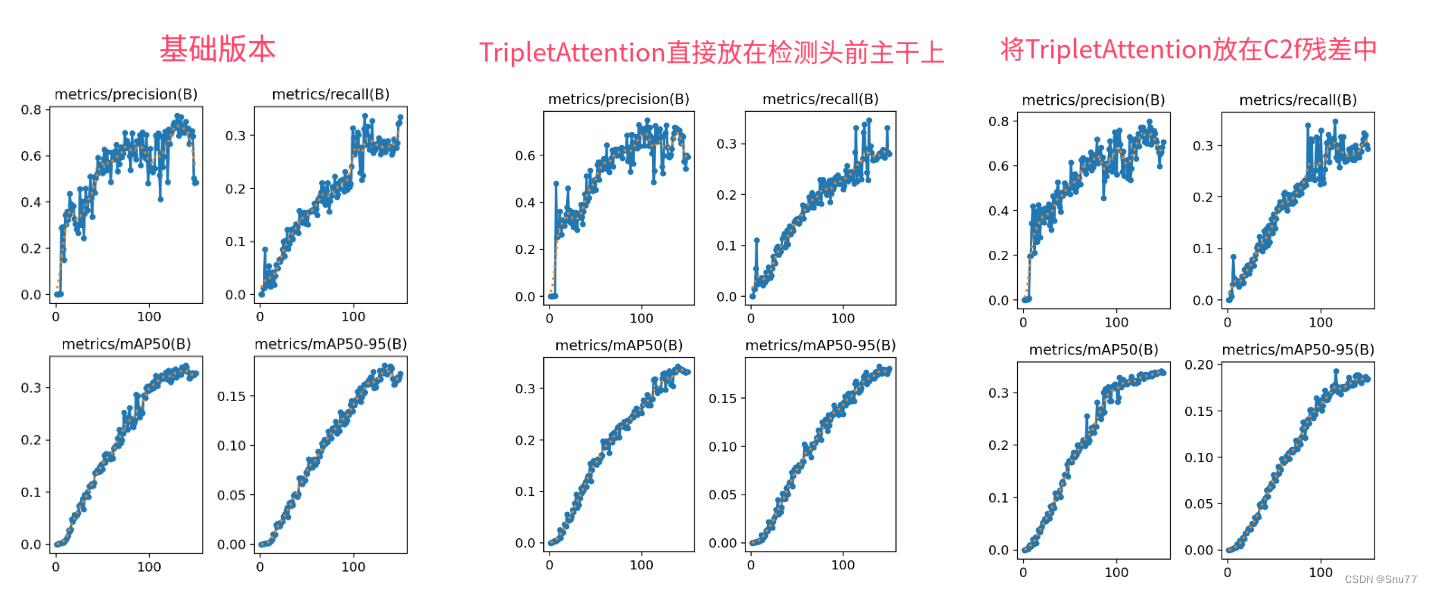
本文给大家带来的改进是Triplet Attention三重注意力机制。这个机制,它通过三个不同的视角来分析输入的数据,就好比三个人从不同的角度来观察同一幅画,然后共同决定哪些部分最值得注意。三重注意力机制的主要思想是在网络中引入了一种新的注意力模块,这个模块包含三个分支,分别关注图像的不同维度。比如说,一个分支可能专注于图像的宽度,另一个分支专注于高度,第三个分支则聚焦于图像的深度,即色彩和纹理等特征。这样一来,网络就能够更全面地理解图像内容,就像是得到了一副三维眼镜,能够看到图片的立体效果一样。本文改进是基于ResNet18、ResNet34、ResNet50、ResNet101,文章中均以提供,本专栏的改进内容全网独一份深度改进RT-DETR非那种无效Neck部分改进,同时本文的改进也支持主干上的即插即用,本文内容也支持PP-HGNetV2版本的修改。
目录
2.2 Triplet Attention和其它简单注意力机制的对比
4.1 修改Basicclock/Bottleneck的教程
5.1 替换ResNet的yaml文件1(ResNet18版本)

 订阅专栏 解锁全文
订阅专栏 解锁全文


















 6678
6678

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











