







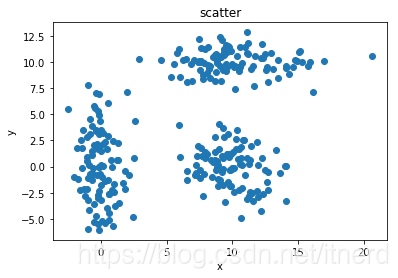
 本文介绍了一种生成三维数据集群的方法,通过使用numpy库创建具有不同均值和协方差矩阵的多元正态分布数据集。这些数据集被合并成一个大型数据集,代表三个不同的集群。此外,还提供了将生成的数据保存到文件、从文件加载数据以及使用matplotlib库进行数据可视化的函数。通过这些函数,可以直观地看到三个集群在二维平面上的分布。
本文介绍了一种生成三维数据集群的方法,通过使用numpy库创建具有不同均值和协方差矩阵的多元正态分布数据集。这些数据集被合并成一个大型数据集,代表三个不同的集群。此外,还提供了将生成的数据保存到文件、从文件加载数据以及使用matplotlib库进行数据可视化的函数。通过这些函数,可以直观地看到三个集群在二维平面上的分布。
import numpy as np
import matplotlib.pyplot as plt
def gen_clusters():
mean1 = [0,0]
cov1 = [[1,0],[0,10]]
data = np.random.multivariate_normal(mean1,cov1,100)
mean2 = [10,10]
cov2 = [[10,0],[0,1]]
data = np.append(data,
np.random.multivariate_normal(mean2,cov2,100),
0)
mean3 = [10,0]
cov3 = [[3,0],[0,4]]
data = np.append(data,
np.random.multivariate_normal(mean3,cov3,100),
0)
return np.round(data,4)
def save_data(data,filename):
with open(filename,'w') as file:
for i in range(data.shape[0]):
file.write(str(data[i,0])+','+str(data[i,1])+'\n')
def load_data(filename):
data = []
with open(filename,'r') as file:
for line in file.readlines():
data.append([ float(i) for i in line.split(',')])
return np.array(data)
def show_scatter(data):
x,y = data.T
plt.scatter(x,y)
plt.axis()
plt.title("scatter")
plt.xlabel("x")
plt.ylabel("y")
data = gen_clusters()
save_data(data,'3clusters.txt')
d = load_data('3clusters.txt')
show_scatter(d)



















 1万+
1万+







 到【灌水乐园】发言
到【灌水乐园】发言









