



使用R语言对糖尿病女性患者进行预测分析
6.1 引言
这项工作旨在检测糖尿病以及预测皮马印第安女性数据集中的糖尿病风险。皮马人属于美洲印第安血统。本研究使用的框架是RStudio,采用R编程语言。选择R框架是因为其在数据分析与可视化中发挥着重要作用,而RStudio提供了一种支持机器学习和可视化的统计工具,该语言易于学习、代码密度高、开源且免费,安装简便,并能提供 sophisticated 的结果。此外,它拥有强大的网络支持。RStudio的一个显著特点是可与Spark和Hadoop集成,从而能够处理大数据集。因此,在研究心脏病发作、肝衰竭、肾衰竭和神经损伤等多种相关健康问题的成因时,可以同时处理大数据和所需的分析任务。
现代生活方式导致了糖尿病这一严重问题,该疾病涉及高血糖水平和血液循环不良。患有糖尿病的女性免疫力较差,降低了身体抵抗感染的能力。糖尿病是许多其他健康问题的主要因素,如心脏病发作、肥胖、神经损伤、肾衰竭、肝衰竭、高血压、视力丧失以及多囊卵巢综合征(PCOS)。由于胰岛素抵抗性日益增加,目前多囊卵巢综合征(PCOS)在女性中的发病率越来越高。因此,即使是青少年患糖尿病的风险也在上升。这种情况还会导致妊娠期间的问题。因此,糖尿病的检测与预测对于提供更好的医疗服务至关重要,尤其是针对女性。
6.1.1 1型糖尿病
1型糖尿病,即身体不产生胰岛素,更常发生于儿童中,通常被称为青少年糖尿病。在这种情况下,产生胰岛素的胰腺β细胞被身体破坏。常见症状包括体重减轻、脱水以及对肝脏和肾脏等身体部位的损伤、视力丧失、尿路感染,以及其他许多问题。
6.1.2 2型糖尿病 [1]
2型糖尿病通常发生在老年人中。男性和女性都可能患上2型糖尿病,但某些症状如尿路感染、多囊卵巢综合征、阴道念珠菌病更易影响女性。在2型糖尿病中,血液中存在过量的葡萄糖未能被消耗。该类型糖尿病的病因包括超重、缺乏运动、遗传因素等。与糖尿病相关的疾病包括糖尿病视网膜病变、糖尿病神经病变、肝脏功能异常、多囊卵巢综合征、胃轻瘫和不孕症。在这种类型糖尿病中,高血糖会传递给未出生婴儿。
6.1.3 妊娠期糖尿病
这种糖尿病是孕妇特有的,通常在妊娠后期发生。通过葡萄糖耐量试验对孕妇进行妊娠期糖尿病的筛查。在大多数女性中,这种类型的糖尿病在妊娠结束后会消失。
6.2 文献综述
本研究使用的数据集最初由国家糖尿病、消化和肾脏疾病研究所发布。准确诊断女性糖尿病非常重要,为此已开发出各种工具并确定了风险因素。然而,目前尚无能够以较高准确率预测或检测女性糖尿病的显著性研究 [2–10]。根据调查,全球有4.22亿人患有糖尿病;到2035年,这一数字可能上升至5.92亿。每个国家中2型糖尿病患者人数都在增加;85%的糖尿病患者生活在欠发达国家和发展中国家。糖尿病患者中人数最多的是40至59岁人群,其中1.75亿糖尿病患者未被确诊。2013年,糖尿病导致510万死亡病例;每6秒就有一人死于糖尿病。>21百万例活产在2013年受到妊娠期糖尿病的影响。
对女性而言,妊娠是一个附加因素,在妊娠期间,母亲过高的血糖也会转移至胎儿。因此,患有糖尿病的母亲所生婴儿通常比其他婴儿体型更大。过多的血糖会导致婴儿体内产生更多的胰岛素,从而引起组织增加和脂肪沉积。
与男性相比,糖尿病对女性的影响往往不同,这主要是因为两性之间的激素变化和炎症差异所致。根据世界卫生组织的标准,餐后2小时血浆葡萄糖水平达到或超过200毫克/分升的女性患有糖尿病 [11]。
许多人已利用数据挖掘技术开发预测模型来预测糖尿病 [3]。本段将介绍一些使用数据挖掘技术开发的模型。阿卜杜拉等人 [1] 基于回归的数据挖掘支持向量机(SVM)开展了糖尿病治疗的预测分析。云生等人采用K近邻算法(KNN),去除了离群值/袋外(outlier/OOB),并在该研究中最小化了存储空间。在移除影响较小的参数后,研究人员获得了更高的准确率。尼拉什等人 [12] 采用了分类与回归树(CART)分析、聚类算法(主成分分析,PCA)以及期望最大化(EM)技术。他们发现,通过CART去除噪声后生成的一些模糊规则在预测中是有效的。维利德·法尼·库马尔等人 [13] 使用多种数据挖掘技术分析糖尿病数据,如朴素贝叶斯、J48(C4.5)、JRip、神经网络、决策树、K近邻算法、模糊逻辑和遗传算法,并基于准确率和时间进行评估。他们发现,在各种数据挖掘技术中,J48(C4.5)耗时最少。鲁帕·巴格迪等人 [2] 开发了一种决策支持系统,结合了在线分析处理(OLAP)和数据挖掘的优势。该系统可预测未来状态,并为有效决策生成有用信息。他们还比较了ID3和C4.5决策树算法的结果。该系统能够发现数据中的隐藏模式,增强实时指标,识别障碍,并改善信息可视化效果。拉杰什等人 [3] 开展了糖尿病临床数据的分类研究,并预测患者患糖尿病的可能性。用于数据挖掘分类的训练数据集为皮马印第安人糖尿病数据库。他们应用了多种分类技术,发现C4.5分类算法是对此数据集进行分类的最佳算法。卡瓦基奥蒂斯等人 [4] 发现机器学习算法对于预测包括糖尿病疾病数据集(DDD)在内的不同医疗数据集非常重要。在他们的研究中,使用支持向量机(SVM)、逻辑回归和朴素贝叶斯,并采用10折交叉验证。研究人员得出结论:支持向量机(SVM)算法提供了最佳准确率。这些研究人员均成功分析了糖尿病数据集并开发出了良好的预测模型。但他们大多数使用Weka和Oracle数据挖掘器等数据挖掘工具,少数人使用Tanagra和Orange等工具。本章节描述了尝试使用R语言分析糖尿病数据集的过程。
6.3 提出的工作
如前所述,本研究使用的数据集是国家糖尿病、消化和肾脏疾病研究所发布的皮马印第安人糖尿病数据库中的女性数据。该数据库包含年龄大于20岁的女性的诊断信息。此数据库共有768名女性,其中268名被诊断患有糖尿病。
样本由8个属性值和两个可能的结果值组成,即患者是否糖尿病检测呈阳性(以输出1表示)或阴性(以0表示)。该数据集已使用R语言进行评估。图6.1展示了所提出系统的架构。
糖尿病数据集通过加载到R语言中作为系统输入。原始数据是一个逗号分隔值(CSV)文件,看起来杂乱无章。但对该数据集进行适当评估后,揭示了一些有趣的事实。将原始数据输入R语言后,该数据集根据不同属性进行了分析和划分;从R语言获得的输出是格式良好的数据。R语言是用于统计计算以及生成图形的最佳语言之一。由于我们知道图片胜于文字,因此在评估之后,使用R语言为每个数据集生成了图形,然后对数据进行了绘图。提出的工作的分析如图6.1所示。提出的工作将在下一节中讨论。
6.3.1 属性
提出的工作使用了皮马印第安女性糖尿病数据集,该数据集主要关注女性健康。此处收集了768个年龄超过20岁的女性的实例,并定义了各种参数。
此处定义的属性为:
1. 妊娠发生次数
2. 口服葡萄糖耐量试验中2小时的血浆葡萄糖浓度
3. 舒张压(毫米汞柱)
4. 三头肌皮褶厚度(毫米)2‐h血清胰岛素(μU/mL)
5. 体重指数(体重kg/身高m²)
6. 糖尿病家族史函数
7. 年龄(岁)
8. 类别变量(0或1)
- 0—表示糖尿病测试阴性
- 1—表示糖尿病测试阳性
6.3.2 预测模型
6.3.2.1 逻辑回归模型
逻辑回归是一种常见且有用的回归方法,适用于解决二分类问题。它易于实现,可作为任何二分类问题的基线模型。其基本核心概念对深度学习也有建设性意义。逻辑回归用于描述和估计一个因二元变量与自变量之间的关系。
在预测女性糖尿病的应用中,该模型以结果作为响应变量,其余八个变量作为预测变量。采用逐步变量选择方法来筛选重要变量。在此模型中,我们使用了以下代码:
library(corrplot)
library(caret)
n <- nrow(皮马)
皮马_训练 <- 皮马[训练]
实现逻辑回归模型:
glm_fm1 <- glm(结果 ~ ., 数据 = 皮马_训练, 家族 = 二项式)
step_模型 <- step(glm_fm1)
绘图(glm_fm2)
lm_probs <- predict(glm_fm2, 新数据 = 皮马_测试, 类型 = "response")
glm_预测 <- 如果否则(lm_probs > 0.5, 1, 0)
# print("logistic regression的混淆矩阵");
Table(预测 = glm_预测, 实际 = 皮马_测试$糖尿病)
混淆矩阵(glm_预测, 皮马_测试$糖尿病)
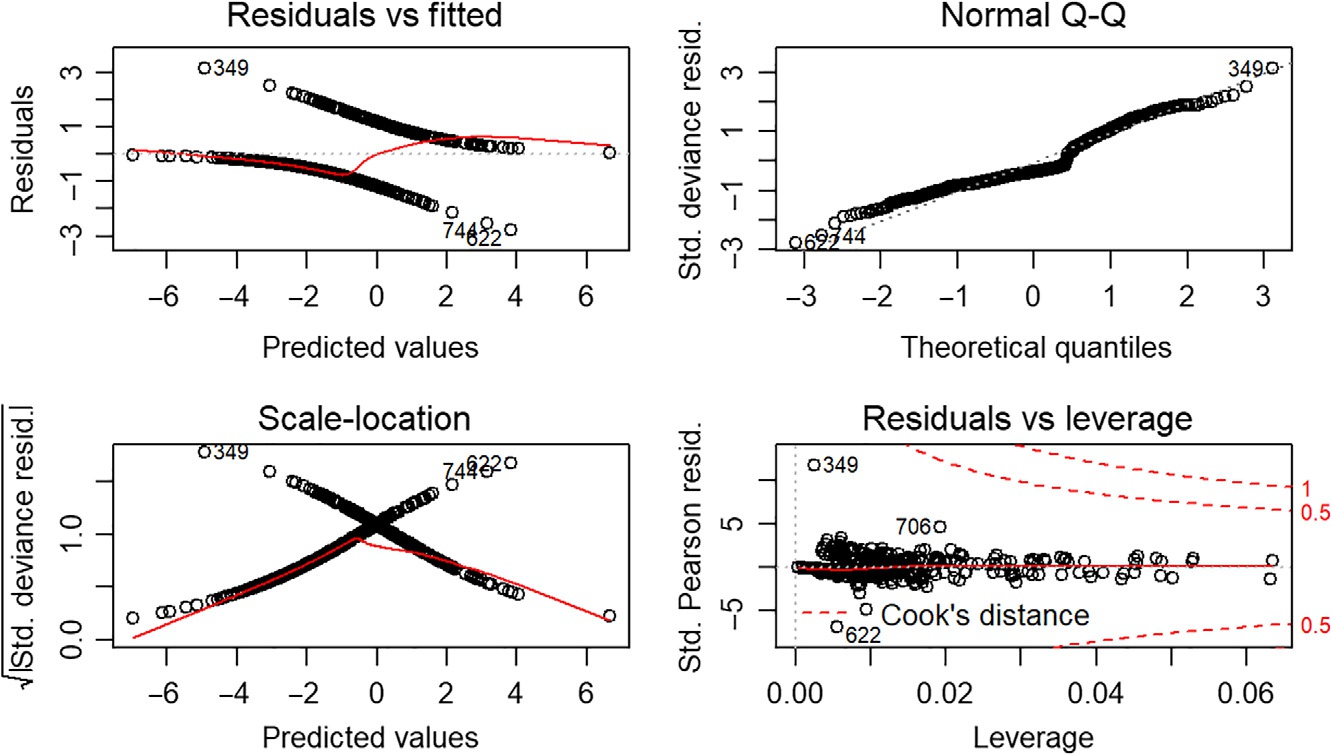
该模型使用RStudio实现,结果如图6.2所示。
6.3.2.2 决策树
决策树也是一种常用于预测的监督学习算法技术。它构成了重要的决策支持工具系统,是运筹学的重要组成部分。因此,选择决策树作为女性糖尿病症状预测的方法是恰当的。这是一个重要的步骤,因为早期预测有助于模型的建立。当响应变量为分类的时,可以使用决策树。
- 决策支持系统基于属性和条件对值进行划分,因此该图呈现出树状结构,可以从根遍历到叶,并评估预测结果。
- 在RStudio中用于实现决策树的包是party包,该包包含ctree函数,可用于创建和可视化决策树。
- 此处使用的语法为ctree(公式, 数据),其中:
- 公式:涉及预测变量和响应变量
- 数据:所用数据集的名称。
在此数据集中,决策树根据输入的预测变量值集合中最具显著性的分割点,将数据划分为两个或多个同质集合。针对使用决策树对女性进行糖尿病预测,我们采用了以下代码:
library(tree)
set.seed(1234)
intrain <- createDataPartition(y = pima$Diabetes, p = 0.7, list = FALSE)
实现决策树模型:
训练 <- pima[intrain,]
测试 <- pima[-intrain,]
树模型 <- 决策树(糖尿病 ~ ., 数据 = 训练)
绘图(树模型)
文本(树模型, 美化 = 0)
决策树_预测 <- predict(树模型, 新数据 = 测试, 类型 = "class")
混淆矩阵(决策树_预测, 测试$Diabetes)
该模型在R语言中实现,结果如图6.3所示。
6.3.2.3 随机森林模型
随机森林是一种分类方法,属于机器学习模型,通过结合弱分类器的预测结果来进行分类。它被广泛认为是处理高维数据[5]的最佳分类器。随机森林通过构建大量分类/回归树来实现其功能。每棵树在构建时使用训练数据的随机替换样本,并且在每次分裂时对每个树采用预测变量的随机替换。最终将这组大量的树结合起来以最大化性能。该方法实现快速简便,能够产生高度准确的预测结果,并且可以在不发生过拟合的情况下处理大量的输入变量。在每个节点处,通过随机选择一小部分输入坐标进行分裂,并基于训练集中的这些特征计算最佳分裂方式。决策树在生长过程中不进行剪枝。该使用R语言预测糖尿病的模型已通过以下代码实现:
设置种子(123)
加载库(RandomForest)
实现随机森林模型:
rf_probs <- predict(rf_pima, newdata = pima_testing)
rf_pred <- ifelse(rf_probs > 0.5, 1, 0)
混淆矩阵(rf_pred, pima_testing$糖尿病)
参数(mfrow = c(1, 2))
变量重要性图(rf_pima, 类型 = 2, 主标题 = "变量重要性", 颜色 = 'black')
绘图(rf_pima, 主标题 = "误差与生长的树的数量")
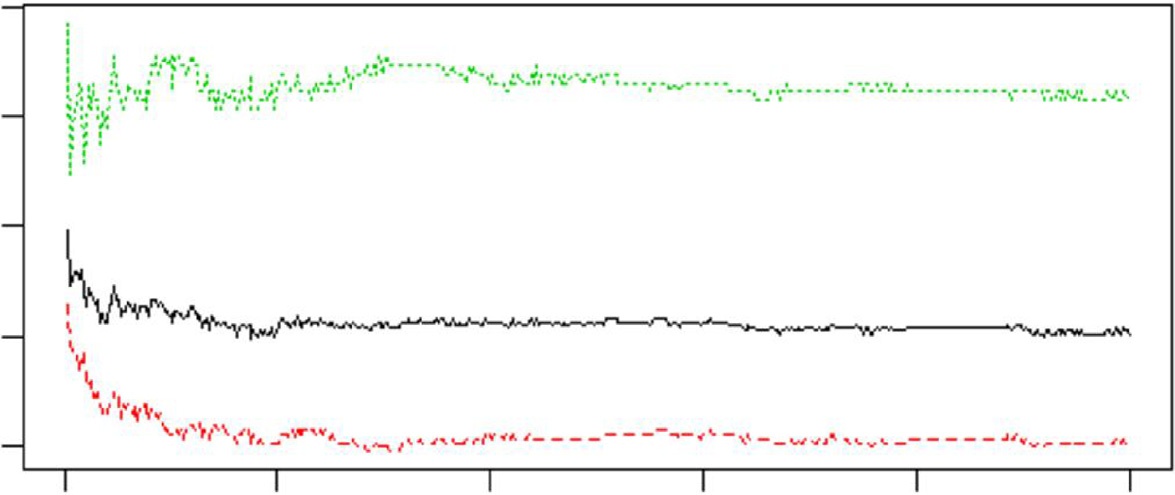
该模型在R语言中实现,结果如图6.4所示。
6.3.2.4 支持向量机
支持向量机(SVM)是一种常用于数据集分类的有监督学习技术。其目标是在训练阶段构建一个与各类别之间具有最大距离的超平面。在测试阶段,根据新实例到超平面的最大距离进行计算,从而将形成的分类扩展到多类分类。
在这种情况下,超平面的构建通过核函数构造实现。SVM易于实现,在处理包含768个实例的小数据集时也不需要很长的处理时间。e1071包在RStudio中用于实现。SVM模型使用以下代码实现:
e1071包
pima$Diabetes <- as.factor(pima$Diabetes)
实现支持向量模型:
tuned <- tune.svm(Diabetes ~ ., data = train, gamma = 10^(-6:-1), cost = 10^(-1:1))
summary(tuned) # 显示结果
svm_pred <- predict(svm_model, newdata = test)
confusionMatrix(svm_pred, test$Diabetes)
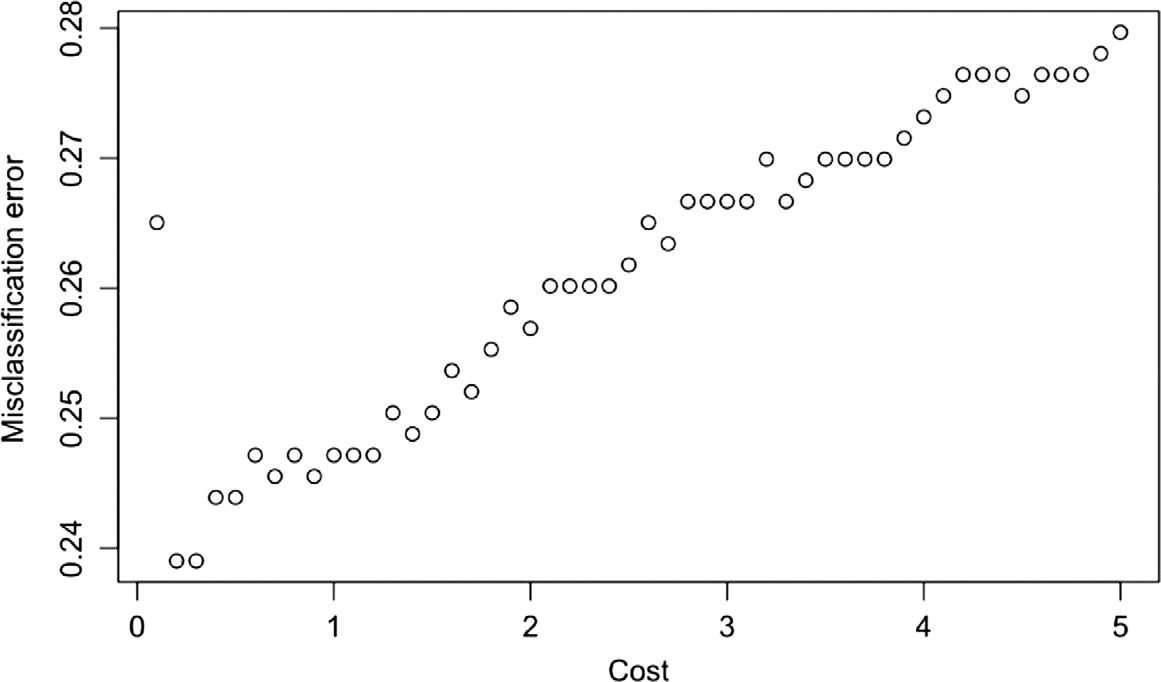
该模型在R语言中实现,结果如图6.5所示。
比较四种模型
比较四种模型——逻辑回归、决策树、随机森林和支持向量机,我们得到了以下结果:
To find the accuracy <- data.frame(模型 = c("逻辑回归", "决策树", "随机森林", "支持向量机(SVM)"),
准确率 = c(acc_glm_fit, acc_treemod, acc_rf_pima, acc_svm_model))
ggplot(准确率, aes(x = 模型, y = 准确率)) +
geom_bar(stat = 'identity') +
theme_bw() +
ggtitle('模型准确率比较')
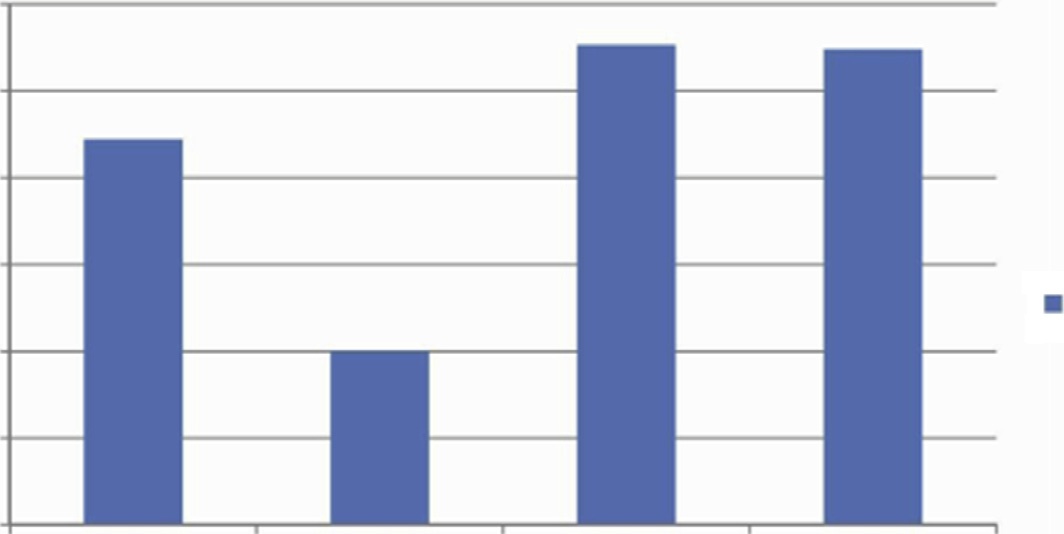
在RStudio中使用了e1071包进行实现。各预测模型之间的准确率比较如图6.6所示。在这四种预测模型中,随机森林模型表现出最高的准确率。
6.4 实验分析
图6.2中的绘图显示,逻辑回归模型绘制了所有的点,因此没有离群值。所以,逻辑回归模型拟合得非常好。错误率是25.11%,准确率是74.89%。
图6.3 显示有5个变量作为内部节点,14个变量作为终端节点,训练错误率为16.95%。测试错误率为30%,准确率为70%。
图6.4 中的绘图可视化了随机森林模型误差。红线(印刷版中的深灰色)表示预测一个人没有糖尿病的错误率,而绿线(印刷版中的浅灰色)表示预测一个人患有糖尿病的错误率。黑线表示总体错误率。该模型产生的测试错误率为22.04%,达到的准确率为77.06%;当错误率下降时,生长的树的数量增加。
图6.5 绘图展示了糖尿病预测的重要变量,即血浆葡萄糖、体重指数(BMI)和舒张压(DPF)。该图表明,当错误率降低时,生长的树的数量增加。
图6.6 显示成本参数被调整以产生最小化总体误分类错误率的最佳值。此处,测试错误率为23.04%,准确率为76.96%。
图6.7 展示了各种预测模型的准确率。在所有这些模型中,随机森林模型的准确率最高,而决策树模型的准确率最低。预测模型的准确率得到了提升。因此,随机森林模型对数据集更具适应性。
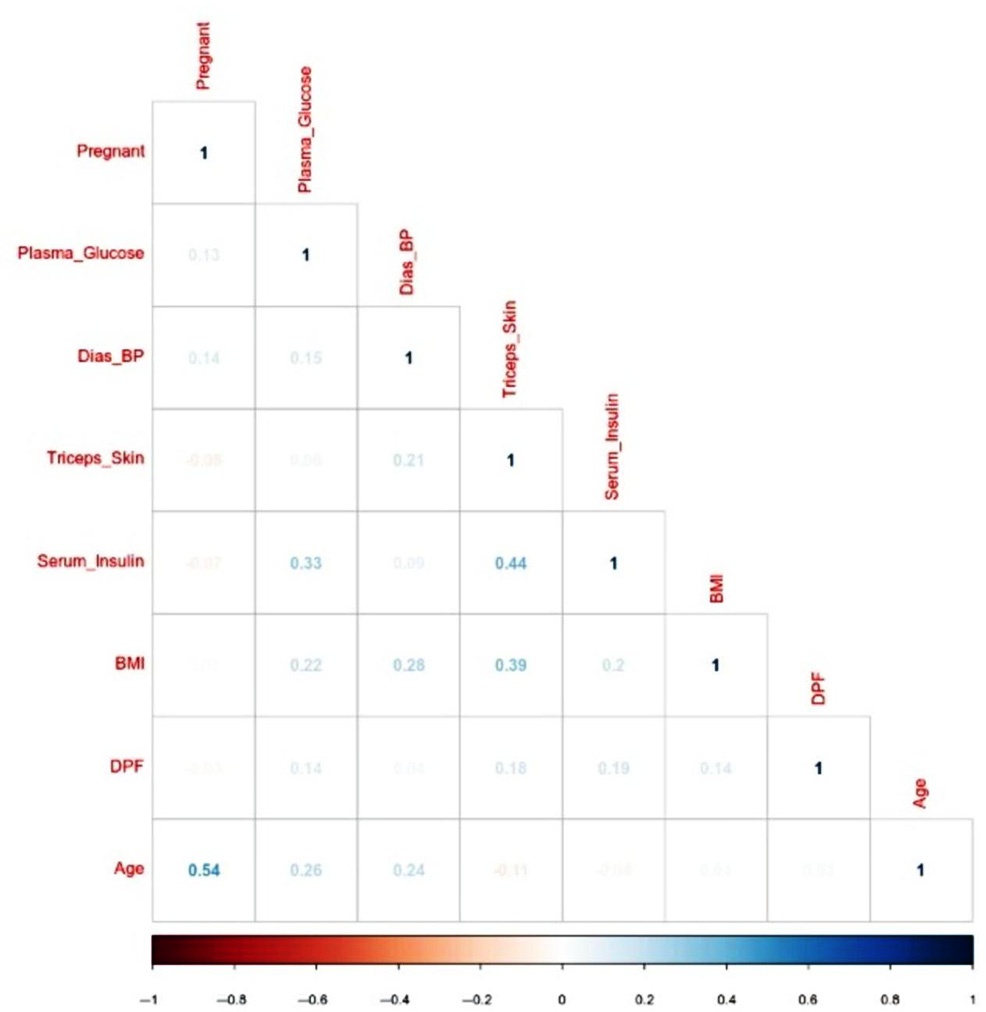
图6.8 显示了变量之间的相关性矩阵。相关性矩阵用于汇总数据,并作为更高级分析的输入。在此分析包中,R工具使用了corr。表6.1 列出了四种模型的分类准确率,分别为逻辑回归模型、决策树、随机森林模型和支持向量机(SVM),我们获得了以下结果。其中,随机森林模型的准确率最高。
表6.1 模型准确率
| 模型 | 准确率 |
|---|---|
| 逻辑回归模型 | 74.89% |
| 决策树 | 70% |
| 随机森林模型 | 77.06% |
| 支持向量机 | 76.96% |
加粗表示随机森林模型的最高准确率。
6.5 结论与未来改进
本文重点研究通过使用R语言比较多种预测模型对女性糖尿病进行分析,并结合统计意义评估其准确率。我们比较了决策树、逻辑回归模型、SVM模型和随机森林模型在分类结果上的表现。分类结果显示,随机森林模型效果最佳。该模型不仅提升了分类性能,还克服了由于数据集中缺失值所导致的过拟合问题。同时,研究也探讨了各种数据挖掘技术及其应用。
已进行审查。机器学习算法被应用于不同的医疗数据集。机器学习方法在不同数据集中具有不同的功能。在此过程中揭示的事实可用于开发一些预测模型。未来工作的可能性包括扩展研究不同类型的技巧,以回顾特征构建过程。

















 1552
1552

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









