







 超级会员免费看
超级会员免费看
 本文详细介绍了利用Java、Scala、Python、Akka、MapReduce、Hive、Storm、Spark RDD、Spark SQL、Spark Streaming和Flink等工具实现词频统计的方法,包括创建项目、数据处理、统计实现和查看结果的步骤。
本文详细介绍了利用Java、Scala、Python、Akka、MapReduce、Hive、Storm、Spark RDD、Spark SQL、Spark Streaming和Flink等工具实现词频统计的方法,包括创建项目、数据处理、统计实现和查看结果的步骤。
文章目录
- 数据文件 -
test.txt
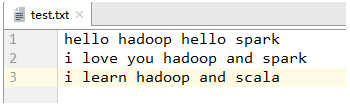
一、利用Java程序实现词频统计
(一)创建Java项目
- 创建Java项目 -
JavaWordCount
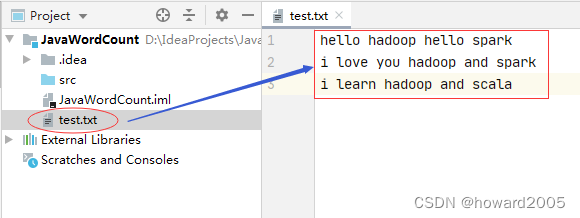
(二)创建数据文件
- 在项目根目录创建数据文件 -
test.txt
(三)创建词频统计类
- 创建
net.hw.wc包,在包里创建WordCount类
test.txtJavaWordCounttest.txtnet.hw.wc包,在包里创建WordCount类 1023
6201
675
1023
6201
675

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言





 订阅专栏 解锁全文
订阅专栏 解锁全文


























