




一、大模型怎么识别图片?图片怎么token化?
图片识别的核心原理
从像素到理解:视觉特征的层次化提取
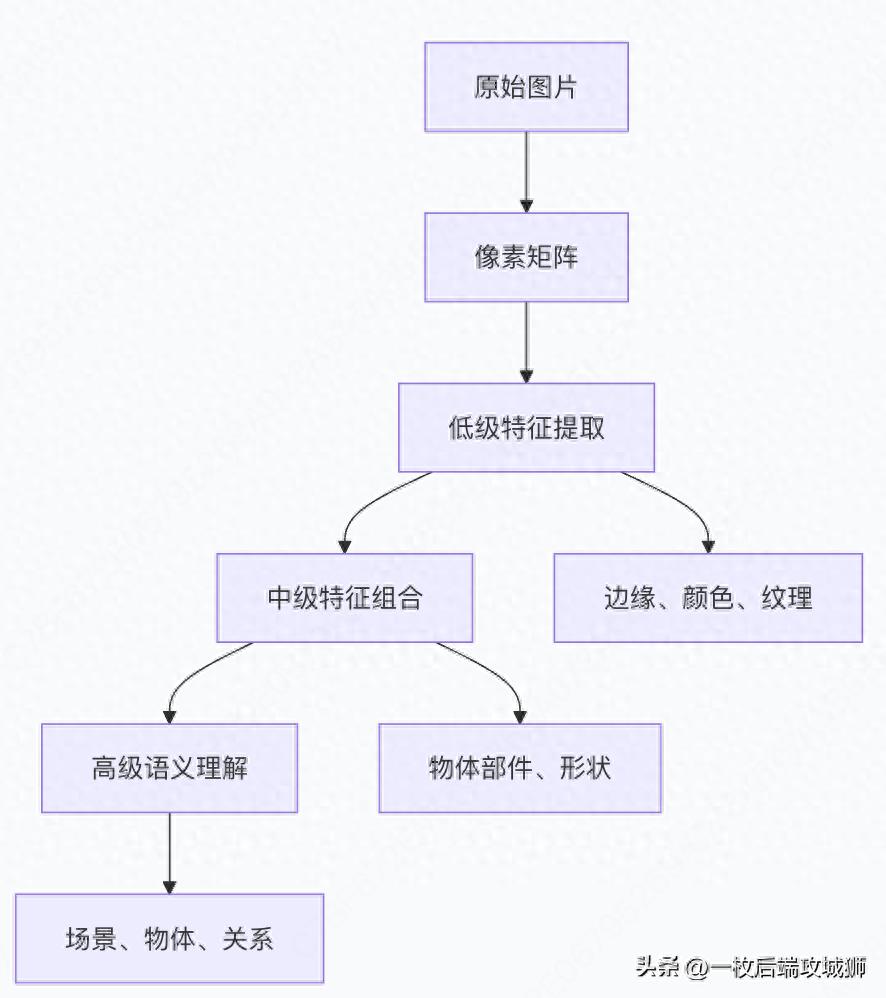
图片token化:将视觉信息"语言化"
传统方法 vs 现代方法
# 图片token化的不同策略对比
image_tokenization_methods = {
"传统CNN方法": {
"过程": "卷积层提取特征 → 全连接层分类",
"token化": "没有明确的token概念",
"局限性": "缺乏位置信息,难以处理复杂关系"
},
"Vision Transformer方法": {
"过程": "分块 → 线性投影 → 位置编码 → Transformer",
"token化": "每个图像块成为一个token",
"优势": "保持空间关系,可扩展性强"
},
"VQ-VAE方法": {
"过程": "编码 → 离散化 → 解码",
"token化": "使用码本中的离散索引作为token",
"应用": "DALL-E第一代使用"
}
}
Vision Transformer的图片token化详解
分块处理过程:
import torch
import torch.nn as nn
import numpy as np
class ImageToTokens(nn.Module):
"""将图片转换为token序列"""
def __init__(self, image_size=224, patch_size=16, hidden_dim=768):
super().__init__()
self.image_size = image_size
self.patch_size = patch_size
self.hidden_dim = hidden_dim
# 计算patch数量
self.num_patches = (image_size // patch_size) ** 2
# 将patch投影到嵌入空间
self.patch_embedding = nn.Conv2d(
in_channels=3, # RGB通道
out_channels=hidden_dim,
kernel_size=patch_size,
stride=patch_size
)
# 位置编码
self.position_embeddings = nn.Parameter(
torch.randn(1, self.num_patches + 1, hidden_dim)
)
# [CLS] token
self.cls_token = nn.Parameter(torch.randn(1, 1, hidden_dim))
def forward(self, x):
"""
输入: [batch_size, 3, 224, 224]
输出: [batch_size, num_tokens, hidden_dim]
"""
batch_size = x.shape[0]
# 1. 分块并嵌入
# [batch, 3, 224, 224] -> [batch, 768, 14, 14]
x = self.patch_embedding(x)
# 展平空间维度: [batch, 768, 14, 14] -> [batch, 768, 196]
x = x.flatten(2)
# 转置: [batch, 768, 196] -> [batch, 196, 768]
x = x.transpose(1, 2)
# 2. 添加[CLS] token
cls_tokens = self.cls_token.expand(batch_size, -1, -1)
x = torch.cat([cls_tokens, x], dim=1) # [batch, 197, 768]
# 3. 添加位置编码
x = x + self.position_embeddings
return x
# 使用示例
tokenizer = ImageToTokens()
image = torch.randn(2, 3, 224, 224) # 2张224x224的RGB图片
tokens = tokenizer(image)
print(f"输入图片形状: {image.shape}")
print(f"输出token形状: {tokens.shape}") # [2, 197, 768]
生动比喻:拼图游戏理解法
- 原始图片:完整的拼图画面
- 分块处理:把拼图拆成16x16的小块
- 线性投影:为每个小块拍"身份证照片"(特征提取)
- 位置编码:记录每个小块在拼图中的原始位置
- Transformer处理:让所有小块相互交流,重建完整画面
视觉编码器的完整流程
class VisionEncoder(nn.Module):
"""完整的视觉编码器"""
def __init__(self, config):
super().__init__()
self.tokenizer = ImageToTokens(
image_size=config.image_size,
patch_size=config.patch_size,
hidden_dim=config.hidden_dim
)
# Transformer编码器层
self.transformer_layers = nn.ModuleList([
TransformerLayer(config) for _ in range(config.num_layers)
])
self.layer_norm = nn.LayerNorm(config.hidden_dim)
def forward(self, images):
# 图片转换为token
tokens = self.tokenizer(images)
# 通过Transformer层
for layer in self.transformer_layers:
tokens = layer(tokens)
# 最终归一化
tokens = self.layer_norm(tokens)
return tokens
class TransformerLayer(nn.Module):
"""标准的Transformer编码器层"""
def __init__(self, config):
super().__init__()
self.attention = nn.MultiheadAttention(
config.hidden_dim,
config.num_heads,
batch_first=True
)
self.mlp = nn.Sequential(
nn.Linear(config.hidden_dim, config.mlp_dim),
nn.GELU(),
nn.Linear(config.mlp_dim, config.hidden_dim)
)
self.norm1 = nn.LayerNorm(config.hidden_dim)
self.norm2 = nn.LayerNorm(config.hidden_dim)
def forward(self, x):
# 自注意力
residual = x
x = self.norm1(x)
attn_output, _ = self.attention(x, x, x)
x = residual + attn_output
# 前馈网络
residual = x
x = self.norm2(x)
ff_output = self.mlp(x)
x = residual + ff_output
return x
二、怎么根据文字生成图片?
文本到图像的生成范式演进
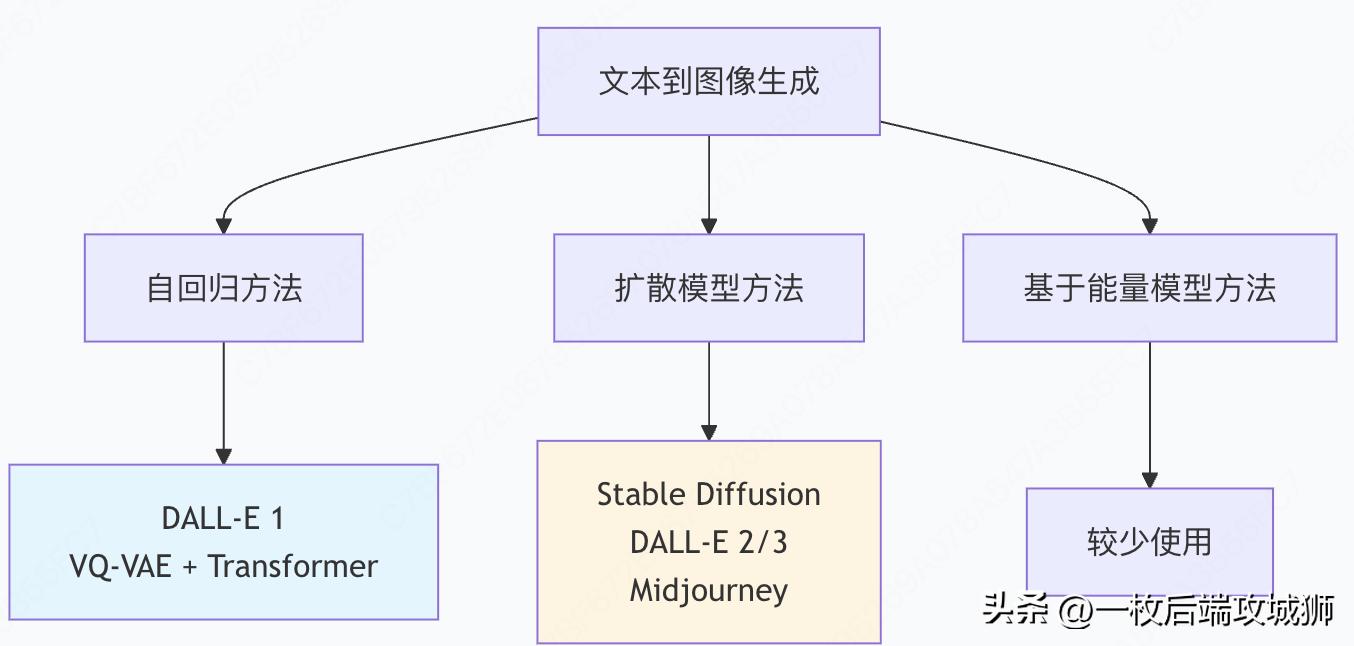
1. 自回归方法:DALL-E 1的原理
VQ-VAE + Transformer架构
class DALL_E_Like_Model(nn.Module):
"""类似DALL-E 1的自回归生成模型"""
def __init__(self, vocab_size, text_vocab_size, hidden_dim):
super().__init__()
# 视觉部分:VQ-VAE
self.vq_vae = VQVAE(vocab_size=vocab_size)
# 文本编码器
self.text_encoder = TextEncoder(vocab_size=text_vocab_size)
# 自回归Transformer
self.transformer = TransformerDecoder(
vocab_size=vocab_size,
hidden_dim=hidden_dim
)
def forward(self, text_tokens, image_tokens=None):
# 编码文本
text_embeddings = self.text_encoder(text_tokens)
if image_tokens is not None:
# 训练时:预测下一个图像token
logits = self.transformer(image_tokens, text_embeddings)
return logits
else:
# 推理时:自回归生成图像tokens
return self.generate_autoregressive(text_embeddings)
def generate_autoregressive(self, text_embeddings, max_length=256):
"""自回归生成图像tokens"""
batch_size = text_embeddings.shape[0]
generated_tokens = torch.zeros(batch_size, 1, dtype=torch.long)
for i in range(max_length):
# 预测下一个token
logits = self.transformer(generated_tokens, text_embeddings)
next_token = torch.argmax(logits[:, -1:], dim=-1)
# 添加到生成序列
generated_tokens = torch.cat([generated_tokens, next_token], dim=1)
# 如果生成了结束token,提前终止
if (next_token == self.end_token).all():
break
return generated_tokens
class VQVAE(nn.Module):
"""向量量化变分自编码器"""
def __init__(self, vocab_size, hidden_dim=256):
super().__init__()
self.encoder = Encoder(hidden_dim)
self.decoder = Decoder(hidden_dim)
# 码本:将连续特征映射到离散token
self.codebook = nn.Embedding(vocab_size, hidden_dim)
self.vocab_size = vocab_size
def encode(self, x):
# 编码为连续特征
z = self.encoder(x)
# 向量量化:找到码本中最接近的向量
z_flat = z.view(-1, z.shape[-1])
distances = torch.cdist(z_flat, self.codebook.weight)
indices = torch.argmin(distances, dim=-1)
# 使用码本中的向量
z_q = self.codebook(indices).view(z.shape)
return z_q, indices
def decode(self, indices):
# 从离散token重建图像
z_q = self.codebook(indices)
return self.decoder(z_q)
2. 扩散模型方法:现代主流技术
扩散模型基本原理

Stable Diffusion架构详解
class StableDiffusionModel:
"""Stable Diffusion核心组件"""
def __init__(self):
self.text_encoder = CLIPTextModel() # 文本编码器
self.vae = AutoencoderKL() # 变分自编码器,处理图像压缩
self.unet = UNet2DConditionModel() # U-Net,去噪网络
def text_to_image(self, prompt, num_inference_steps=50, guidance_scale=7.5):
"""
文本到图像生成流程
"""
# 1. 文本编码
text_embeddings = self.encode_text(prompt)
# 2. 初始化潜空间噪声
latents = torch.randn((1, 4, 64, 64)) # 压缩的潜表示
# 3. 扩散过程(去噪)
latents = self.diffusion_denoise(latents, text_embeddings,
num_inference_steps, guidance_scale)
# 4. 解码潜空间到像素空间
image = self.vae.decode(latents)
return image
def encode_text(self, prompt):
"""使用CLIP编码文本"""
inputs = self.tokenizer(prompt, return_tensors="pt", padding=True)
text_embeddings = self.text_encoder(**inputs).last_hidden_state
return text_embeddings
def diffusion_denoise(self, latents, text_embeddings, steps, guidance_scale):
"""扩散模型去噪过程"""
# 调度器,控制噪声调度
scheduler = self.scheduler
scheduler.set_timesteps(steps)
# 无分类器引导:同时计算有条件和无条件预测
uncond_embeddings = self.encode_text("") # 空文本
text_embeddings = torch.cat([uncond_embeddings, text_embeddings])
for t in scheduler.timesteps:
# 扩展潜空间以进行无分类器引导
latent_model_input = torch.cat([latents] * 2)
latent_model_input = scheduler.scale_model_input(latent_model_input, t)
# 预测噪声
noise_pred = self.unet(latent_model_input, t,
encoder_hidden_states=text_embeddings).sample
# 分离有条件和无条件预测
noise_pred_uncond, noise_pred_text = noise_pred.chunk(2)
# 无分类器引导
noise_pred = noise_pred_uncond + guidance_scale * \
(noise_pred_text - noise_pred_uncond)
# 更新潜空间
latents = scheduler.step(noise_pred, t, latents).prev_sample
return latents
U-Net去噪网络结构
class UNet2DConditionModel(nn.Module):
"""条件U-Net,用于扩散模型去噪"""
def __init__(self):
super().__init__()
# 编码器(下采样)
self.down_blocks = nn.ModuleList([
DownBlock2D(3, 64), # 64x64
DownBlock2D(64, 128), # 32x32
DownBlock2D(128, 256), # 16x16
DownBlock2D(256, 512) # 8x8
])
# 中间块
self.mid_block = MidBlock2D(512)
# 解码器(上采样)
self.up_blocks = nn.ModuleList([
UpBlock2D(512, 256), # 16x16
UpBlock2D(256, 128), # 32x32
UpBlock2D(128, 64), # 64x64
UpBlock2D(64, 3) # 128x128
])
# 时间步嵌入
self.time_embedding = TimestepEmbedding(512)
# 文本条件嵌入
self.text_embedding = TextEmbedding(512)
def forward(self, x, timestep, encoder_hidden_states):
"""
x: 噪声潜变量 [batch, channels, height, width]
timestep: 时间步
encoder_hidden_states: 文本嵌入 [batch, seq_len, hidden_dim]
"""
# 时间步嵌入
t_emb = self.time_embedding(timestep)
# 文本条件嵌入
text_emb = self.text_embedding(encoder_hidden_states)
# 编码器路径
skip_connections = []
for down_block in self.down_blocks:
x = down_block(x, t_emb, text_emb)
skip_connections.append(x)
# 中间块
x = self.mid_block(x, t_emb, text_emb)
# 解码器路径(使用跳跃连接)
for up_block in self.up_blocks:
skip = skip_connections.pop()
x = up_block(x, skip, t_emb, text_emb)
return x
3. 生成过程的生动比喻
雕塑家的创作过程
- 文本提示:雕塑的设计蓝图
- 初始噪声:原始的石料
- 扩散过程:雕塑家逐步凿去多余部分
- U-Net:雕塑家的手艺和经验
- 文本引导:按照蓝图不断调整雕刻方向
- 最终图像:完成的雕塑作品
三、生成图片过程中怎么优化图片?
1. 采样策略优化
不同采样器对比
# 扩散模型采样策略对比
sampling_strategies = {
"DDPM": {
"类型": "随机采样",
"特点": "完全随机过程,质量高但速度慢",
"步骤": "1000步",
"适用场景": "追求最高质量"
},
"DDIM": {
"类型": "确定性采样",
"特点": "确定性过程,可插值,速度快",
"步骤": "20-50步",
"适用场景": "快速生成,可控性强"
},
"DPM-Solver": {
"类型": "快速求解器",
"特点": "数学优化,极少步数高质量",
"步骤": "10-20步",
"适用场景": "生产环境,效率优先"
},
"PLMS": {
"类型": "伪线性多步",
"特点": "平衡质量和速度",
"步骤": "20-30步",
"适用场景": "通用场景"
}
}
class SamplerOptimizer:
"""采样优化器"""
def __init__(self, sampler_type="DDIM"):
self.sampler_type = sampler_type
self.setup_sampler()
def setup_sampler(self):
if self.sampler_type == "DDIM":
self.sampler = DDIMSampler(
num_train_timesteps=1000,
beta_start=0.0001,
beta_end=0.02
)
elif self.sampler_type == "DPM_Solver":
self.sampler = DPMSolverSampler(
num_train_timesteps=1000,
thresholding=True # 防止数值不稳定
)
def optimize_sampling(self, model, latents, text_embeddings, steps=20):
"""优化采样过程"""
return self.sampler.sample(
model=model,
latents=latents,
text_embeddings=text_embeddings,
num_inference_steps=steps,
guidance_scale=7.5
)
2. 提示工程优化
提示词优化策略
class PromptOptimizer:
"""提示词优化器"""
def __init__(self):
self.templates = self.load_templates()
self.quality_boosters = [
"masterpiece", "best quality", "4K", "ultra detailed",
"sharp focus", "professional photography"
]
self.style_modifiers = {
"realistic": ["photorealistic", "realistic", "natural lighting"],
"artistic": ["painting", "oil on canvas", "artistic"],
"anime": ["anime style", "Japanese animation", "cel shading"]
}
def optimize_prompt(self, base_prompt, style="realistic", quality="high"):
"""优化提示词"""
optimized = base_prompt
# 添加质量提升词
if quality == "high":
optimized += ", " + ", ".join(self.quality_boosters[:3])
# 添加风格修饰词
if style in self.style_modifiers:
optimized += ", " + ", ".join(self.style_modifiers[style])
# 负面提示词(不希望出现的元素)
negative_prompt = "blurry, low quality, distorted, ugly"
return optimized, negative_prompt
def create_composition_prompt(self, subject, environment, lighting, mood):
"""构建构图提示词"""
template = "{subject} in {environment}, {lighting} lighting, {mood} mood"
return template.format(
subject=subject,
environment=environment,
lighting=lighting,
mood=mood
)
# 使用示例
optimizer = PromptOptimizer()
base_prompt = "a beautiful landscape with mountains"
optimized_prompt, negative = optimizer.optimize_prompt(
base_prompt, style="realistic", quality="high"
)
print(f"优化后提示: {optimized_prompt}")
print(f"负面提示: {negative}")
3. 生成后处理优化
超分辨率增强
class ImagePostProcessor:
"""图像后处理器"""
def __init__(self):
self.upscaler = RealESRGANModel() # 超分模型
self.face_enhancer = GFPGANModel() # 人脸增强
self.color_corrector = ColorCorrector()
def enhance_image(self, image, target_size=(1024, 1024), enhance_faces=True):
"""增强图像质量"""
# 1. 超分辨率放大
if image.size != target_size:
image = self.upscale_image(image, target_size)
# 2. 人脸增强(如果检测到人脸)
if enhance_faces and self.detect_faces(image):
image = self.enhance_faces(image)
# 3. 颜色校正
image = self.color_corrector.adjust_contrast(image)
image = self.color_corrector.white_balance(image)
# 4. 锐化
image = self.sharpen_image(image)
return image
def upscale_image(self, image, target_size):
"""超分辨率放大"""
# 使用Real-ESRGAN或类似模型
upscaled = self.upscaler.upscale(image, scale=4) # 4倍放大
# 调整到目标尺寸
if upscaled.size != target_size:
upscaled = upscaled.resize(target_size, Image.LANCZOS)
return upscaled
def enhance_faces(self, image):
"""增强人脸细节"""
return self.face_enhancer.enhance(image)
def sharpen_image(self, image):
"""锐化图像"""
import PIL.ImageFilter as Filter
return image.filter(Filter.SHARPEN)
4. 多阶段生成优化
从粗到细的生成策略
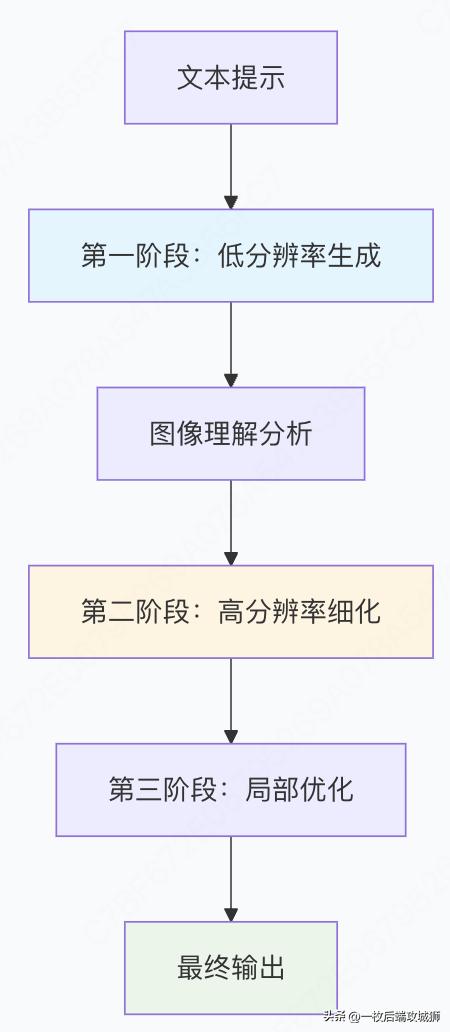
class MultiStageGenerator:
"""多阶段图像生成器"""
def __init__(self):
self.low_res_model = None # 低分辨率快速模型
self.high_res_model = None # 高分辨率精细模型
self.refinement_model = None # 局部优化模型
def generate_with_refinement(self, prompt, initial_size=256, final_size=1024):
"""多阶段生成优化"""
# 阶段1:快速低分辨率生成
print("阶段1: 快速构图生成...")
low_res_image = self.low_res_model.generate(
prompt,
size=initial_size,
num_steps=20 # 较少步数快速生成
)
# 分析生成结果
analysis = self.analyze_image_composition(low_res_image)
# 阶段2:高分辨率细化
print("阶段2: 高分辨率细化...")
high_res_image = self.high_res_model.generate(
prompt,
init_image=low_res_image, # 使用低分辨率结果作为初始化
strength=0.7, # 保持主要构图
size=final_size,
num_steps=30
)
# 阶段3:局部优化
print("阶段3: 局部优化...")
if analysis["needs_face_enhancement"]:
high_res_image = self.enhance_facial_details(high_res_image)
if analysis["needs_texture_refinement"]:
high_res_image = self.refine_textures(high_res_image)
return high_res_image
def analyze_image_composition(self, image):
"""分析图像构图和质量"""
analysis = {
"composition_score": self.evaluate_composition(image),
"needs_face_enhancement": self.detect_faces(image),
"needs_texture_refinement": self.assess_texture_quality(image),
"color_balance": self.analyze_color_balance(image)
}
return analysis
5. 基于反馈的迭代优化
class IterativeRefinement:
"""基于反馈的迭代优化"""
def __init__(self, quality_criteria):
self.quality_criteria = quality_criteria
self.feedback_history = []
def generate_with_feedback(self, prompt, max_iterations=3):
"""带反馈的迭代生成"""
best_image = None
best_score = 0
for iteration in range(max_iterations):
print(f"迭代 {iteration + 1}/{max_iterations}")
# 生成候选图像
candidate = self.generate_candidate(prompt, iteration)
# 质量评估
score, feedback = self.evaluate_quality(candidate, prompt)
# 记录反馈
self.feedback_history.append({
'iteration': iteration,
'image': candidate,
'score': score,
'feedback': feedback
})
# 更新最佳结果
if score > best_score:
best_image = candidate
best_score = score
# 如果质量足够好,提前终止
if score > self.quality_criteria["satisfactory_threshold"]:
break
return best_image, self.feedback_history
def evaluate_quality(self, image, prompt):
"""评估图像质量"""
scores = {}
# 文本-图像对齐度
scores['alignment'] = self.evaluate_text_image_alignment(image, prompt)
# 美学质量
scores['aesthetic'] = self.evaluate_aesthetic_quality(image)
# 技术质量
scores['technical'] = self.evaluate_technical_quality(image)
# 综合评分
total_score = (
scores['alignment'] * 0.4 +
scores['aesthetic'] * 0.4 +
scores['technical'] * 0.2
)
# 生成反馈
feedback = self.generate_feedback(scores)
return total_score, feedback
def generate_feedback(self, scores):
"""根据评分生成改进反馈"""
feedback = []
if scores['alignment'] < 0.7:
feedback.append("图像与文本描述的对齐度需要提高")
if scores['aesthetic'] < 0.6:
feedback.append("美学质量有待提升,考虑调整构图或色彩")
if scores['technical'] < 0.8:
feedback.append("存在技术问题,如图像模糊或伪影")
return feedback
四、完整流程总结与技术展望
图像生成完整流程整合
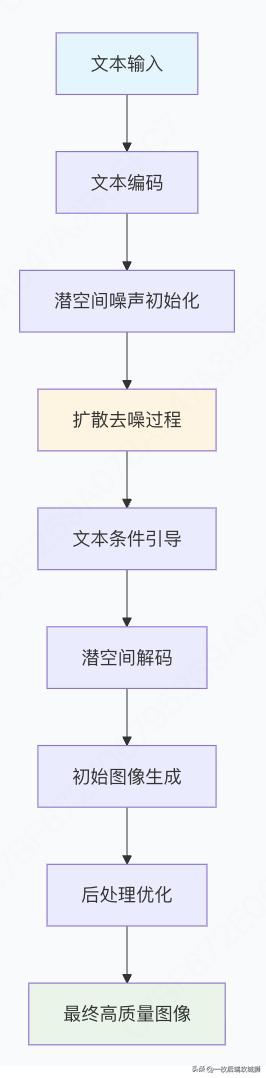
关键技术突破总结
1.表示学习的革命
- 图片token化:将连续视觉空间离散化,使图像能够用"视觉语言"描述
- 跨模态对齐:在统一语义空间中对齐文本和视觉概念
2.生成范式的进化
# 生成技术演进里程碑
generation_milestones = {
"2014": "GANs - 生成对抗网络",
"2017": "VAEs - 变分自编码器",
"2020": "VQ-VAE - 离散表示学习",
"2021": "扩散模型 - 去噪生成范式",
"2022": "潜空间扩散 - 效率突破",
"2023": "多模态统一 - 文本到一切"
}
3.优化技术的成熟
- 采样加速:从1000步到10步的质量生成
- 控制增强:从随机生成到精确控制
- 质量提升:从模糊到照片级真实感
实际应用代码示例
class CompleteImageGenerationPipeline:
"""完整的图像生成流水线"""
def __init__(self, model_name="stable-diffusion-v1-5"):
self.model = StableDiffusionPipeline.from_pretrained(model_name)
self.optimizer = PromptOptimizer()
self.post_processor = ImagePostProcessor()
self.refinement = IterativeRefinement()
def generate_high_quality_image(self, prompt,
size=(1024, 1024),
style="realistic",
iterations=2):
"""生成高质量图像"""
# 1. 提示词优化
optimized_prompt, negative_prompt = self.optimizer.optimize_prompt(
prompt, style=style, quality="high"
)
# 2. 多阶段生成
final_image = None
for i in range(iterations):
print(f"生成迭代 {i+1}/{iterations}")
# 生成基础图像
image = self.model(
prompt=optimized_prompt,
negative_prompt=negative_prompt,
height=size[1],
width=size[0],
num_inference_steps=30,
guidance_scale=7.5
).images[0]
# 后处理优化
enhanced_image = self.post_processor.enhance_image(image, size)
# 评估并决定是否继续
if i == 0 or self.is_improvement(enhanced_image, final_image):
final_image = enhanced_image
return final_image
def is_improvement(self, new_image, old_image):
"""判断新图像是否比旧图像有改进"""
if old_image is None:
return True
# 简单的质量比较(实际中会用更复杂的指标)
new_score = self.assess_image_quality(new_image)
old_score = self.assess_image_quality(old_image)
return new_score > old_score
def assess_image_quality(self, image):
"""评估图像质量"""
# 使用CLIP评估文本-图像对齐
# 使用美学评估模型评估美学质量
# 使用技术指标评估清晰度等
return 0.8 # 简化返回
未来发展方向
1.技术前沿
- 3D生成:从文本直接生成3D模型和场景
- 视频生成:时序一致的视频内容创作
- 交互式生成:实时调整和编辑生成过程
2.应用拓展
- 个性化创作:基于用户风格的定制化生成
- 产业应用:设计、广告、教育、医疗等领域
- 无障碍创作:让非专业人士也能进行高质量创作
3.挑战与机遇
- 可控性:更精确的内容控制
- 效率:实时生成能力
- 伦理:版权、真实性、偏见等问题
总结:视觉创造的新纪元
图像生成技术的发展标志着AI从"理解"到"创造"的重大跨越。通过:
- 视觉语言的建立(图片token化)
- 生成范式的革新(扩散模型)
- 优化技术的成熟(采样、提示、后处理)
我们现在能够用自然语言描述就能生成高质量的视觉内容。这不仅改变了内容创作的方式,更重新定义了人类与机器的创造性合作关系。
正如摄影术的发明让每个人都能成为"画家",AI图像生成技术正在让每个人都能成为"视觉创作者"。这不仅是技术的进步,更是人类表达能力的一次重大解放。


















 2325
2325

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











