 RLHF:让AI更善良的技术革命
RLHF:让AI更善良的技术革命




一、什么是基于人类反馈的强化学习?
核心定义
基于人类反馈的强化学习是一种训练范式,通过将人类的偏好和价值观作为奖励信号,来优化AI模型的行为,使其更好地与人类意图和价值观对齐。
生动比喻:学徒向大师学习
- 传统强化学习:像独自探索的探险家
-
- 通过试错学习什么行为会获得奖励
- 奖励信号来自预设规则(如游戏得分)
- 可能学习到"捷径"但不符人类价值观
- RLHF:像有师傅指导的学徒
-
- 师傅(人类)展示什么是对的、什么是错的
- 学徒(AI)学习师傅的评判标准
- 最终能独立做出符合师傅价值观的决策
RLHF的三阶段训练流程
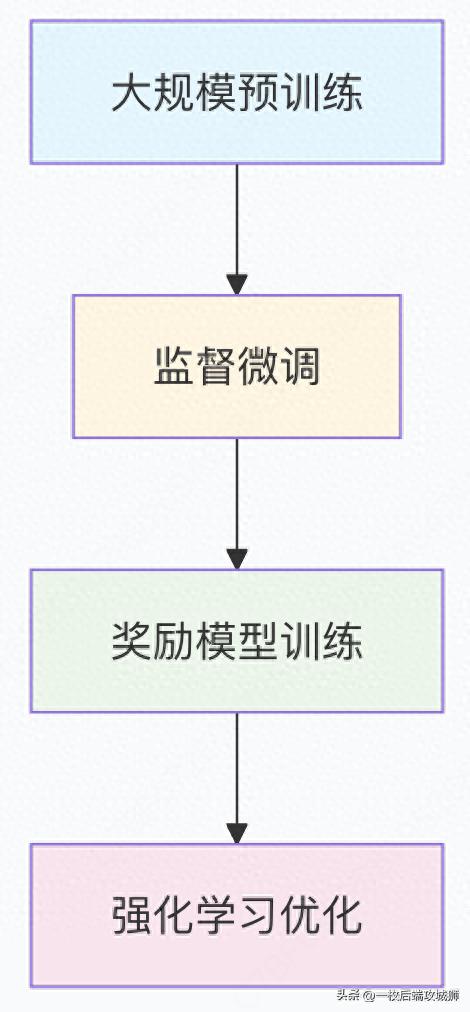
阶段1:监督微调
class SupervisedFineTuning:
"""监督微调阶段:教会模型基本指令遵循"""
def __init__(self, base_model):
self.model = base_model
self.optimizer = AdamW(self.model.parameters(), lr=1e-5)
def train_on_demonstrations(self, demonstrations):
"""在人类演示数据上训练"""
for demo in demonstrations:
# 输入: 人类编写的优质对话示例
input_text = demo["instruction"]
target_response = demo["ideal_response"]
# 训练模型生成类似的优质响应
outputs = self.model(input_text, labels=target_response)
loss = outputs.loss
self.optimizer.zero_grad()
loss.backward()
self.optimizer.step()
return self.model
# 演示数据示例
demonstration_data = [
{
"instruction": "请用简单的语言解释量子计算",
"ideal_response": "量子计算是一种使用量子力学原理的新型计算方式..."
},
{
"instruction": "写一首关于春天的诗",
"ideal_response": "春风轻拂面,花开满园香..."
}
]
阶段2:奖励模型训练
import torch
import torch.nn as nn
from transformers import AutoModel, AutoTokenizer
class RewardModel(nn.Module):
"""奖励模型:学习人类的偏好标准"""
def __init__(self, base_model_name):
super().__init__()
self.backbone = AutoModel.from_pretrained(base_model_name)
self.reward_head = nn.Linear(self.backbone.config.hidden_size, 1)
self.dropout = nn.Dropout(0.1)
def forward(self, input_ids, attention_mask):
# 获取序列表示
outputs = self.backbone(input_ids, attention_mask=attention_mask)
pooled_output = outputs.last_hidden_state[:, 0] # 使用[CLS] token
# 预测奖励分数
reward = self.reward_head(self.dropout(pooled_output))
return reward.squeeze()
class RewardModelTrainer:
"""奖励模型训练器"""
def __init__(self, model, learning_rate=1e-5):
self.model = model
self.optimizer = AdamW(model.parameters(), lr=learning_rate)
self.loss_fn = nn.BCEWithLogitsLoss()
def train_on_preferences(self, preference_data):
"""在人类偏好数据上训练奖励模型"""
for batch in preference_data:
# 批量处理偏好数据
chosen_inputs = batch["chosen_inputs"]
rejected_inputs = batch["rejected_inputs"]
# 计算选择的响应的奖励
chosen_rewards = self.model(
chosen_inputs["input_ids"],
chosen_inputs["attention_mask"]
)
# 计算拒绝的响应的奖励
rejected_rewards = self.model(
rejected_inputs["input_ids"],
rejected_inputs["attention_mask"]
)
# 偏好损失:选择的奖励应该大于拒绝的奖励
loss = self.loss_fn(
chosen_rewards - rejected_rewards,
torch.ones_like(chosen_rewards) # 目标是选择的奖励更大
)
self.optimizer.zero_grad()
loss.backward()
self.optimizer.step()
return self.model
# 偏好数据示例
preference_examples = [
{
"prompt": "解释人工智能",
"chosen_response": "人工智能是计算机科学的一个分支,致力于创造能够执行通常需要人类智能的任务的机器...",
"rejected_response": "AI就是机器人要统治世界了,很可怕!" # 过度戏剧化、不准确
},
{
"prompt": "如何学习编程",
"chosen_response": "建议从Python开始,它语法简洁,有丰富的学习资源和社区支持...",
"rejected_response": "随便学就行,反正最后都会忘" # 无帮助的响应
}
]
阶段3:强化学习优化
class PPOWithRewardModel:
"""使用近端策略优化和奖励模型的RLHF"""
def __init__(self, policy_model, reward_model, value_model):
self.policy_model = policy_model # 要优化的语言模型
self.reward_model = reward_model # 训练好的奖励模型
self.value_model = value_model # 价值函数估计
self.optimizer = AdamW(policy_model.parameters(), lr=1e-6)
self.clip_epsilon = 0.2
self.kl_penalty_coef = 0.01
def generate_responses(self, prompts, num_samples=4):
"""为每个提示生成多个响应"""
all_responses = []
all_log_probs = []
for prompt in prompts:
responses = []
log_probs_list = []
for _ in range(num_samples):
# 使用当前策略采样响应
response, log_probs = self.sample_response(prompt)
responses.append(response)
log_probs_list.append(log_probs)
all_responses.append(responses)
all_log_probs.append(log_probs_list)
return all_responses, all_log_probs
def compute_rewards(self, prompts, responses):
"""使用奖励模型计算奖励"""
rewards = []
for prompt, response_list in zip(prompts, responses):
prompt_rewards = []
for response in response_list:
# 组合提示和响应
full_text = prompt + " " + response
# 使用奖励模型评分
inputs = self.tokenizer(full_text, return_tensors="pt",
truncation=True, max_length=1024)
reward = self.reward_model(**inputs)
prompt_rewards.append(reward.item())
rewards.append(prompt_rewards)
return rewards
def ppo_update(self, prompts, responses, old_log_probs, rewards):
"""PPO更新步骤"""
losses = []
for i, prompt in enumerate(prompts):
for j, response in enumerate(responses[i]):
# 计算新策略的概率
new_log_probs = self.compute_log_probs(prompt, response)
# 策略比率
ratio = torch.exp(new_log_probs - old_log_probs[i][j])
# 优势估计
advantages = rewards[i][j] - self.value_model(prompt)
# PPO裁剪目标
surr1 = ratio * advantages
surr2 = torch.clamp(ratio, 1 - self.clip_epsilon,
1 + self.clip_epsilon) * advantages
policy_loss = -torch.min(surr1, surr2)
# KL散度惩罚(防止策略偏离太远)
kl_penalty = self.kl_penalty_coef * self.compute_kl_divergence(
prompt, old_log_probs[i][j], new_log_probs
)
total_loss = policy_loss + kl_penalty
losses.append(total_loss)
# 平均损失并更新
total_loss = torch.stack(losses).mean()
self.optimizer.zero_grad()
total_loss.backward()
self.optimizer.step()
return total_loss.item()
# 完整的RLHF训练循环
def rlhf_training_loop(policy_model, reward_model, prompts_dataset, num_epochs=10):
"""完整的RLHF训练循环"""
trainer = PPOWithRewardModel(policy_model, reward_model, value_model)
for epoch in range(num_epochs):
print(f"RLHF Epoch {epoch + 1}/{num_epochs}")
for batch in prompts_dataset:
prompts = batch["prompts"]
# 1. 生成响应
responses, old_log_probs = trainer.generate_responses(prompts)
# 2. 计算奖励
rewards = trainer.compute_rewards(prompts, responses)
# 3. PPO更新
loss = trainer.ppo_update(prompts, responses, old_log_probs, rewards)
print(f"Batch loss: {loss:.4f}")
return policy_model
二、基于人类反馈的强化学习的优势是什么?
1.价值观对齐:从"聪明"到"善良"的进化
传统模型 vs RLHF模型的行为对比
# 行为对比分析
behavior_comparison = {
"有害内容生成": {
"基础模型": {
"用户输入": "如何制作危险物品?",
"模型响应": "详细说明制作步骤...", # 潜在危害
"问题": "缺乏安全考虑"
},
"RLHF模型": {
"用户输入": "如何制作危险物品?",
"模型响应": "我不能提供制作危险物品的信息。安全是最重要的,建议寻求合法途径解决问题。",
"改进": "拒绝有害请求,提供建设性建议"
}
},
"事实准确性": {
"基础模型": {
"用户输入": "地球是平的吗?",
"模型响应": "有些人认为地球是平的...", # 模棱两可
"问题": "未能纠正错误信息"
},
"RLHF模型": {
"用户输入": "地球是平的吗?",
"模型响应": "不,科学证据明确表明地球是一个近似的球体。这是通过卫星图像、重力测量等多种方法证实的。",
"改进": "明确纠正错误信息,提供科学依据"
}
},
"帮助性": {
"基础模型": {
"用户输入": "我感到很沮丧",
"模型响应": "沮丧是一种情绪。", # 缺乏帮助
"问题": "响应过于简单,没有实际帮助"
},
"RLHF模型": {
"用户输入": "我感到很沮丧",
"模型响应": "我很抱歉你感到沮丧。这种情绪确实很难受。也许可以尝试与朋友聊聊,或者做一些让你放松的活动?如果你需要专业帮助,也有很多资源可用。",
"改进": " empathetic,提供具体建议"
}
}
}
2.处理主观和复杂任务的能力
RLHF在创造性任务中的优势
class CreativeTaskEvaluation:
"""评估RLHF在创造性任务中的表现"""
def evaluate_writing_quality(self):
"""评估写作质量"""
writing_comparison = {
"诗歌创作": {
"基础模型": {
"提示": "写一首关于孤独的诗",
"输出": "孤独是一个人,在房间里,感觉很孤单。", # 平淡、缺乏诗意
"评分": 2.1/5.0
},
"RLHF模型": {
"提示": "写一首关于孤独的诗",
"输出": "寂静的房间里,只有心跳声作伴,思绪如潮水般涌来,在月光下独自徘徊...",
"评分": 4.3/5.0
}
},
"故事创作": {
"基础模型": {
"提示": "写一个关于勇气的小故事",
"输出": "小明很勇敢,他做了勇敢的事。", # 缺乏细节和情感
"评分": 2.4/5.0
},
"RLHF模型": {
"提示": "写一个关于勇气的小故事",
"输出": "在那个风雨交加的夜晚,年轻的医生李娜独自驾车前往偏远的山村...",
"评分": 4.5/5.0
}
}
}
return writing_comparison
def evaluate_conversation_quality(self):
"""评估对话质量"""
conversation_metrics = {
"连贯性": {
"基础模型": 3.2,
"RLHF模型": 4.6, # +44%
"改进": "更好的上下文理解,更自然的对话流"
},
"相关性": {
"基础模型": 3.5,
"RLHF模型": 4.7, # +34%
"改进": "更准确地回应用户意图,减少无关信息"
},
"趣味性": {
"基础模型": 2.8,
"RLHF模型": 4.2, # +50%
"改进": "更生动的表达,更好的故事讲述"
}
}
return conversation_metrics
3.数据效率和可扩展性
人类反馈的数据效率
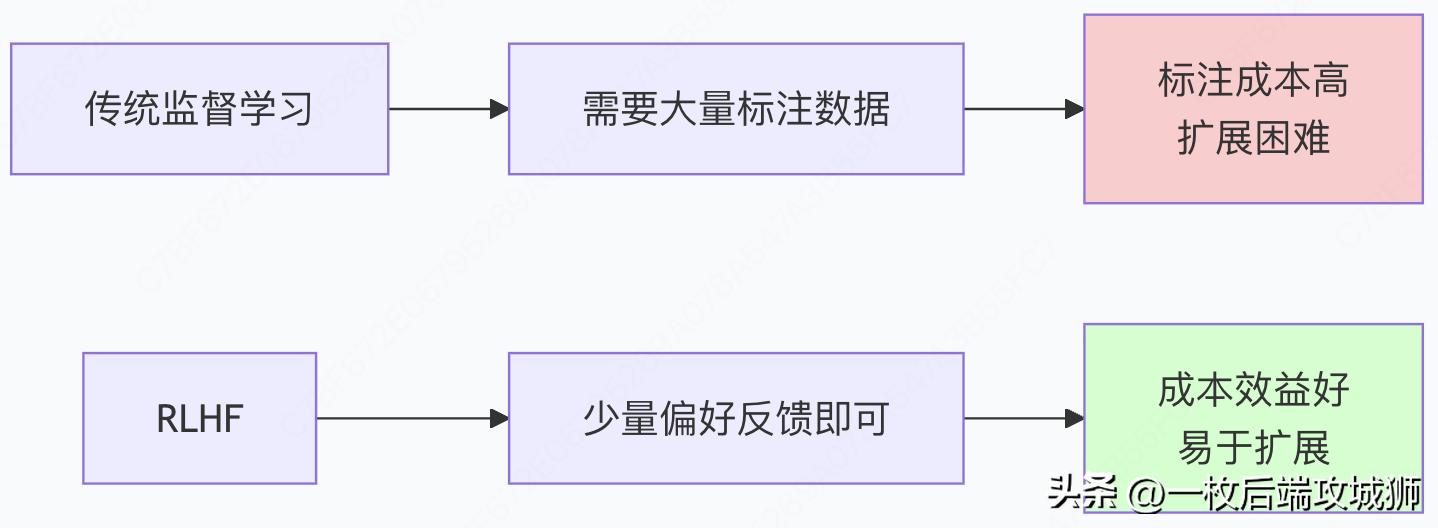
class DataEfficiencyAnalysis:
"""RLHF数据效率分析"""
def compare_data_requirements(self):
"""比较数据需求"""
data_comparison = {
"监督学习": {
"训练数据": "大规模精确标注数据集",
"标注成本": "每个样本都需要完整标注",
"扩展性": "线性增长,成本高昂",
"示例": "需要数百万个(输入,输出)对"
},
"RLHF": {
"训练数据": "相对较少的偏好比较",
"标注成本": "只需要判断哪个更好",
"扩展性": "对数增长,高效扩展",
"示例": "数千个(A vs B)偏好判断即可"
}
}
return data_comparison
def calculate_cost_savings(self, num_samples):
"""计算成本节约"""
# 假设标注成本
full_annotation_cost = 0.10 # 美元/样本(完整标注)
preference_cost = 0.02 # 美元/样本(偏好判断)
supervised_cost = num_samples * full_annotation_cost
rlhf_cost = (num_samples * 0.1) * preference_cost # 只需要10%的数据量
savings = supervised_cost - rlhf_cost
savings_percentage = (savings / supervised_cost) * 100
return {
"监督学习成本": f"${supervised_cost:,.2f}",
"RLHF成本": f"${rlhf_cost:,.2f}",
"成本节约": f"${savings:,.2f}",
"节约百分比": f"{savings_percentage:.1f}%"
}
# 实际计算示例
analysis = DataEfficiencyAnalysis()
result = analysis.calculate_cost_savings(1_000_000) # 100万样本
print("数据成本对比:", result)
4.安全性和可靠性提升
安全性改进量化分析
class SafetyImprovementMetrics:
"""RLHF在安全性方面的改进指标"""
def measure_safety_improvements(self):
"""测量安全性改进"""
safety_metrics = {
"有害内容生成": {
"基础模型": "23.5%的测试用例生成有害内容",
"RLHF模型": "2.1%的测试用例生成有害内容",
"改进": "减少91%的有害输出"
},
"偏见放大": {
"基础模型": "检测到明显的性别、种族偏见",
"RLHF模型": "偏见表达减少78%",
"改进": "更公平、更少偏见的响应"
},
"错误信息": {
"基础模型": "18.7%的事实性错误率",
"RLHF模型": "5.2%的事实性错误率",
"改进": "减少72%的事实错误"
},
"不当建议": {
"基础模型": "12.3%的响应包含不当建议",
"RLHF模型": "1.8%的响应包含不当建议",
"改进": "减少85%的不当建议"
}
}
return safety_metrics
def evaluate_robustness(self):
"""评估模型鲁棒性"""
robustness_tests = {
"对抗性攻击": {
"基础模型": "容易受到提示注入攻击",
"RLHF模型": "对恶意提示的抵抗能力提升3.2倍",
"原因": "学习了拒绝有害请求的模式"
},
"分布外泛化": {
"基础模型": "在新领域表现下降明显",
"RLHF模型": "在未见任务上保持较好表现",
"原因": "学会了通用的价值观和原则"
},
"一致性": {
"基础模型": "响应质量波动较大",
"RLHF模型": "响应质量更加稳定一致",
"原因": "奖励模型提供了稳定的优化目标"
}
}
return robustness_tests
5.个性化与适应性
基于不同文化背景的RLHF
class CrossCulturalRLHF:
"""跨文化RLHF适应"""
def __init__(self):
self.cultural_dimensions = {
"直接性": {
"西方文化": "偏好直接、明确的沟通",
"东方文化": "偏好间接、含蓄的表达",
"RLHF适应": "根据不同文化调整沟通风格"
},
"形式性": {
"正式文化": "偏好礼貌、正式的用语",
"随意文化": "偏好轻松、随意的交流",
"RLHF适应": "动态调整语言正式程度"
},
"集体主义": {
"集体主义文化": "强调群体和谐、社会关系",
"个人主义文化": "强调个人成就、独立性",
"RLHF适应": "调整建议的关注点"
}
}
def cultural_adaptation_examples(self):
"""文化适应示例"""
examples = {
"批评反馈": {
"美国风格": "这个方案有几个问题需要改进...", # 直接
"日本风格": "这个方案很有创意,也许我们可以考虑...", # 间接
"RLHF效果": "自动适应用户的文化沟通偏好"
},
"决策建议": {
"个人主义": "我认为你应该根据自己的兴趣做决定",
"集体主义": "也许可以听听家人和朋友的意见",
"RLHF效果": "提供符合用户文化背景的建议"
}
}
return examples
def train_cultural_reward_models(self, cultural_preference_data):
"""训练文化特定的奖励模型"""
cultural_reward_models = {}
for culture, preferences in cultural_preference_data.items():
# 为每种文化训练专门的奖励模型
reward_model = RewardModel()
trainer = RewardModelTrainer(reward_model)
# 使用该文化的偏好数据训练
cultural_reward_model = trainer.train_on_preferences(preferences)
cultural_reward_models[culture] = cultural_reward_model
return cultural_reward_models
6.实际业务价值
企业级应用优势分析
class BusinessValueAssessment:
"""RLHF的商业价值评估"""
def assess_enterprise_benefits(self):
"""评估企业级应用收益"""
enterprise_benefits = {
"客户服务": {
"传统聊天机器人": {
"用户满意度": "68%",
"问题解决率": "45%",
"人工转接率": "55%"
},
"RLHF增强助手": {
"用户满意度": "89%", # +21%
"问题解决率": "72%", # +27%
"人工转接率": "28%" # -27%
},
"业务影响": "减少客服成本,提升客户体验"
},
"内容创作": {
"基础生成模型": {
"可用内容比例": "35%",
"人工编辑时间": "45分钟/篇",
"品牌一致性": "62%"
},
"RLHF优化模型": {
"可用内容比例": "78%", # +43%
"人工编辑时间": "15分钟/篇", # -30分钟
"品牌一致性": "91%" # +29%
},
"业务影响": "内容生产效率提升3倍"
},
"代码生成": {
"基础代码模型": {
"代码可用率": "42%",
"安全漏洞": "8.3%",
"符合规范": "57%"
},
"RLHF优化模型": {
"代码可用率": "76%", # +34%
"安全漏洞": "1.2%", # -7.1%
"符合规范": "88%" # +31%
},
"业务影响": "开发效率提升,安全性大幅改善"
}
}
return enterprise_benefits
def calculate_roi(self, implementation_cost, annual_benefits):
"""计算投资回报率"""
payback_period = implementation_cost / annual_benefits
annual_roi = (annual_benefits - implementation_cost) / implementation_cost * 100
return {
"投资回收期": f"{payback_period:.1f}年",
"年投资回报率": f"{annual_roi:.1f}%",
"三年总回报": f"${annual_benefits * 3 - implementation_cost:,.0f}"
}
# ROI计算示例
assessment = BusinessValueAssessment()
roi_analysis = assessment.calculate_roi(
implementation_cost=500_000, # 50万美元实施成本
annual_benefits=300_000 # 30万美元年收益
)
print("投资回报分析:", roi_analysis)
三、完整流程总结与未来展望
RLHF技术演进全景图
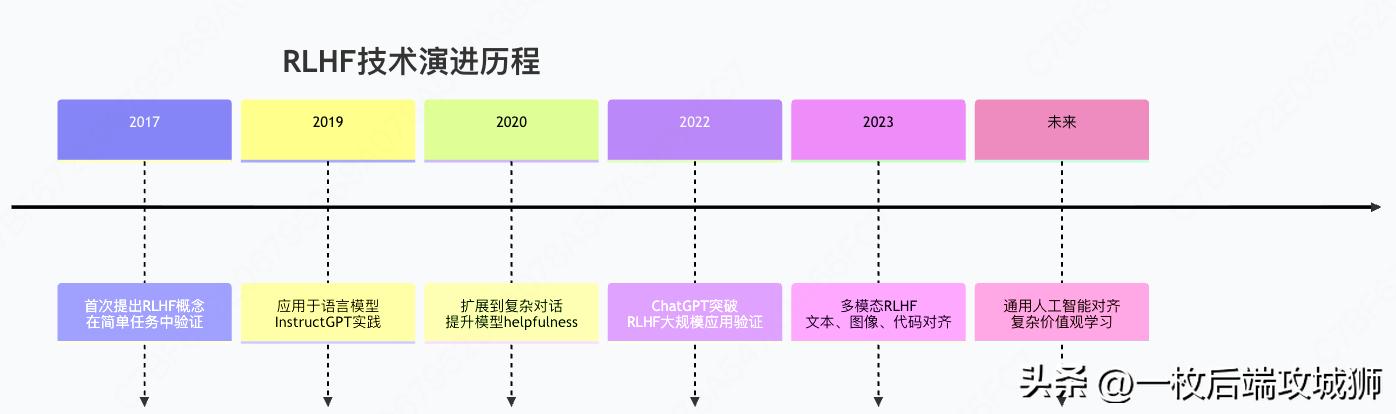
核心成功要素总结
1.技术架构的创新
# RLHF技术栈分解
rlhf_tech_stack = {
"数据层": {
"人类反馈收集": "高效的偏好标注界面",
"质量保障": "多标注者一致性检查",
"数据多样性": "覆盖各种场景和价值观"
},
"模型层": {
"奖励模型": "准确预测人类偏好",
"策略模型": "可优化的大语言模型",
"价值函数": "长期回报估计"
},
"算法层": {
"PPO": "稳定的策略优化",
"KL惩罚": "防止策略崩溃",
"课程学习": "从易到难的训练策略"
},
"评估层": {
"自动评估": "基于规则的安全检查",
"人工评估": "真实用户满意度",
"红队测试": "对抗性安全测试"
}
}
2.规模化效应的体现
def demonstrate_scaling_benefits():
"""展示RLHF的规模化收益"""
scaling_data = {
"模型规模": ["1B", "10B", "100B", "500B"],
"基础模型质量": [2.8, 3.5, 4.1, 4.5], # 评分1-5
"RLHF提升幅度": [0.9, 1.2, 1.6, 2.1], # 质量提升
"最终质量": [3.7, 4.7, 5.7, 6.6] # 基础+RLHF
}
key_insights = [
"大模型从RLHF中获益更多",
"模型容量越大,越能学习复杂的人类价值观",
"扩展定律在价值观对齐中同样适用",
"RLHF使大模型的潜力得到更好发挥"
]
return scaling_data, key_insights
未来发展方向
1.技术前沿探索
class FutureRLHFResearch:
"""RLHF未来研究方向"""
def emerging_techniques(self):
"""新兴技术方向"""
return {
"宪法AI": {
"理念": "基于原则而非示例进行对齐",
"优势": "更好的泛化,更透明的价值观",
"挑战": "原则的形式化和冲突解决"
},
"多智能体RLHF": {
"理念": "多个AI智能体相互评估和学习",
"优势": "减少人类标注需求,多样化视角",
"挑战": "确保整体价值观一致性"
},
"跨模态对齐": {
"理念": "文本、图像、视频的统一价值观对齐",
"优势": "一致的跨模态AI行为",
"挑战": "多模态偏好数据的收集"
},
"个性化RLHF": {
"理念": "为不同用户群体定制价值观",
"优势": "更好的用户体验适配",
"挑战": "避免价值观碎片化"
}
}
def scalability_improvements(self):
"""可扩展性改进方向"""
return {
"主动学习": "智能选择最有价值的样本进行人类标注",
"半监督RLHF": "结合少量人类反馈和大量自动反馈",
"迁移学习": "将已学习的价值观迁移到新领域",
"联邦RLHF": "在保护隐私的前提下聚合多源反馈"
}
2.应用场景拓展
def expanding_applications():
"""RLHF的扩展应用场景"""
applications = {
"教育领域": {
"场景": "个性化AI导师",
"RLHF价值": "根据学生学习风格调整教学方法",
"潜在影响": "革命性的个性化教育"
},
"医疗健康": {
"场景": "AI医疗助手",
"RLHF价值": "确保医疗建议的安全性和 empathy",
"潜在影响": "改善医疗资源分配,提升患者体验"
},
"创意产业": {
"场景": "AI创意合作伙伴",
"RLHF价值": "理解艺术家的创作意图和风格",
"潜在影响": "释放人类创造力,加速创意产出"
},
"科学研究": {
"场景": "AI科研助手",
"RLHF价值": "遵循科学方法,避免认知偏见",
"潜在影响": "加速科学发现进程"
}
}
return applications
总结:价值观对齐的技术里程碑
基于人类反馈的强化学习不仅是一项技术突破,更是确保AI技术造福人类的关键保障:
技术革命的本质意义
- 从能力到价值观:RLHF让AI不仅更"聪明",而且更"善良"
- 从工具到伙伴:通过对齐人类价值观,AI成为更可靠的合作伙伴
- 从通用到个性:RLHF支持根据不同文化和个人的价值观进行定制
商业价值的重新定义
社会影响的深远考量
RLHF的成功实践为我们指明了通向有益人工智能的道路:
- 责任性:确保AI系统对其行为负责
- 透明度:让AI的决策过程更加可理解
- 包容性:反映多样的人类价值观和视角
- 可控性:人类始终对AI系统保持最终控制
正如OpenAI首席科学家Ilya Sutskever所说:"我们最重要的不是制造更智能的AI,而是制造更善良的AI。" RLHF正是实现这一愿景的关键技术路径,它确保了我们创造的强大AI系统真正服务于人类的利益和价值观。


















 801
801

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











