




1. 引言:为什么需要执行计划分析?
在数据库性能优化中,执行计划(Execution Plan)是理解SQL语句执行过程的"地图"。对于Java开发者而言,掌握EXPLAIN工具能够:
- 诊断慢查询:快速定位性能瓶颈
- 优化索引策略:验证索引使用效果
- 理解查询执行:深入数据库内部工作机制
- 预防潜在问题:在开发阶段发现性能隐患
// 实际开发中的性能问题场景
@Service
public class OrderService {
@Autowired
private JdbcTemplate jdbcTemplate;
public List<Order> findRecentOrders(Long userId, Date startDate) {
// 看似简单的查询,可能隐藏性能陷阱
String sql = "SELECT * FROM orders WHERE user_id = ? AND create_time > ? " +
"ORDER BY create_time DESC LIMIT 100";
// 如何知道这个查询是否高效?
return jdbcTemplate.query(sql, new Object[]{userId, startDate},
new OrderRowMapper());
}
}
2. EXPLAIN基础:语法与输出解读
2.1 基本语法格式
-- 基本用法 EXPLAIN SELECT * FROM users WHERE id = 1; -- 扩展信息(MySQL 5.6+) EXPLAIN FORMAT=JSON SELECT * FROM users WHERE id = 1; -- 实际执行信息(MySQL 8.0+) EXPLAIN ANALYZE SELECT * FROM users WHERE id = 1; -- 查看分区信息 EXPLAIN PARTITIONS SELECT * FROM orders WHERE order_date > '2023-01-01';
2.2 执行计划输出结构
-- 示例执行计划输出 EXPLAIN SELECT u.name, o.order_no FROM users u JOIN orders o ON u.id = o.user_id WHERE u.status = 'ACTIVE' AND o.amount > 1000; -- 输出结果: +----+-------------+-------+------------+--------+---------------+---------+---------+------------------+------+----------+-------------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+-------+------------+--------+---------------+---------+---------+------------------+------+----------+-------------+ | 1 | SIMPLE | u | NULL | ref | status_idx | status_idx | 102 | const | 1000 | 100.00 | Using where | | 1 | SIMPLE | o | NULL | eq_ref | PRIMARY,user_id_idx | user_id_idx | 8 | db.u.id | 1 | 33.33 | Using where | +----+-------------+-------+------------+--------+---------------+---------+---------+------------------+------+----------+-------------+
3. 执行计划各列深度解析
3.1 id - 查询标识
public class ExplainIdAnalysis {
/**
* id列的含义:
* - 相同id:同一查询级别,执行顺序从上到下
* - 不同id:id值越大,执行优先级越高
* - NULL:表示结果集,如UNION操作
*/
public void analyzeIdExamples() {
// 示例1:简单查询
// EXPLAIN SELECT * FROM users;
// id: 1
// 示例2:子查询
// EXPLAIN SELECT * FROM users WHERE id IN (SELECT user_id FROM orders);
// id: 1 (主查询), id: 2 (子查询) - 子查询先执行
// 示例3:UNION查询
// EXPLAIN SELECT id FROM users UNION SELECT id FROM admins;
// id: 1 (第一个SELECT), id: 2 (第二个SELECT), id: NULL (UNION结果)
}
}
3.2 select_type - 查询类型
|
select_type |
含义 |
场景示例 |
|
SIMPLE |
简单SELECT查询 |
SELECT * FROM users |
|
PRIMARY |
最外层查询 |
包含子查询的最外层 |
|
SUBQUERY |
子查询 |
SELECT id, (SELECT name FROM profiles) FROM users |
|
DERIVED |
派生表 |
SELECT * FROM (SELECT * FROM users) t |
|
UNION |
UNION中的第二个及以后查询 |
SELECT id FROM users UNION SELECT id FROM admins |
|
UNION RESULT |
UNION的结果 |
UNION操作的最终结果 |
-- 复杂查询示例
EXPLAIN
SELECT u.name,
(SELECT COUNT(*) FROM orders o WHERE o.user_id = u.id) as order_count
FROM users u
WHERE u.id IN (SELECT user_id FROM payments WHERE amount > 100)
UNION
SELECT name FROM admins;
-- 预期select_type分布:
-- PRIMARY, SUBQUERY, SUBQUERY, UNION, UNION RESULT
3.3 type - 访问类型(关键性能指标)
访问类型从最优到最差排序:
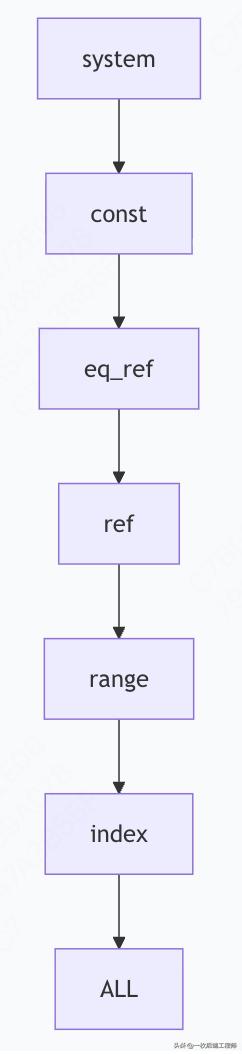
3.3.1 最优访问类型详解
-- const: 通过主键或唯一索引定位单条记录 EXPLAIN SELECT * FROM users WHERE id = 1; -- type: const -- eq_ref: 多表关联时,使用主键或唯一索引 EXPLAIN SELECT * FROM users u JOIN orders o ON u.id = o.user_id WHERE o.order_no = 'ORDER123'; -- users表: eq_ref -- ref: 使用非唯一索引扫描 EXPLAIN SELECT * FROM users WHERE status = 'ACTIVE'; -- type: ref (如果status有索引)
3.3.2 需要优化的访问类型
-- range: 索引范围扫描 EXPLAIN SELECT * FROM orders WHERE create_time BETWEEN '2023-01-01' AND '2023-01-31'; -- type: range -- index: 全索引扫描 EXPLAIN SELECT status FROM users; -- type: index (如果status有索引) -- ALL: 全表扫描 - 需要重点关注优化 EXPLAIN SELECT * FROM users WHERE phone LIKE '%1234%'; -- type: ALL
3.4 possible_keys, key, key_len - 索引使用情况
public class IndexAnalysis {
/**
* 索引使用分析:
* - possible_keys: 可能使用的索引
* - key: 实际使用的索引
* - key_len: 使用的索引长度
*/
public void analyzeIndexUsage() {
// 场景1:索引命中
// EXPLAIN SELECT * FROM users WHERE email = 'test@example.com';
// possible_keys: email_idx
// key: email_idx
// key_len: 102 (email字段长度)
// 场景2:索引未命中
// EXPLAIN SELECT * FROM users WHERE name LIKE '%John%';
// possible_keys: NULL
// key: NULL
// key_len: NULL
// 场景3:索引选择
// EXPLAIN SELECT * FROM users WHERE status = 'ACTIVE' AND country = 'US';
// possible_keys: status_idx, country_idx, composite_idx
// key: composite_idx (优化器选择最合适的索引)
}
public void understandKeyLen() {
// key_len计算规则:
// VARCHAR(100) UTF8: 3*100 + 2(长度位) = 302
// INT: 4
// DATETIME: 8
// 可为NULL: +1
// 复合索引使用长度分析
// INDEX (col1, col2, col3)
// WHERE col1 = 1 AND col2 = 2 → key_len = len(col1) + len(col2)
}
}
3.5 rows, filtered - 数据扫描分析
-- rows: 预估扫描行数 -- filtered: 条件过滤百分比 EXPLAIN SELECT * FROM users u JOIN orders o ON u.id = o.user_id WHERE u.age > 30 AND o.amount > 1000; -- 分析: -- users表: rows=10000, filtered=10.00 (预估1000行满足age>30) -- orders表: rows=5, filtered=20.00 (预估20%订单满足amount>1000) -- 总预估数据量: 1000 * 5 * 0.2 = 1000行
3.6 Extra - 额外信息(重要优化提示)
|
Extra信息 |
含义 |
优化建议 |
|
Using where |
使用WHERE条件过滤 |
检查是否可以利用索引 |
|
Using index |
覆盖索引扫描 |
良好,无需回表 |
|
Using temporary |
使用临时表 |
考虑优化查询或索引 |
|
Using filesort |
文件排序 |
考虑添加排序索引 |
|
Using join buffer |
使用连接缓冲 |
表连接较大,考虑索引优化 |
4. 实战案例:执行计划分析与优化
4.1 案例一:慢查询优化
-- 原始查询(执行缓慢) EXPLAIN SELECT * FROM orders WHERE user_id = 1001 AND status = 'COMPLETED' AND create_time BETWEEN '2023-01-01' AND '2023-12-31' ORDER BY amount DESC; -- 执行计划分析: +----+-------------+--------+------+---------------+------+---------+------+--------+-------------+ | id | select_type | table | type | key | rows | filtered | Extra +----+-------------+--------+------+---------------+------+---------+------+--------+-------------+ | 1 | SIMPLE | orders | ALL | NULL | 100K | 1.00 | Using where; Using filesort +----+-------------+--------+------+---------------+------+---------+------+--------+-------------+ -- 问题诊断: -- 1. type=ALL: 全表扫描 -- 2. Using filesort: 文件排序 -- 3. 扫描行数多(100K),过滤率低(1%) -- 优化方案: -- 添加复合索引 ALTER TABLE orders ADD INDEX idx_user_status_time (user_id, status, create_time); -- 优化后执行计划: +----+-------------+--------+------+-----------------------+------+---------+-----+------+-------------+ | id | select_type | table | type | key | rows | filtered | Extra +----+-------------+--------+------+-----------------------+------+---------+-----+------+-------------+ | 1 | SIMPLE | orders | ref | idx_user_status_time | 100 | 100.00 | Using where +----+-------------+--------+------+-----------------------+------+---------+-----+------+-------------+
4.2 案例二:JOIN查询优化
-- 多表关联查询 EXPLAIN SELECT u.name, o.order_no, p.amount FROM users u JOIN orders o ON u.id = o.user_id JOIN payments p ON o.id = p.order_id WHERE u.country = 'US' AND o.status = 'COMPLETED' AND p.create_time >= '2023-01-01'; -- 执行计划分析及优化策略
4.3 Java代码中的执行计划集成
@Component
public class QueryOptimizer {
@Autowired
private JdbcTemplate jdbcTemplate;
/**
* 自动分析查询性能
*/
public void analyzeQuery(String sql, Object... params) {
String explainSql = "EXPLAIN FORMAT=JSON " + sql;
try {
String explainResult = jdbcTemplate.queryForObject(
explainSql, String.class, params);
JsonNode plan = new ObjectMapper().readTree(explainResult);
analyzeExecutionPlan(plan);
} catch (Exception e) {
logger.warn("执行计划分析失败: {}", e.getMessage());
}
}
private void analyzeExecutionPlan(JsonNode plan) {
double cost = plan.path("query_block")
.path("cost_info")
.path("query_cost")
.asDouble();
if (cost > 1000) {
logger.warn("高成本查询检测,执行成本: {}", cost);
// 触发告警或记录优化建议
}
// 分析全表扫描
if (hasFullTableScan(plan)) {
logger.warn("检测到全表扫描,建议添加合适索引");
}
}
private boolean hasFullTableScan(JsonNode plan) {
// 遍历执行计划树,检查是否有type=ALL的节点
return checkNodeForFullScan(plan);
}
}
5. 高级特性:EXPLAIN FORMAT=JSON与EXPLAIN ANALYZE
5.1 JSON格式详细分析
EXPLAIN FORMAT=JSON
SELECT u.name, COUNT(o.id)
FROM users u
LEFT JOIN orders o ON u.id = o.user_id
GROUP BY u.id;
-- JSON输出包含丰富信息:
{
"query_block": {
"select_id": 1,
"cost_info": {
"query_cost": "1250.25"
},
"nested_loop": [
{
"table": {
"table_name": "u",
"access_type": "index",
"rows_examined_per_scan": 10000,
"rows_produced_per_join": 10000,
"filtered": "100.00",
"cost_info": {
"read_cost": "250.25",
"eval_cost": "1000.00",
"prefix_cost": "1250.25",
"data_read_per_join": "15M"
}
}
}
]
}
}
5.2 EXPLAIN ANALYZE(MySQL 8.0+)
-- 实际执行统计(会真正执行查询) EXPLAIN ANALYZE SELECT * FROM orders WHERE user_id = 1001 AND create_time > '2023-01-01'; -- 输出示例: -> Index range scan on orders using idx_user_time over (user_id = 1001 and create_time > '2023-01-01') (cost=25.75 rows=240) (actual time=0.125..0.456 rows=215 loops=1)
6. 执行计划在Java开发中的实践应用
6.1 开发阶段的SQL审查
@Aspect
@Component
public class SqlPerformanceAspect {
private static final Logger logger = LoggerFactory.getLogger(SqlPerformanceAspect.class);
@Autowired
private JdbcTemplate jdbcTemplate;
@Around("execution(* com.example.repository.*.*(..))")
public Object monitorSqlPerformance(ProceedingJoinPoint joinPoint) throws Throwable {
String methodName = joinPoint.getSignature().getName();
// 获取执行的SQL(需要根据具体ORM框架调整)
String sql = extractSqlFromJoinPoint(joinPoint);
if (sql != null && isSelectQuery(sql)) {
analyzeSqlPerformance(sql);
}
return joinPoint.proceed();
}
private void analyzeSqlPerformance(String sql) {
try {
// 简化版执行计划分析
List<Map<String, Object>> explainResult =
jdbcTemplate.queryForList("EXPLAIN " + sql);
for (Map<String, Object> row : explainResult) {
String type = (String) row.get("type");
long rows = (Long) row.get("rows");
String extra = (String) row.get("Extra");
// 性能警告规则
if ("ALL".equals(type) && rows > 1000) {
logger.warn("发现全表扫描SQL: {}, 预估扫描行数: {}", sql, rows);
}
if (extra != null && extra.contains("Using filesort")) {
logger.warn("发现文件排序SQL: {}", sql);
}
}
} catch (Exception e) {
// 忽略分析异常,不影响业务
}
}
}
6.2 数据库访问层优化框架
@Repository
public class OptimizedUserRepository {
@Autowired
private JdbcTemplate jdbcTemplate;
/**
* 基于执行计划的智能查询方法
*/
public List<User> findActiveUsersByCountry(String country, int limit) {
String sql = "SELECT * FROM users WHERE country = ? AND status = 'ACTIVE' LIMIT ?";
// 执行前分析
analyzeQueryPlan(sql, country, limit);
return jdbcTemplate.query(sql, new Object[]{country, limit}, new UserRowMapper());
}
private void analyzeQueryPlan(String sql, Object... params) {
String explainSql = "EXPLAIN " + sql;
try {
Map<String, Object> plan = jdbcTemplate.queryForMap(explainSql, params);
String type = (String) plan.get("type");
String key = (String) plan.get("key");
if ("ALL".equals(type) && key == null) {
// 记录到监控系统
logSlowQueryWarning(sql, "FULL_TABLE_SCAN");
}
} catch (Exception e) {
// 分析失败不影响主流程
}
}
}
7. 常见执行计划模式与优化方案
7.1 全表扫描模式
-- 模式识别
EXPLAIN SELECT * FROM products WHERE name LIKE '%discount%';
-- 优化方案:
-- 1. 考虑全文索引
ALTER TABLE products ADD FULLTEXT(name);
-- 2. 修改查询模式(如确需前缀匹配)
-- 3. 考虑搜索引擎(Elasticsearch)
-- 优化后:
EXPLAIN SELECT * FROM products WHERE MATCH(name) AGAINST('discount');
7.2 文件排序模式
-- 问题查询 EXPLAIN SELECT * FROM orders WHERE user_id = 1001 ORDER BY create_time DESC; -- 优化:添加排序索引 ALTER TABLE orders ADD INDEX idx_user_time (user_id, create_time DESC); -- 优化后检查: EXPLAIN SELECT * FROM orders WHERE user_id = 1001 ORDER BY create_time DESC; -- Extra: Using index (不再显示Using filesort)
7.3 临时表模式
-- 复杂GROUP BY查询 EXPLAIN SELECT user_id, COUNT(*), AVG(amount) FROM orders GROUP BY user_id HAVING COUNT(*) > 5; -- 优化方案: -- 1. 添加覆盖索引 ALTER TABLE orders ADD INDEX idx_user_amount (user_id, amount); -- 2. 考虑预聚合表(数据仓库场景)
8. 监控与自动化优化
8.1 执行计划监控体系
# 监控配置示例
metrics:
execution_plans:
- name: full_table_scans
query: |
SELECT COUNT(*)
FROM information_schema.processlist
WHERE INFO LIKE 'SELECT%'
AND STATE = 'executing'
threshold: 5
- name: slow_queries
query: |
SELECT COUNT(*)
FROM mysql.slow_log
WHERE start_time > NOW() - INTERVAL 5 MINUTE
threshold: 10
8.2 自动化优化建议
@Service
public class AutoOptimizationService {
public void generateIndexSuggestions() {
// 基于执行计划历史分析索引需求
String analysisSql = """
SELECT TABLE_NAME, INDEX_COLUMN, USAGE_COUNT
FROM performance_schema.index_usage_stats
WHERE USAGE_EFFICIENCY < 0.5
ORDER BY USAGE_COUNT DESC
""";
// 生成索引创建建议
List<IndexSuggestion> suggestions = generateIndexSuggestionsFromStats();
// 在测试环境验证建议
validateSuggestionsInStaging(suggestions);
}
}
9. 总结
MySQL执行计划是Java开发者必须掌握的数据库性能分析工具。通过系统学习EXPLAIN的各个维度,我们能够:
- 快速定位:识别查询性能瓶颈
- 精准优化:制定有效的索引策略
- 预防问题:在开发阶段发现潜在风险
- 持续监控:建立性能保障体系
掌握执行计划分析,让数据库查询从"黑盒"变为"透明",为构建高性能Java应用奠定坚实基础。


















 6944
6944

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











