




一、什么是多模态大模型?
核心定义
多模态大模型是指能够同时处理和理解多种类型信息(如文本、图像、音频、视频等)的大型人工智能模型。它们打破了传统单一模态模型的局限,实现了跨模态的理解、推理和生成能力。
生动比喻:从单科专家到全科博士
- 单模态模型:像专科医生
-
- 文本模型:只懂语言,像眼科医生
- 视觉模型:只懂图像,像骨科医生
- 语音模型:只懂声音,像耳科医生
- 各精一域,但无法全面诊断
- 多模态模型:像全科医学博士
-
- 同时理解症状描述(文本)、X光片(图像)、患者口述(语音)
- 综合各种信息做出准确诊断
- 具备跨学科的全面知识
多模态的基本原理
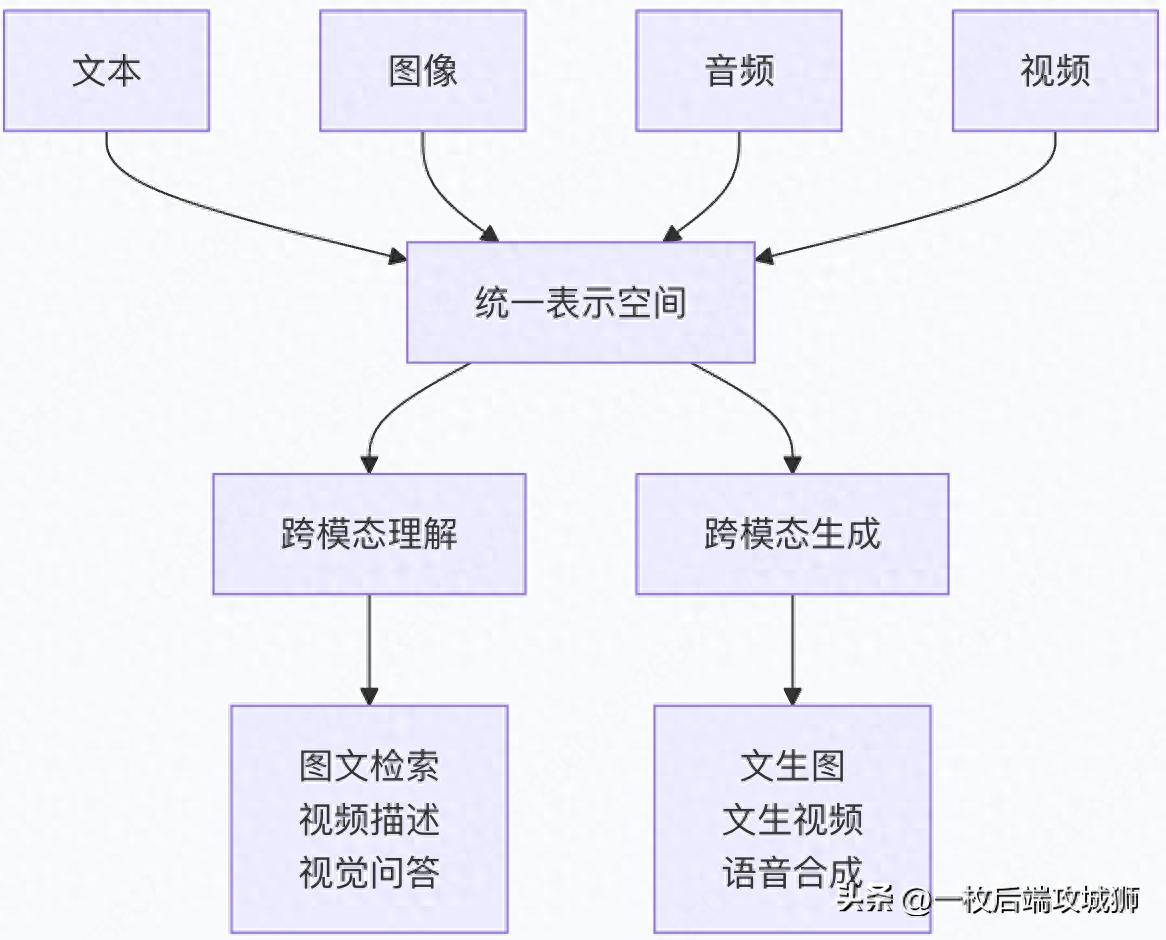
技术架构演进
# 多模态模型架构的演进
multimodal_evolution = {
"早期方法": {
"技术": "分别处理各模态,后期融合",
"例子": "分别提取图像和文本特征,然后拼接",
"缺点": "缺乏深层交互,理解有限"
},
"中期方法": {
"技术": "跨模态注意力机制",
"例子": "CLIP, ViLBERT",
"优点": "模态间交互,理解更深"
},
"现代方法": {
"技术": "统一编码器,任意模态输入输出",
"例子": "GPT-4V, DALL-E 3, Sora",
"优点": "无缝跨模态,端到端学习"
}
}
二、多模态大模型优势是什么?
1.更全面的世界理解
人类认知的模拟
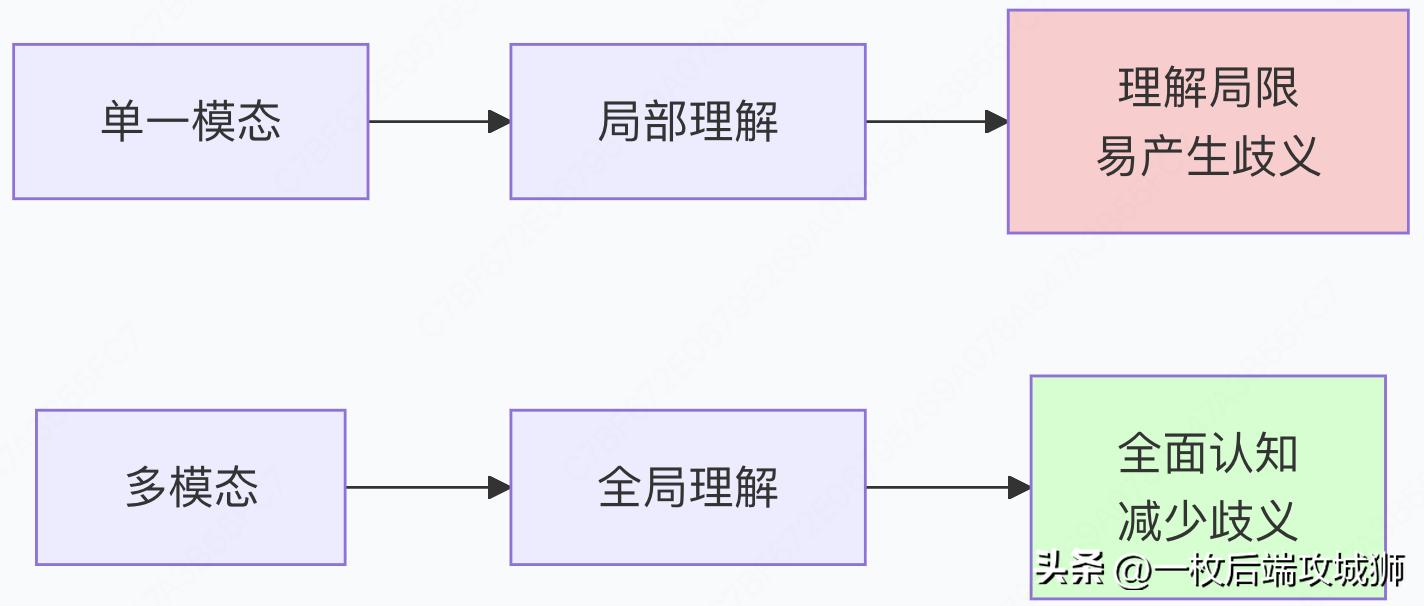
实际例子:
- 单模态:看到"苹果"文本,可能指水果或公司
- 多模态:结合苹果图片,立即确定含义
代码示例:多模态消歧
class MultimodalDisambiguation:
def __init__(self, text_model, vision_model, fusion_network):
self.text_model = text_model
self.vision_model = vision_model
self.fusion = fusion_network
def resolve_ambiguity(self, text_input, image_input):
# 提取文本特征
text_features = self.text_model.encode(text_input)
# 提取视觉特征
image_features = self.vision_model.encode(image_input)
# 多模态融合理解
fused_representation = self.fusion(text_features, image_features)
# 基于融合表示进行推理
interpretation = self.interpret(fused_representation)
return interpretation
def interpret(self, fused_features):
# 在多模态空间中进行推理
if self.is_fruit_apple(fused_features):
return "水果苹果"
elif self.is_company_apple(fused_features):
return "苹果公司"
else:
return "未知含义"
# 使用示例
disambiguator = MultimodalDisambiguation(text_model, vision_model, fusion_net)
text = "苹果发布了新产品"
image = load_image("apple_logo.jpg")
result = disambiguator.resolve_ambiguity(text, image)
print(f"含义: {result}") # 输出: "苹果公司"
2.更强的泛化能力
跨模态迁移学习
# 多模态模型的泛化优势
def multimodal_generalization_benefits():
benefits = {
"知识迁移": "从文本中学到的知识可以应用到视觉任务",
"数据效率": "多模态数据相互增强,减少对单一模态数据的依赖",
"鲁棒性": "某个模态缺失或噪声时,其他模态可补充"
}
# 实际研究结果
research_findings = {
"CLIP": "在ImageNet零样本识别中达到ResNet-50水平,无需训练",
"GPT-4V": "能理解复杂图表并解释,无需专门训练",
"DALL-E": "能生成训练数据中未出现过的概念组合"
}
return benefits, research_findings
3.更自然的人机交互
多模态交互场景
# 多模态交互的优势场景
multimodal_interaction_scenarios = {
"智能助手": {
"输入": "用户拍照询问+语音描述",
"处理": "同时理解图像和语音",
"输出": "语音回答+图文展示",
"优势": "交互自然,像人与人交流"
},
"教育应用": {
"输入": "学生手写公式+语音提问",
"处理": "识别笔迹+理解问题",
"输出": "分步骤解答+动画演示",
"优势": "个性化教学,多感官学习"
},
"医疗诊断": {
"输入": "医学影像+病历文本+医生口述",
"处理": "综合分析多源信息",
"输出": "诊断报告+治疗建议",
"优势": "全面评估,减少误诊"
}
}
4.创造力的突破
跨模态生成能力
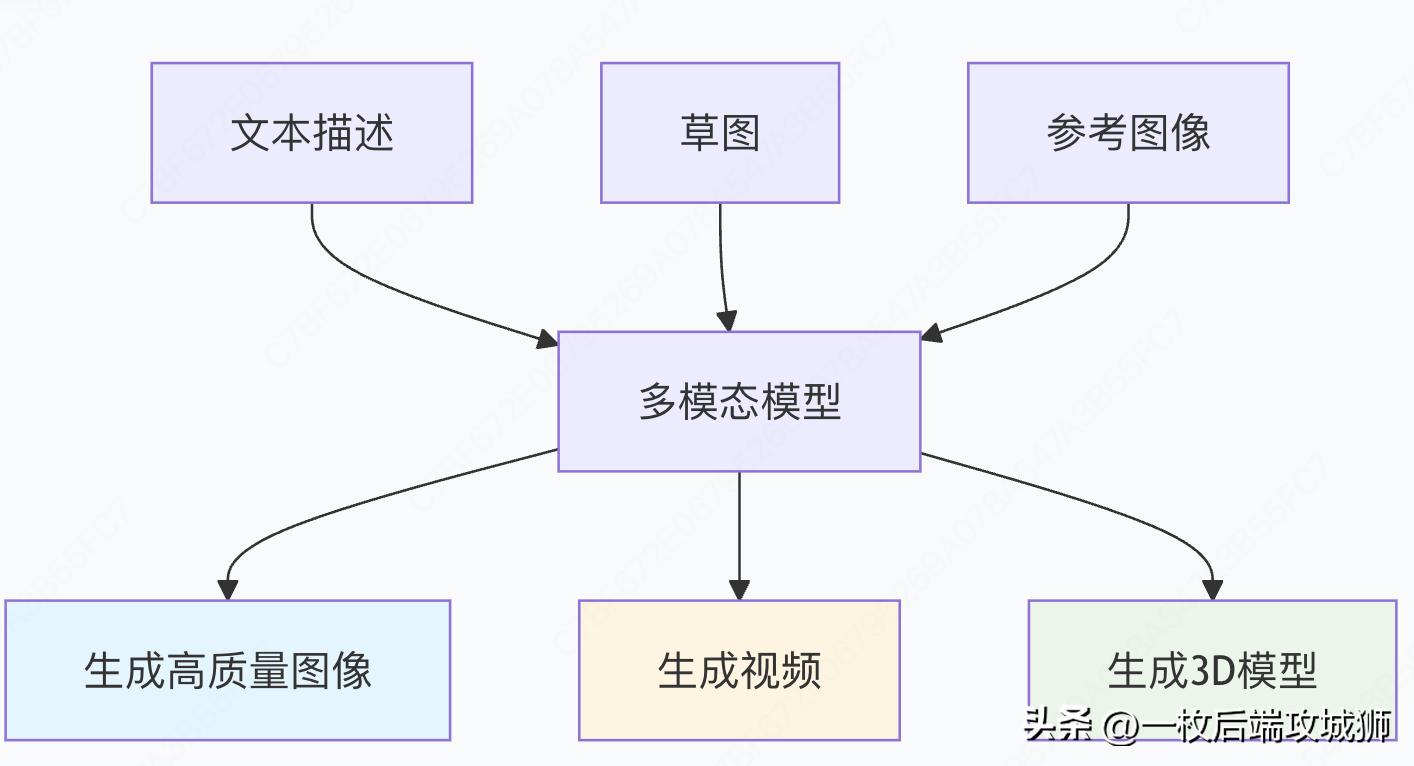
代码示例:创意生成
class CreativeMultimodalGenerator:
def __init__(self, model):
self.model = model
def generate_artwork(self, style_description, content_reference, mood_text):
"""基于多模态输入生成艺术作品"""
# 融合风格描述、内容参考和情感文本
multimodal_prompt = self.fuse_prompts(
style_description,
content_reference,
mood_text
)
# 生成图像
generated_image = self.model.generate_image(multimodal_prompt)
return generated_image
def create_story(self, initial_image, opening_text, character_descriptions):
"""基于图像和文本生成故事"""
# 分析初始图像
image_analysis = self.model.analyze_image(initial_image)
# 结合文本提示生成连贯故事
story = self.model.generate_story(
image_context=image_analysis,
text_prompt=opening_text,
characters=character_descriptions
)
return story
# 使用示例
generator = CreativeMultimodalGenerator(multimodal_model)
# 生成概念艺术
artwork = generator.generate_artwork(
style_description="梵高风格,鲜艳色彩",
content_reference=load_image("landscape_sketch.jpg"),
mood_text="宁静而充满希望的黄昏"
)
# 生成故事
story = generator.create_story(
initial_image=artwork,
opening_text="在一个遥远的星球上",
character_descriptions={"主角": "勇敢的太空探险家"}
)
三、有哪些多模态大模型?
1.开创性模型
CLIP - 连接文本和图像
# CLIP模型配置和特点
clip_model_info = {
"开发者": "OpenAI",
"发布时间": "2021",
"核心创新": "对比学习连接文本和图像表示",
"训练数据": "4亿个图文对",
"能力": {
"零样本图像分类": "无需训练直接分类",
"图文检索": "跨模态搜索",
"图像生成引导": "为DALL-E提供基础"
},
"架构": {
"文本编码器": "Transformer",
"图像编码器": "ViT或CNN",
"损失函数": "对比损失"
}
}
# CLIP工作原理伪代码
class CLIPModel:
def __init__(self, text_encoder, image_encoder, projection_dim):
self.text_encoder = text_encoder
self.image_encoder = image_encoder
self.text_projection = nn.Linear(text_encoder.dim, projection_dim)
self.image_projection = nn.Linear(image_encoder.dim, projection_dim)
def forward(self, text, images):
# 编码文本和图像
text_features = self.text_encoder(text)
image_features = self.image_encoder(images)
# 投影到共享空间
text_embeddings = self.text_projection(text_features)
image_embeddings = self.image_projection(image_features)
# 归一化
text_embeddings = F.normalize(text_embeddings, dim=-1)
image_embeddings = F.normalize(image_embeddings, dim=-1)
# 计算相似度矩阵
logits = torch.matmul(text_embeddings, image_embeddings.T) * self.temperature
return logits
DALL-E系列 - 文本到图像生成
dalle_evolution = {
"DALL-E 1": {
"发布时间": "2021年1月",
"核心能力": "从文本生成图像",
"技术特点": "离散VAE + Transformer",
"训练数据": "数亿图文对",
"生成质量": "256x256分辨率,概念组合能力强"
},
"DALL-E 2": {
"发布时间": "2022年4月",
"改进点": "更高的分辨率和真实性",
"新技术": "扩散模型 + CLIP引导",
"分辨率": "1024x1024",
"应用": "商业设计、艺术创作"
},
"DALL-E 3": {
"发布时间": "2023年",
"重大改进": "更好的提示跟随和细节",
"集成": "与ChatGPT深度集成",
"安全性": "更强的内容过滤"
}
}
2.通用多模态模型
GPT-4V - 多模态理解大师
gpt4v_capabilities = {
"模型全称": "GPT-4 with Vision",
"发布方": "OpenAI",
"核心能力": "理解和推理多模态内容",
"支持模态": ["文本", "图像", "文档", "图表"],
"典型应用": {
"视觉问答": "回答关于图像的问题",
"文档分析": "理解扫描文档和表格",
"代码生成": "根据图表生成代码",
"创意写作": "基于图像启发创作"
},
"技术特点": {
"架构": "基于GPT-4扩展视觉编码器",
"训练": "大规模多模态数据",
"安全性": "多层级内容审核"
}
}
# GPT-4V使用示例
class GPT4VApplication:
def analyze_complex_image(self, image, question):
"""分析复杂图像并回答问题"""
response = gpt4v.chat([
{"role": "user", "content": [
{"type": "text", "text": question},
{"type": "image", "image": image}
]}
])
return response
def document_understanding(self, document_image):
"""理解文档内容"""
prompt = "请总结这个文档的主要内容和关键信息"
return self.analyze_complex_image(document_image, prompt)
def technical_diagram_analysis(self, diagram, target_framework):
"""分析技术图表并生成代码"""
prompt = f"请分析这个架构图并用{target_framework}实现核心组件"
return self.analyze_complex_image(diagram, prompt)
Gemini - 原生多模态设计
gemini_model_info = {
"开发方": "Google DeepMind",
"设计理念": "原生多模态,从底层支持多种模态",
"模型规模": ["Gemini Ultra", "Gemini Pro", "Gemini Nano"],
"模态支持": ["文本", "图像", "音频", "视频", "代码"],
"技术突破": {
"协同训练": "同时训练所有模态,而非后期融合",
"高效推理": "优化跨模态注意力机制",
"多尺度处理": "处理不同粒度的多模态信息"
},
"性能表现": {
"MMLU": "90.0% (超越人类专家)",
"图像理解": "在多个基准测试中领先",
"代码生成": "在HumanEval上达到顶级水平"
}
}
3.开源多模态模型
LLaVA - 开源多模态助手
llava_model_info = {
"全称": "Large Language and Vision Assistant",
"特点": "将预训练视觉编码器与LLM连接",
"训练数据": "GPT-4生成的视觉指令数据",
"版本演进": {
"LLaVA-1.5": "使用CLIP-ViT和Vicuna,在11个基准上达到SOTA",
"LLaVA-1.6": "改进的视觉编码器和训练配方"
},
"应用场景": [
"学术研究",
"低成本多模态应用",
"定制化开发基础"
]
}
# LLaVA架构示例
class LLaVAModel:
def __init__(self, vision_tower, language_model, connector):
self.vision_tower = vision_tower # 通常为CLIP-ViT
self.language_model = language_model # 如Vicuna, LLaMA
self.connector = connector # 投影层,连接视觉和语言特征
def process_multimodal_input(self, image, text):
# 提取视觉特征
visual_features = self.vision_tower.encode(image)
# 投影到语言模型空间
projected_visual = self.connector(visual_features)
# 与文本特征结合
combined_input = self.combine_features(projected_visual, text)
# 语言模型生成响应
response = self.language_model.generate(combined_input)
return response
OpenFlamingo - 开源多模态对话
openflamingo_info = {
"基于": "CLIP视觉编码器 + LLaMA语言模型",
"特点": "支持交错的多模态输入(图像、文本交替)",
"能力": "视觉对话、推理、描述",
"训练": "大规模多模态网页数据",
"优势": "灵活的对话形式,强大的上下文学习"
}
4.视频生成模型
Sora - 文本到视频生成
sora_model_info = {
"开发方": "OpenAI",
"发布时间": "2024年2月",
"核心能力": "从文本生成高质量视频",
"视频参数": {
"长度": "最多60秒",
"分辨率": "1920x1080",
"连贯性": "保持物体在时间上的一致性"
},
"技术特点": {
"架构": "扩散Transformer",
"训练数据": "海量视频和图文数据",
"创新": "时空 patches 表示"
},
"应用前景": [
"影视制作",
"游戏开发",
"广告创意",
"教育内容"
]
}
Runway、Pika等视频生成工具
video_generation_ecosystem = {
"Runway Gen-2": {
"类型": "商业视频生成平台",
"能力": "文本/图像到视频",
"特色": "运动控制、风格化"
},
"Pika Labs": {
"类型": "AI视频生成工具",
"优势": "用户友好,快速迭代",
"应用": "社交媒体内容创作"
},
"Stable Video Diffusion": {
"类型": "开源视频生成",
"基于": "Stable Diffusion",
"特点": "可定制性强"
}
}
多模态模型对比表格
|
模型 |
开发方 |
主要能力 |
模态支持 |
特点 |
|
CLIP |
OpenAI |
图文理解 |
文本、图像 |
零样本能力强 |
|
DALL-E 3 |
OpenAI |
文生图 |
文本→图像 |
提示跟随优秀 |
|
GPT-4V |
OpenAI |
多模态理解 |
文本、图像 |
推理能力强 |
|
Gemini |
|
通用多模态 |
文本、图像、音频、视频 |
原生多模态设计 |
|
LLaVA |
开源 |
视觉对话 |
文本、图像 |
成本低,可定制 |
|
Sora |
OpenAI |
文生视频 |
文本→视频 |
时间连贯性好 |
四、多模态大模型的技术挑战与未来
当前技术挑战
multimodal_challenges = {
"表示对齐": {
"问题": "不同模态的语义空间对齐困难",
"例子": "文本'红色'与视觉红色的精确对应",
"研究方向": "更好的跨模态表示学习"
},
"数据稀缺": {
"问题": "高质量多模态训练数据有限",
"例子": "精确的图文对、视频文本描述",
"解决方案": "合成数据、自监督学习"
},
"计算复杂度": {
"问题": "处理多模态数据计算需求大",
"影响": "训练和推理成本高",
"优化方向": "模型压缩、高效注意力"
},
"评估困难": {
"问题": "缺乏统一的多模态评估标准",
"现状": "各任务使用不同指标",
"未来": "建立综合评估体系"
}
}
未来发展方向
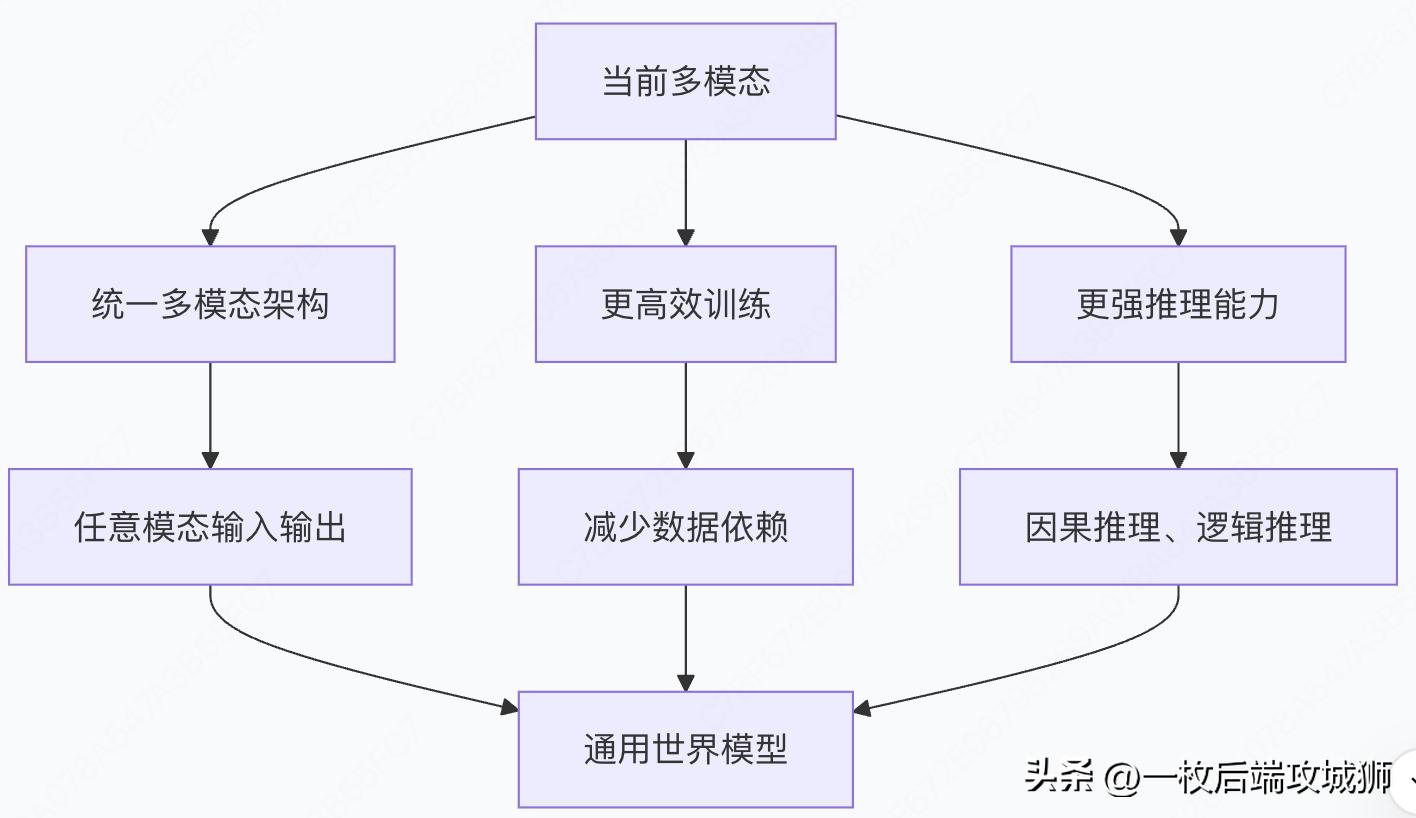
实际应用建议
# 多模态模型选择指南
def select_multimodal_model(requirements):
"""
根据需求选择合适的多模态模型
"""
if requirements["budget"] == "high" and requirements["quality"] == "best":
recommendations = {
"图文生成": "DALL-E 3",
"多模态理解": "GPT-4V",
"视频生成": "Sora",
"理由": "性能最优,但API调用成本高"
}
elif requirements["open_source"] == True:
recommendations = {
"图文对话": "LLaVA",
"文生图": "Stable Diffusion",
"多模态检索": "OpenCLIP",
"理由": "可定制,成本可控"
}
elif requirements["real_time"] == True:
recommendations = {
"移动端应用": "Gemini Nano",
"边缘计算": "定制小模型",
"理由": "低延迟,离线可用"
}
return recommendations
# 使用示例
project_needs = {
"budget": "medium",
"quality": "good",
"open_source": True,
"real_time": False
}
suggestions = select_multimodal_model(project_needs)
print("推荐模型方案:", suggestions)
总结:多模态智能的新纪元
技术革命的本质
多模态大模型不仅仅是技术的叠加,而是认知能力的质变:
- 从单感官到多感官:模拟人类的多模态感知
- 从理解到创造:跨越模态的内容生成
- 从工具到伙伴:更自然的人机协作
核心价值总结
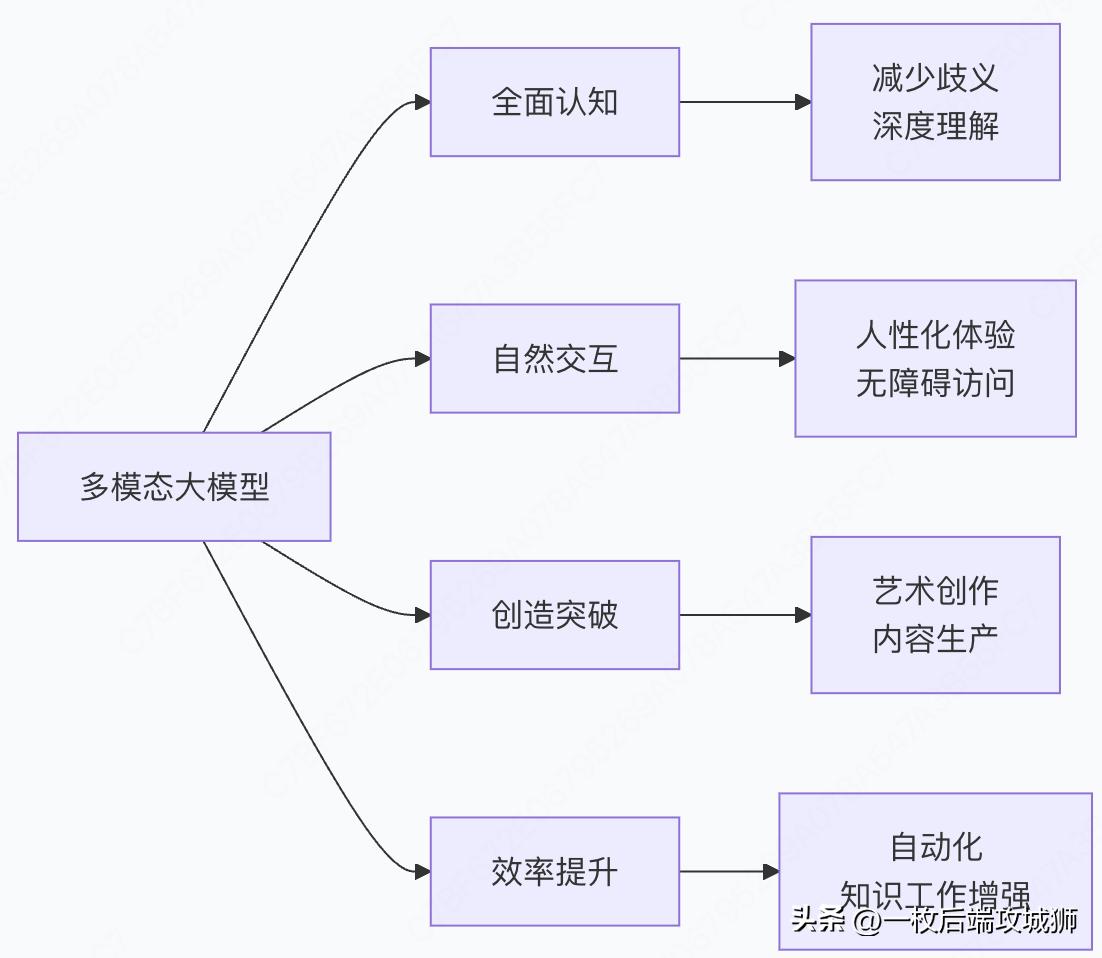
发展前景展望
- 技术融合:多模态与具身智能、世界模型结合
- 应用普及:从专业领域到日常生活全方位渗透
- 伦理规范:建立多模态AI的负责任使用框架
- 民主化:开源模型降低技术门槛,促进创新
多模态大模型正在重新定义人工智能的边界,让我们朝着构建真正通用人工智能迈出了关键一步。这不仅是技术的进步,更是人类认知边界的拓展,为解决复杂问题、激发创造力、增强人类能力开辟了全新的可能性。
正如人类通过多感官体验理解世界,多模态AI正在学会用"数字感官"来感知和创造,这将深刻改变我们与机器交互的方式,乃至重新定义什么是"智能"。


















 742
742

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











