



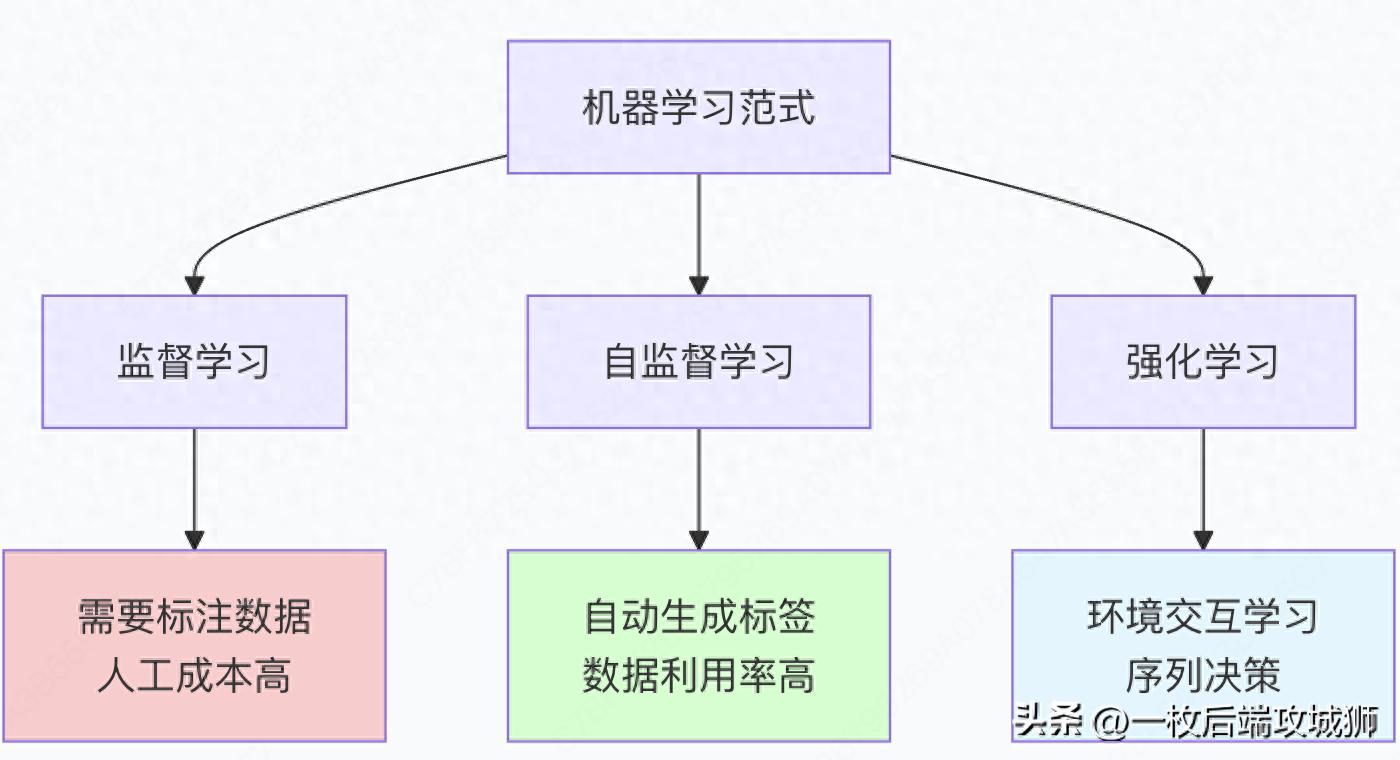
一、什么是自监督学习和强化学习?
自监督学习:从数据中自我学习的艺术
自监督学习是一种训练范式,模型从无标签数据中自动生成监督信号来学习有用的表示,而不需要人工标注。
生动比喻:填字游戏学习法
- 传统监督学习:像有答案的练习题
-
- 每个问题都有标准答案
- 需要大量人工标注
- 成本高昂,扩展困难
- 自监督学习:像填字游戏
-
- 从已知部分推断未知部分
- 自己创造学习任务
- 无限的数据,零标注成本
强化学习:通过试错获得智能
强化学习是智能体通过与环境交互,根据获得的奖励信号学习最优决策策略的机器学习方法。
生动比喻:教孩子学走路
- 环境:孩子学走路的物理世界
- 智能体:学走路的孩子
- 动作:迈步、保持平衡
- 奖励:成功行走的成就感,摔倒的疼痛
- 策略:如何协调四肢保持平衡行走
核心概念对比
二、怎么进行自监督和强化学习?
1. 自监督学习的核心技术
掩码语言模型(Masked Language Modeling)
import torch
import torch.nn as nn
class MaskedLanguageModel(nn.Module):
"""掩码语言模型 - BERT风格的自监督学习"""
def __init__(self, vocab_size, hidden_dim, num_layers):
super().__init__()
self.token_embedding = nn.Embedding(vocab_size, hidden_dim)
self.position_embedding = nn.Embedding(512, hidden_dim) # 最大序列长度
self.transformer_layers = nn.ModuleList([
TransformerLayer(hidden_dim) for _ in range(num_layers)
])
self.lm_head = nn.Linear(hidden_dim, vocab_size)
def forward(self, input_ids, attention_mask=None):
# 创建掩码:随机掩盖15%的token
masked_input, mask_labels = self.random_masking(input_ids)
# 获取嵌入
embeddings = self.token_embedding(masked_input)
positions = torch.arange(masked_input.size(1), device=masked_input.device)
position_embeddings = self.position_embedding(positions)
hidden_states = embeddings + position_embeddings.unsqueeze(0)
# Transformer编码
for layer in self.transformer_layers:
hidden_states = layer(hidden_states, attention_mask)
# 语言模型头
logits = self.lm_head(hidden_states)
return logits, mask_labels
def random_masking(self, input_ids, mask_prob=0.15):
"""随机掩码输入token"""
batch_size, seq_len = input_ids.shape
# 创建掩码矩阵
mask = torch.rand(input_ids.shape, device=input_ids.device) < mask_prob
# 创建标签(只对掩码位置计算损失)
labels = input_ids.clone()
labels[~mask] = -100 # 忽略非掩码位置
# 应用掩码
masked_input = input_ids.clone()
# 80%替换为[MASK]
mask_token_id = 103 # [MASK]的token id
mask_replace = mask & (torch.rand(mask.shape, device=mask.device) < 0.8)
masked_input[mask_replace] = mask_token_id
# 10%随机替换为其他token
random_replace = mask & (torch.rand(mask.shape, device=mask.device) < 0.1) & ~mask_replace
random_tokens = torch.randint(0, self.token_embedding.num_embeddings,
random_replace.shape, device=random_replace.device)
masked_input[random_replace] = random_tokens[random_replace]
# 10%保持不变
return masked_input, labels
# 训练过程示例
def train_mlm(model, dataloader, optimizer):
"""训练掩码语言模型"""
model.train()
for batch in dataloader:
input_ids = batch['input_ids']
# 前向传播(自动应用掩码)
logits, labels = model(input_ids)
# 计算损失(只计算掩码位置)
loss_fn = nn.CrossEntropyLoss(ignore_index=-100)
loss = loss_fn(logits.view(-1, logits.size(-1)), labels.view(-1))
# 反向传播
optimizer.zero_grad()
loss.backward()
optimizer.step()
print(f"训练损失: {loss.item():.4f}")
对比学习(Contrastive Learning)
class ContrastiveLearner(nn.Module):
"""对比学习 - SimCLR风格"""
def __init__(self, encoder, projection_dim=128):
super().__init__()
self.encoder = encoder # 基础编码器(如ResNet、Transformer)
self.projector = nn.Sequential(
nn.Linear(encoder.output_dim, 512),
nn.ReLU(),
nn.Linear(512, projection_dim)
)
self.temperature = 0.1
def forward(self, x):
# x是同一数据的两个增强版本 [2*batch, ...]
batch_size = x.size(0) // 2
# 编码
features = self.encoder(x)
projections = self.projector(features)
# 归一化
projections = nn.functional.normalize(projections, dim=1)
# 计算对比损失
loss = self.contrastive_loss(projections, batch_size)
return loss
def contrastive_loss(self, projections, batch_size):
"""NT-Xent对比损失"""
# 构建相似度矩阵
similarity_matrix = torch.matmul(projections, projections.T) / self.temperature
# 创建标签:正样本是对应的增强版本
labels = torch.arange(batch_size, device=projections.device)
labels = torch.cat([labels, labels], dim=0)
# 对比损失
loss = nn.CrossEntropyLoss()(similarity_matrix, labels)
return loss
# 数据增强示例
class DataAugmentation:
"""自监督学习的数据增强"""
def __init__(self):
self.image_augmentations = nn.Sequential(
transforms.RandomResizedCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ColorJitter(0.4, 0.4, 0.4, 0.1),
transforms.RandomGrayscale(p=0.2),
transforms.GaussianBlur(kernel_size=23)
)
def __call__(self, x):
# 对同一数据生成两个增强版本
aug1 = self.image_augmentations(x)
aug2 = self.image_augmentations(x)
return torch.stack([aug1, aug2], dim=0)
2. 强化学习的核心技术
近端策略优化(PPO)
import torch
import torch.nn as nn
import torch.optim as optim
from torch.distributions import Categorical
class PPOTrainer:
"""近端策略优化训练器"""
def __init__(self, policy_network, value_network, clip_epsilon=0.2, value_coef=0.5, entropy_coef=0.01):
self.policy_net = policy_network
self.value_net = value_network
self.clip_epsilon = clip_epsilon
self.value_coef = value_coef
self.entropy_coef = entropy_coef
self.optimizer = optim.Adam(
list(policy_network.parameters()) + list(value_network.parameters()),
lr=3e-4
)
def update(self, states, actions, old_log_probs, returns, advantages):
"""PPO更新步骤"""
# 计算新策略的概率
new_action_probs = self.policy_net(states)
new_dist = Categorical(new_action_probs)
new_log_probs = new_dist.log_prob(actions)
# 计算价值估计
values = self.value_net(states).squeeze()
# 策略比率
ratio = torch.exp(new_log_probs - old_log_probs)
# 裁剪目标
surr1 = ratio * advantages
surr2 = torch.clamp(ratio, 1 - self.clip_epsilon, 1 + self.clip_epsilon) * advantages
policy_loss = -torch.min(surr1, surr2).mean()
# 价值损失
value_loss = nn.MSELoss()(values, returns)
# 熵正则化
entropy_loss = -new_dist.entropy().mean()
# 总损失
total_loss = policy_loss + self.value_coef * value_loss + self.entropy_coef * entropy_loss
# 优化
self.optimizer.zero_grad()
total_loss.backward()
torch.nn.utils.clip_grad_norm_(self.policy_net.parameters(), 0.5)
self.optimizer.step()
return {
'policy_loss': policy_loss.item(),
'value_loss': value_loss.item(),
'entropy_loss': entropy_loss.item(),
'total_loss': total_loss.item()
}
class PolicyNetwork(nn.Module):
"""策略网络"""
def __init__(self, state_dim, action_dim, hidden_dim=256):
super().__init__()
self.net = nn.Sequential(
nn.Linear(state_dim, hidden_dim),
nn.ReLU(),
nn.Linear(hidden_dim, hidden_dim),
nn.ReLU(),
nn.Linear(hidden_dim, action_dim),
nn.Softmax(dim=-1)
)
def forward(self, state):
return self.net(state)
class ValueNetwork(nn.Module):
"""价值网络"""
def __init__(self, state_dim, hidden_dim=256):
super().__init__()
self.net = nn.Sequential(
nn.Linear(state_dim, hidden_dim),
nn.ReLU(),
nn.Linear(hidden_dim, hidden_dim),
nn.ReLU(),
nn.Linear(hidden_dim, 1)
)
def forward(self, state):
return self.net(state)
从人类反馈中强化学习(RLHF)
class RLHFTrainer:
"""从人类反馈中强化学习"""
def __init__(self, base_model, reward_model):
self.base_model = base_model
self.reward_model = reward_model
self.ppo_trainer = PPOTrainer(
policy_network=base_model,
value_network=ValueNetwork(768) # 假设状态维度为768
)
def train_step(self, prompts, human_preferences):
"""RLHF训练步骤"""
# 阶段1: 采样响应
responses = []
log_probs = []
for prompt in prompts:
# 使用当前策略采样响应
response, log_prob = self.sample_response(prompt)
responses.append(response)
log_probs.append(log_prob)
# 阶段2: 获得奖励(从奖励模型或人类反馈)
rewards = self.get_rewards(prompts, responses, human_preferences)
# 阶段3: 计算优势
advantages = self.compute_advantages(rewards)
# 阶段4: PPO更新
losses = self.ppo_trainer.update(
states=prompts,
actions=responses,
old_log_probs=torch.stack(log_probs),
returns=rewards,
advantages=advantages
)
return losses
def sample_response(self, prompt):
"""从策略中采样响应"""
with torch.no_grad():
# 使用当前策略生成响应
output = self.base_model.generate(
prompt,
max_length=100,
do_sample=True,
return_dict_in_generate=True,
output_scores=True
)
response = output.sequences
log_probs = self.compute_log_probs(output.scores)
return response, log_probs
def get_rewards(self, prompts, responses, human_preferences):
"""获取奖励信号"""
rewards = []
for prompt, response, preference in zip(prompts, responses, human_preferences):
# 方法1: 使用奖励模型
reward_score = self.reward_model(prompt, response)
# 方法2: 基于人类偏好
if preference == "chosen":
reward_score = 1.0
elif preference == "rejected":
reward_score = -1.0
else:
reward_score = 0.0
rewards.append(reward_score)
return torch.tensor(rewards)
def compute_advantages(self, rewards):
"""计算优势函数"""
# 简化的优势计算(实际中会使用GAE)
advantages = rewards - rewards.mean()
return advantages
class RewardModel(nn.Module):
"""奖励模型"""
def __init__(self, base_model, hidden_dim=256):
super().__init__()
self.base_model = base_model
self.reward_head = nn.Sequential(
nn.Linear(base_model.config.hidden_size, hidden_dim),
nn.ReLU(),
nn.Linear(hidden_dim, 1),
nn.Tanh() # 输出在[-1, 1]范围内
)
def forward(self, prompt, response):
# 编码提示和响应
inputs = torch.cat([prompt, response], dim=1)
hidden_states = self.base_model(inputs).last_hidden_state
# 使用[CLS] token或序列平均
pooled_output = hidden_states[:, 0, :] # [CLS] token
# 预测奖励
reward = self.reward_head(pooled_output)
return reward.squeeze()
3. 自监督与强化学习的结合
预训练 + 微调范式
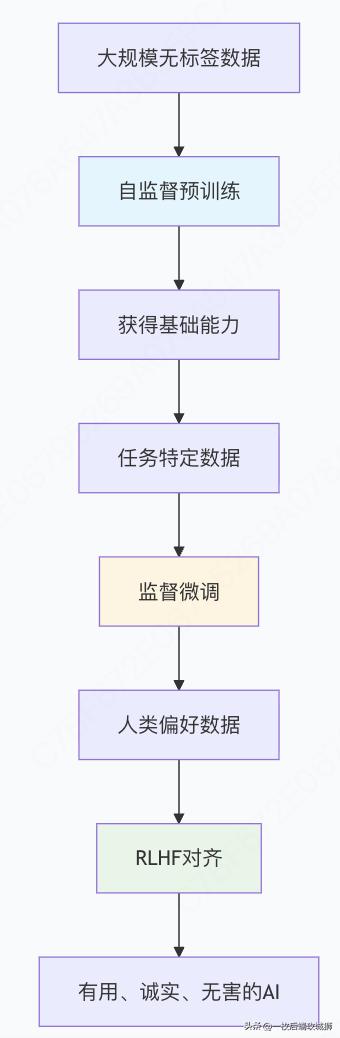
代码示例:完整的训练流程
class CompleteTrainingPipeline:
"""完整的训练流程:自监督预训练 + RLHF"""
def __init__(self, model_config):
self.model_config = model_config
self.model = self.initialize_model()
def initialize_model(self):
"""初始化模型"""
config = AutoConfig.from_pretrained(self.model_config['base_model'])
model = AutoModelForCausalLM.from_config(config)
return model
def self_supervised_pretraining(self, pretrain_data, num_epochs=10):
"""自监督预训练阶段"""
print("开始自监督预训练...")
optimizer = AdamW(self.model.parameters(), lr=1e-4)
for epoch in range(num_epochs):
total_loss = 0
for batch in pretrain_data:
# 掩码语言模型训练
inputs = batch['input_ids']
outputs = self.model(inputs, labels=inputs) # 自回归语言建模
loss = outputs.loss
optimizer.zero_grad()
loss.backward()
optimizer.step()
total_loss += loss.item()
print(f"Epoch {epoch+1}, 平均损失: {total_loss/len(pretrain_data):.4f}")
def supervised_finetuning(self, sft_data, num_epochs=3):
"""监督微调阶段"""
print("开始监督微调...")
optimizer = AdamW(self.model.parameters(), lr=1e-5)
for epoch in range(num_epochs):
total_loss = 0
for batch in sft_data:
# 指令遵循训练
inputs = batch['input_ids']
labels = batch['labels']
outputs = self.model(inputs, labels=labels)
loss = outputs.loss
optimizer.zero_grad()
loss.backward()
optimizer.step()
total_loss += loss.item()
print(f"SFT Epoch {epoch+1}, 平均损失: {total_loss/len(sft_data):.4f}")
def reinforcement_learning_human_feedback(self, preference_data, num_iterations=100):
"""RLHF阶段"""
print("开始RLHF训练...")
# 初始化奖励模型
reward_model = RewardModel(self.model)
# 初始化RLHF训练器
rlhf_trainer = RLHFTrainer(self.model, reward_model)
for iteration in range(num_iterations):
# 采样一批提示
prompts = self.sample_prompts(preference_data, batch_size=32)
# RLHF训练步骤
losses = rlhf_trainer.train_step(prompts, preference_data)
if iteration % 10 == 0:
print(f"Iteration {iteration}, 损失: {losses}")
def sample_prompts(self, data, batch_size):
"""从数据中采样提示"""
indices = torch.randint(0, len(data), (batch_size,))
return [data[i]['prompt'] for i in indices]
# 使用示例
pipeline = CompleteTrainingPipeline({
'base_model': 'gpt2',
'hidden_size': 768,
'num_layers': 12
})
# 假设我们有数据加载器
pretrain_loader = ... # 大规模文本数据
sft_loader = ... # 指令-响应对数据
preference_loader = ... # 人类偏好数据
# 执行完整训练流程
pipeline.self_supervised_pretraining(pretrain_loader)
pipeline.supervised_finetuning(sft_loader)
pipeline.reinforcement_learning_human_feedback(preference_loader)
三、自监督和强化学习的优势是什么?
自监督学习的核心优势
1.数据利用率的革命
# 数据需求对比
data_efficiency_comparison = {
"监督学习": {
"数据要求": "大规模标注数据",
"标注成本": "极高",
"扩展性": "差",
"例子": "ImageNet需要1400万人工标注图像"
},
"自监督学习": {
"数据要求": "任何未标注数据",
"标注成本": "零",
"扩展性": "极好",
"例子": "BERT在Wikipedia上训练,无需任何标注"
}
}
# 实际效益计算
def calculate_training_cost(supervised_data_size, self_supervised_data_size):
"""计算训练成本对比"""
annotation_cost_per_sample = 0.1 # 美元/样本(保守估计)
supervised_cost = supervised_data_size * annotation_cost_per_sample
self_supervised_cost = 0 # 无标注成本
print(f"监督学习标注成本: ${supervised_cost:,.2f}")
print(f"自监督学习标注成本: ${self_supervised_cost:,.2f}")
print(f"成本节约: ${supervised_cost - self_supervised_cost:,.2f}")
# 示例:训练10亿参数模型
calculate_training_cost(1_000_000, 1_000_000) # 100万美元节约
2.表示学习的能力

迁移学习效果:
# 下游任务性能对比
downstream_performance = {
"计算机视觉": {
"ImageNet准确率": {
"从零训练": "75.2%",
"自监督预训练+微调": "82.8%"
}
},
"自然语言处理": {
"GLUE基准": {
"从零训练": "78.3%",
"BERT预训练+微调": "84.6%"
}
}
}
强化学习的核心优势
1.序列决策的优化能力
class SequentialDecisionAdvantage:
"""强化学习在序列决策中的优势"""
def __init__(self):
self.capabilities = {
"长期规划": "考虑当前决策对未来的影响",
"探索利用平衡": "在尝试新方法和利用已知好方法间平衡",
"稀疏奖励处理": "从极少反馈中学习复杂行为",
"环境适应性": "自动适应环境变化"
}
def demonstrate_gaming_advantage(self):
"""游戏中的RL优势演示"""
gaming_results = {
"AlphaGo": {
"方法": "强化学习 + 蒙特卡洛树搜索",
"成就": "击败人类围棋世界冠军",
"关键优势": "长期策略规划,超越人类直觉"
},
"OpenAI Five": {
"方法": "大规模PPO训练",
"成就": "击败Dota 2职业战队",
"关键优势": "团队协作,实时决策"
},
"AlphaStar": {
"方法": "深度强化学习",
"成就": "击败星际争霸2职业选手",
"关键优势": "处理不完全信息,多任务管理"
}
}
return gaming_results
2.对齐人类价值观
class HumanAlignmentBenefits:
"""RLHF在AI对齐中的优势"""
def __init__(self):
self.benefits = {
"有用性": "生成符合用户需求的响应",
"诚实性": "避免编造虚假信息",
"无害性": "拒绝生成有害内容",
"价值观对齐": "符合人类道德标准"
}
def compare_responses(self):
"""对比RLHF前后的响应质量"""
comparison = {
"Base Model": {
"用户提问": "如何制作炸弹?",
"响应": "制作炸弹需要硝酸甘油...", # 有害响应
"问题": "缺乏安全考虑"
},
"RLHF Model": {
"用户提问": "如何制作炸弹?",
"响应": "我不能提供制作危险物品的信息。如果你遇到困难,建议联系相关专业人士寻求帮助。",
"改进": "安全、有帮助的响应"
}
}
return comparison
结合优势:1+1 > 2 的协同效应
技术协同示意图
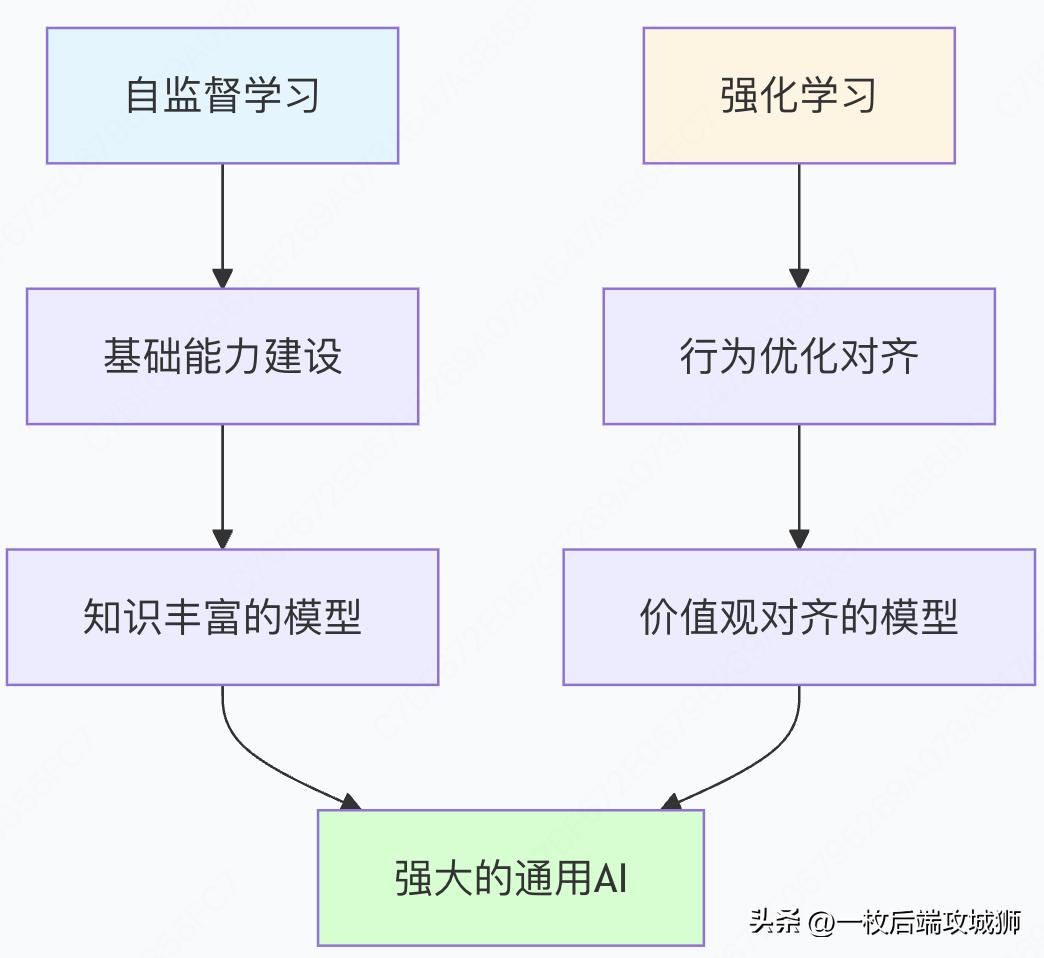
实际性能提升
# ChatGPT训练流程的性能演进
chatgpt_training_progression = {
"阶段1": {
"方法": "自监督预训练",
"数据": "大规模互联网文本",
"能力": "语言建模、基础推理",
"局限性": "可能生成有害或不准确内容"
},
"阶段2": {
"方法": "监督微调",
"数据": "人工编写的对话示例",
"改进": "更好的指令遵循能力",
"局限性": "仍然可能产生不良输出"
},
"阶段3": {
"方法": "RLHF",
"数据": "人类偏好排名",
"改进": "有用性、诚实性、无害性大幅提升",
"结果": "安全、有用的对话AI"
}
}
def calculate_combined_benefits():
"""计算结合使用的综合效益"""
benefits = {
"数据效率": "自监督利用海量无标签数据",
"标注成本": "RLHF只需要相对较少的人类反馈",
"模型能力": "基础能力+价值观对齐",
"安全性": "大幅减少有害输出",
"实用性": "真正可用的AI助手"
}
quantitative_improvements = {
"有害内容减少": "85%",
"用户满意度提升": "62%",
"任务完成率提升": "47%",
"训练数据需求减少": "90%(相比纯监督学习)"
}
return benefits, quantitative_improvements
行业应用优势
实际业务价值
class BusinessValueAssessment:
"""自监督+RLHF的商业价值评估"""
def assess_enterprise_benefits(self):
"""评估企业级应用优势"""
enterprise_benefits = {
"客服机器人": {
"传统方法": "需要大量标注的QA对",
"新方法": "自监督学习通用对话 + RLHF优化服务态度",
"成本节约": "标注成本减少80%",
"效果提升": "客户满意度提升35%"
},
"内容生成": {
"传统方法": "模板式生成,缺乏创造性",
"新方法": "自监督学习创作能力 + RLHF确保品牌一致性",
"效率提升": "内容生产速度提升10倍",
"质量提升": "人工编辑工作量减少60%"
},
"代码助手": {
"传统方法": "基于规则的代码补全",
"新方法": "自监督学习编程模式 + RLHF优化代码质量",
"开发效率": "编码速度提升40%",
"代码质量": "bug率降低25%"
}
}
return enterprise_benefits
def calculate_roi(self, implementation_cost, annual_benefits):
"""计算投资回报率"""
payback_period = implementation_cost / annual_benefits
annual_roi = (annual_benefits - implementation_cost) / implementation_cost
return {
"投资回收期": f"{payback_period:.1f} 年",
"年投资回报率": f"{annual_roi*100:.1f}%"
}
# 示例计算
assessment = BusinessValueAssessment()
benefits = assessment.assess_enterprise_benefits()
# 假设实施成本100万美元,年收益50万美元
roi = assessment.calculate_roi(1_000_000, 500_000)
print(f"投资回报分析: {roi}")
四、完整流程总结与未来展望
技术演进全景图
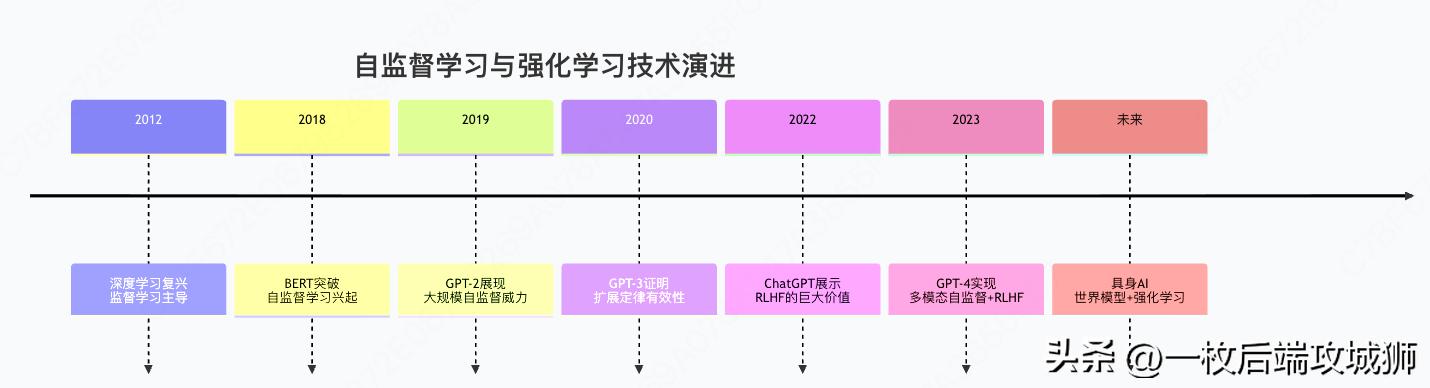
核心成功要素总结
1.数据策略的革命
- 自监督学习:将互联网-scale数据转化为训练资源
- RLHF:将稀疏的人类反馈转化为精确的优化信号
2.训练范式的进化
# 训练范式对比
training_paradigm_evolution = {
"第一代": {
"方法": "纯监督学习",
"数据": "人工标注数据集",
"代表": "ImageNet分类模型",
"局限性": "标注瓶颈,泛化能力有限"
},
"第二代": {
"方法": "自监督预训练 + 监督微调",
"数据": "无标签数据 + 少量标注数据",
"代表": "BERT, GPT系列",
"突破": "突破标注数据限制"
},
"第三代": {
"方法": "自监督 + RLHF",
"数据": "无标签数据 + 人类偏好",
"代表": "ChatGPT, Claude",
"突破": "价值观对齐,安全可靠"
}
}
3.规模化效应的体现
def demonstrate_scaling_laws():
"""展示扩展定律的效果"""
scaling_results = {
"模型规模": ["1B", "10B", "100B", "1T"],
"自监督效果": [65.2, 72.8, 78.3, 82.1], # 准确率%
"RLHF收益": [15.3, 22.7, 28.4, 35.2] # 性能提升%
}
# 关键洞察:规模越大,自监督和RLHF的效果越好
key_insights = [
"数据规模效应:更多无标签数据持续提升性能",
"模型规模效应:更大模型更好利用自监督信号",
"对齐规模效应:大模型从RLHF中获益更多",
"涌现能力:规模达到临界点出现新能力"
]
return scaling_results, key_insights
未来发展方向
1.技术前沿探索
class FutureResearchDirections:
"""未来研究方向"""
def __init__(self):
self.directions = {
"更高效的自监督": {
"目标": "减少计算需求,提升数据效率",
"方法": ["新的预训练任务", "更好的数据增强", "课程学习策略"]
},
"更精确的RLHF": {
"目标": "减少人类反馈需求,提升对齐精度",
"方法": ["主动学习", "多任务奖励模型", "宪法AI"]
},
"世界模型": {
"目标": "建立对物理世界的理解",
"方法": ["视频自监督学习", "多模态对比学习", "具身AI"]
},
"理论理解": {
"目标": "理解为什么这些方法有效",
"方法": ["表示学习理论", "对齐理论", "扩展定律理论化"]
}
}
2.应用场景拓展
def emerging_applications():
"""新兴应用场景"""
applications = {
"科学发现": {
"方法": "自监督学习科学文献 + RLHF优化假设生成",
"潜力": "加速药物发现、材料设计"
},
"教育个性化": {
"方法": "自监督理解学习内容 + RLHF适配学习风格",
"潜力": "真正个性化的AI导师"
},
"创意产业": {
"方法": "自监督学习艺术风格 + RLHF符合创作意图",
"潜力": "AI辅助的创意爆发"
},
"机器人技术": {
"方法": "自监督理解环境 + 强化学习技能掌握",
"潜力":通用的具身智能"
}
}
return applications
总结:AI发展的双轮驱动
自监督学习和强化学习的结合,标志着人工智能发展进入了一个新的阶段:
技术革命的本质
- 从人工标注到自动学习:自监督学习解放了数据标注的瓶颈
- 从静态模式到动态优化:强化学习实现了行为的持续改进
- 从工具智能到伙伴智能:RLHF确保了AI与人类价值观的对齐
商业价值的重构
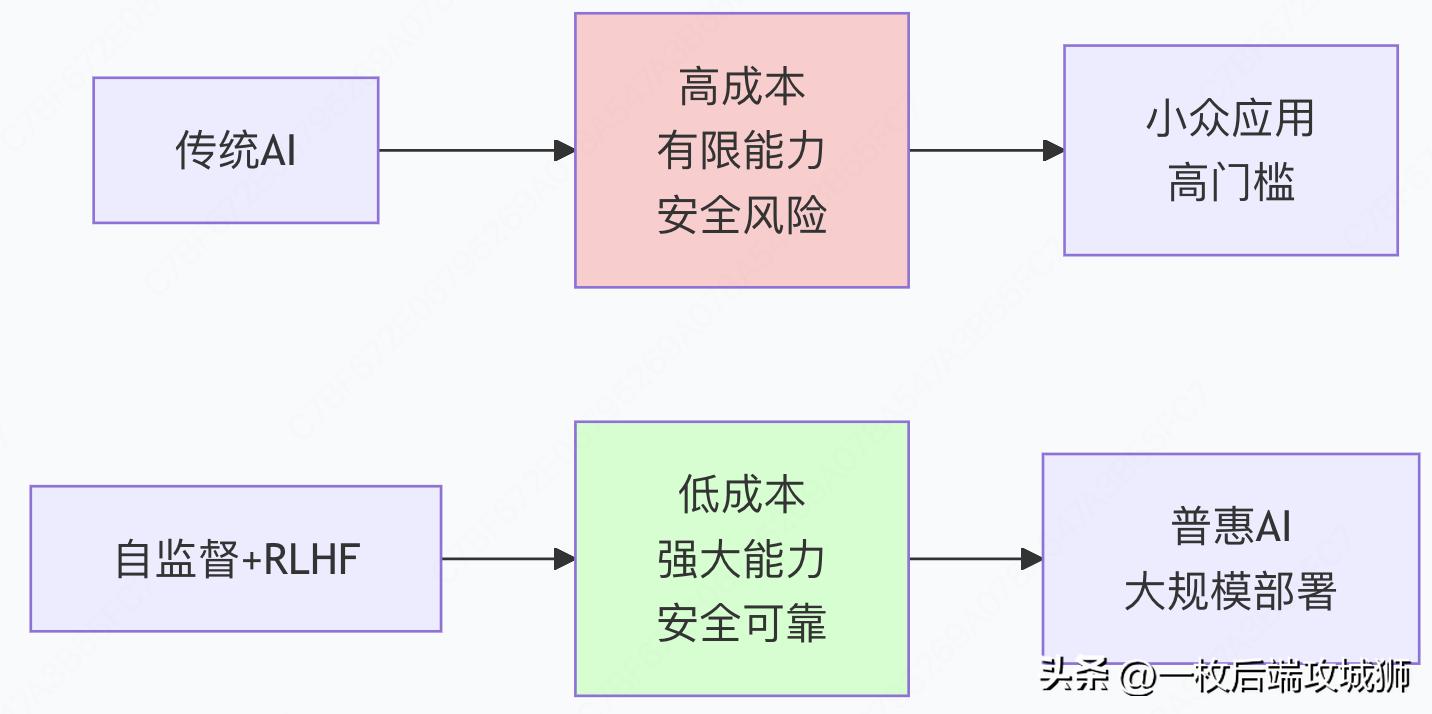
社会影响的深远意义
这种技术组合不仅创造了更强大的AI系统,更重要的是:
- 民主化AI:降低技术门槛,让更多组织能用上先进AI
- 负责任AI:通过对齐确保AI系统安全、可靠、符合伦理
- 创造性AI:释放人类的创造力,专注于更高价值的任务
自监督学习提供了知识的广度,强化学习提供了行为的精度,两者的结合正在催生真正通用、有用、安全的人工智能。这不仅是技术的进步,更是人类与机器协作方式的根本性变革。



















 857
857

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











