



参考链接:
简介
LLaMA-Factory 是一个面向大语言模型(LLM)的高效训练与微调框架,专为简化 LLaMA 系列以及各类开源大模型的训练流程而设计。它以“开箱即用、灵活高效”为核心理念,提供从数据准备、参数高效微调(PEFT)、训练配置管理到模型部署的一站式解决方案。
LLaMA-Factory 支持多种主流模型架构(如 LLaMA、Qwen、Gemma、Mistral 等),并集成了 LoRA、QLoRA、AdaLoRA、Prompt Tuning 等多种轻量化训练技术,使开发者能够以极低成本在单卡或多卡环境下完成高质量模型微调。
该框架提供直观易用的命令行工具与 Web UI,适配从科研实验到生产级应用的多场景需求。通过结构化的配置体系、完善的训练监控以及可扩展的数据加载管线,LLaMA-Factory 让大模型训练变得更加透明、可控且易于维护。
项目结构
LLaMA-Factory
├── assets # 项目静态资源(图标、示例图片、赞助商信息等)
│ ├── sponsors # 赞助商Logo与展示资源
│ └── thirdparty # 第三方依赖或引用资源
│
├── data # Demo 数据与示例数据集
│ └── mllm_demo_data # 多模态LLM(MLLM)演示数据
│
├── docker # Docker 环境配置(CUDA/NPU/ROCm 等)
│ ├── docker-cuda # NVIDIA GPU 环境 Dockerfile
│ ├── docker-npu # 华为 Ascend NPU 训练环境
│ └── docker-rocm # AMD ROCm 训练环境
│
├── examples # 训练、推理、工具使用的完整示例脚本
│ ├── accelerate # accelerate 分布式训练示例
│ ├── ascend # 华为 Ascend NPU 示例
│ ├── deepspeed # DeepSpeed 训练配置与示例
│ ├── extras # 各类高级特性示例(如 fp8、Galore、LoRA+ 等)
│ │ ├── adam_mini # Adam mini 参数优化示例
│ │ ├── apollo # Apollo 优化器示例
│ │ ├── badam # BAdam 优化器示例
│ │ ├── dft # DFT 训练示例
│ │ ├── fp8 # FP8 训练示例
│ │ ├── fsdp_qlora # FSDP + QLoRA 示例
│ │ ├── galore # GaLore低秩优化示例
│ │ ├── llama_pro # LLaMA-Pro 示例
│ │ ├── loraplus # LoRA+ 示例
│ │ ├── mod # MOD 技术示例
│ │ ├── multi_tokens # 多Token生成实验示例
│ │ ├── muon # Muon 优化器示例
│ │ ├── nlg_eval # 文本生成质量评测示例
│ │ ├── oft # OFT 微调示例
│ │ ├── pissa # PiSSA 权重重参数方法示例
│ │ └── qoft # QOFT 示例
│ ├── inference # 推理脚本示例(Chat、工具调用等)
│ ├── kt_optimize_rules # KTO 规则示例(奖励建模优化)
│ ├── megatron # Megatron-LM 适配示例
│ ├── merge_lora # LoRA 权重合并示例
│ ├── train_full # 全参数训练示例
│ ├── train_lora # LoRA 微调示例
│ └── train_qlora # QLoRA 微调示例
│
├── scripts # 辅助脚本(转换、统计、API示例)
│ ├── api_example # HTTP/API 使用示例
│ ├── convert_ckpt # 权重转换脚本(HF <-> 原始权重)
│ └── stat_utils # 数据、token 统计工具
│
├── src
│ └── llamafactory # 核心代码入口
│ ├── api # Web API / 服务端(OpenAI 接口兼容)
│ ├── chat # ChatEngine、多轮对话、工具调用
│ ├── data # 数据加载、处理、格式化、模板系统
│ │ ├── processor # 数据预处理组件(指令/对话/多模态)
│ ├── eval # 模型评测
│ ├── extras # 辅助函数(如日志、常量,环境等)
│ ├── hparams # 超参数解析(模型/数据/训练参数)
│ ├── model # 模型加载、LoRA/QLoRA/PEFT、patch等
│ │ └── model_utils # 模型结构、权重、分布式工具
│ ├── third_party # 集成第三方模块(如 muon 优化器)
│ ├── train # 训练核心模块(SFT/DPO/KTO/PPO/RM等)
│ │ ├── dpo # DPO 训练逻辑
│ │ ├── ksft # KSFT 训练逻辑
│ │ ├── kto # KTO 训练逻辑
│ │ ├── mca # MCA 对齐算法
│ │ ├── ppo # PPO 强化学习训练
│ │ ├── pt # 预训练流程
│ │ ├── rm # Reward Model(奖励模型训练)
│ │ └── sft # 指令监督微调
│ ├── v1 # 老版本核心(LLaMA-Factory v1)
│ │ ├── config # v1 配置系统
│ │ ├── core # v1 核心训练与推理模块
│ │ ├── extras # v1 扩展功能
│ │ ├── plugins # 插件系统(模型/采样器/分布式等)
│ │ └── trainers # 训练器(Trainer)体系
│ └── webui # Web UI(Gradio 界面)
│ ├── components # UI 组件
│
├── tests # 测试集(核心模块测试)
│ ├── data # 数据处理测试
│ ├── e2e # 端到端测试
│ ├── eval # 评测模块测试
│ ├── model # 模型加载/patch等测试
│ └── train # 训练流程测试
│
└── tests_v1 # v1 版本的历史测试集
├── core # v1 核心模块测试
└── plugins # v1 插件系统测试
支持的训练方法如下:
| 方法 | 全参数训练 | 部分参数训练 | LoRA | QLoRA |
|---|---|---|---|---|
| 预训练 | ✅ | ✅ | ✅ | ✅ |
| 指令监督微调 | ✅ | ✅ | ✅ | ✅ |
| 奖励模型训练 | ✅ | ✅ | ✅ | ✅ |
| PPO 训练 | ✅ | ✅ | ✅ | ✅ |
| DPO 训练 | ✅ | ✅ | ✅ | ✅ |
| KTO 训练 | ✅ | ✅ | ✅ | ✅ |
| ORPO 训练 | ✅ | ✅ | ✅ | ✅ |
| SimPO 训练 | ✅ | ✅ | ✅ | ✅ |
原文是在mac下实现的,现在我需要的是在ubuntu下完成微调和部署的工作,这是我本机的配置情况(32G内存和24G显存)。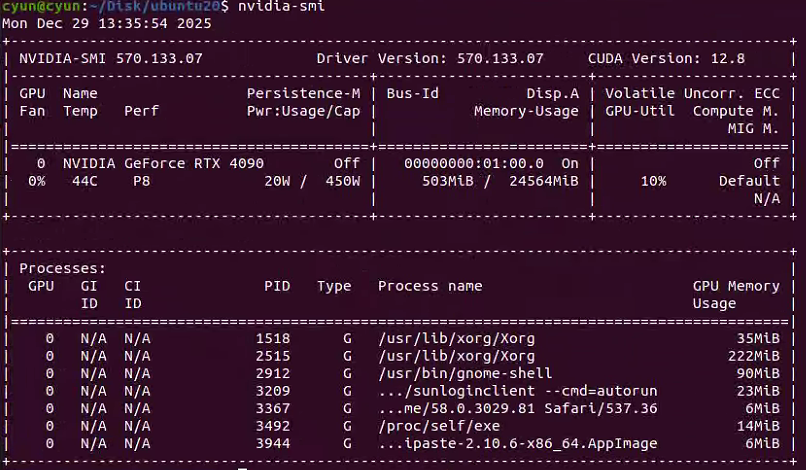
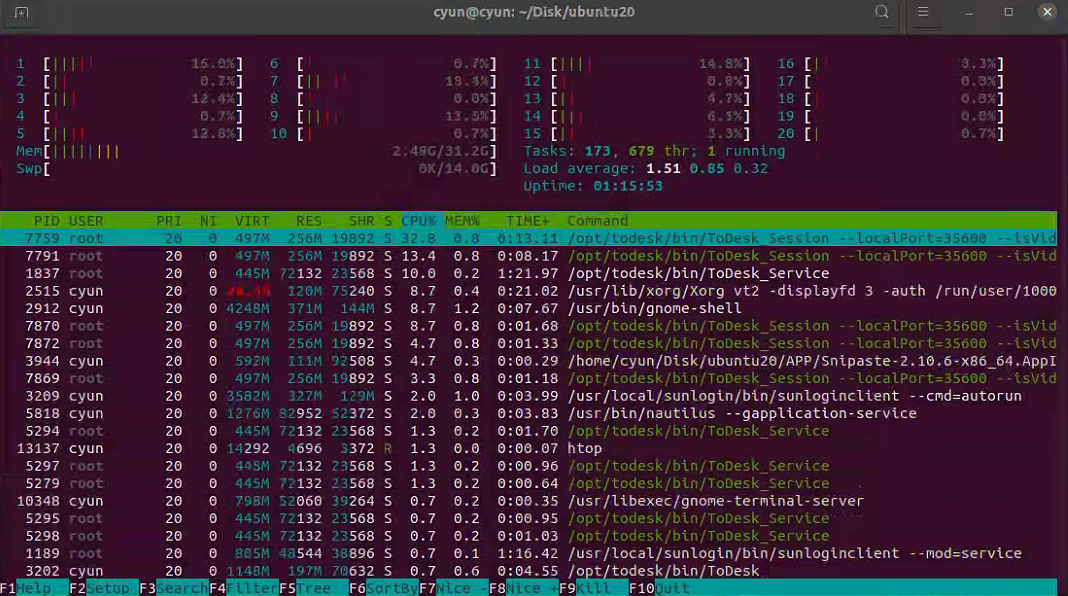
如果是mac,需要先确认自己的电脑是否支持mps的gpu。
安装
接下来我们正式安装LLaMA-Factory,首先克隆对应的源码内容:
# 克隆源码
git clone --depth 1 https://github.com/hiyouga/LLaMA-Factory.git
接着开始安装
# 进入到源码目录
cd LLaMA-Factory
# 创建conda环境
conda create -n llama_factory python=3.11
conda activate llama_factory
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu124
pip install flash-attn==2.7.4 --no-build-isolation
# 开始安装
pip install -e ".[torch,metrics]"
安装完成后即可使用。
或者直接使用一键安装与配置的脚本:
#!/bin/bash
set -e # 遇到错误立即停止
# ================= 目标配置 =================
ENV_NAME="llama_factory_cu124"
PYTHON_VER="3.11"
TORCH_VER="2.6.0"
CUDA_TAG="cu124" # 对应 PyTorch 的 CUDA 版本标识
FA_VER="2.7.4.post1" # Flash Attention 版本
# ===========================================
echo ">>> [1/6] 初始化 Conda..."
# 尝试找到 conda 的初始化脚本,确保脚本内可以使用 conda 命令
# 如果你的 conda 安装路径不同,请手动修改下面这一行,例如 ~/anaconda3/etc/profile.d/conda.sh
CONDA_PATH=$(conda info --base)
source "$CONDA_PATH/etc/profile.d/conda.sh"
echo ">>> [2/6] 创建新环境 (Python $PYTHON_VER)..."
# 如果环境已存在,会先移除旧的 (保证纯净)
if conda info --envs | grep -q "$ENV_NAME"; then
echo "环境 $ENV_NAME 已存在,正在重建以确保纯净..."
conda env remove -n "$ENV_NAME" -y
fi
conda create -n "$ENV_NAME" python="$PYTHON_VER" -y
conda activate "$ENV_NAME"
echo ">>> [3/6] 安装构建工具 (用于编译 Flash Attention)..."
# 安装 ninja 和 packaging,这对编译 flash-attn 至关重要
pip install ninja packaging wheel setuptools
echo ">>> [4/6] 安装 PyTorch $TORCH_VER ($CUDA_TAG)..."
# 指定 index-url 为 cu124 版本
pip install torch==${TORCH_VER} torchvision torchaudio --index-url https://download.pytorch.org/whl/${CUDA_TAG}
echo ">>> [5/6] 安装 Flash Attention $FA_VER..."
# 注意:这步通常最耗时,因为它可能需要本地编译 CUDA 代码
# 必须加上 --no-build-isolation 以便使用当前环境的 PyTorch 进行编译链接
pip install flash-attn==${FA_VER} --no-build-isolation
echo ">>> [6/6] 安装 LLaMA-Factory..."
if [ ! -d "LLaMA-Factory" ]; then
git clone --depth 1 https://github.com/hiyouga/LLaMA-Factory.git
fi
cd LLaMA-Factory
# 强制更新一下代码
git pull
# 安装本体
pip install -e ".[torch,metrics]"
echo "=================================================="
echo "✅ 安装全部完成!"
echo "配置详情: Python $PYTHON_VER | Torch $TORCH_VER | CUDA $CUDA_TAG | Flash-Attn $FA_VER"
echo ""
echo "请执行以下命令开始使用:"
echo " conda activate $ENV_NAME"
echo " llamafactory-cli webui"
echo "=================================================="
启动
安装完毕后就可以启动了,但是要注意先关闭vpn,有vpn的情况下无法正常启动webui界面。注意,在启动之前,我们需要提前指定安装源,使用的是modelscope,国内可以正常访问下载模型的地址:
export USE_MODELSCOPE_HUB=1
llamafactory-cli webui
File "/home/cyun/Disk/Shared/Conda/envs/llama_factory/lib/python3.11/site-packages/httpx/_client.py", line 245, in <dictcomp>
key: None if url is None else Proxy(url=url)
^^^^^^^^^^^^^^
File "/home/cyun/Disk/Shared/Conda/envs/llama_factory/lib/python3.11/site-packages/httpx/_config.py", line 214, in __init__
raise ValueError(f"Unknown scheme for proxy URL {url!r}")
ValueError: Unknown scheme for proxy URL URL('socks://127.0.0.1:7890/')

这个问题说的比较明确,就是无法使用socks://127.0.0.1:7890/,这配置终端的环境变量导致的问题,只需要解除相关的环境变量就可以了(不需要关闭vpn)
unset all_proxy http_proxy https_proxy ALL_PROXY HTTP_PROXY HTTPS_PROXY
解除配置后,即可重新运行
llamafactory-cli webui

微调
下载示例的数据集,进入LLaMA-Factory文件夹:
wget https://atp-modelzoo-sh.oss-cn-shanghai.aliyuncs.com/release/tutorials/llama_factory/data.zip
# 把原有的data文件夹备份到rawdata中,然后解压当前的压缩包
mv data rawdata && unzip data.zip -d data
数据就在data文件夹下的train和eval两个json文件,info的json对应的是这个数据集的信息。示例如下
[
{
"conversations": [
{
"from": "human",
"value": "模仿西游记的孙悟空的语气和我聊天。如果你把水冻住,你会得到什么?"
},
{
"from": "gpt",
"value": "哈哈,这问题还难倒俺老孙吗?把水冻住就是变成冰啦!不过若是在取经的路上用得着这冰来做啥,比如过火焰山时,那可就是解渴消暑的好东西了!你觉得呢?还有没有更有趣的问题让俺老孙来解答?"
},
{
"from": "human",
"value": "那怎么做才可以把水冻住"
},
{
"from": "gpt",
"value": "哈哈,对俺老孙来说,这可是轻而易举的事情!只需将水放在凉快的地方,或者使用法力,一吹仙气,水便能迅速结冰啦!当然,在你的世界里,把水放进冰箱的冷冻室里等一阵子,水就会变成冰块了。要是嫌慢,可以尝试用点干冰或液氮什么的,不过得小心使用哈!毕竟不像俺老孙有抗寒法力。"
}
]
}
]
接下来设置一下微调的参数,修改内容如下(之后我们再深入学习这些配置参数的含义)
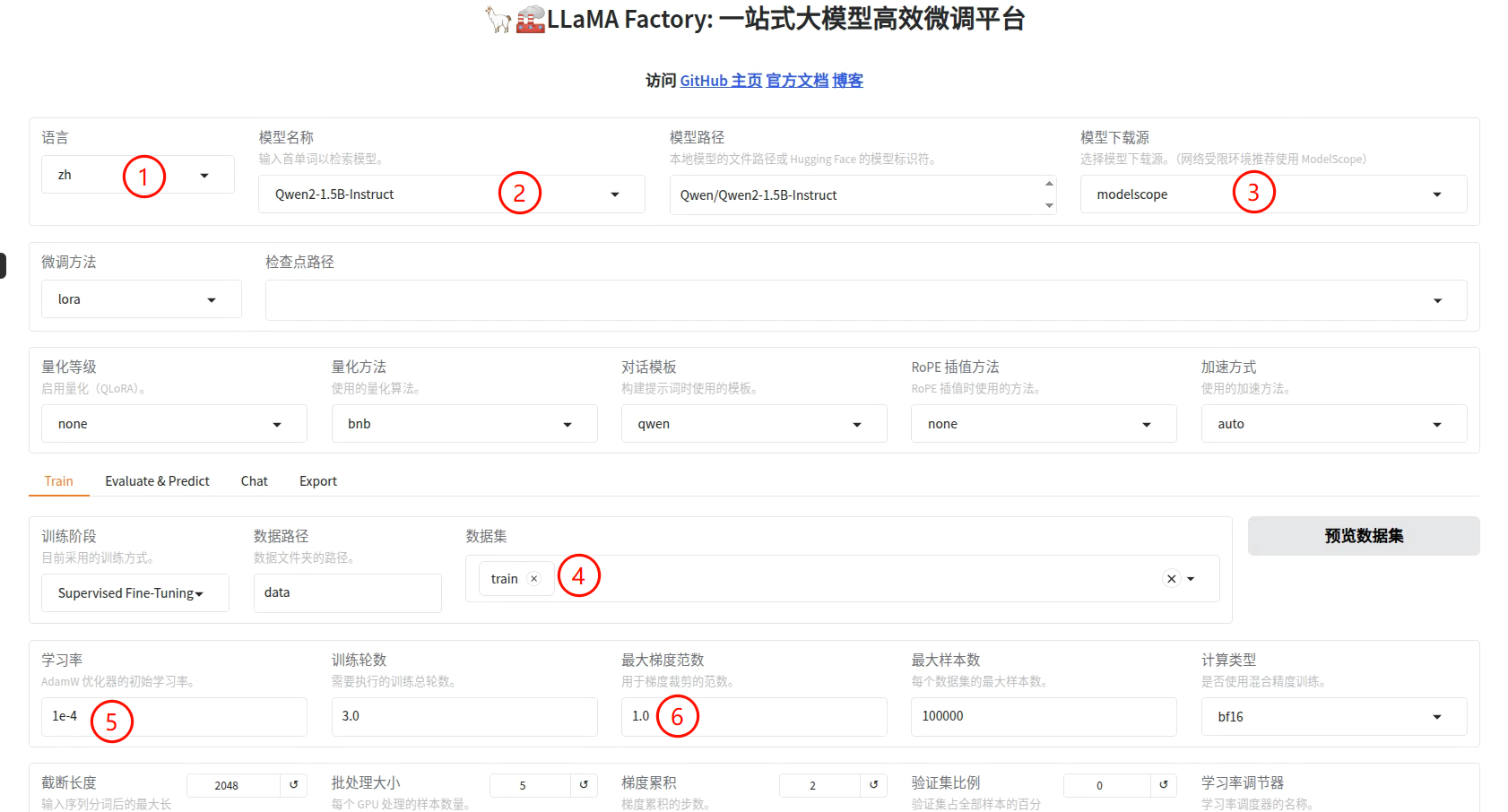
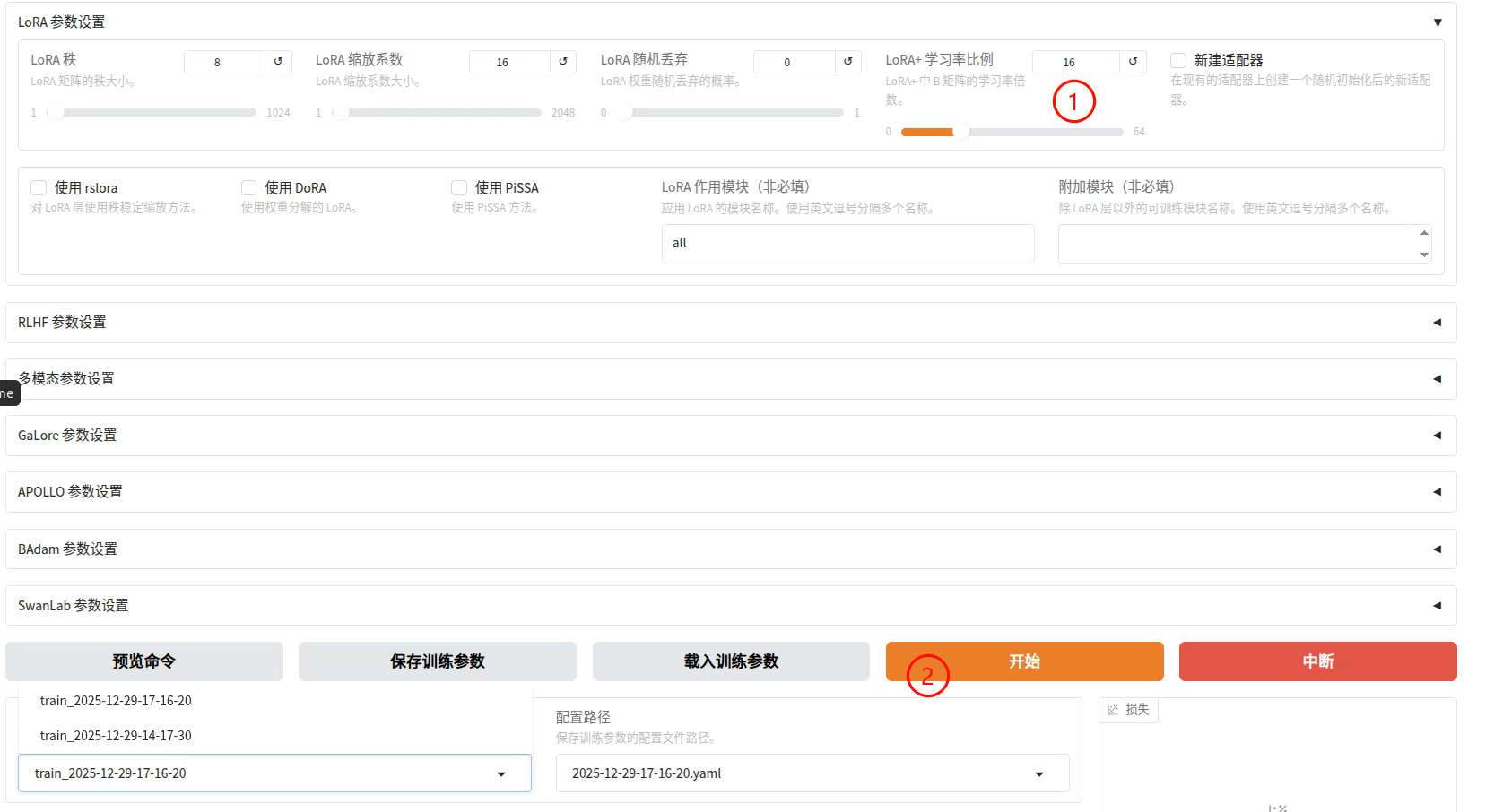
目前还不理解相关的配置参数的意义,先跟着配置一下,然后就可以**[开始]**训练了。
如果没有提前指定模型位置,那它就会先下载对应的模型,路径如下:
~/.cache/modelscope/hub/models/Qwen
如果想要看到当前的网速情况,可以下载sudo apt install nload工具进行观看。
下载完成后它就会开始微调了。我的设备使用的显存大概在20G左右。训练完成之后的文件都保存在了saves文件夹中,可以进入到最底层,此时的文件大概有几百MB,它是微调的输出文件,这里介绍一下一下微调生成的这些文件。
先介绍微调后显示结果的相关参数:
指标详解
| 键名 | 含义 | 说明 |
|---|---|---|
predict_bleu-4 | BLEU-4 分数:24.27 | 常用于机器翻译/文本生成评估,表示预测结果与参考答案在 n-gram 上的重合程度。24.26 属于中等偏上的水平。 |
predict_rouge-1 | ROUGE-1 分数:46.49 | 测量预测与参考答案之间 unigram(单个词)的重合率,适合评估总结、对话等生成任务。 |
predict_rouge-2 | ROUGE-2 分数:25.11 | 测量 bigram(2个词组合)的重合率,越高表示生成更符合参考内容。 |
predict_rouge-l | ROUGE-L 分数:38.39 | 衡量预测与参考答案之间的最长公共子序列(LCS),体现句子结构与顺序的匹配程度。 |
性能相关指标
| 键名 | 含义 | 说明 |
|---|---|---|
predict_model_preparation_time | 模型加载准备耗时(秒):0.0011 | 几乎忽略不计,说明模型已提前加载好或在内存中。 |
predict_runtime | 预测耗时:3469.58 秒 | 整体预测任务总耗时(约 57 分钟),与评估的数据量和硬件环境有关。 |
predict_samples_per_second | 平均每秒处理样本数:0.314 | 说明每秒大约能预测 0.314 条样本,较慢,可能是模型大/显存限制/生成长度较长导致。 |
predict_steps_per_second | 每秒执行 step 数:0.157 | 每秒的 forward 推理 step 次数,一般用于性能调优参考。 |
主要生成质量指标
- 生成结果与参考答案在 BLEU-4 上达到了 24.26
- ROUGE 指标表现良好,ROUGE-1 为 46.49%,ROUGE-L 为 38.39%
- 说明模型已经能够生成较有质量的文本
- 性能上处理速度较慢(每秒不到 1 条样本),但正常
{
"epoch": 3.0,
"num_input_tokens_seen": 596904,
"total_flos": 4725950383300608.0,
"train_loss": 1.4550889680782955,
"train_runtime": 119.3362,
"train_samples_per_second": 8.044,
"train_steps_per_second": 4.022
}
-
adapter_model.safetensors (或 .bin):这是核心文件。它里面装的是你训练出来的“新知识”或“新说话方式”的权重参数。注意:它不是一个完整的模型,它只是原有模型的一层“补丁”。
-
adapter_config.json:这是说明书。它告诉程序这块“补丁”应该贴在模型的哪个位置(比如贴在 Attention 层),以及使用了什么参数(Rank, Alpha 等)。
-
tokenizer 相关文件 (可选):有时会包含 tokenizer.json 等。如果你的微调没有修改词表(一般 LoRA 不改),这些文件和基座模型的一样。
-
trainer_state.json 等日志文件:记录了训练过程中的 Loss 曲线、步数等信息,用于回顾训练质量。
知道这些就可以了,也就是说,基座模型还是一直都是需要的。
我们先回顾两个概念,分别是预训练和微调,其中:
- Pre-train (预训练) 让模型学会了“成语接龙”和“世界知识”(它看过《新华字典》)。
- SFT (微调) 则是让模型学会“听懂指令”和“按格式回答”(教它如何当一个客服、翻译官或医生)。
SFT作为监督微调,是有它的损失的概念的,这是它的损失曲线:
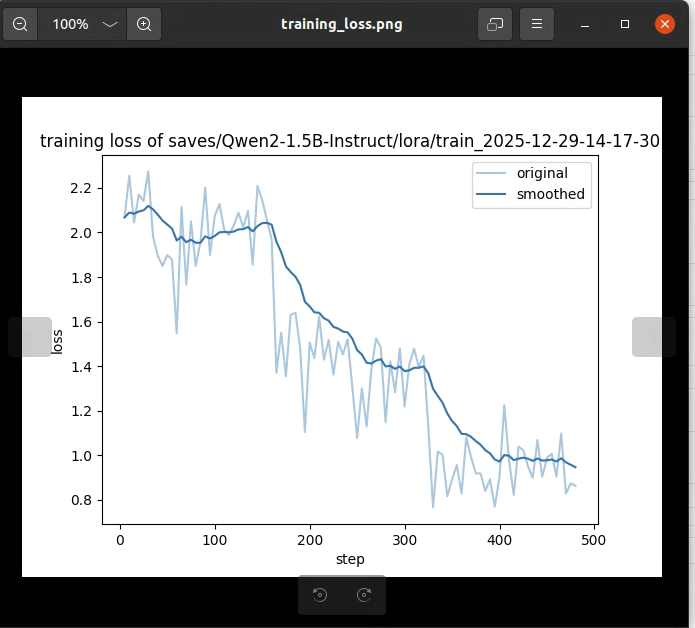
SFT 使用的损失函数依然是 交叉熵损失函数 (Cross-Entropy Loss),具体形式为 Next Token Prediction Loss(下一个词预测损失)。

也就是说微调的时候只有回答会计算损失,这里还是没有清楚的表达出怎么处理数据的,我们举个具体的例子来进行说明,假设输入输出分别为
Instruction: “你好” (假设分词后 id 为 [101, 200])
Output: “好” (假设分词后 id 为 [300])
在 LLaMA-Factory 内部处理时,数据会被拼接成一个序列,并生成对应的 labels:
序列内容 User : 你 好 \n AI : 好
Token ID 1 2 101 200 3 4 5 300 2
Labels (用于算Loss) -100 -100 -100 -100 -100 -100 -100 300 2
这里面很多是-100,这是 PyTorch 中 CrossEntropyLoss 的默认忽略索引(ignore_index)。这意味着模型在处理“User: 你好”这部分时,无论预测得准不准,都不产生梯度,不更新参数。
而300,2当中:只有在模型预测“好”和结束符 时,产生的误差才会反向传播,更新模型权重。数学本质是带Mask的CLM(Causal Language Modeling)(因果语言建模)
更加详细的内容会在后面的文章中继续学习其详细的情况是怎么样的。
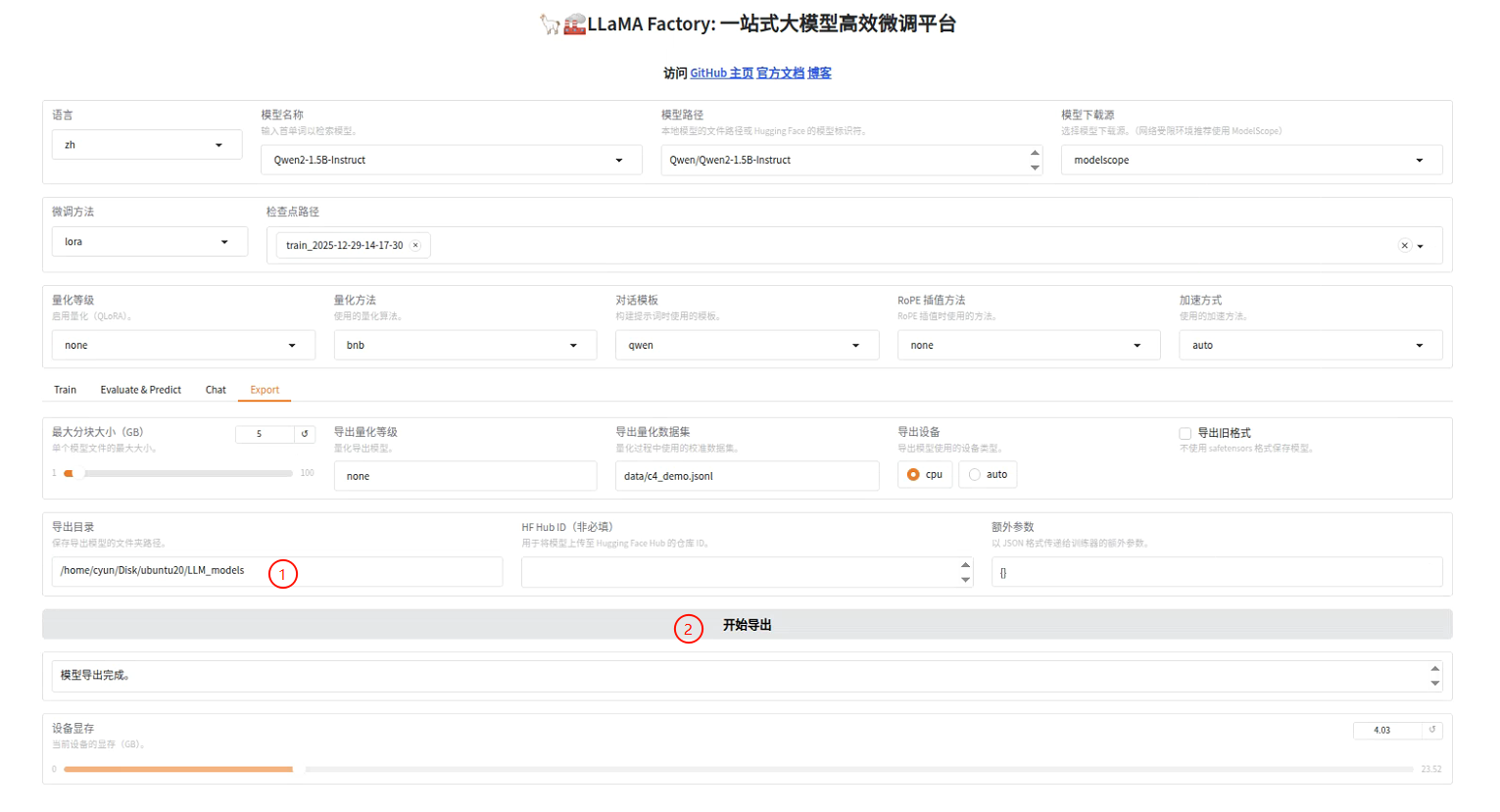
完整导出
如果要导出微调后的所有文件包括基座模型,可以使用LLama-Factory的Export功能。导出之前也是需要先加载模型的,这个会在模型对话里面再次提到,这里我们要导出的是微调后的模型,所以按照我的配置设置即可。
然后导出(默认配置+导出路径即可),等待一段时间后就导出完成了,对应路径下就有了整体的模型了。
评估
接下来评估微调好的模型,也是直接运行:
llamafactory-cli webui
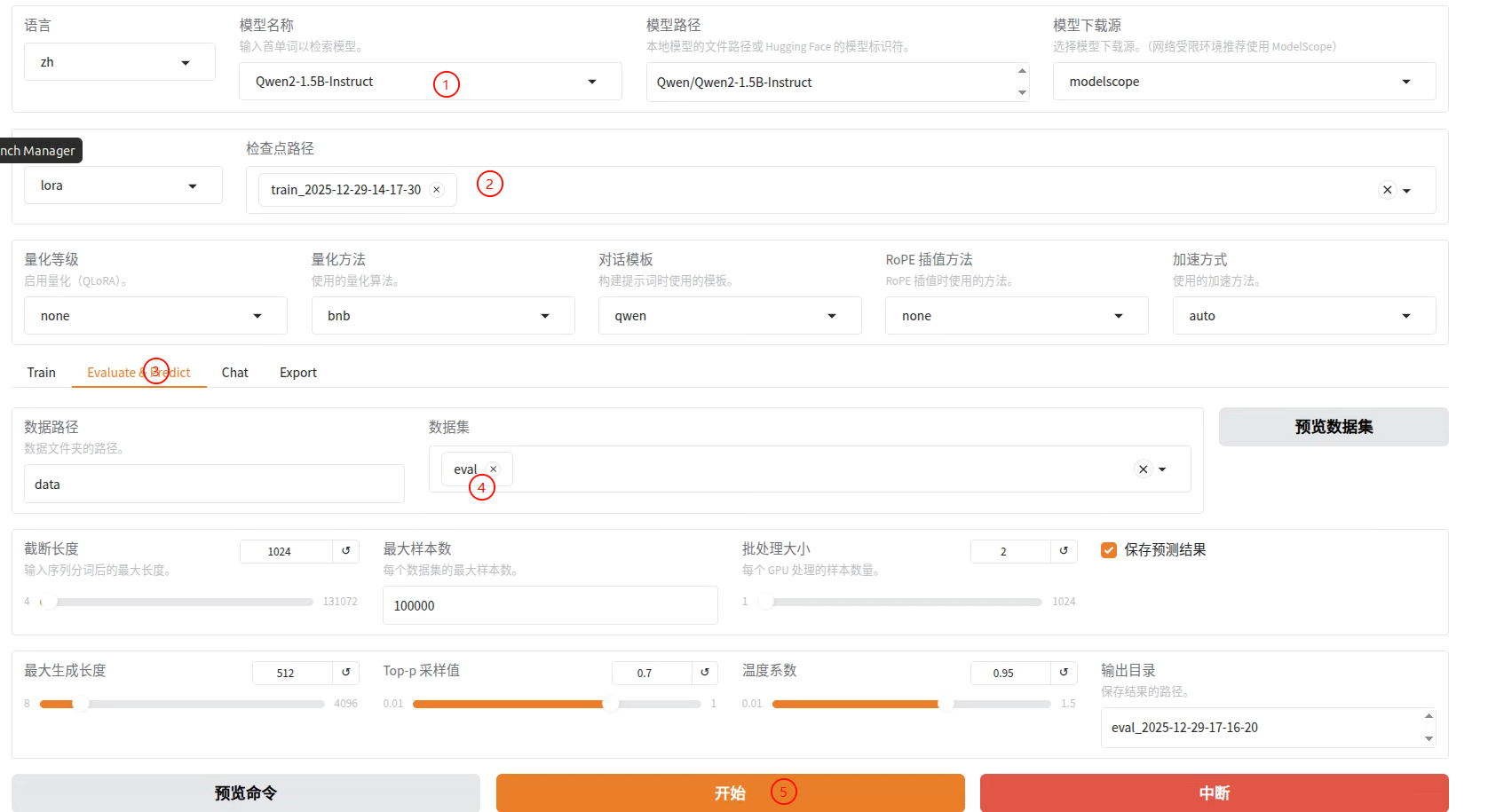
配置好过后开始即可。
对话
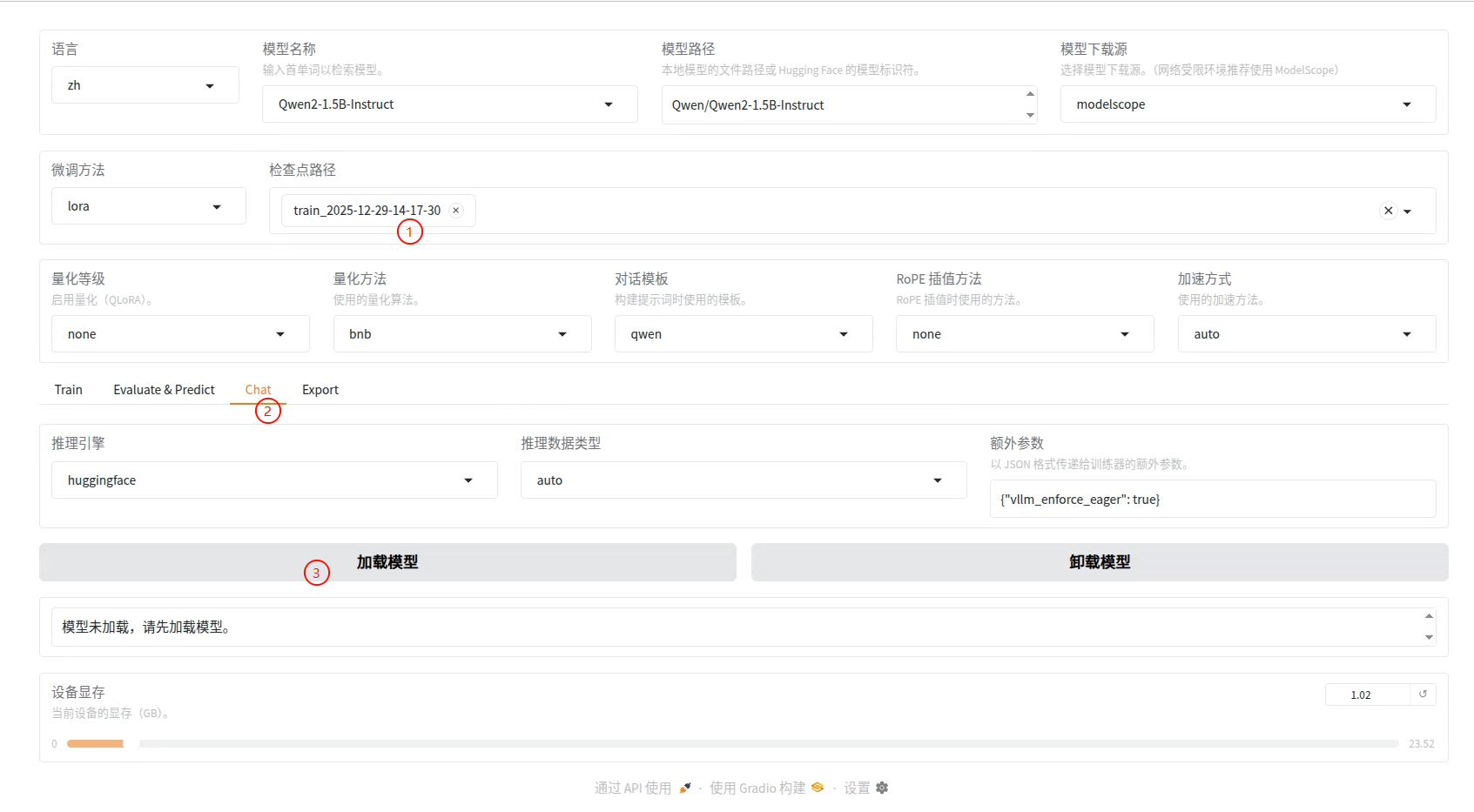
加载一下模型就好了
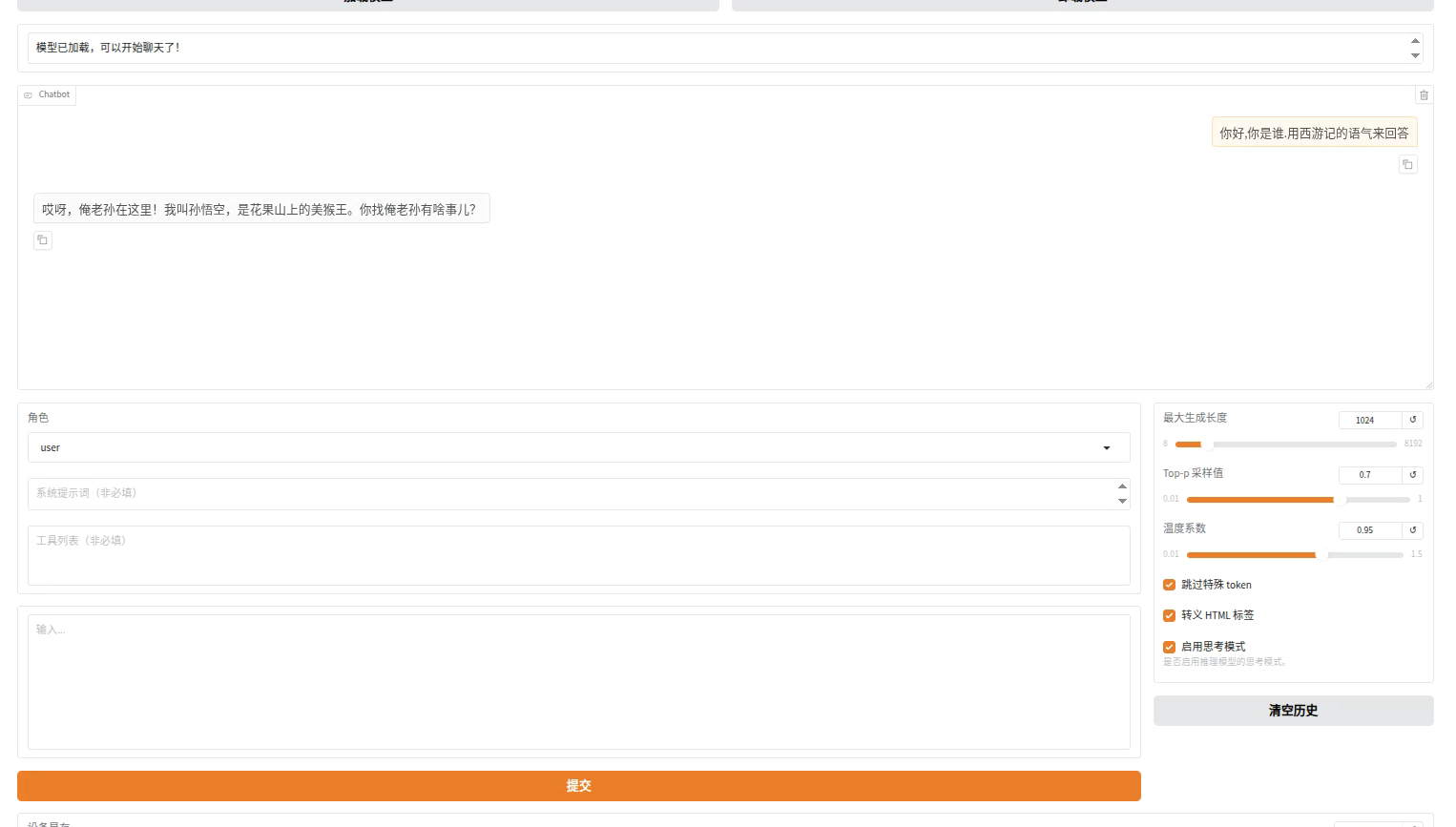
如果不加载模型,那就是微调之前的效果,我们同样来测试一下:
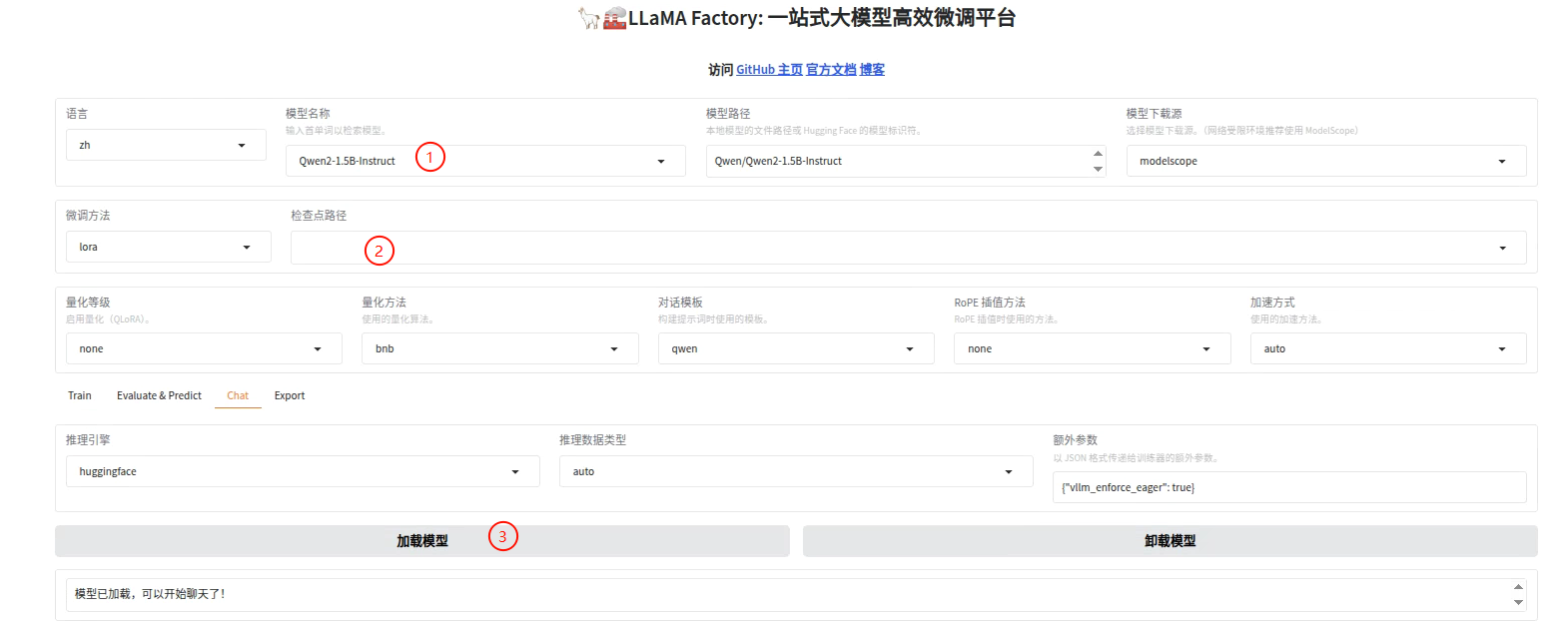
测试微调效果的时候用同样的问题来对比
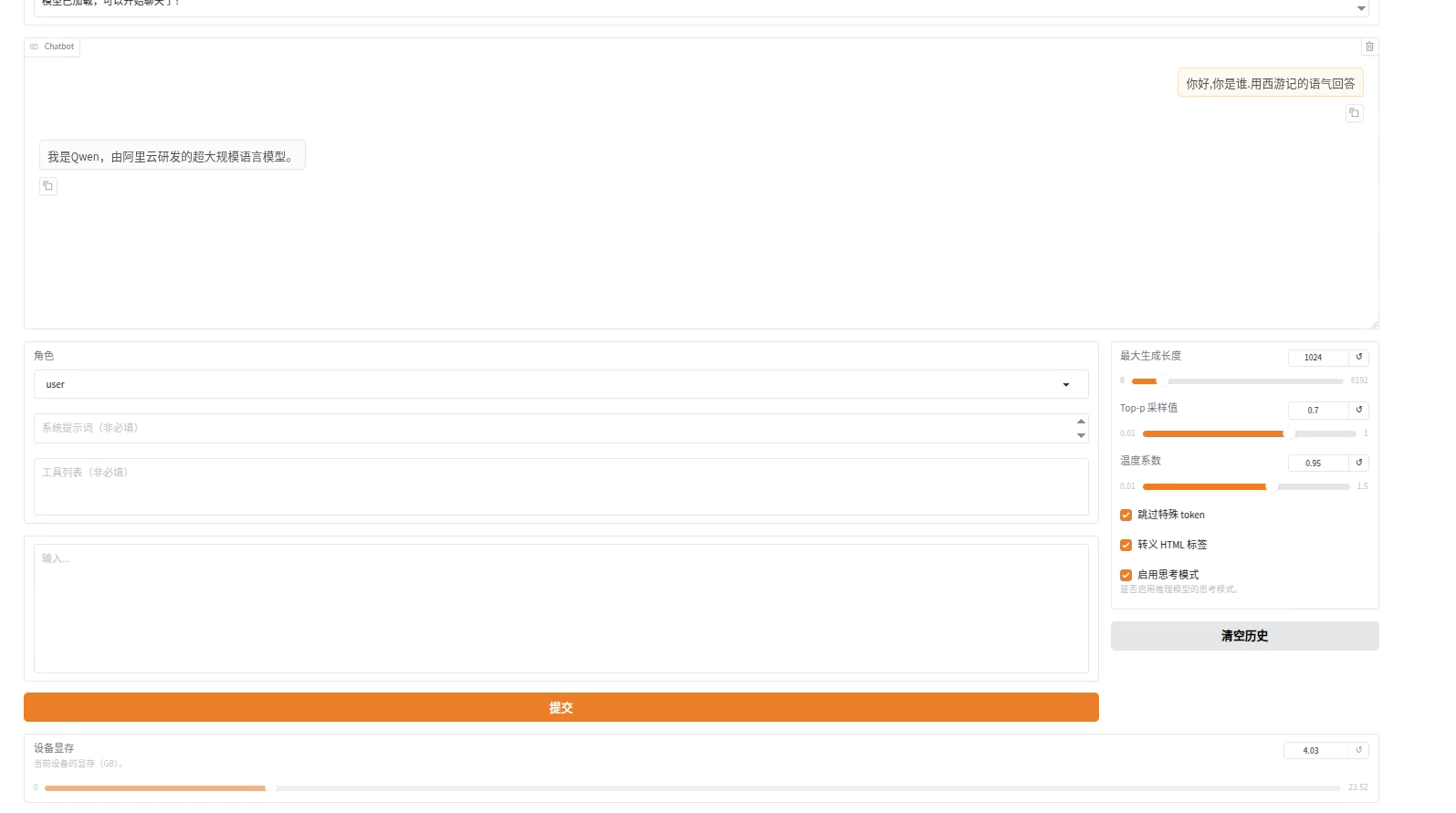
当然,更加正式的对比应该是用微调前的模型和微调后的模型对一些更加复杂的问题进行测试(有一些评估模型水平的标准)
以上就是大模型微调的全部内容了,也是最基础的一些知识,包括Lora微调,加载模型,导出模型等等,后续就要从更加复杂一点的数学原理上来进行学习认识了。



















 17万+
17万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











