







 DeepLabV3重新审视了空洞卷积在级联模块和空间金字塔池化中的应用。文章提出了连续池化和下采样对精细分割的挑战,以及多尺度目标的问题。DeepLabV3采用级联的ResNet块,结合不同率的空洞卷积,以解决这些问题。实验结果显示,在Pascal VOC 2012测试中达到85.7%的精度。
DeepLabV3重新审视了空洞卷积在级联模块和空间金字塔池化中的应用。文章提出了连续池化和下采样对精细分割的挑战,以及多尺度目标的问题。DeepLabV3采用级联的ResNet块,结合不同率的空洞卷积,以解决这些问题。实验结果显示,在Pascal VOC 2012测试中达到85.7%的精度。

概述
以下主要来自其官方PPT
- 文中提出两个语义分割的challenges:
- 1、连续池化和下采样会让后面特征的分辨率下降,这对于做精细的分割是不利的。
- 2、多尺度目标的存在。
- 相对于V1、V2的改变:
- V3所提出的框架可以应用到任意的网络中,应该指的是主干网络。
- 最后的ResNet block被重用多次,被安排进行级联操作。
- 在ASPP中加入了Batch normalization。
- CRF没有被用到。

- Contribution:
- 本文重新讨论了空洞卷积在cascaded modules and spatical pyramid pooling(Parallel)结构中的应用问题。
- 讨论了一个重要的问题:对3x3的空洞卷积进行各种rate的尝试,甚至是很极端的情况(在极端的rate情况下,空洞卷积就失去了获取更多上下文信息的能力,转而就退化为1x1卷积功能)。
- 阐述了一些训练的经验和实验细节。
- Result:
- Pascal VOC 2012 test 85.7%
细节
Challenge
上面已经阐述过了有两个问题,以下讨论四种利用上下文信息的方法来进行语义分割:
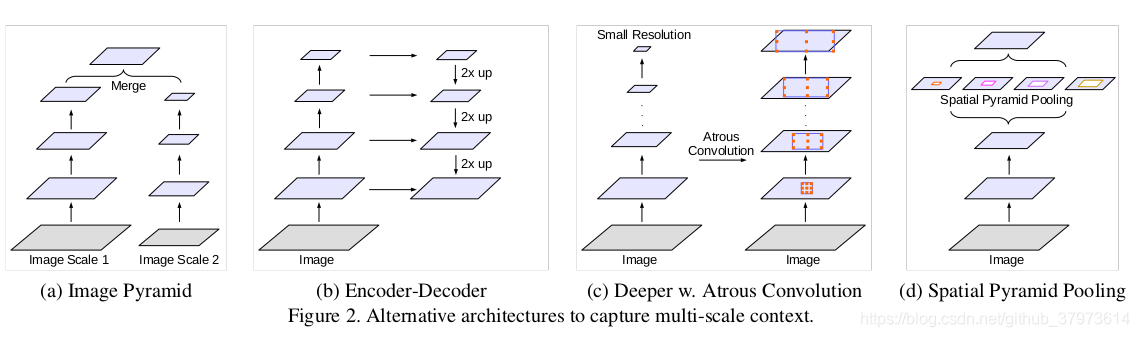
- Image pyramid:将图片缩放成不同比例,各种经过DCNN后融合输出。
- Encoder-Decoder:利用Encoder阶段的多尺度特征,运用到Decoder阶段上恢复空间分辨率,这样做法有FCN、SegNet、Unet等网络。
- Context module:在原始模块后增加模块,如DenseCRF,对像素间的关联进行分析。
- Spatial pyramid pooling:使用spp在不同的范围内获取上下文信息。如,在ParseNet中就使用了Image-level feature,可以获取全局的上下文信息。DeepLabV2使用ASP
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 4万+
4万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









