




 本文详细介绍了Caffe框架中的prototxt文件,讲解了data_layer、vision_layer、common_layer和Neuron_layer中的关键组件,如Data层的参数设置、卷积(Convolution)和池化(Pooling)层的特性、内积(InnerProduct)层(FC)、Sigmoid和ReLU等激活函数层,以及损失(loss_layer)层中的softmax-loss。此外,还提及了数据预处理、模型精度计算和Dropout层的作用。
本文详细介绍了Caffe框架中的prototxt文件,讲解了data_layer、vision_layer、common_layer和Neuron_layer中的关键组件,如Data层的参数设置、卷积(Convolution)和池化(Pooling)层的特性、内积(InnerProduct)层(FC)、Sigmoid和ReLU等激活函数层,以及损失(loss_layer)层中的softmax-loss。此外,还提及了数据预处理、模型精度计算和Dropout层的作用。

【参考】
data_layer
1、Data层
layer {
name: "cifar"
type: "Data"
top: "data"
top: "label"
include {
phase: TRAIN
}
transform_param {
mean_file: "examples/cifar10/mean.binaryproto"
}
data_param {
source: "examples/cifar10/cifar10_train_lmdb"
batch_size: 100
backend: LMDB
}
}- name任取,表示这一层的名字
- type:层类型,如果是Data,表示数据来源是LevelDB后者LMDB,根据数据来源的不同,数据层的类型也不同,有些还是从磁盘中存储hdf5或者图片格式。
- top和bottom:top为此层输出,bottom为此层输入,在数据层中,至少有一个命名为data的top。如果有第二个top,一般命名为label。这种(data, label)的配对是分类模型所必需的。
- include:一般训练和测试的时候,模型的参数有些不一样。所以这个是用来指定该数据层是属于训练阶段或者测试阶段的层。若未指定,则该层既用在训练模型又用在测试模型上。
- transform_param:数据的预处理,可以将数据变换到定义的范围内。如设置scale为0.00390625,实际上就是1/255,即将输入数据由0~255归一化到0~1之间。
- data_param:根据数据来源的不同,来进行不同的设置。必须设置的参数有source和batch_size,source包含数据库的目录名字,batch_size就是每次处理的数据个数。可选参数有rand_skip和backend,backend是选择采用LevelDB还是LMDB,默认是LevelDB【这个应该是选择数据库引擎】
vision_layer
【Convolution、Pooling】
2、Convolution层
layer {
name: "conv1"
type: "Convolution"
bottom: "data"
top: "conv1"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
convolution_param {
num_output: 96
kernel_size: 11
stride: 4
pad: 2
weight_filler {
type: "gaussian"
std: 0.01 #标准差:distribution with stdev 0.01(default mean: 0)
}
bias_filler {
type: "constant"
value: 0
}
}
}- lr_mult:学习率的系数,最终的学习率是这个数乘以solver.prototxt配置文件中的base_lr。如有两个lr_mult,则第一个表示权值w的学习率,第二个表示偏置项的学习率。一般偏置项的学习率是权值学习率的两倍。
- 必须设置的参数有:
- num_output:卷积核的个数
- kernel_size:卷积核的大小,如果kernel_size长宽不一样,则需要通过kernel_h,kernel_w分别设定。
- 其他参数:
- stride:卷积核的步长,默认为1, 也可以用stride_h, stride_w来设置。
- pad
- weight_filter:权值初始化。默认为“constant”,值权威0,很多时候我们用“xavier”算法来进行初始化,也可以设置为“gaussian”
- bias_filter:偏置项的初始化,一般设置为“constant”,值全为0。
- bias_term:是否开启偏置项,默认为true
- group:分组,默认为1组。如果大于1,我们限制卷积的连接操作在一个子集里。
3、pooling层
layer {
name: "pool1"
type: "Pooling"
bottom: "conv1"
top: "pool1"
pooling_param {
pool: MAX
kernel_size: 3
stride: 2
}
} 4、Local Response Normalization层
LRN是对一个局部的输入进行的归一化操作。【貌似现在不怎么用了】
5、im2col层
在caffe中,卷积运算就是先对数据矩阵进行im2col操作,在进行内积运算,这样做,会比原始的卷积操作更快。
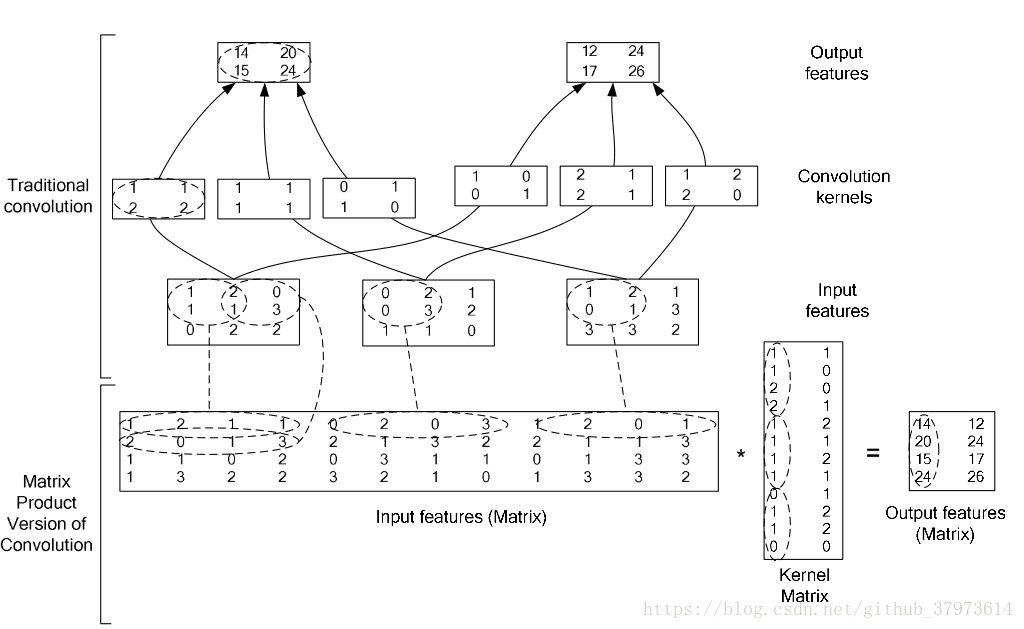
common_layer
【InnerProductLayer、SplitLayer、FlattenLayer、ConcatLayer、SilenceLayer、(Elementwise Operations)这个是我们常说的激活函数层Activation Layers、EltwiseLayer、SoftmaxLayer、ArgMaxLayer、MVNLayer】
6、inner_product层(FC)
layers {
name: "fc8"
type: "InnerProduct"
blobs_lr: 1 # learning rate multiplier for the filters
blobs_lr: 2 # learning rate multiplier for the biases
weight_decay: 1 # weight decay multiplier for the filters
weight_decay: 0 # weight decay multiplier for the biases
inner_product_param {
num_output: 1000
weight_filler {
type: "gaussian"
std: 0.01
}
bias_filler {
type: "constant"
value: 0
}
}
bottom: "fc7"
top: "fc8"
7、accuracy
layer {
name: "accuracy"
type: "Accuracy"
bottom: "ip2"
bottom: "label"
top: "accuracy"
include {
phase: TEST
}
}- accuracy只在test有,因此要设置include为TEST。输出分类(预测)的精确度。
8、reshape
layer {
name: "reshape"
type: "Reshape"
bottom: "input"
top: "output"
reshape_param {
shape {
dim: 0 # copy the dimension from below
dim: 2
dim: 3
dim: -1 # infer it from the other dimensions
}
}
}- 有一个可选的参数组shape,用于指定blob数据的各维的值(blob是一个四维的数据nxcxwxh)
- "dim:0"表示维度不变,即输入和输出是一样的维度。"dim:-1"表示由系统自动计算维度。数据总量不变,系统根据其他三维来确定这一维。
9、dropout
layer {
name: "drop7"
type: "Dropout"
bottom: "fc7-conv"
top: "fc7-conv"
dropout_param {
dropout_ratio: 0.5 #只需要设置一个dropout_ratio参数即可
}
}
Neuron_layer
10、Sigmoid
layer {
name: "encode1neuron"
bottom: "encode1"
top: "encode1neuron"
type: "Sigmoid"
}11、ReLU/Rectified-linear and Leaky-ReLU
layers {
name: "relu1"
type: RELU
bottom: "conv1"
top: "conv1"
}12、TanH/Hyperbolic Tangent
layer {
name: "layer"
bottom: "in"
top: "out"
type: "TanH"
}13、Absolute value(绝对值)
layer {
name: "layer"
bottom: "in"
top: "out"
type: "AbsVal"
}14、Power(幂运算)
layer {
name: "layer"
bottom: "in"
top: "out"
type: "Power"
power_param {
power: 2
scale: 1
shift: 0
}
}15、BNLL(binomial normal log likelihood)
layer {
name: "layer"
bottom: "in"
top: "out"
type: “BNLL”
}
loss_layer
【待续,还有很多的】
16、softmax-loss
layer {
name: "loss"
type: "SoftmaxWithLoss"
bottom: "ip1"
bottom: "label"
top: "loss"
}
ps:
- solver算是caffe核心的核心,它协调着整个模型的运作,caffe程序运行必须带一个参数就是solver配置文件。
- caffe提供了六种优化算法来求解最优解,在solver配置文件中,通过设置type类型来选择:
-
Stochastic Gradient Descent (type: "SGD"), AdaDelta (type: "AdaDelta"), Adaptive Gradient (type: "AdaGrad"), Adam (type: "Adam"), Nesterov’s Accelerated Gradient (type: "Nesterov") and RMSprop (type: "RMSProp")
-
- Solver的流程:
-
1. 设计好需要优化的对象,以及用于学习的训练网络和用于评估的测试网络。(通过调用另外一个配置文件prototxt来进行) 2. 通过forward和backward迭代的进行优化来跟新参数。 3. 定期的评价测试网络。 (可设定多少次训练后,进行一次测试) 4. 在优化过程中显示模型和solver的状态 -
#每一次的迭代过程 • 1、调用forward算法来计算最终的输出值,以及对应的loss • 2、调用backward算法来计算每层的梯度 • 3、根据选用的slover方法,利用梯度进行参数更新 • 4、记录并保存每次迭代的学习率、快照,以及对应的状态。
-


















 1585
1585

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









