 深度学习语义分割:DeepLabv3+与Atrous Separable卷积解析
深度学习语义分割:DeepLabv3+与Atrous Separable卷积解析





 DeepLabv3+是ECCV2018上提出的一种改进的语义图像分割方法,它在DeepLabv3基础上结合Encoder-Decoder结构和Atrous Separable卷积,达到state-of-the-art性能。通过ResNet101或Xception作为backbone,利用Depthwise Separable Convolution提高效率。在Pascal VOC 2012上达到89.0%的准确率,Cityscapes上达到82.1%。文章详细介绍了Atrous Convolution和Decoder的设计,以及实验结果。
DeepLabv3+是ECCV2018上提出的一种改进的语义图像分割方法,它在DeepLabv3基础上结合Encoder-Decoder结构和Atrous Separable卷积,达到state-of-the-art性能。通过ResNet101或Xception作为backbone,利用Depthwise Separable Convolution提高效率。在Pascal VOC 2012上达到89.0%的准确率,Cityscapes上达到82.1%。文章详细介绍了Atrous Convolution和Decoder的设计,以及实验结果。
这篇论文呢是参与了DeepLab整个系列的作者Liang-Chieh Chen的又一新作。在V3的基础上进行的优化更新,故,又叫V3+。这个一作还参与了MaskLab系列和MobileNet系列的工作,其中就会设计到MobileNet的一些方法。
ECCV2018
概述
- 解决的问题?
- 本文主要是在V3的基础上进行了改进,达到了最新的语义分割的state-of-the-art。
- 采用了方法?(Innovation)
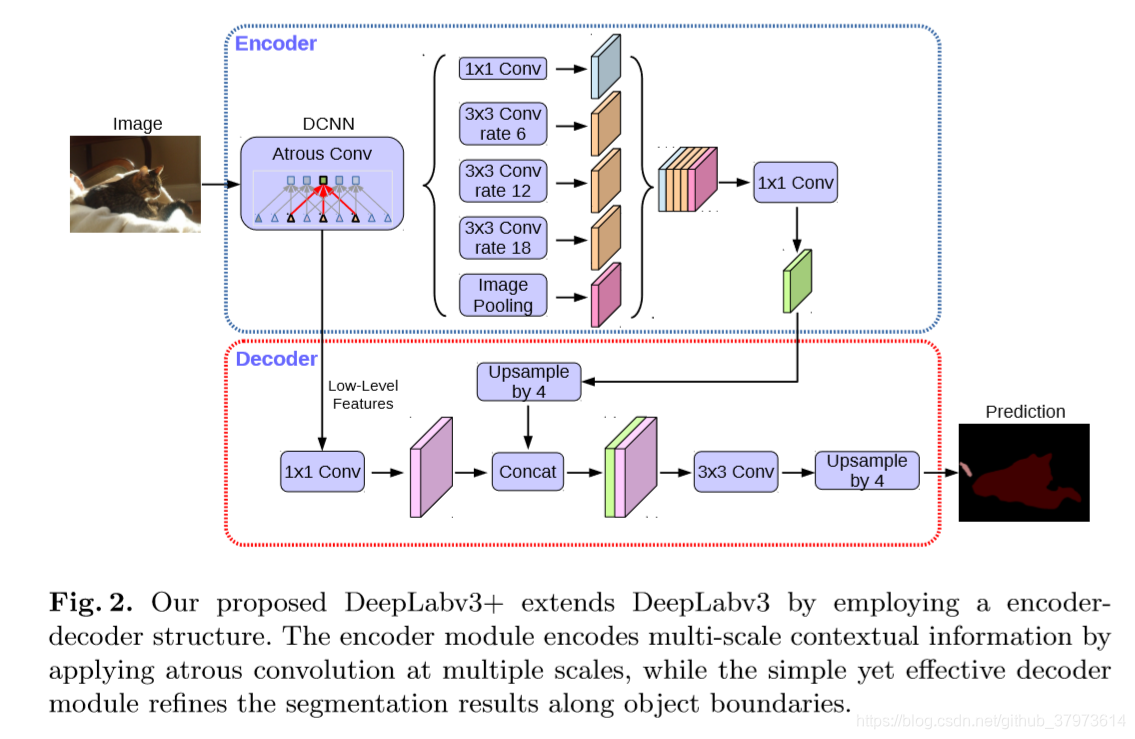
- ASPP & Encoder-Decoder,以DeepLabV3为encoder架构。
- ResNet101 & Xception
- Depthwise separable convolution
- 结果如何(没有任何后处理)
- Pascal VOC 2012:89.0%
- Cityscapes:82.1%
- code:here
- Contributions
- 论文提出一个全新的Encoder-Decoder框架,使用DeepLabV3作为encoder模块,并添加了一个简单的Decoder部分。
- 论文将Xception结构应用于分割任务中,在ASPP和Decoder模块中加入了深度分离卷积 (depthwise separable convolution),获得强大又快速的模型
细节
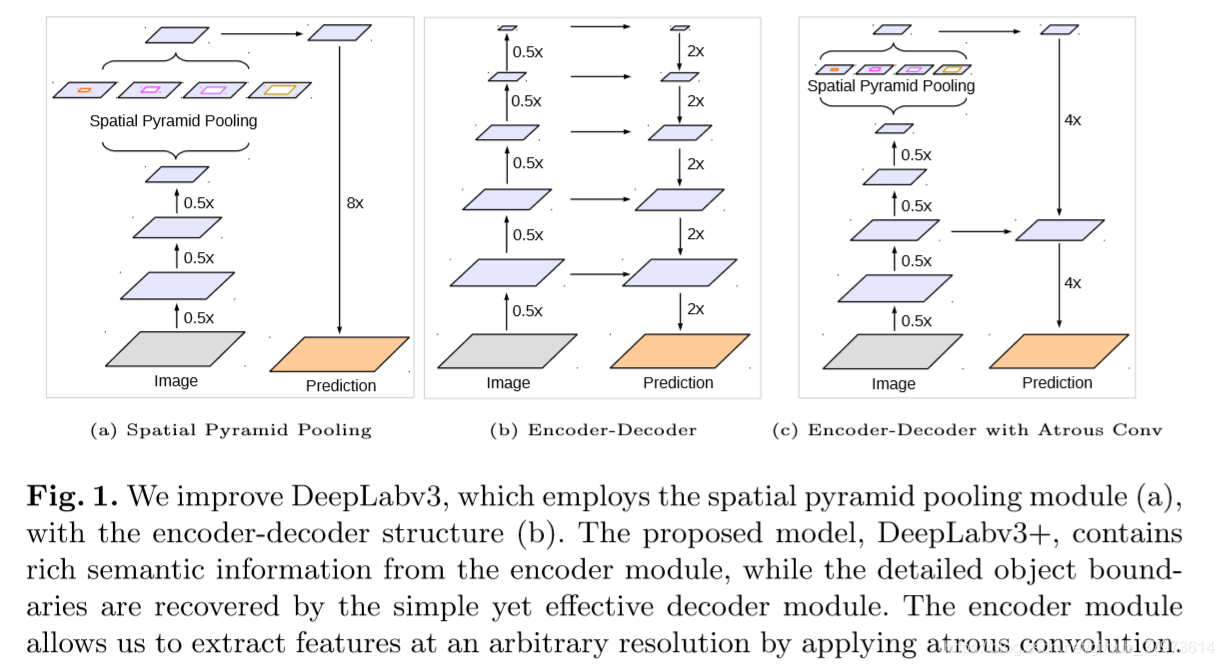
上面的结构是SPP、E-D、E-D with Atrous Conv的结构,很明显就可以看出结构的组成。
methods
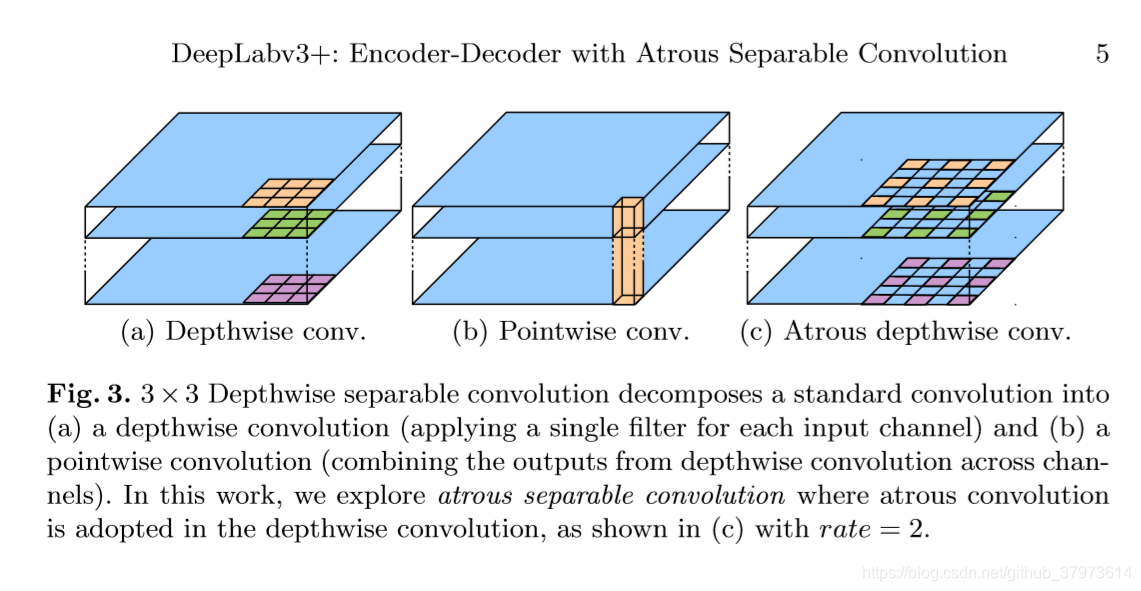
- Atrous Convolution
上图是关于几种卷积的介绍,Atrous Conv很好理解了。这个是轻车熟路的。而且在后面会专门从源码去看一下他们的操作。 - Depthwise separable convolution
其实也很简单,MobileNet也有使用。本来我们对feature map做卷积时,假若feature map为 n ∗ n ∗ c n*n*c n∗n∗c大小,那么我们的卷积其实output_c个 k ∗ k ∗ c k*k*c k∗k∗c<
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1022
1022

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









