



01
AI大模型「基模五强专题」评测榜单说明
【关于基模五强】国内大模型竞争从“百模大战”,到“6+2”战局,再到如今的“基模五强”(字节豆包、阿里千问、深度求索、智谱AI、阶跃星辰),可谓“神仙打架”,精彩纷呈!今天咱们就结合实测数据,扒一扒这五强在旗舰性能、领域应用和价格上,各方实力如何!
【评测目标】以评促优、以评促用、以评促享
【评测模型】基模五强文本大模型
【评测集】8大领域、300+维度评估,2025最新题集,低污染度,大模型“闭卷”考试实测;为便于各领域横向对比,本次评分机制细分领域、总分均为为百分制;
【评测方式】基模五强(系列大模型)官方API
【更多评测资讯】https://nonelinear.com
02
AI大模型「基模五强专题」优劣势核心结论
基模五强优、劣势简析汇总表

*数据来源:ReLE中文大模型能力评测
#基模五强-各家模型概况小结
- 字节豆包
以“综合实力派”的形象,在多个领域展现出强大的通用能力。
- 阿里千问
凭借“模型矩阵”的优势,力求覆盖所有需求,打法全面。
- 智谱AI
则以“专业领域尖刀”的姿态,在特定行业形成壁垒。
- 深度求索
瞄准“高端性能”和“科研突破”,目标是技术高地。
- 阶跃星辰
作为“潜力黑马”,未来表现值得期待。
03
AI大模型「基模五强专题」评测关键发现
一、旗舰模型巅峰对比(仅取各厂商总分排名最高模型)
-
旗舰模型PK:豆包领跑,智谱和深度求索紧追!
-
一句话总结:旗舰模型榜,豆包以全能表现暂时领跑,智谱AI和深度求索凭借各自专长紧随其后,阿里和阶跃星辰也各有亮点。
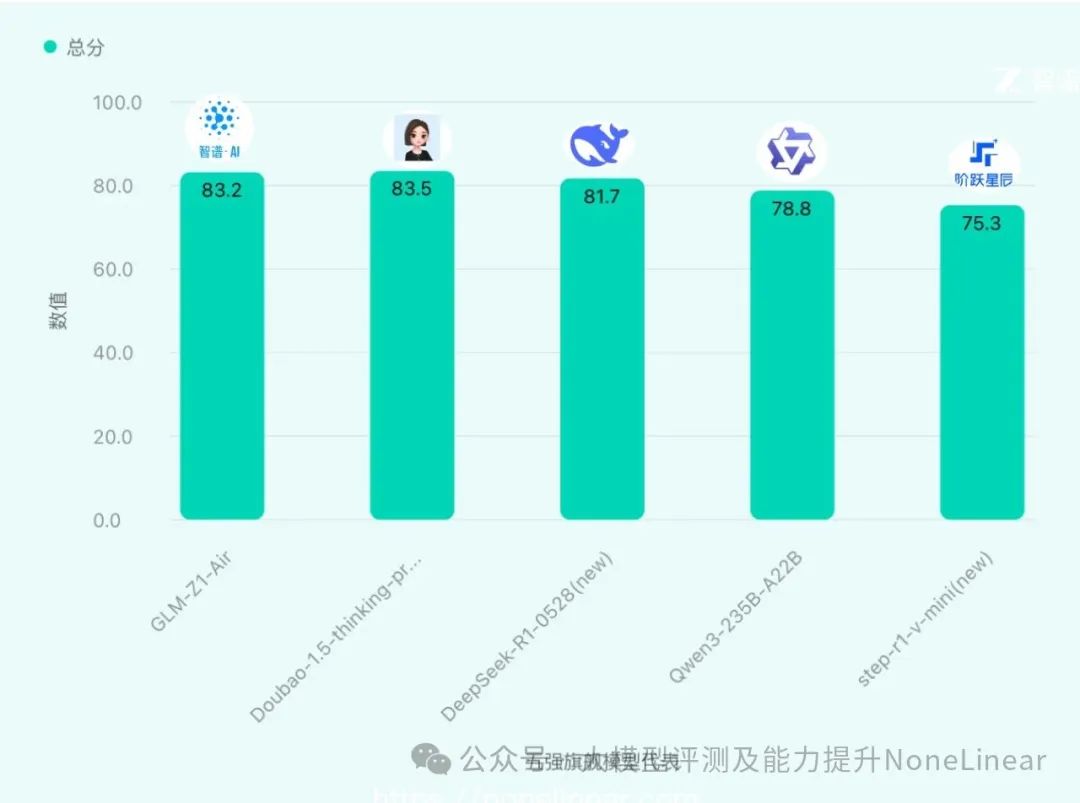
*数据来源:ReLE中文大模型能力评测
旗舰模型总分、领域得分与输出价格明细表(¥RMB / Million tokens)

*数据来源:ReLE中文大模型能力评测
二、模型布局:全家桶战术 vs 精锐路线
-
模型布局策略:阿里“人海”,豆包“精兵”,智谱“专业”!
-
一句话总结:阿里模型多如牛毛主打全覆盖,豆包少而精要打精品战,智谱AI专注专业领域,深度求索和阶跃星辰也各出奇招。
基模五强各家模型布局概况
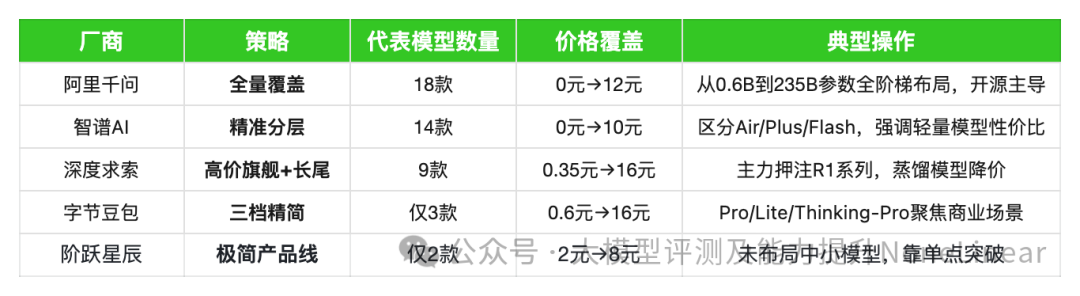
*数据来源:ReLE中文大模型能力评测
#核心洞察
各家模型家族的“排兵布阵”也很有意思
观察各家的大模型布局,可以发现它们的策略各具特色:
-
字节豆包:
模型数量相对较少,但其旗舰模型表现强劲,且价格策略灵活,从0.6元到16元不等,覆盖了从轻量级到旗舰级不同需求。
-
阿里千问:
拥有最庞大的模型家族,从Qwen3-235B-A22B到Qwen3-0.6B,价格从0元到12元,显示出其全系列覆盖的野心。
-
智谱AI:
模型种类也较为丰富,从0元到10元的价格区间,其模型在法律、行政公务等领域优势明显。
-
深度求索:
其模型数量适中,但旗舰模型价格偏高(16元),同时也有免费模型。深度求索更专注于科研技术突破,同时通过免费模型进行技术普及。
-
阶跃星辰:
目前提供的数据模型较少,但其step-r1-v-mini(new)的表现不俗。作为新晋玩家,阶跃星辰可能采取精品策略,先推出具有竞争力的核心模型,再逐步拓展。
三、领域应用强弱对比:
-
领域应用得分:智谱“法务行政”无敌,豆包“教育医疗”称王!
-
一句话总结:智谱AI在法律和行政公务领域几乎无敌,豆包在教育和医疗领域拔得头筹,其他领域各家你追我赶。
基模五强各领域得分Top3明细表
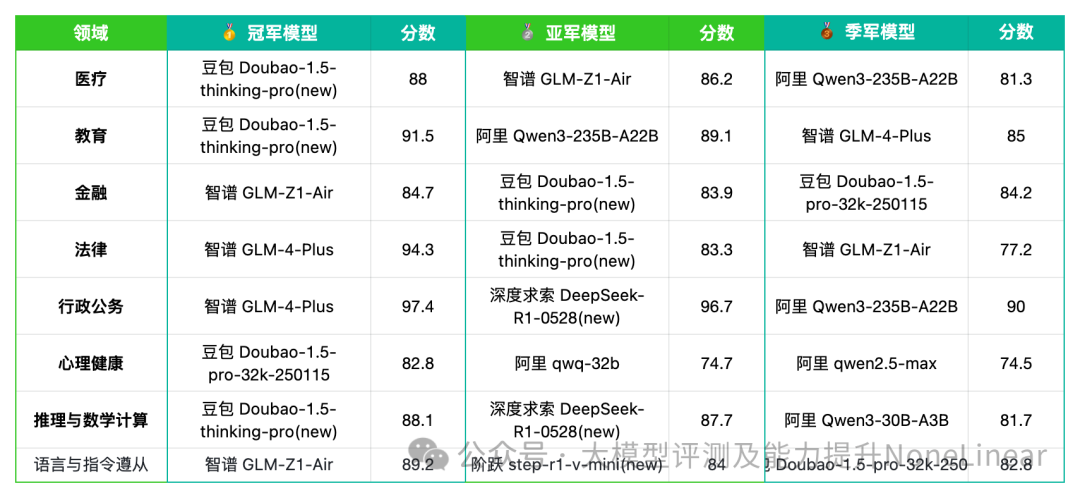
*数据来源:ReLE中文大模型能力评测
#“考场”表现
谁能更好地服务行业?
除了总分表现,各模型在特定领域的应用能力也是衡量其价值的关键,来看看大家在不同“考场”的表现:
-
行政公务:智谱AI的GLM-4-Plus (97.4分)和深度求索的DeepSeek-R1-0528(new) (96.7分)表现一骑绝尘,展现出强大的文本理解、信息提取和逻辑推理能力;阿里千问和阶跃星辰在这一领域也表现不俗,拥有90分以上的模型。
-
教育与医疗:字节豆包的**Doubao-1.5-thinking-pro(new)**在教育(91.5分)和医疗(88.0分)方面均有亮眼表现,显示出其在知识问答、内容生成、辅助诊断等方面的潜力。阿里千问在教育领域也有多个模型得分较高。
-
法律与金融:智谱AI在法律领域(GLM-4-Plus 94.3分)的统治力尤其突出,;在金融领域,各家模型表现较为均衡,多在70-80分区间,仍有提升空间。
-
推理与数学计算:字节豆包和深度求索的旗舰模型在推理与数学计算方面表现出色,分别达到88.1分和87.7分,这对于需要强大逻辑分析和数据处理能力的场景至关重要。

















 6862
6862

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









