




 本文介绍了R包MUVR,它使用repeated double cross validation (rdCV)方法,结合PLS和RF模型进行变量选择。适用于变量数大于观测数的大规模数据,支持分类和连续响应变量的分析。MUVR提供了数据预处理功能,并通过案例展示了如何寻找生物标记物和预测变量。
本文介绍了R包MUVR,它使用repeated double cross validation (rdCV)方法,结合PLS和RF模型进行变量选择。适用于变量数大于观测数的大规模数据,支持分类和连续响应变量的分析。MUVR提供了数据预处理功能,并通过案例展示了如何寻找生物标记物和预测变量。
导读
今天给大家介绍的是一款施琳大神(现就读于查尔默斯大学,postdoc)于今年发表的一个R包-
MUVR(Multivariate methods with Unbiased Variable selection in R),主要是为计算预测变量和响应变量之间的关系提供了一种新的算法,那么这里的响应变量既可以是连续变量用于回归分析,也可以是因子变量用于分类分析。另外一个我之所以介绍这个软件的原因是,它可以用于处理大规模变量数目大于观测数的数据格式,所以还是很友好的一个软件。因为大多数科研单位都不太可能做到那么大的样本量,除非是豪门!
文章介绍
-
这个方法施琳师姐也是以一作和通讯的身份发表在了Bioinformatics杂志上,让我等有机会拜读。文章标题为Variable selection and validation in multivariate modelling
-
再给个文章截图,有需要的可以自行下载(Open Access,DOI:10.1093/bioinformatics/bty710)

方法原理简介
- 那么从技术分析的角度,MUVR采用的是一种
双重复交叉验证(repeated double cross validation, rdCV)的递归式的变量选择方法。MUVR包括了偏最小二乘(partial least squares, PLS)和随机森林(random forest, RF)模型。它有两种变量的选择方法:
-
minimal-optimal variables: 最少-最优变量,主要用于发现具有预测性的生物标记物;
-
all-relevant variables: 全部相关的变量,主要用于生物学呈现和机制研究。
- MUVR的工作原理见下图
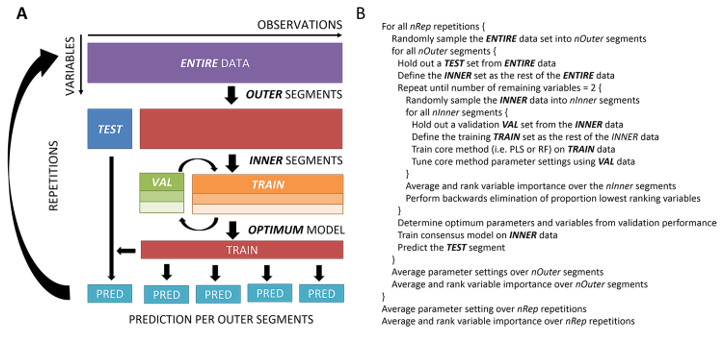
包的安装和案例演示
1.包的安装
- 这里建议大家在安装了R软件的同时,安装一个Rstudio软件,这个软件非常友好,提供了很多可视化的界面。然后大家的包的下载,安装以及工作都在Rstudio这个软件上。
library(devtools)
install_git("https://gitlab.com/CarlBrunius/MUVR.git")
library(MUVR)
2.对于Y变量是分类变量的数据
首先要对输入的数据做个说明,这里的预测变量,暂且用大写的X表示,以及响应变量,用Y表示,两个输入数据必须是观测数要要一致(不论是数目还是ID都要相符合)。另外X的变量不能重复,要每一个都是唯一的。另外的一点就是数据的前处理这一块,因为随
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2766
2766

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









