




 本文介绍如何使用OpenCV库中的compareHist函数比较图像的H-S直方图,并通过不同指标评估图像间的相似度。
本文介绍如何使用OpenCV库中的compareHist函数比较图像的H-S直方图,并通过不同指标评估图像间的相似度。
Goal
在本教程中,您将学习如何:
使用函数 cv::compareHist 获取一个数值参数,该参数表示两个直方图相互匹配的程度。
使用不同的指标来比较直方图
Theory
要比较两个直方图(H1 和 H2),首先我们必须选择一个指标(d(H1,H2))来表示两个直方图的匹配程度。
OpenCV 实现函数 cv::compareHist 来执行比较。 它还提供了 4 种不同的指标来计算匹配:
- Correlation ( CV_COMP_CORREL ) 相关性
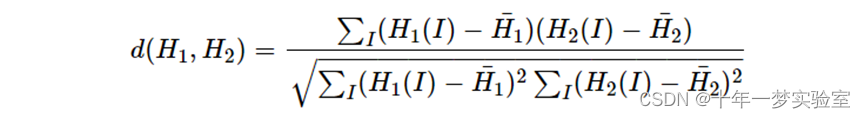
其中
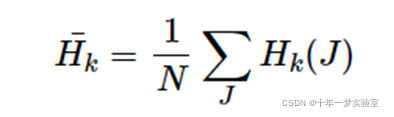
N 是直方图 bin 的总数。
2. Chi-Square ( CV_COMP_CHISQR ) 卡方
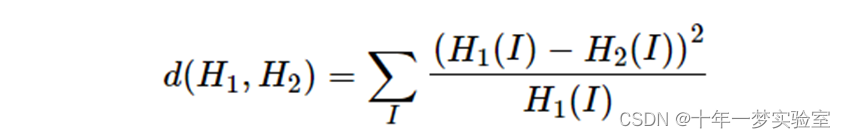
3.Intersection ( method=CV_COMP_INTERSECT ) 相交
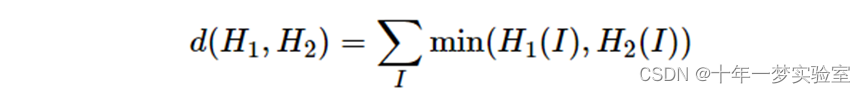
4.Bhattacharyya distance ( CV_COMP_BHATTACHARYYA )
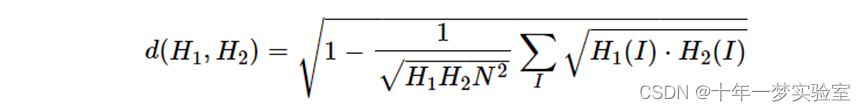
Code
这个程序有什么作用?
加载一个基本图像和 2 个要与之比较的测试图像。
生成 1 个图像,它是基础图像的下半部分
将图像转换为 HSV 格式
计算所有图像的 H-S 直方图并将它们归一化以便比较它们。
将基础图像的直方图与 2 个测试直方图、下半部分基础图像的直方图和相同的基础图像直方图进行比较。
显示获得的数值匹配参数。
可下载代码:点击这里opencv/compareHist_Demo.cpp at 4.x · opencv/opencv (github.com)
代码一览:
/**
* @file compareHist_Demo.cpp
* @brief 比较直方图Sample code to use the function compareHist
* @author OpenCV team
*/
#include "opencv2/imgcodecs.hpp"
#include "opencv2/highgui.hpp"
#include "opencv2/imgproc.hpp"
#include <iostream>
using namespace std;
using namespace cv;
const char* keys =
"{ help h| | Print help message. }"
"{ @input1 | | Path to input image 1. }"
"{ @input2 | | Path to input image 2. }"
"{ @input3 | | Path to input image 3. }";
/**
* @function main
*/
int main( int argc, char** argv )
{
//! [加载三个具有不同环境设置的图像]
CommandLineParser parser( argc, argv, keys );
Mat src_base = imread( parser.get<String>("input1") );
Mat src_test1 = imread( parser.get<String>("input2") );
Mat src_test2 = imread( parser.get<String>("input3") );
if( src_base.empty() || src_test1.empty() || src_test2.empty() )
{
cout << "Could not open or find the images!\n" << endl;
parser.printMessage();
return -1;
}
//! [Load three images with different environment settings]
//! [转换为 HSV]
Mat hsv_base, hsv_test1, hsv_test2;
cvtColor( src_base, hsv_base, COLOR_BGR2HSV );
cvtColor( src_test1, hsv_test1, COLOR_BGR2HSV );
cvtColor( src_test2, hsv_test2, COLOR_BGR2HSV );
//! [Convert to HSV]
//! [Convert to HSV half] 取hsv_base的下半部分
Mat hsv_half_down = hsv_base( Range( hsv_base.rows/2, hsv_base.rows ), Range( 0, hsv_base.cols ) );
//! [Convert to HSV half]
//! [Using 50 bins for hue and 60 for saturation]色调使用 50 个 bin,饱和度使用 60
int h_bins = 50, s_bins = 60;
int histSize[] = { h_bins, s_bins };
// hue varies from 0 to 179, saturation from 0 to 255 色调从 0 到 179 变化,饱和度从 0 到 255
float h_ranges[] = { 0, 180 };
float s_ranges[] = { 0, 256 };
const float* ranges[] = { h_ranges, s_ranges };
// Use the 0-th and 1-st channels 使用第 0 和第 1 通道
int channels[] = { 0, 1 };
//! [Using 50 bins for hue and 60 for saturation]
//! [Calculate the histograms for the HSV images] 计算4张 HSV 图像的直方图并归一化
Mat hist_base, hist_half_down, hist_test1, hist_test2;
calcHist( &hsv_base, 1, channels, Mat(), hist_base, 2, histSize, ranges, true, false );
normalize( hist_base, hist_base, 0, 1, NORM_MINMAX, -1, Mat() );
calcHist( &hsv_half_down, 1, channels, Mat(), hist_half_down, 2, histSize, ranges, true, false );
normalize( hist_half_down, hist_half_down, 0, 1, NORM_MINMAX, -1, Mat() );
calcHist( &hsv_test1, 1, channels, Mat(), hist_test1, 2, histSize, ranges, true, false );
normalize( hist_test1, hist_test1, 0, 1, NORM_MINMAX, -1, Mat() );
calcHist( &hsv_test2, 1, channels, Mat(), hist_test2, 2, histSize, ranges, true, false );
normalize( hist_test2, hist_test2, 0, 1, NORM_MINMAX, -1, Mat() );
//! [Calculate the histograms for the HSV images]
//! [应用直方图比较方法]
for( int compare_method = 0; compare_method < 4; compare_method++ )
{
double base_base = compareHist( hist_base, hist_base, compare_method );
double base_half = compareHist( hist_base, hist_half_down, compare_method );
double base_test1 = compareHist( hist_base, hist_test1, compare_method );
double base_test2 = compareHist( hist_base, hist_test2, compare_method );
cout << "Method " << compare_method << " Perfect, Base-Half, Base-Test(1), Base-Test(2) : "
<< base_base << " / " << base_half << " / " << base_test1 << " / " << base_test2 << endl;
}
//! [Apply the histogram comparison methods]
cout << "Done \n";
return 0;
}Explanation
加载基础图像 (src_base) 和其他两个测试图像:
CommandLineParser parser( argc, argv, keys );
Mat src_base = imread( parser.get<String>("input1") );//基础图像
Mat src_test1 = imread( parser.get<String>("input2") );//测试图像1
Mat src_test2 = imread( parser.get<String>("input3") );//测试图像2
if( src_base.empty() || src_test1.empty() || src_test2.empty() )
{
cout << "Could not open or find the images!\n" << endl;
parser.printMessage();
return -1;
}将它们转换为 HSV 格式:
Mat hsv_base, hsv_test1, hsv_test2;
cvtColor( src_base, hsv_base, COLOR_BGR2HSV );
cvtColor( src_test1, hsv_test1, COLOR_BGR2HSV );
cvtColor( src_test2, hsv_test2, COLOR_BGR2HSV );此外,创建一半基本图像的图像(HSV 格式):
Mat hsv_half_down = hsv_base( Range( hsv_base.rows/2, hsv_base.rows ), Range( 0, hsv_base.cols ) ); //下半截图像初始化参数以计算直方图(箱、范围和通道 H 和 S )。
int h_bins = 50, s_bins = 60;
int histSize[] = { h_bins, s_bins };
// 色调从 0 到 179 变化,饱和度从 0 到 255
// hue varies from 0 to 179, saturation from 0 to 255
float h_ranges[] = { 0, 180 };
float s_ranges[] = { 0, 256 };
const float* ranges[] = { h_ranges, s_ranges };
// Use the 0-th and 1-st channels
int channels[] = { 0, 1 };计算基础图像、2 个测试图像和 基础图像下半部分的直方图:
Mat hist_base, hist_half_down, hist_test1, hist_test2;
calcHist( &hsv_base, 1, channels, Mat(), hist_base, 2, histSize, ranges, true, false );
normalize( hist_base, hist_base, 0, 1, NORM_MINMAX, -1, Mat() );
calcHist( &hsv_half_down, 1, channels, Mat(), hist_half_down, 2, histSize, ranges, true, false );
normalize( hist_half_down, hist_half_down, 0, 1, NORM_MINMAX, -1, Mat() );
calcHist( &hsv_test1, 1, channels, Mat(), hist_test1, 2, histSize, ranges, true, false );
normalize( hist_test1, hist_test1, 0, 1, NORM_MINMAX, -1, Mat() );
calcHist( &hsv_test2, 1, channels, Mat(), hist_test2, 2, histSize, ranges, true, false );
normalize( hist_test2, hist_test2, 0, 1, NORM_MINMAX, -1, Mat() ); 在基础图像 (hist_base) 的直方图和其他直方图之间依次应用 4 种比较方法:
for( int compare_method = 0; compare_method < 4; compare_method++ )
{
double base_base = compareHist( hist_base, hist_base, compare_method );
double base_half = compareHist( hist_base, hist_half_down, compare_method );
double base_test1 = compareHist( hist_base, hist_test1, compare_method );
double base_test2 = compareHist( hist_base, hist_test2, compare_method );
cout << "Method " << compare_method << " Perfect, Base-Half, Base-Test(1), Base-Test(2) : "
<< base_base << " / " << base_half << " / " << base_test1 << " / " << base_test2 << endl;
}Results
- 我们使用以下图像作为输入:

Base_0

Test_1

Test_2
其中第一个是基础(与其他图像进行比较),另外两个是测试图像。 我们还将比较第一张图像与其自身和一半的基本图像。
2. 当我们将基本图像直方图与其自身进行比较时,我们应该期待完美匹配。 此外,与一半基本图像的直方图相比,它应该呈现出高度匹配,因为两者都来自同一来源。 对于另外两张测试图像,我们可以观察到它们的光照条件非常不同,所以匹配应该不是很好:
3. 这是我们使用 OpenCV 3.4.1 得到的数值结果:
| *Method* | Base - Base | Base - Half | Base - Test 1 | Base - Test 2 |
| *Correlation* | 1.000000 | 0.880438 | 0.20457 | 0.0664547 |
| *Chi-square* | 0.000000 | 4.6834 | 2697.98 | 4763.8 |
| *Intersection* | 18.8947 | 13.022 | 5.44085 | 2.58173 |
| *Bhattacharyya* | 0.000000 | 0.237887 | 0.679826 | 0.874173 |
对于 Correlation 和 Intersection 方法,度量越高,匹配越准确。 正如我们所见,match base-base 是所有预期中最高的。 我们还可以观察到匹配的下半部分是第二好的匹配(正如我们所预测的那样)。 对于其他两个指标(Chi-square、Bhattacharyya),结果越少,匹配越好。 我们可以观察到,测试 1 和测试 2 之间关于基的匹配更差,这也是意料之中的。

















 473
473

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









