




UniHOPE: A Unified Approach for Hand-Only and Hand-Object Pose Estimation
期刊:Computer Vision and Pattern Recognition
原文链接:[2503.13303] UniHOPE: A Unified Approach for Hand-Only and Hand-Object Pose Estimation
摘要:从单目图像中估计手和潜在手持物体的 3D 姿势是一项长期的挑战。然而,现有的方法是专门的,专注于裸手或手与对象的交互。没有一种方法可以灵活地处理这两种情况,当应用于另一种情况时,它们的性能会下降。在本文中,我们提出了 UniHOPE,这是一种用于通用 3D 手部物体姿态估计的统一方法,可以灵活地适应这两种情况。从技术上讲,我们设计了一个抓取感知特征融合模块,将手部物体特征与物体切换器集成,根据抓取状态动态控制手部物体姿态估计。此外,为了提高手部姿势估计的鲁棒性,无论对象是否存在,我们生成了逼真的去遮挡图像对来训练模型学习对象诱导的手部遮挡,并制定多级特征增强技术来学习遮挡不变特征。对三个常用基准的广泛实验证明了 UniHOPE 的 SOTA 在解决仅手和手部对象场景方面的性能。
1.动机
从单目图像中估计手和潜在手持物体的 3D 姿态是一项长期的任务,在 VR/AR、人机交互等方面都有应用。但是,现有方法存在分歧。手部姿势估计 (HPE) 方法在不考虑手持物体的情况下预测 3D 手部姿势。相反,手部物体姿态估计 (HOPE) 方法假设存在手持物体,并使用额外的物体分支执行物体姿态估计。然而,即使没有物体,也总是做出预测。这两种方法都无法灵活地同时考虑仅手和手对象方案,泛化性、灵活性差。
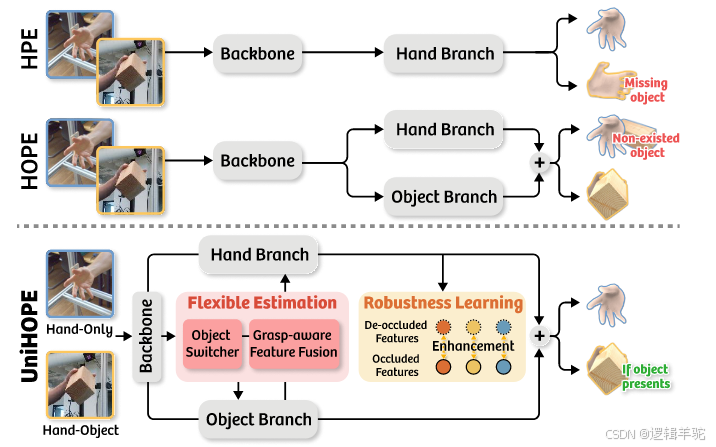
2.解决思路
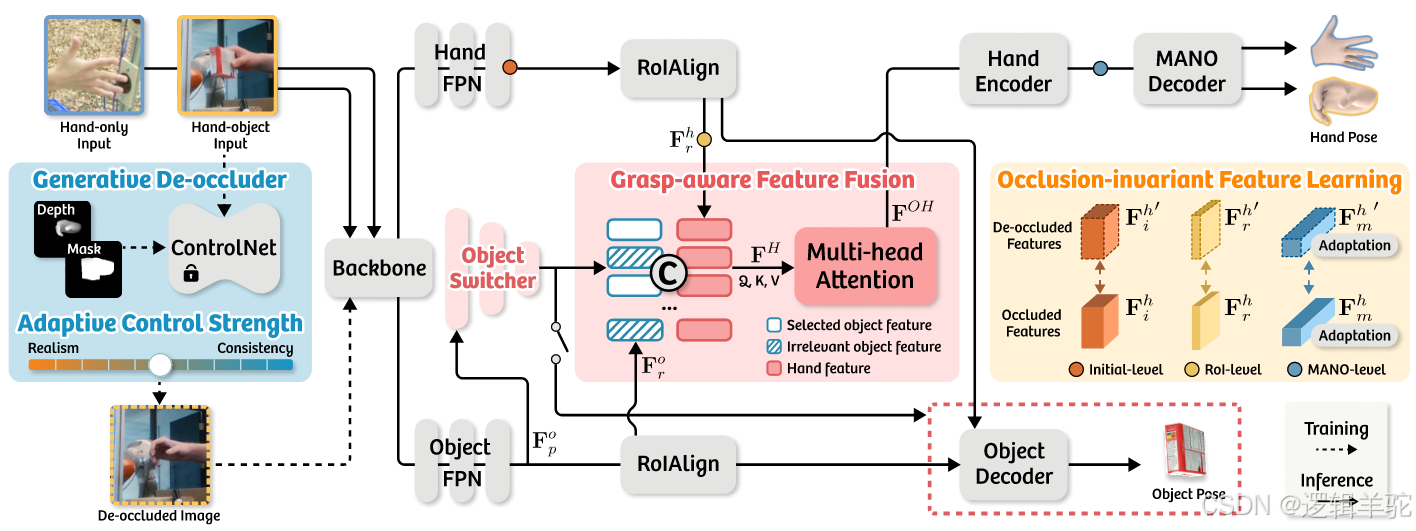
输入:仅手部的图像 or 手部与物体交互的图像
经过一个生成式去遮挡器(蓝色背景)去除手部图像中的遮挡部分,生成清晰的手部图像。Adaptive Control Strength是一个自适应强度控制,用来平滑生成图像的真实度的。
然后使用Backbone提取图像特征,Hand FPN是处理手部特征的特征金字塔网络,Object FPN是处理手部特征的特征金字塔网络。
而后通过一个对象切换器(基于MLP的二分类器)进行选择,只有“抓取”标签的图片才会进行手部-物体特征融合,节约计算资源。RolAlign用于从特征图里提取感兴趣区域的特征,Multi-head Attention用于特征融合,增强特征表示,融合后的手-物体特征被送到Hand Encoder编码手部特征,MANO Decoder进一步解码手部特征,输出手部姿态。物体姿态则直接进行解码求解。
而遮挡不变特征学习(橙色背景)是在遮挡情况下学习鲁棒的特征表示,其中Multi-level Feature Enhancement是在多个层次上增强特征,而Adaptation则是通过多头注意力块改善不同层次的特征传递,最后输出增强后的特征。
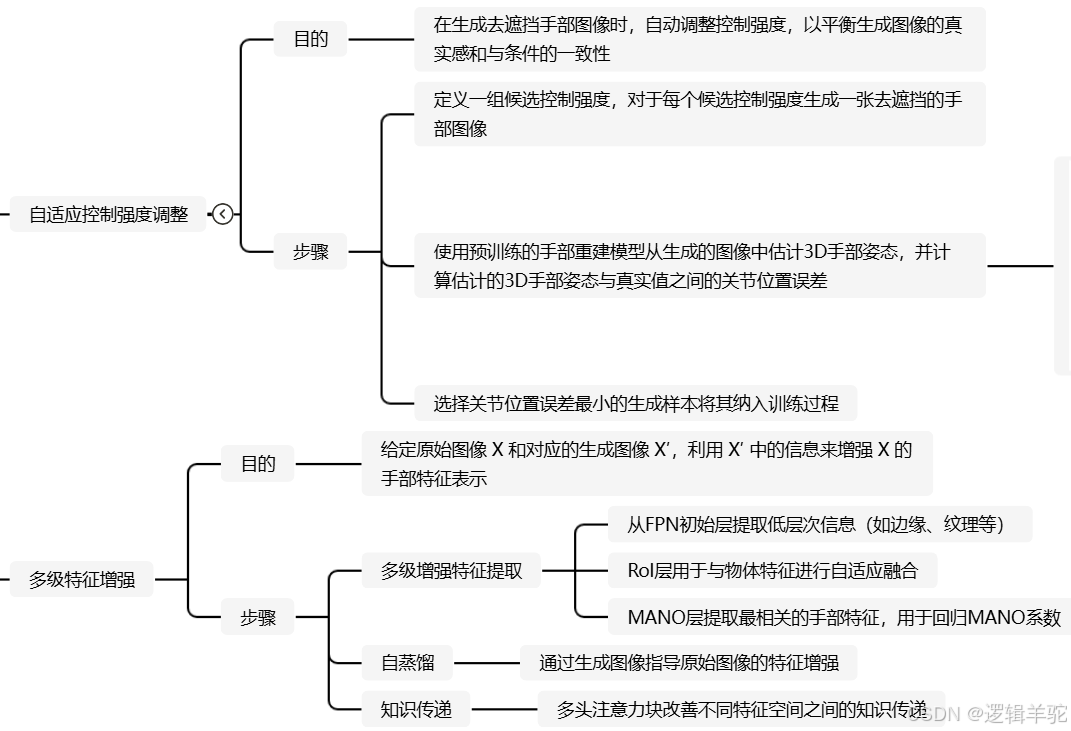
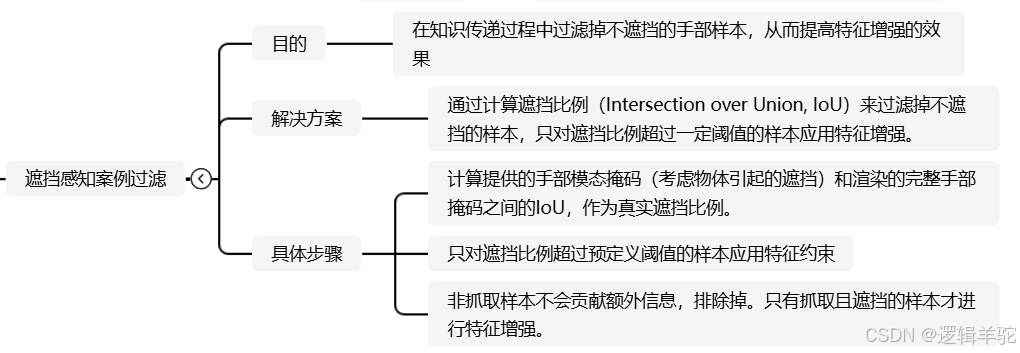
部分模块的思维导图截图如下,完整思维导图


3.创新性
- 对象切换器:只有带“抓取”标签的图像才会进行手部-物体特征融合,节约计算资源,同时也使得整个系统能够更灵活地处理“仅手部”和“手部-物体交互”两种场景,提高了整个系统的泛化性和灵活性。
- 生成式去遮挡器:结合了ControlNet和潜在扩散模型,能够根据深度图和掩码生成高质量的去遮挡图像,并通过自适应控制强度调整确保生成图像的真实性和一致性。
- 多级特征增强:在多个层次(初始层、Rol层、MANO层)上对手部特征进行增强表示,全面提升了手部特征的表示能力,并通过多头注意力块改善特征传递,确保特征的一致性和真实性。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









