




 本文介绍了机器学习的基本概念,定义为计算机程序通过经验E提升解决任务T的性能P。机器学习分为监督学习和非监督学习。监督学习包含分类(如房屋价格预测)和回归(如肿瘤恶性判断)问题;非监督学习则在无标签数据中寻找特征的内在联系,如聚类分析。
本文介绍了机器学习的基本概念,定义为计算机程序通过经验E提升解决任务T的性能P。机器学习分为监督学习和非监督学习。监督学习包含分类(如房屋价格预测)和回归(如肿瘤恶性判断)问题;非监督学习则在无标签数据中寻找特征的内在联系,如聚类分析。
目录
1 机器学习的定义
课程中关于机器学习的表述:计算机程序从经验E中学习,解决某一任务T,进行某一性能度量P,通过P测定在T上的表现因经验E而提高。
用一种通俗的说法就是机器从大量数据中学习,总结出一个符合客观规律的模型,令机器使用该模型解决某项任务,机器使用该模型解决问题的表现得到了提高。
2 机器学习的分类
1 监督学习
已有的数据集包含了输入和输出的关系,通过输入可以获取输出的明确结果。通过这种数据集训练得到一个最优的模型。换而言之,监督学习所使用的数据集既有特征也有标签,通过训练,机器可以学习到特征与标签的对应关系,当机器遇到只有特征没有标签的数据时,可以根据已有模型推断出对应的标签。监督学习同样包括两种分类,即分类问题和回归问题。
分类问题
分类问题所输出的是连续型变量。比如针对房屋价格的预测问题就是一个典型的分类问题,根据房屋面积的不同售价也会有差异,但售价并不是一个离散变量而是一个连续变量。
回归问题
回归问题所输出的是离散型变量。比方说针对肿瘤的大小判断恶性还是良性就是对回归问题的典型应用,恶性和良性是典型的离散变量。
2 非监督学习
非监督学习与监督学习的不同在于我们的数据集并没有明确的输出,也就是说只有特征而没有标签,机器需要通过训练自我学习找到特征的内在联系。聚类是一种非监督学习的典型算法。
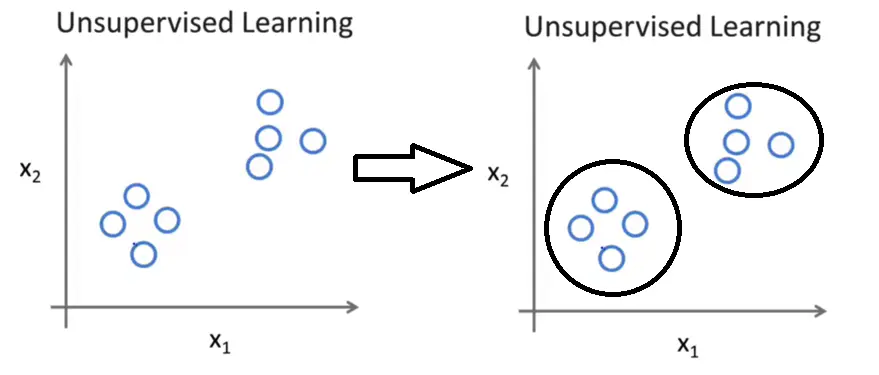
上图中我们的数据只有输入特征并没有明确的标签,这里我们使用聚类算法让机器通过学习分析数据特征的内在联系,将数据集分成了两个簇。

















 3491
3491

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









