







 本文详细介绍了优化机器学习模型的各种策略,包括正交化、评价标准、训练集验证集测试集划分、误差分析以及应对不同分布问题的方法。重点讨论了如何选择合适的评价指标、如何处理数据分布不一致的问题,还探讨了迁移学习、多任务学习和端到端学习等深度学习方法在模型优化中的应用。
本文详细介绍了优化机器学习模型的各种策略,包括正交化、评价标准、训练集验证集测试集划分、误差分析以及应对不同分布问题的方法。重点讨论了如何选择合适的评价指标、如何处理数据分布不一致的问题,还探讨了迁移学习、多任务学习和端到端学习等深度学习方法在模型优化中的应用。
目录
在得到一个基础的神经网络模型后,我们需要寻找各种方法来优化它,因此我们需要机器学习策略来优化我们的模型。
1 正交化
在机器学习中有很多参数,超参数需要调试,每次只调试一个参数,保持其他参数不变,从而使模型性能改变,这一方法被称为正交化方法。
通常情况下,我们希望机器学习系统达到以下四个要求:
- 在训练集上获得优秀的结果
- 在验证集上获得优秀的结果
- 在测试集上获得优秀的结果
- 在测试集上的成本函数在实际应用中令人满意
以上第一个要求可以通过使用更复杂的算法实现,第二个可以通过正则化等手段实现,第三条可以通过使用更多验证集样本来实现,第四条可以通过更好验证集,使用新的成本函数来实现。
2 评价标准
1 单一数字评价标准
优化模型时,我们需要一个单值评价指标来选择最优的模型,举个例子,有AB两个模型,其查准率和召回率如下所示

单纯从某一个指标来看很难区别哪个更好,因此我们引入了F1 score来评价模型的好坏。
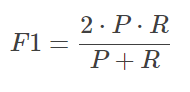
引入F1后得到AB各自的F1 score
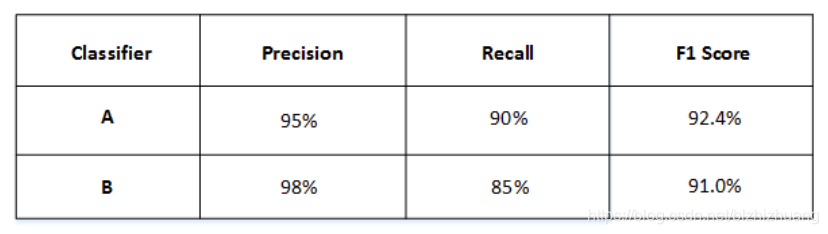
从上图可见A模型优于B模型
2 满足和优化指标
有时我们对模型的很多性能指标都有要求,此时把它们综合在一起寻求一个单值指标不太现实,解决方法是我们可以把某些性能作为优化指标,寻求最优化值;而某些性能作为满意指标,只要满足阈值就行了。
下面有ABC三个模型,各自的准确率和运行时间如下所示

我们让准确率作为优化指标,运行时间作为满意指标,满意阈值设为100ms,很容易可知B是最优的选择。
3 划分训练集验证集和测试集
1 划分原则
合理的训练集验证集测试集比例设置能大大提高训练效率和训练质量。
原则上测试集和验证集都应当来自同一分布并且反应现实情况的样本集合,从数量的角度而言,对三者的比例同样有要求,前面提到过,当样本数量较少时应当满足3:1:1的标准,在不设置验证集的情况下训练集和测试集的比例应当设置为7:3,并且样本越大,训练集的占比就应当越高。
对于验证集的数量需要满足其能检测不同算法或模型的区别,以便选择最优的模型,对于测试集的要求时能反映出模型在实际中的表现。
2 什么时候调整集合划分
我们已经了解了算法的评价标准,但是静态的标准有时无法适应实际应用,比如在识别猫图的例子中,一开始我们使用的是错误率作为评价标准
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1803
1803

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









